Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione consente di accelerare il processo di valutazione per Data Factory in Microsoft Fabric fornendo i passaggi per uno scenario di integrazione completa dei dati entro un'ora. Al termine di questa esercitazione si comprende il valore e le funzionalità chiave di Data Factory e si è appreso come completare uno scenario di integrazione dei dati end-to-end comune.
Lo scenario è suddiviso in un'introduzione e tre moduli:
- Introduzione all'esercitazione e al motivo per cui è consigliabile usare Data Factory in Microsoft Fabric.
- Modulo 1: Creare una pipeline con Data Factory per inserire dati non elaborati da un archivio BLOB a una tabella del livello dati bronze in una data Lakehouse.
- Modulo 2: Trasformare i dati con un flusso di dati in Data Factory per elaborare i dati non elaborati dalla tabella bronze e spostarli in una tabella livello dati gold in Data Lakehouse.
- Modulo 3: Completare il primo percorso di integrazione dei dati e inviare un messaggio di posta elettronica per notificare il completamento di tutti i processi e infine configurare l'intero flusso per l'esecuzione in base a una pianificazione.
Perché Data Factory in Microsoft Fabric?
Microsoft Fabric offre una singola piattaforma per tutte le esigenze analitiche di un'azienda. Include lo spettro di analisi, tra cui lo spostamento dei dati, i data lake, la progettazione dei dati, l'integrazione dei dati, l'analisi scientifica dei dati, l'analisi in tempo reale e l'intelligence aziendale. Con Fabric non è necessario unire servizi diversi da più fornitori. Gli utenti godono invece di un prodotto completo che è facile da comprendere, creare, caricare e gestire.
Data Factory in Fabric combina la facilità d'uso di Power Query con la scalabilità e la potenza di Azure Data Factory. Offre il meglio di entrambi i prodotti in un'unica esperienza. L'obiettivo è che gli sviluppatori di dati cittadini e professionisti abbiano gli strumenti di integrazione dei dati appropriati. Data Factory offre esperienze di preparazione e trasformazione dei dati abilitate per intelligenza artificiale con poco codice, trasformazione su scala petabyte e centinaia di connettori con connettività ibrida e multicloud.
Tre funzionalità chiave di Data Factory
- Inserimento dati: L'attività di copia nelle pipeline (o il processo di copia autonomo) consente di spostare i dati su scala petabyte da centinaia di origini dati in Data Lakehouse per un'ulteriore elaborazione.
- Trasformazione e preparazione dei dati: Dataflow Gen2 offre un'interfaccia a basso codice per trasformare i dati usando più di 300 trasformazioni di dati, con la possibilità di caricare i risultati trasformati in più destinazioni, ad esempio database SQL di Azure, Lakehouse e altro ancora.
- Automazione end-to-end: Le pipeline forniscono l'orchestrazione delle attività che includono attività di copia, flusso di dati e notebook e altro ancora. Le attività in una pipeline possono essere concatenate per funzionare in modo sequenziale o indipendentemente in parallelo. L'intero flusso di integrazione dei dati viene eseguito automaticamente e può essere monitorato in un'unica posizione.
Architettura del tutorial
Nei prossimi 50 minuti verranno illustrate tutte e tre le funzionalità principali di Data Factory durante il completamento di uno scenario di integrazione dei dati end-to-end.
Lo scenario è suddiviso in tre moduli:
- Modulo 1: Creare una pipeline con Data Factory per inserire dati non elaborati da un archivio BLOB a una tabella del livello dati bronze in una data Lakehouse.
- Modulo 2: Trasformare i dati con un flusso di dati in Data Factory per elaborare i dati non elaborati dalla tabella bronze e spostarli in una tabella livello dati gold in Data Lakehouse.
- Modulo 3: Completare il primo percorso di integrazione dei dati e inviare un messaggio di posta elettronica per notificare il completamento di tutti i processi e infine configurare l'intero flusso per l'esecuzione in base a una pianificazione.
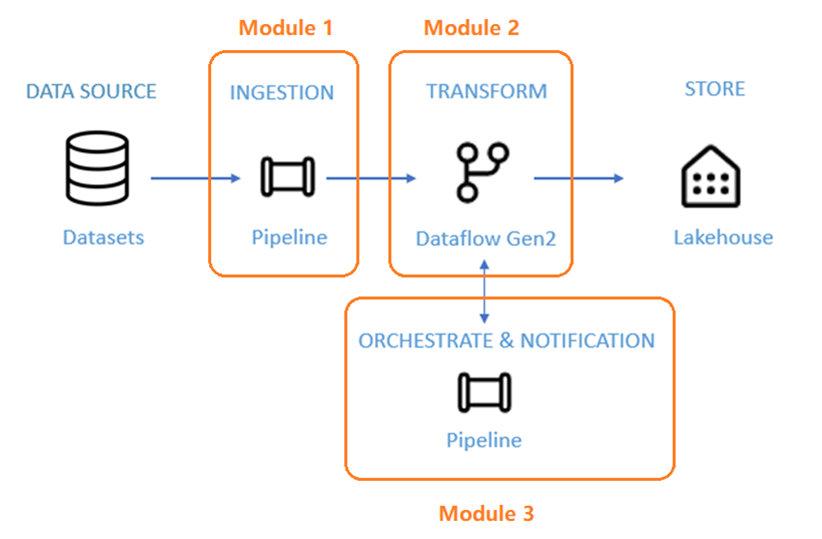 Diagramma del flusso di dati e dei moduli dell'esercitazione.
Diagramma del flusso di dati e dei moduli dell'esercitazione.
Si utilizza il set di dati di esempio NYC-Taxi come origine dati per l'esercitazione. Al termine, sarà possibile ottenere informazioni dettagliate sugli sconti giornalieri sulle tariffe dei taxi per un periodo di tempo specifico usando Data Factory in Microsoft Fabric.
Passo successivo
Passare alla sezione successiva per configurare la pipeline.