Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo è destinato agli sviluppatori che necessitano di una comprensione più approfondita della composizione del set di competenze e presuppone la familiarità con i concetti generali di arricchimento tramite intelligenza artificiale o intelligenza artificiale applicata in Ricerca di intelligenza artificiale di Azure.
Un set di competenze è un oggetto riutilizzabile in Azure AI Search collegato a un indicizzatore. Questo contiene una o più competenze che richiedono l'intelligenza artificiale predefinita o l'elaborazione personalizzata esterna sui documenti recuperati da una origine dati esterna.
Il diagramma seguente illustra il flusso di dati di base dell'esecuzione del set di competenze.
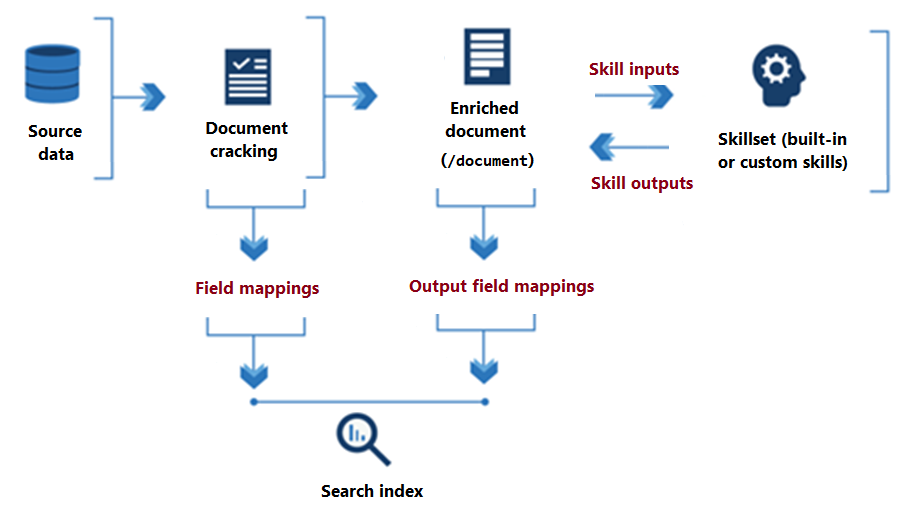
Dall'inizio dell'elaborazione del set di competenze alla sua conclusione, le competenze leggono e scrivono in un documento arricchito presente in memoria. Inizialmente, un documento arricchito è solo il contenuto non elaborato estratto da un'origine dati (articolato come "/document" nodo radice). Con ogni esecuzione delle competenze, il documento arricchito ottiene struttura e sostanza man mano che ogni competenza scrive l'output come nodi nel grafo.
Al termine dell'esecuzione del set di competenze, l'output di un documento arricchito viene inserito in un indice tramite mapping dei campi di output definite dall'utente. Qualsiasi contenuto grezzo che si desidera trasferire intatto, dall’origine a un indice, viene definito tramite mapping dei campi. Al contrario, i mapping dei campi di output trasferisce il contenuto in memoria (nodi) all'indice.
Per configurare l'intelligenza artificiale applicata, specificare le impostazioni in un set di competenze e un indicizzatore.
Definizione del set di competenze
Un set di competenze è una matrice di una o più competenze che eseguono un arricchimento, ad esempio la traduzione di testo o il riconoscimento ottico dei caratteri (OCR) in un file di immagine. Le competenze possono essere le competenze predefinite di Microsoft o le competenze personalizzate per la logica di elaborazione ospitata esternamente. Un set di competenze produce documenti arricchiti utilizzati durante l'indicizzazione o proiettati in un archivio conoscenze.
Le competenze presentano un contesto, input e output:
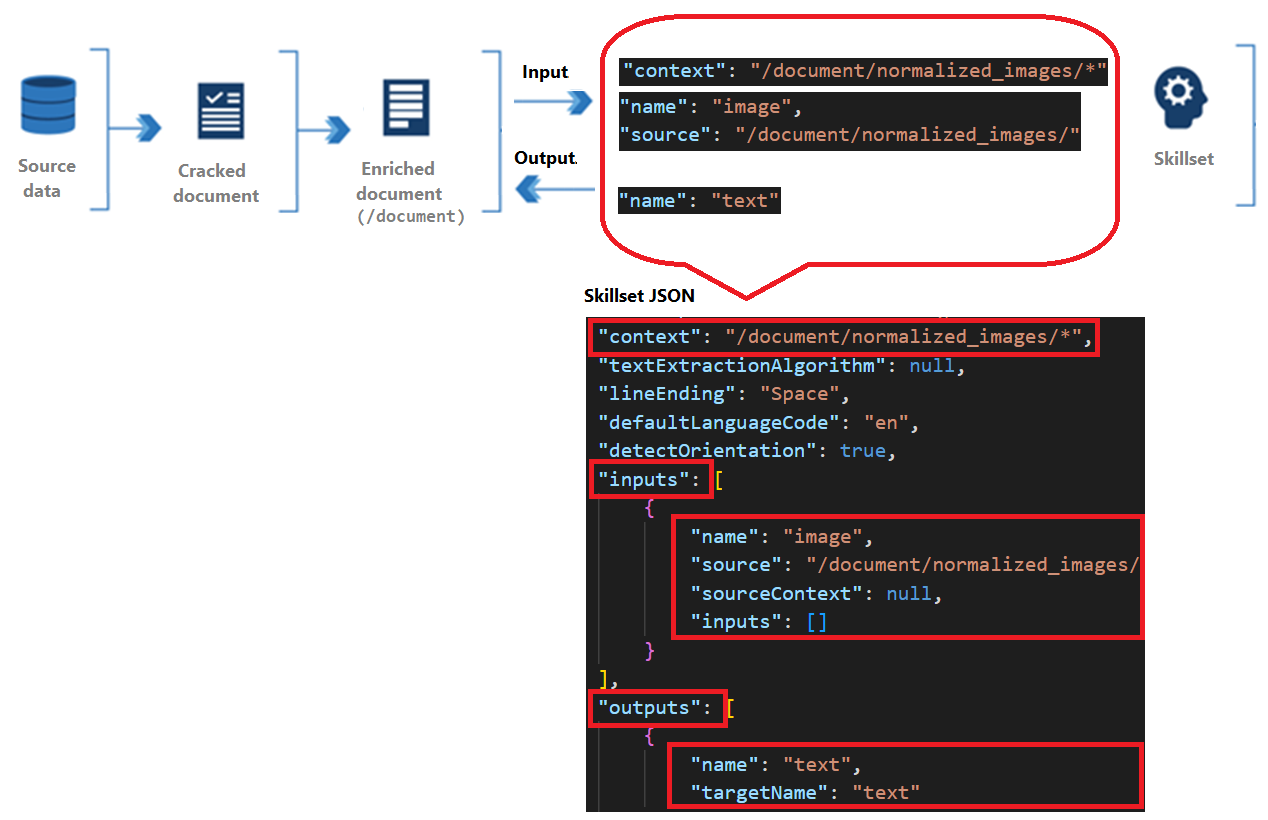
Il contesto fa riferimento all'ambito dell'operazione, che può essere una volta per ogni documento o una volta per ogni elemento in una raccolta.
Gli input provengono dai nodi in un documento arricchito, in cui una "origine" e un "nome" identificano un determinato nodo.
L'output viene restituito al documento arricchito come nuovo nodo. I valori sono il contenuto del nodo e il "nome" del nodo. Se un nome di nodo è duplicato, è possibile impostare un nome di destinazione per la disambiguazione.
Contesto della competenza
Ogni competenza presenta un contesto, che può essere l'intero documento (/document) o un nodo inferiore nell'albero (/document/countries/*).
Un contesto determina:
Numero di volte in cui la competenza viene eseguita su un singolo valore (una volta per campo, per documento) o per una raccolta, in cui l'aggiunta di
/*comporta una chiamata di competenza per ogni istanza della raccolta.Dichiarazione di output o dove nell'albero di arricchimento vengono aggiunti gli output della competenza. Gli output vengono sempre aggiunti all'albero come elementi figlio del nodo di contesto.
Forma degli input. Per le raccolte multilivello, l'impostazione del contesto sulla raccolta padre influirà sulla forma dell'input per la competenza. Ad esempio, nel caso di un albero di arricchimento con un elenco di paesi/aree, ognuno arricchito con un elenco di stati contenente un elenco di codici di avviamento postale, come si imposta il contesto determina la modalità di interpretazione dell'input.
Contesto Input Forma dell'input Chiamata della competenza /document/countries/*/document/countries/*/states/*/zipcodes/*Elenco di tutti i codici di avviamento postale nel paese/area Una volta per paese/area /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Elenco di codici di avviamento postale nello stato Una volta per ogni combinazione di paese/area e stato
Dipendenze delle competenze
Le competenze possono essere eseguite in modo indipendente e in parallelo o in sequenza se si inserisce l'output di una competenza in un'altra competenza. L'esempio seguente illustra due competenze predefinite eseguite in sequenza:
La competenza n. 1 è una competenza di Suddivisione del testo, che accetta il contenuto del campo di origine "reviews_text" come input e suddivide il contenuto in "pagine" di 5.000 caratteri come output. La suddivisione di testo di grandi dimensioni in blocchi più piccoli può produrre risultati migliori per competenze come il rilevamento della valutazione.
La competenza n. 2 è una competenza Rilevamento della valutazione, che accetta "pagine" come input e produce un nuovo campo denominato "Valutazione" come output, che contiene i risultati dell'analisi della valutazione.
Si noti che l'output della prima competenza ("pagine") viene usato nell'analisi della valutazione, dove "/document/reviews_text/pages/*" è sia il contesto che l'input. Per altre informazioni sulla formulazione del percorso, vedere Come fare riferimento agli arricchimenti.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Albero di arricchimento
Un documento arricchito è una struttura di dati temporanea e simile ad albero creata durante l'esecuzione del set di competenze che raccoglie tutte le modifiche introdotte tramite le competenze. Collettivamente, gli arricchimenti sono rappresentati come una gerarchia di nodi indirizzabili. I nodi includono anche tutti i campi non arricchiti che vengono trasmessi alla lettera dalla fonte dati esterna.
Un documento arricchito esiste per la durata dell'esecuzione del set di competenze, ma può essere memorizzato nella cache o inviato a un archivio conoscenze.
Inizialmente, un documento arricchito è semplicemente il contenuto estratto da un'origine dati durante il cracking di documenti, in cui il testo e le immagini vengono estratti dall'origine e resi disponibili per l'analisi della lingua o dell'immagine.
Il contenuto iniziale è costituito dai metadati e dal nodo radice (document/content). Il nodo radice è in genere un intero documento o un'immagine normalizzata estratta da un'origine dati durante il cracking di documenti. Il modo in cui viene articolato in un albero di arricchimento varia per ogni tipo di origine dati. La tabella seguente illustra lo stato di un documento che entra nella pipeline di arricchimento per diverse origini dati supportate:
| Origine dati/modalità di analisi | Predefiniti | JSON, righe JSON e CSV |
|---|---|---|
| Archiviazione BLOB | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
N/D |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
N/D |
Durante l'esecuzione delle competenze, l'output viene aggiunto all'albero di arricchimento come nuovi nodi. Se l'esecuzione delle competenze si trova sull'intero documento, i nodi vengono aggiunti al primo livello sotto radice.
I nodi possono essere usati come input per le competenze downstream. Ad esempio, le competenze che creano contenuto, ad esempio stringhe tradotte, possono diventare input per competenze che riconoscono le entità o estraggono frasi chiave.
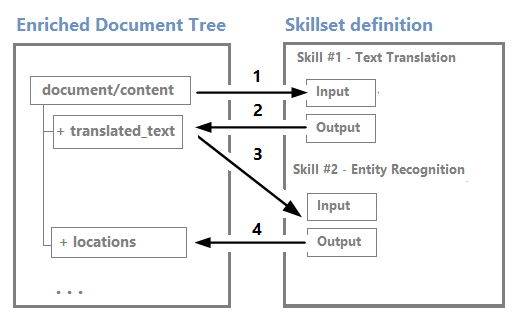
Sebbene sia possibile visualizzare e usare un albero di arricchimento tramite l'editor visivo Sessioni di debug, si tratta principalmente di una struttura interna.
Gli arricchimenti non sono modificabili: una volta creati, i nodi non possono essere modificati. Un albero di arricchimento diventa complesso contestualmente ai set di competenze, ma non tutti i nodi dell'albero di arricchimento devono necessariamente raggiungere l'indice o l'archivio conoscenze.
È possibile rendere persistente in modo selettivo solo un subset degli output di arricchimento in modo da mantenere solo ciò che si intende usare. I mapping dei campi di output nella definizione dell'indicizzatore determinano il contenuto effettivamente inserito nell'indice di ricerca. Analogamente, se si sta creando un archivio conoscenze, è possibile eseguire il mapping degli output in forme assegnate alle proiezioni.
Nota
Il formato albero di arricchimento consente alla pipeline di arricchimento di collegare metadati anche ai tipi di dati primitivi. I metadati non saranno un oggetto JSON valido, ma possono essere proiettati in un formato JSON valido nelle definizioni di proiezione in un archivio conoscenze. Per altre informazioni, vedere Competenza shaper.
Definizione di indicizzatore
Un indicizzatore dispone di proprietà e parametri usati per configurare l'esecuzione dell'indicizzatore. Tra queste proprietà sono presenti mapping che impostano il percorso dei dati sui campi in un indice di ricerca.

Esistono due set di mapping:
"fieldMappings" esegue il mapping di un campo di origine a un campo di ricerca.
"outputFieldMappings" esegue il mapping di un nodo in un documento arricchito a un campo di ricerca.
La proprietà "sourceFieldName" specifica un campo nell'origine dati o un nodo in un albero di arricchimento. La proprietà "targetFieldName" specifica il campo di ricerca in un indice che riceve il contenuto.
Esempio di arricchimento
Usando il set di competenze di recensioni di hotel come punto di riferimento, questo esempio spiega come un albero di arricchimento si evolve attraverso l'esecuzione delle competenze usando diagrammi concettuali.
Questo esempio mostra anche:
- in che modo il contesto e gli input di un'abilità funzionano per determinare quante volte un'abilità viene eseguita
- qual è la forma dell'input in base al contesto
In questo esempio, i campi di origine di un file CSV includono recensioni dei clienti su hotel ("reviews_text") e valutazioni ("reviews_rating"). L'indicizzatore aggiunge campi di metadati dall'archiviazione BLOB e le competenze aggiungono testo tradotto, punteggi di valutazioni e rilevamento frasi chiave.
Nell'esempio di recensioni di hotel, un "documento" all'interno del processo di arricchimento rappresenta una singola revisione dell'hotel.
Suggerimento
È possibile creare un indice di ricerca e un archivio conoscenze per questi dati nel portale di Azure o nelle API REST. È anche possibile usare Sessioni di debug per informazioni dettagliate sulla composizione, le dipendenze e gli effetti del set di competenze su un albero di arricchimento. Le immagini in questo articolo vengono estratte dalle Sessioni di debug.
Concettualmente, l'albero di arricchimento iniziale è simile al seguente:

Il nodo radice per tutti gli arricchimenti è "/document". Quando si lavora con gli indicizzatori BLOB, il nodo "/document" ha nodi figli "/document/content" e "/document/normalized_images". Quando i dati sono CSV, come in questo esempio, i nomi delle colonne vengono mappati ai nodi sotto "/document".
Competenza n. 1: Suddivisione della competenza
Quando il contenuto di origine è costituito da blocchi di testo di grandi dimensioni, è utile suddividerlo in componenti più piccoli per la vettorializzazione integrata o per una maggiore accuratezza della lingua, del sentiment e del rilevamento delle frasi chiave. Sono disponibili due intervalli: pagine e frasi. Una pagina è costituita da circa 5.000 caratteri.
Un'alternativa alla suddivisione in blocchi con la competenza Dividi consiste nell'usare la competenza Layout documento, ma tale competenza non rientra nell'ambito di questo articolo.
Quando è necessaria la suddivisione in blocchi, la competenza Split è in genere la prima in un set di competenze.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Con il contesto della competenza "/document/reviews_text", la competenza divisa viene eseguita una volta per reviews_text. L'output della competenza è un elenco in cui reviews_text è suddiviso in segmenti di 5.000 caratteri. L'output della competenza di divisione è denominato pages e viene aggiunto all'albero di arricchimento. La funzionalità targetName consente di rinominare l'output di una competenza prima che venga aggiunto all'albero di arricchimento.
L'albero di arricchimento dispone ora di un nuovo nodo inserito nel contesto della competenza. Questo nodo è disponibile per il mapping dei campi di qualsiasi competenza, proiezione o output.

Per accedere a uno qualsiasi degli arricchimenti aggiunti a un nodo da una competenza, è necessario il percorso completo per l'arricchimento. Se ad esempio si vuole usare il testo del nodo pages come input per un'altra competenza, specificarlo come "/document/reviews_text/pages/*". Per altre informazioni sui percorsi, vedere Arricchimenti di riferimento.
Competenza n. 2: rilevamento della lingua
I documenti di revisione degli hotel includono il feedback dei clienti espresso in più lingue. La competenza di rilevamento della lingua determina quale lingua viene usata. Il risultato verrà quindi passato all'estrazione di frasi chiave e al rilevamento della valutazione (non visualizzato), prendendo in considerazione la lingua durante il rilevamento di valutazione e frasi.
Sebbene la competenza di rilevamento della lingua sia la terza (n. 3) definita, è quella successiva da eseguire. Non richiede alcun input in modo che venga eseguito in parallelo con la competenza precedente. Analogamente alla competenza di divisione che la precede, anche la competenza di rilevamento della lingua viene richiamata una volta per ogni documento. L'albero di arricchimento dispone ora di un nuovo nodo per la lingua.

Competenze n. 3 e 4 (analisi valutazione e rilevamento frasi chiave)
Il feedback dei clienti riflette una gamma di esperienze positive e negative. La competenza di analisi valutazione analizza il feedback e assegna un punteggio lungo un continuum di numeri da negativi a positivi, o punteggio neutro se la valutazione non è determinata. Parallela all'analisi valutazione, il rilevamento delle frasi chiave identifica ed estrae parole e frasi brevi che appaiono consequenziali.
Dato il contesto /document/reviews_text/pages/*, sia l'analisi valutazione che le competenze chiave di frase vengono richiamate una volta per ognuno degli elementi nella raccolta pages. L'output della competenza sarà un nodo nell'elemento di pagina associato.
A questo punto dovrebbe essere possibile esaminare il resto delle competenze nel set di competenze e visualizzare il modo in cui l'albero di arricchimento cresce con l'esecuzione di ogni competenza. Alcune competenze, come quella di unione e dello shaper, creano nuovi nodi, ma usano solo i dati provenienti da nodi esistenti e non creano nuovi arricchimenti.

I colori dei connettori nell'albero sopra indicato rilevano che gli arricchimenti sono stati creati da competenze diverse e che i nodi devono essere risolti singolarmente e non faranno parte dell'oggetto restituito quando si seleziona il nodo padre.
Competenza n. 5 Competenza shaper
Se l'output include un archivio conoscenze, aggiungere una competenza Shaper come ultimo passaggio. La competenza Shaper crea forme di dati fuori dai nodi in un albero di arricchimento. Ad esempio, è possibile consolidare più nodi in una singola forma. È quindi possibile proiettare questa forma come tabella (i nodi diventano le colonne di una tabella), passando la forma in base al nome a una proiezione di tabella.
La competenza Shaper è facile da usare perché è incentrata sulla forma in un'unica competenza. In alternativa, è possibile optare per il data shaping in linea all'interno di singole proiezioni. La competenza shaper non aggiunge o detrae da un albero di arricchimento, quindi non viene visualizzata. È invece possibile pensare a una competenza Shaper come ai mezzi mediante cui si riprogetta l'albero di arricchimento già presente. Concettualmente, si tratta di una procedura simile alla creazione di viste da tabelle in un database.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Passaggi successivi
Con l’introduzione e l’esempio precedenti, provare a creare il primo set di competenze usando competenze predefinite.