Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo include due esempi di modelli di raccomandazione basati su Deep Learning in Azure Databricks. Rispetto ai modelli di raccomandazione tradizionali, i modelli di Deep Learning possono ottenere risultati di qualità superiore e adattarsi a grandi quantità di dati. Man mano che questi modelli continuano a evolversi, Databricks fornisce un framework per il training efficace di modelli di raccomandazione su larga scala in grado di gestire centinaia di milioni di utenti.
Un sistema di raccomandazione generale può essere visualizzato come un imbuto con le fasi mostrate nel diagramma.
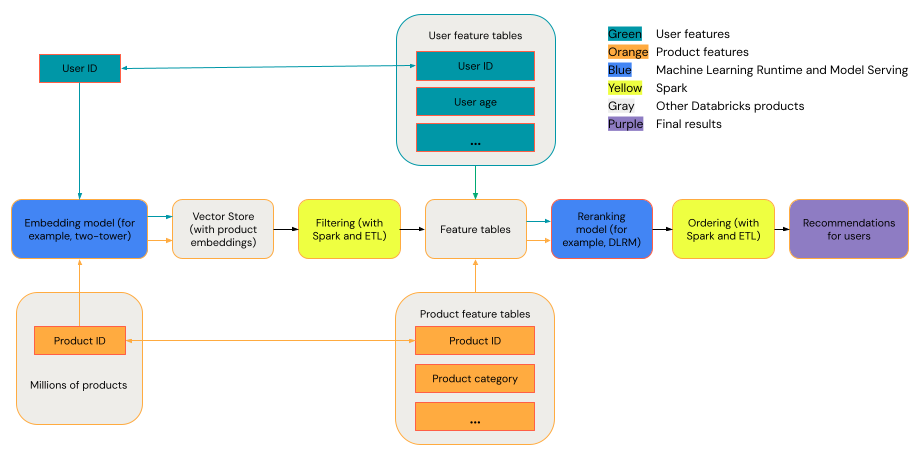
Alcuni modelli, ad esempio il modello a due torri, offrono prestazioni migliori come modelli di recupero. Questi modelli sono più piccoli e possono operare in modo efficace su milioni di punti dati. Altri modelli, come DLRM o DeepFM, offrono prestazioni migliori durante la riclassificazione dei modelli. Questi modelli possono accettare più dati, sono più grandi e possono fornire raccomandazioni granulari.
Requisiti
Databricks Runtime 14.3 LTS ML
Strumenti
Gli esempi in questo articolo illustrano i seguenti strumenti:
- TorchDistributor: TorchDistributor è un framework che consente di eseguire il training del modello PyTorch su larga scala in Databricks. Usa Spark per l'orchestrazione e può essere ridimensionato per tutte le GPU disponibili nel cluster.
- MLflow: MLflow consente di tenere traccia di parametri, metriche e checkpoint del modello.
- TorchRec: I moderni sistemi di raccomandazione usano tabelle di ricerca di embedding per gestire milioni di utenti e oggetti per generare raccomandazioni di alta qualità. Le dimensioni di incorporamento maggiori migliorano le prestazioni del modello, ma richiedono notevoli configurazioni di memoria GPU e multi-GPU. TorchRec offre un framework per scalare i modelli di raccomandazione e le tabelle di consultazione su più GPU, rendendolo ideale per grandi embedding.
Esempio: raccomandazioni di film che usano un'architettura del modello a due torri
Il modello a due torri è progettato per gestire le attività di personalizzazione su larga scala elaborando i dati degli utenti e degli elementi separatamente prima di combinarli. Esso è in grado di generare in modo efficiente centinaia o migliaia di raccomandazioni di qualità accettabile. Il modello prevede in genere tre input: una funzionalità user_id, una funzionalità product_id e un'etichetta binaria che definisce se l<'utente, l'interazione del prodotto> è stata positiva (l'utente ha acquistato il prodotto) o negativa (l'utente ha dato al prodotto una classificazione a una stella). Gli output del modello sono incorporamenti sia per gli utenti che per gli elementi, che vengono quindi in genere combinati (spesso usando un prodotto scalare o una somiglianza del coseno) per prevedere le interazioni degli elementi utente.
Poiché il modello a due torre fornisce incorporamenti sia per gli utenti che per i prodotti, è possibile inserire questi incorporamenti in un indice vettoriale, ad esempio Ricerca di intelligenza artificiale di Databricks ed eseguire operazioni simili a quelle di ricerca sugli utenti e sugli elementi. Ad esempio, è possibile inserire tutti gli elementi in un archivio vettoriale e, per ogni utente, eseguire una query sull'archivio vettoriale per trovare i primi cento elementi i cui incorporamenti sono simili a quello dell'utente.
Il notebook di esempio seguente implementa l'addestramento del modello a due torri usando il set di dati "Learning from Sets of Items" per stimare la probabilità che un utente valuti positivamente un determinato film. Usa Mosaic StreamingDataset per il caricamento di dati distribuiti, TorchDistributor per il training del modello distribuito e MLflow per il rilevamento e la registrazione dei modelli.
Notebook del sistema di raccomandazione a due torri
Prendi il notebook
Questo notebook è disponibile anche in Databricks Marketplace: notebook del modello a due torri
Nota
- Gli input per il modello a due torri sono spesso le caratteristiche categoriche user_id e product_id. Il modello può essere modificato per supportare più vettori di funzionalità per utenti e prodotti.
- Gli output per il modello a due torri sono in genere valori binari che indicano se l'utente avrà un'interazione positiva o negativa con il prodotto. Il modello può essere modificato per altre applicazioni, ad esempio regressione, classificazione multiclasse e probabilità per più azioni utente( ad esempio, ignorare o acquistare). Gli output complessi devono essere implementati con attenzione, poiché gli obiettivi concorrenti possono ridurre la qualità degli incorporamenti generati dal modello.
Esempio: eseguire il training di un'architettura DLRM usando un set di dati sintetico
DLRM è un'architettura di rete neurale all'avanguardia progettata appositamente per i sistemi di personalizzazione e raccomandazione. Combina input categorici e numerici per modellare in modo efficace le interazioni degli elementi utente e stimare le preferenze utente. Le DLRM in genere prevedono input che includono funzionalità di tipo sparse (ad esempio ID utente, ID elemento, posizione geografica o categoria di prodotti) e funzionalità dense (ad esempio l'età dell'utente o il prezzo dell'articolo). L'output di un modello DLRM è in genere una stima del coinvolgimento degli utenti, ad esempio tassi di click-through o probabilità di acquisto.
Le DLRM offrono un framework altamente personalizzabile in grado di gestire dati su larga scala, rendendoli adatti per attività di raccomandazione complesse in vari domini. Poiché si tratta di un modello più grande rispetto all'architettura a due torri, questo modello viene spesso usato nella fase di reranking.
Il notebook di esempio seguente compila un modello DLRM per stimare le etichette binarie usando funzionalità dense (numeriche) e funzionalità sparse (categoriche). Usa un set di dati sintetico per eseguire il training del modello, il dataset Mosaic StreamingDataset per il caricamento dei dati distribuito, TorchDistributor per il training del modello distribuito e MLflow per il monitoraggio e il tracciamento dei modelli.
Notebook DLRM
Prendi il notebook
Questo notebook è disponibile anche nel Databricks Marketplace: notebook DLRM.
Confronto tra modelli a due torri e DLRM
La tabella mostra alcune linee guida per la selezione del modello di raccomandazione da usare.
| Tipo di modello | Dimensioni del set di dati necessarie per il training | Dimensioni del modello | Tipi di input supportati | Tipi di output supportati | Casi d'uso |
|---|---|---|---|---|---|
| Doppia torre | Più piccolo | Più piccolo | In genere due funzionalità (user_id, product_id) | Principalmente la classificazione binaria e la generazione di incorporamenti | Generazione di centinaia o migliaia di possibili raccomandazioni |
| DLRM | Maggiore | Maggiore | Varie caratteristiche categoriche e dense (ID utente, sesso, localizzazione geografica, ID prodotto, categoria prodotto, ...) | Classificazione multiclasse, regressione, altri | Sistema di recupero con granularità fine (consigliare decine di elementi ad alta rilevanza) |
In sintesi, il modello a due torri è meglio usato per generare migliaia di raccomandazioni di buona qualità in modo molto efficiente. Un esempio potrebbe essere rappresentato da raccomandazioni di film di un provider di cavi. Il modello DLRM è ideale per generare raccomandazioni molto specifiche in base a più dati. Un esempio può essere un rivenditore che vuole presentare a un cliente un numero inferiore di articoli che è altamente probabile acquistare.