Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Questo articolo descrive gli endpoint online per l'inferenza in tempo reale in Azure Machine Learning. L'inferenza è il processo di applicazione di nuovi dati di input a un modello di apprendimento automatico per generare output. Azure Machine Learning consente di eseguire l'inferenza in tempo reale sui dati usando modelli distribuiti negli endpoint online. Anche se questi output vengono in genere definiti previsioni, è possibile usare l'inferenza per generare output per altre attività di apprendimento automatico, come la classificazione e il clustering.
Endpoint online
Gli endpoint online distribuiscono i modelli a un server Web in grado di restituire stime con il protocollo HTTP. Gli endpoint online possono rendere operativi i modelli per l'inferenza in tempo reale in richieste sincrone a bassa latenza ed è consigliabile usarli quando:
- Si dispone di requisiti di bassa latenza.
- Il modello può rispondere alla richiesta in un periodo di tempo relativamente breve.
- Gli input del modello si adattano al payload HTTP della richiesta.
- È necessario aumentare il numero di richieste.
Per definire un endpoint, è necessario specificare:
- Nome dell'endpoint. Questo nome deve essere univoco nell'area di Azure. Per altri requisiti di denominazione, vedere Endpoint online ed endpoint batch di Azure Machine Learning.
- Modalità di autenticazione. È possibile scegliere tra la modalità di autenticazione basata su chiave, la modalità di autenticazione basata su token di Azure Machine Learning o l'autenticazione basata su token di Microsoft Entra per l'endpoint. Per altre informazioni sull'autenticazione, vedere Eseguire l'autenticazione di client per endpoint online.
Endpoint online gestiti
Gli endpoint online gestiti distribuiscono i modelli di Machine Learning in modo pratico e chiavi in mano e sono il modo consigliato per usare gli endpoint online di Azure Machine Learning. Funzionano con computer CPU e GPU potenti in Azure in modo scalabile e completamente gestito.
Questi endpoint si occupano anche di gestire, dimensionare, proteggere e monitorare i modelli, in modo da liberare l'utente dalle attività di configurazione e gestione dell'infrastruttura sottostante. Per informazioni su come definire endpoint online gestiti, vedere Definire l'endpoint.
Confronto tra endpoint online gestiti e Istanze di Azure Container o servizio Azure Kubernetes v1
Gli endpoint online gestiti sono il modo consigliato per usare gli endpoint online in Azure Machine Learning. La tabella seguente evidenzia gli attributi chiave degli endpoint online gestiti rispetto alle soluzioni Istanze di Azure Container e servizio Azure Kubernetes v1.
| Attributi | Endpoint online gestiti (v2) | Istanze di Container o servizio Azure Kubernetes (v1) |
|---|---|---|
| Sicurezza/Isolamento rete | Facile controllo in ingresso/in uscita con attivazione/disattivazione rapida | La rete virtuale non è supportata o richiede una configurazione manuale complessa |
| Servizio gestito | • Provisioning/ridimensionamento dell'ambiente di calcolo completamente gestito • Configurazione di rete per la prevenzione dell'esfiltrazione di dati • Aggiornamento del sistema operativo host, implementazione controllata degli aggiornamenti sul posto |
• Scalabilità limitata • L'utente deve gestire la configurazione o l'aggiornamento della rete |
| Concetto di endpoint/distribuzione | La distinzione tra endpoint e distribuzione consente scenari complessi, come l'implementazione sicura dei modelli | Nessun concetto di endpoint |
| Diagnostica e monitoraggio | • Debug dell'endpoint locale possibile con Docker e Visual Studio Code • Analisi avanzata delle metriche e dei log con grafico/query da confrontare tra le distribuzioni • Suddivisione dei costi fino al livello di distribuzione |
Nessun debug locale semplice |
| Scalabilità | Elastico e ridimensionamento automatico (non associato alle dimensioni predefinite del cluster) | • Istanze di Container non è scalabile • Il servizio Azure Kubernetes v1 supporta solo la scalabilità all'interno del cluster e richiede la configurazione della scalabilità |
| Soluzione pronta per l'azienda | Collegamento privato, chiavi gestite dal cliente, Microsoft Entra ID, gestione delle quote, integrazione della fatturazione, contratto di servizio | Non supportato |
| Funzionalità avanzate di Machine Learning | • Raccolta di dati del modello • Monitoraggio di modelli • Modello champion-challenger, implementazione sicura, mirroring del traffico • Estendibilità dell'intelligenza artificiale responsabile |
Non supportato |
Confronto tra endpoint online gestiti ed endpoint online Kubernetes
Se si preferisce usare Kubernetes per distribuire i modelli e gestire gli endpoint e si ha familiarità con la gestione dei requisiti dell'infrastruttura, è possibile usare gli endpoint online Kubernetes. Questi endpoint consentono di distribuire modelli e gestire endpoint online con CPU o GPU nel cluster Kubernetes completamente configurato e gestito ovunque.
Gli endpoint online gestiti possono semplificare il processo di distribuzione e offrire i vantaggi seguenti rispetto agli endpoint online Kubernetes:
Gestione automatica dell'infrastruttura
- Effettua il provisioning dell'ambiente di calcolo e ospita il modello. È sufficiente specificare il tipo di macchina virtuale e le impostazioni di scalabilità.
- Aggiorna e applica le patch all'immagine del sistema operativo host sottostante.
- Esegue il ripristino dei nodi in caso di errore del sistema.
Monitoraggio e log
- Possibilità di monitorare la disponibilità, le prestazioni e il contratto di servizio del modello grazie all'integrazione nativa con Monitoraggio di Azure.
- Facilità di debug delle distribuzioni tramite i log e l'integrazione nativa con Log Analytics.
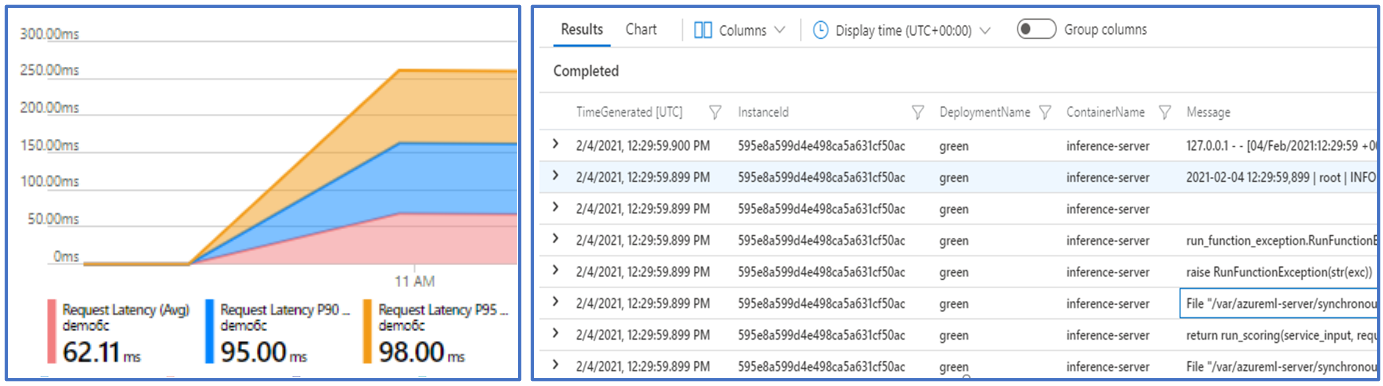
-

Nota
Gli endpoint online gestiti sono basati sull'ambiente di calcolo di Azure Machine Learning. Quando si usa un endpoint online gestito, si pagano i costi dell'ambiente di calcolo e di rete. Non c'è alcun supplemento aggiuntivo. Per altre informazioni sui prezzi, vedere Calcolatore prezzi di Azure.
Se si usa una rete virtuale di Azure Machine Learning per proteggere il traffico in uscita dall'endpoint online gestito, vengono addebitati i costi per il collegamento privato di Azure e le regole del nome di dominio completo (FQDN) in uscita usate dalla rete virtuale gestita. Per altre informazioni, vedere Prezzi per la rete virtuale gestita.


La tabella seguente evidenzia le differenze principali tra gli endpoint online gestiti e gli endpoint online Kubernetes.
| Endpoint online gestiti | Endpoint online Kubernetes (servizio Azure Kubernetes v2) | |
|---|---|---|
| Utenti consigliati | Utenti che vogliono una distribuzione di modelli gestita e un'esperienza MLOps migliorata | Utenti che preferiscono Kubernetes e possono gestire autonomamente i requisiti dell'infrastruttura |
| Provisioning dei nodi | Provisioning, aggiornamento e rimozione dell'ambiente di calcolo gestito | Responsabilità dell'utente |
| Manutenzione dei nodi | Aggiornamenti delle immagini del sistema operativo host gestito e protezione avanzata | Responsabilità dell'utente |
| Dimensionamento (ridimensionamento) del cluster | Manuale gestito e scalabilità automatica che supporta il provisioning di nodi aggiuntivo | Scalabilità automatica e manuale, con supporto del ridimensionamento del numero di repliche entro i limiti fissi del cluster |
| Tipo di ambiente di calcolo | Gestito dal servizio | Cluster Kubernetes gestito dal cliente |
| Identità gestita | Supportata | Supportata |
| Rete virtuale | Supportata tramite l'isolamento network gestito | Responsabilità dell'utente |
| Monitoraggio e registrazione predefiniti | Basati su Monitoraggio di Azure e Log Analytics, incluse metriche chiave e tabelle di log per endpoint e distribuzioni | Responsabilità dell'utente |
| Registrazione con Application Insights (legacy) | Supportata | Supportata |
| Visualizzazione costi | Dettagliati a livello di endpoint/distribuzione | Livello cluster |
| Costi applicati a | Macchine virtuali assegnate alla distribuzione | Macchine virtuali assegnate al cluster |
| Traffico con mirroring | Supportata | Non supportato |
| Distribuzione senza codice | Supporta modelli MLflow e Triton | Supporta modelli MLflow e Triton |
Distribuzioni online
Una distribuzione è un set di risorse e ambienti di calcolo necessari per ospitare il modello che esegue l'inferenza. Un singolo endpoint può contenere più distribuzioni con configurazioni diverse. Questa configurazione consente di separare l'interfaccia presentata dall'endpoint dai dettagli di implementazione presenti nella distribuzione. Un endpoint online ha un meccanismo di routing che può indirizzare le richieste a distribuzioni specifiche nell'endpoint.
Il diagramma seguente mostra un endpoint online con due distribuzioni, blu e verde. La distribuzione blu usa macchine virtuali con uno SKU CPU ed esegue la versione 1 di un modello. La distribuzione verde usa macchine virtuali con uno SKU GPU ed esegue la versione 2 del modello. L'endpoint è configurato per instradare il 90% del traffico in ingresso alla distribuzione blu, mentre la distribuzione verde riceve il rimanente 10%.
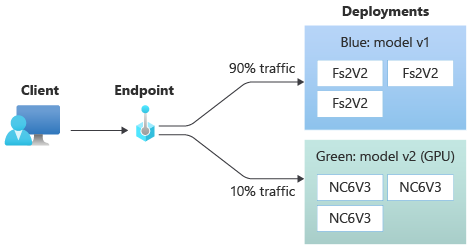
Per distribuire un modello, è necessario disporre di:
File di modello oppure il nome e la versione di un modello già registrato nell'area di lavoro.
Codice di script di assegnazione dei punteggi che esegue il modello in una determinata richiesta di input.
Lo script di assegnazione dei punteggi riceve i dati inviati a un servizio Web distribuito e lo passa al modello. Quindi, lo script esegue il modello e restituisce la risposta al client. Lo script di assegnazione dei punteggi è specifico del modello e deve comprendere i dati che il modello prevede come input e restituisce come output.
Un ambiente per eseguire il modello. L'ambiente può essere un'immagine Docker con dipendenze Conda o un Dockerfile.
Impostazioni per specificare il tipo di istanza e la capacità di ridimensionamento.
Per informazioni su come distribuire endpoint online usando l'interfaccia della riga di comando di Azure, Python SDK, studio di Azure Machine Learning o un modello di Resource Manager, vedere Distribuire un modello di Machine Learning usando un endpoint online.
Attributi chiave di una distribuzione
La tabella seguente descrive gli attributi chiave di una distribuzione:
| Attributo | Descrizione |
|---|---|
| Nome | Nome della distribuzione. |
| Nome endpoint | Nome dell'endpoint in cui creare la distribuzione. |
| Modello | Modello da usare per la distribuzione. Questo valore può essere un riferimento a un modello con controllo delle versioni esistente nell'area di lavoro o a una specifica del modello inline. Per altre informazioni su come tenere traccia e specificare il percorso del modello, vedere Specificare il modello da distribuire per l'uso nell'endpoint online. |
| Percorso del codice | Percorso della directory nell'ambiente di sviluppo locale che contiene tutto il codice sorgente Python per l'assegnazione del punteggio al modello. È possibile usare directory e pacchetti annidati. |
| Scoring script (Script di assegnazione punteggi) | Percorso relativo del file di punteggio nella directory del codice sorgente. Questo codice Python deve avere una funzione init() e una funzione run(). La funzione init() viene chiamata dopo la creazione o l'aggiornamento del modello, ad esempio per memorizzare nella cache il modello in memoria. La funzione run() viene chiamata a ogni chiamata dell'endpoint per eseguire l'assegnazione del punteggio e la stima effettive. |
| Ambiente | Ambiente in cui ospitare il modello e il codice. Questo valore può essere un riferimento a un ambiente con controllo delle versioni esistente nell'area di lavoro o a una specifica dell'ambiente inline. |
| Tipo di istanza | Dimensioni della macchina virtuale da usare per la distribuzione. Per l'elenco delle dimensioni supportate, vedere Elenco di SKU degli endpoint online gestiti. |
| Numero di istanze | Numero di istanze da usare per la distribuzione. Basare il valore sul carico di lavoro previsto. Per la disponibilità elevata, impostare il valore su almeno 3. Il sistema riserva un ulteriore 20% per l'esecuzione degli aggiornamenti. Per altre informazioni, vedere Allocazione della quota di macchine virtuali per le distribuzioni. |
Note per le distribuzioni online
La distribuzione può fare riferimento al modello e all'immagine del contenitore definita in Ambiente in qualsiasi momento, ad esempio quando le istanze di distribuzione vengono sottoposte a patch di sicurezza o altre operazioni di ripristino. Se si usa un modello o un'immagine del contenitore registrata in Registro Azure Container per la distribuzione e in un secondo momento si rimuove il modello o l'immagine del contenitore, le distribuzioni che si basano su questi asset possono riscontrare errori al momento della ricreazione dell'immagine. Se si rimuove il modello o l'immagine del contenitore, assicurarsi di ricreare o aggiornare le distribuzioni dipendenti con un modello o un'immagine del contenitore alternativa.
Il registro contenitori a cui fa riferimento l'ambiente può essere privato solo se l'identità dell'endpoint ha l'autorizzazione per accedervi tramite l'autenticazione di Microsoft Entra e il Controllo degli accessi in base al ruolo di Azure. Per lo stesso motivo, i registri Docker privati diversi da Registro Container non sono supportati.
Microsoft applica regolarmente patch alle immagini di base per le vulnerabilità di sicurezza note. È necessario ridistribuire l'endpoint per usare l'immagine con le patch. Se si usa la propria immagine, si è responsabili dell'aggiornamento. Per altre informazioni, vedere Applicazione delle patch all'immagine.
Allocazione della quota di macchine virtuali per la distribuzione
Per gli endpoint online gestiti, Azure Machine Learning riserva il 20% delle risorse di calcolo per l'esecuzione degli aggiornamenti in alcune SKU di VM. Se si richiede un determinato numero di istanze per gli SKU delle macchine virtuali in una distribuzione, è necessario che sia disponibile una quota per ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU disponibile per evitare che venga restituito un errore. Ad esempio, se si richiedono 10 istanze di una macchina virtuale Standard_DS3_v2 (fornita con quattro core) in una distribuzione, è necessario che sia disponibile una quota per 48 core (12 instances * 4 cores). Questa quota aggiuntiva è riservata alle operazioni avviate dal sistema, come gli aggiornamenti del sistema operativo e il ripristino delle macchine virtuali, e non comporta costi a meno che tali operazioni non vengano eseguite.
Esistono determinati SKU di VM esentati dalla prenotazione di quote aggiuntive. Per visualizzare l'elenco completo, vedere l'elenco degli SKU degli endpoint online gestiti. Per visualizzare gli incrementi relativi all'utilizzo e alla quota di richieste, vedere Visualizzare l'utilizzo e le quote nel portale di Azure. Per visualizzare i costi di esecuzione di un endpoint online gestito, vedere Visualizzare i costi per un endpoint online gestito.
Pool di quote condivise
Azure Machine Learning offre un pool di quote condivise da cui gli utenti in diverse aree possono accedere alla quota per eseguire test per un periodo di tempo limitato, a seconda della disponibilità. Quando si usa Studio per distribuire modelli Llama-2, Phi, Nemotron, Mistral, Dolly e Deci-DeciLM dal catalogo dei modelli a un endpoint online gestito, Azure Machine Learning consente di accedere al proprio pool di quote condivise per un breve periodo di tempo, in modo da poter eseguire la verifica. Per altre informazioni sul pool di quote condivise, vedere Quota condivisa di Azure Machine Learning.
Per distribuire modelli Llama-2, Phi, Nemotron, Mistral, Dolly e Deci-DeciLM dal catalogo dei modelli usando la quota condivisa, è necessario avere una sottoscrizione con Contratto Enterprise. Per altre informazioni su come usare la quota condivisa per la distribuzione di endpoint online, vedere Come distribuire i modelli di base usando Studio.
Per altre informazioni sulle quote e sui limiti per le risorse in Azure Machine Learning, vedere Gestire e aumentare quote e limiti per le risorse con Azure Machine Learning.
Distribuzione per utenti che scrivono codice e quelli che non scrivono codice
Azure Machine Learning supporta la distribuzione di modelli in endpoint online sia per utenti che scrivono codice sia per quelli che non scrivono codice, fornendo opzioni per la distribuzione senza codice, la distribuzione con poco codice e la distribuzione BYOC (Bring Your Own Container).
- La distribuzione senza codice fornisce l'inferenza predefinita per i framework comuni, ad esempio scikit-learn, TensorFlow, PyTorch e Open Neural Network Exchange (ONNX) tramite MLflow e Triton.
- La distribuzione con poco codice consente di fornire un codice minimo insieme al modello di Machine Learning per la distribuzione.
- La distribuzione BYOC consente di portare praticamente qualsiasi contenitore per eseguire l'endpoint online. È possibile usare tutte le funzionalità della piattaforma Azure Machine Learning, come scalabilità automatica, GitOps, debug e implementazione sicura per gestire le pipeline MLOps.
La tabella seguente illustra gli aspetti principali relativi alle opzioni di distribuzione online:
| Senza codice | Basso codice | BYOC | |
|---|---|---|---|
| Riepilogo | Usa l'inferenza predefinita per i framework più comuni come scikit-learn, TensorFlow, PyTorch e ONNX tramite MLflow e Triton. Per altre informazioni, vedere Distribuire modelli MLflow in endpoint online. | Usa immagini curate sicure pubblicate pubblicamente per i framework più comuni, con aggiornamenti ogni due settimane per risolvere le vulnerabilità. È possibile fornire script di assegnazione dei punteggi e/o dipendenze Python. Per altre informazioni, vedere Ambienti curati di Azure Machine Learning. | È possibile fornire lo stack completo tramite il supporto di Azure Machine Learning per le immagini personalizzate. Per altre informazioni, vedere Usare un contenitore personalizzato per distribuire un modello in un endpoint online. |
| Immagine di base personalizzata | Nessuno. Gli ambienti curati forniscono l'immagine di base per semplificare la distribuzione. | È possibile usare un'immagine curata o l'immagine personalizzata. | Usare un percorso di immagine del contenitore accessibile, ad esempio docker.io, Registro Container o Registro artefatti Microsoft, o un Dockerfile di cui è possibile eseguire la compilazione/push con Registro Container per il contenitore. |
| Dipendenze personalizzate | Nessuno. Gli ambienti curati forniscono dipendenze per semplificare la distribuzione. | Fornire l'ambiente di Azure Machine Learning in cui viene eseguito il modello, ovvero un'immagine Docker con dipendenze Conda o un Dockerfile. | Le dipendenze personalizzate sono incluse nell'immagine del contenitore. |
| Codice personalizzato | Nessuno. Lo script di assegnazione dei punteggi viene generato automaticamente per semplificare la distribuzione. | Fornire lo script di assegnazione dei punteggi. | Lo script di assegnazione dei punteggi è incluso nell'immagine del contenitore. |
Nota
AutoML esegue la creazione automatica di uno script di assegnazione dei punteggi e dipendenze per gli utenti. Per la distribuzione senza codice, è possibile distribuire qualsiasi modello di AutoML senza creare altro codice. Per la distribuzione con poco codice, è possibile modificare gli script generati automaticamente in base alle esigenze aziendali. Per informazioni su come eseguire la distribuzione con i modelli di AutoML, vedere Come distribuire un modello di AutoML con un endpoint online.
Debug degli endpoint online
Se possibile, testare l'endpoint in locale per convalidare ed eseguire il debug del codice e della configurazione prima di procedere alla distribuzione in Azure. L'interfaccia della riga di comando di Azure e Python SDK supportano endpoint e distribuzioni locali, mentre lo studio di Azure Machine Learning e i modelli ARM non supportano endpoint o distribuzioni locali.
Azure Machine Learning offre i modi seguenti per eseguire il debug degli endpoint online in locale e usando i log dei contenitori:
- Debug locale con il server HTTP di inferenza di Azure Machine Learning
- Debug locale con endpoint locale
- Debug locale con endpoint locale e Visual Studio Code
- Debug con i log dei contenitori
Debug locale con il server HTTP di inferenza di Azure Machine Learning
È possibile eseguire il debug dello script di assegnazione dei punteggi in locale usando il server HTTP di inferenza di Azure Machine Learning. Il server HTTP è un pacchetto Python che espone la funzione di assegnazione del punteggio come endpoint HTTP ed esegue il wrapping del codice e delle dipendenze del server Flask in un singolo pacchetto.
Azure Machine Learning include un server HTTP nelle immagini Docker predefinite per l'inferenza usate per distribuire un modello. Usando il pacchetto da solo, è possibile distribuire il modello in locale per la produzione ed è anche possibile convalidare facilmente lo script di assegnazione dei punteggi delle voci in un ambiente di sviluppo locale. Se si verifica un problema con lo script di assegnazione dei punteggi, il server restituisce un errore e la posizione in cui si è verificato l'errore. È anche possibile usare Visual Studio Code per eseguire il debug con il server HTTP di inferenza di Azure Machine Learning.
Suggerimento
È possibile usare il pacchetto Python del server HTTP di inferenza di Azure Machine Learning per eseguire il debug dello script di assegnazione dei punteggi in locale senza il motore Docker. Il debug con il server di inferenza consente di eseguire il debug dello script di assegnazione dei punteggi prima della distribuzione negli endpoint locali in modo che sia possibile eseguire il debug senza subire l'impatto delle configurazioni del contenitore di distribuzione.
Per altre informazioni sul debug con il server HTTP, vedere Eseguire il debug dello script di assegnazione dei punteggi con il server HTTP di inferenza di Azure Machine Learning.
Debug locale con endpoint locale
Per il debug locale, è necessario un modello distribuito in un ambiente Docker locale. È possibile usare questa distribuzione locale per il test e il debug prima della distribuzione nel cloud.
Per eseguire la distribuzione in locale, è necessario che il motore Docker sia installato e in esecuzione. Azure Machine Learning crea quindi un'immagine Docker locale per simulare l'immagine online. Azure Machine Learning crea ed esegue le distribuzioni per l'utente in locale e memorizza nella cache l'immagine per iterazioni rapide.
Suggerimento
Se il motore Docker non viene avviato all'avvio del computer, è possibile risolvere i problemi del motore Docker. È possibile usare strumenti lato client, come Docker Desktop per eseguire il debug degli eventi nel contenitore.
Il debug locale prevede in genere i passaggi seguenti:
- Verificare prima di tutto la corretta esecuzione della distribuzione locale.
- Richiamare quindi l'endpoint locale per l'inferenza.
- Esaminare infine i log di output per l'operazione
invoke.
Gli endpoint locali presentano le limitazioni seguenti:
Nessun supporto per le regole di traffico, l'autenticazione o le impostazioni del probe.
Supporto per una sola distribuzione per endpoint.
Supporto per file di modello e ambiente locali solo con file Conda locale.
Per testare i modelli registrati, prima di tutto scaricarli usando l'interfaccia della riga di comando o l'SDK, quindi usare
pathnella definizione della distribuzione per fare riferimento alla cartella padre.Per testare gli ambienti registrati, verificare il contesto dell'ambiente nello studio di Azure Machine Learning e preparare un file Conda locale da usare.
Per altre informazioni sul debug locale, vedere Distribuire ed eseguire il debug in locale usando un endpoint locale.
Debug locale con endpoint locale e Visual Studio Code (anteprima)
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Analogamente al debug locale, è necessario che il motore Docker sia installato e in esecuzione e quindi occorre distribuire un modello nell'ambiente Docker locale. Dopo aver creato una distribuzione locale, gli endpoint locali di Azure Machine Learning usano i contenitori di sviluppo Docker e Visual Studio Code (contenitori di sviluppo) per creare e configurare un ambiente di debug locale.
Con i contenitori di sviluppo è possibile usare le funzionalità di Visual Studio Code, come il debug interattivo, dall'interno di un contenitore Docker. Per altre informazioni sul debug interattivo degli endpoint online in Visual Studio Code, vedere Eseguire il debug degli endpoint online in locale in Visual Studio Code.
Debug con i log dei contenitori
Non è possibile ottenere l'accesso diretto a una macchina virtuale in cui viene distribuito un modello, ma è possibile ottenere i log dai contenitori seguenti in esecuzione nella macchina virtuale:
- Il log della console del server di inferenza contiene l'output delle funzioni di stampa/registrazione dal codie dello script di assegnazione dei punteggi score.py.
- I log dell'inizializzatore di archiviazione contengono informazioni che specificano se il codice e i dati del modello sono stati scaricati correttamente nel contenitore. Il contenitore viene eseguito prima dell'avvio dell'esecuzione del contenitore del server di inferenza.
Per altre informazioni sul debug con i log dei contenitori, vedere Ottenere i log dei contenitori.
Routing e mirroring del traffico verso distribuzioni online
Un singolo endpoint online può avere più distribuzioni. Quando l'endpoint riceve richieste di traffico in ingresso, può instradare percentuali di traffico a ogni distribuzione, come nella strategia nativa di distribuzione blu/verde. L'endpoint può anche eseguire il mirroring o la copia del traffico da una distribuzione a un'altra, operazione denominata mirroring o shadowing del traffico.
Routing del traffico per la distribuzione blu/verde
La distribuzione blu/verde è una strategia di distribuzione che consente di implementare una nuova distribuzione verde in un piccolo subset di utenti o richieste prima di implementarla completamente. L'endpoint può implementare il bilanciamento del carico per allocare determinate percentuali del traffico a ogni distribuzione, con l'allocazione totale in tutte le distribuzioni che raggiunge il 100%.
Suggerimento
Una richiesta può ignorare il bilanciamento del carico del traffico configurato includendo un'intestazione HTTP di azureml-model-deployment. Impostare il valore dell'intestazione sul nome della distribuzione a cui si vuole indirizzare la richiesta.
L'immagine seguente mostra le impostazioni nello studio di Azure Machine Learning per allocare il traffico tra una distribuzione blu e una verde.
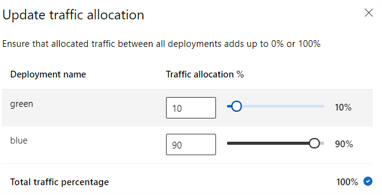
L'allocazione del traffico precedente instrada il 10% del traffico alla distribuzione verde e il 90% del traffico verso la distribuzione blu, come illustrato nell'immagine seguente.
Mirroring del traffico verso distribuzioni online
L'endpoint può anche eseguire il mirroring o la copia del traffico da una distribuzione a un'altra. È possibile usare il mirroring del traffico, detto anche shadow testing, quando si vuole testare una nuova distribuzione con traffico di produzione senza influire sui risultati che i clienti ricevono dalle distribuzioni esistenti.
Ad esempio, è possibile implementare una distribuzione blu/verde in cui il 100% del traffico viene instradato alla distribuzione blu e viene eseguito il mirroring del 10% del traffico alla distribuzione verde. I risultati del traffico con mirroring verso la distribuzione verde non vengono restituiti ai client, ma viene eseguita la registrazione di metriche e log.
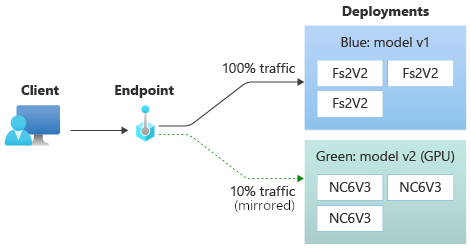
Per altre informazioni su come usare il mirroring del traffico, vedere Eseguire l'implementazione sicura delle nuove distribuzioni per l'inferenza in tempo reale.
Altre funzionalità degli endpoint online
Le sezioni seguenti descrivono altre funzionalità degli endpoint online di Azure Machine Learning.
Autenticazione e crittografia
- Autenticazione: chiave e token di Azure Machine Learning
- Identità gestita: assegnata dall'utente e assegnata dal sistema
- SSL (Secure Socket Layer) per impostazione predefinita per la chiamata all'endpoint
Scalabilità automatica
La scalabilità automatica usa automaticamente la quantità corretta di risorse per gestire il carico dell'applicazione. Gli endpoint gestiti supportano la scalabilità automatica tramite l'integrazione con la funzionalità di scalabilità automatica di Monitoraggio di Azure. È possibile configurare la scalabilità basata su metriche, ad esempio l'utilizzo della CPU > 70%, il ridimensionamento basato su pianificazione, ad esempio le regole basate sugli di orari lavorativi di punta, o usare entrambi gli approcci.

Per altre informazioni, vedere Ridimensionare automaticamente gli endpoint online in Azure Machine Learning.
Isolamento network gestito
Quando si distribuisce un modello di Machine Learning in un endpoint online gestito, è possibile proteggere la comunicazione con l'endpoint online usando endpoint privati. È possibile configurare la sicurezza per le richieste di assegnazione dei punteggi in ingresso e le comunicazioni in uscita separatamente.
Le comunicazioni in ingresso usano l'endpoint privato dell'area di lavoro di Azure Machine Learning, mentre le comunicazioni in uscita usano gli endpoint privati creati per la rete virtuale gestita dell'area di lavoro. Per altre informazioni, vedere Isolamento di rete con gli endpoint online gestiti.
Monitoraggio di endpoint e distribuzioni online
Gli endpoint di Azure Machine Learning si integrano con Monitoraggio di Azure. L'integrazione di Monitoraggio di Azure consente di visualizzare le metriche nei grafici, configurare avvisi, eseguire query nelle tabelle di log e usare Application Insights per analizzare gli eventi dai contenitori utente. Per altre informazioni, vedere Monitorare gli endpoint online.
Inserimento di segreti nelle distribuzioni online (anteprima)
L'inserimento di segreti per una distribuzione online comporta il recupero di segreti come le chiavi API dagli archivi di segreti e il relativo inserimento nel contenitore utente eseguito all'interno della distribuzione. Per fornire un utilizzo sicuro dei segreti per il server di inferenza che esegue lo script di assegnazione dei punteggi o lo stack di inferenza nella distribuzione BYOC, è possibile usare le variabili di ambiente per accedere ai segreti.
È possibile inserire i segreti manualmente usando le identità gestite oppure è possibile usare la funzionalità di inserimento dei segreti. Per altre informazioni, vedere Inserimento di segreti negli endpoint online (anteprima).
Contenuto correlato
- Distribuire e assegnare un punteggio a un modello di Machine Learning usando un endpoint online
- Endpoint batch
- Proteggere gli endpoint online gestiti con l'isolamento rete
- Distribuire modelli con REST
- Monitorare gli endpoint online
- Visualizzare i costi per un endpoint online gestito di Azure Machine Learning
- Gestire e aumentare le quote e i limiti per le risorse con Azure Machine Learning