Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione presenta un esempio end-to-end di un flusso di lavoro di data science Synapse in Microsoft Fabric. Usa sia la risorsa dati nycflights13 che R, per prevedere se un aereo arriva più di 30 minuti di ritardo. Usa quindi i risultati della stima per creare un dashboard interattivo di Power BI.
In questa esercitazione apprenderai a:
Usare pacchetti tidymodels
- ricette
- pastinaca
- rsample
- flussi di lavoro per elaborare i dati ed eseguire il training di un modello di Machine Learning
Scrivi i dati di uscita nella lakehouse come una tabella delta
Creare un report visivo di Power BI per accedere direttamente ai dati in tale lakehouse
Prerequisiti
Ottieni una sottoscrizione a Microsoft Fabric. In alternativa, iscriviti per una prova gratuita di Microsoft Fabric.
Accedi a Microsoft Fabric.
Passare a Fabric usando il commutatore dell'esperienza in basso a sinistra della tua home page.

Aprire o creare un notebook. Per imparare come, vedere Come usare i notebook di Microsoft Fabric.
Impostare l'opzione del linguaggio su SparkR (R) per modificare il linguaggio primario.
Collega il notebook a un lakehouse. Nel lato sinistro, selezionare Aggiungi per aggiungere un lakehouse esistente o creare un lakehouse.
Installare i pacchetti
Installare il pacchetto nycflights13 per usare il codice in questa esercitazione.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Esplora i dati
I dati nycflights13 contengono informazioni su 325.819 voli arrivati vicino a New York nel 2013. Prima di tutto, esaminare la distribuzione dei ritardi dei voli. La cella di codice seguente genera un grafico che mostra che la distribuzione del ritardo di arrivo è asimmetrica a destra.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Ha una coda lunga nei valori alti, come illustrato nell'immagine seguente:
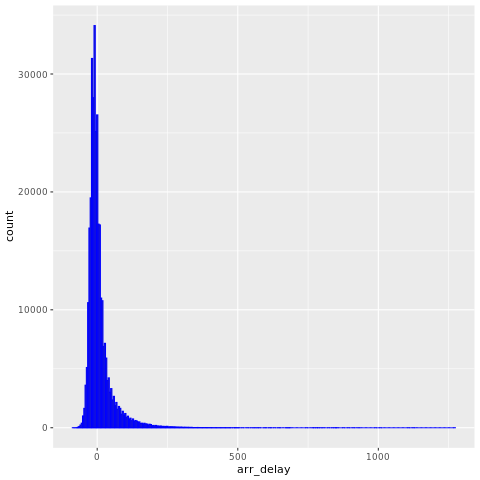 Screenshot che mostra un grafico dei ritardi dei voli.
Screenshot che mostra un grafico dei ritardi dei voli.
Caricare i dati e apportare alcune modifiche alle variabili:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Prima di compilare il modello, considerare alcune variabili specifiche che hanno importanza sia per la pre-elaborazione che per la modellazione.
La arr_delay variabile è una variabile di fattore. Per il training del modello di regressione logistica, è importante che la variabile di risultato sia una variabile di fattore.
glimpse(flight_data)
Circa 16% dei voli in questo set di dati sono arrivati più di 30 minuti in ritardo:
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
La dest funzionalità include 104 destinazioni di volo:
unique(flight_data$dest)
Esistono 16 vettori distinti:
unique(flight_data$carrier)
Suddividere i dati
Dividere l'unico insieme di dati in due insiemi: un insieme di training e un insieme di test. Mantenere la maggior parte delle righe nel set di dati originale (come sottoinsieme scelto in modo casuale) nel set di dati di addestramento. Usare il set di dati di training per adattare il modello e usare il set di dati di test per misurare le prestazioni del modello.
Utilizzare il pacchetto rsample per creare un oggetto contenente informazioni su come suddividere i dati. Quindi, usa altre due funzioni rsample per creare dataframes per i set di training e test:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Creare una ricetta e definire i ruoli
Creare una ricetta per un semplice modello di regressione logistica. Prima di eseguire il training del modello, usare una ricetta per creare nuovi predittori ed eseguire la pre-elaborazione richiesta dal modello.
Usare la update_role() funzione , con un ruolo personalizzato denominato ID, in modo che le ricette conoscano che flight e time_hour sono variabili. Un ruolo può avere qualsiasi valore di carattere. La formula include tutte le variabili nel set di training come predittori, ad eccezione di arr_delay. La ricetta mantiene queste due variabili ID, ma non le usa come risultati o predittori:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Per visualizzare il set corrente di variabili e ruoli, usare la funzione summary().
summary(flights_rec)
Creare caratteristiche
La progettazione delle funzionalità può migliorare il modello. La data del volo potrebbe avere un effetto ragionevole sulla probabilità di arrivo in ritardo:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Può essere utile aggiungere termini del modello, derivati dalla data, che hanno un'importanza potenziale per il modello. Derivare le funzionalità significative seguenti dalla singola variabile di data:
- Giorno della settimana
- Mese
- Indica se la data corrisponde o meno a una festività
Aggiungere i tre passaggi alla ricetta:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Adattare un modello con una ricetta
Usare la regressione logistica per modellare i dati dei voli. Prima di tutto, costruire una specifica del modello con il pacchetto parsnip.
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Utilizzare il pacchetto workflows per integrare il modello parsnip (lr_mod) con la ricetta flights_rec:
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Eseguire l'addestramento del modello
Questa funzione può preparare la ricetta ed eseguire il training del modello dai predittori risultanti:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Usare le funzioni ausiliarie xtract_fit_parsnip()extract_fit_parsnip()xtract_fit_parsnip() e extract_recipe() per estrarre gli oggetti modello o ricetta dal flusso di lavoro. In questo esempio, estrarre l'oggetto modello adattato, quindi usare la funzione broom::tidy() per ottenere una tibble ordinata dei coefficienti del modello.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Stimare i risultati
Una singola chiamata a predict() utilizza il flusso di lavoro addestrato (flights_fit) per fare previsioni con i dati di test non visti. Il predict() metodo applica la ricetta ai nuovi dati, quindi passa i risultati al modello adattato.
predict(flights_fit, test_data)
Ottieni l'output da predict() per restituire la classe prevista: late rispetto a on_time. Tuttavia, per le probabilità della classe stimata per ogni volo, usare augment() con il modello, in combinazione con i dati di test, per salvarle insieme:
flights_aug <-
augment(flights_fit, test_data)
Rivedere i dati:
glimpse(flights_aug)
Valutare il modello
È ora disponibile una variabile con le probabilità della classe stimata. Nelle prime poche righe, il modello ha previsto correttamente cinque voli puntuali (i valori di .pred_on_time sono p > 0.50). Tuttavia, sono necessarie stime per un totale di 81.455 righe.
È necessaria una metrica che indica in che modo il modello ha stimato gli arrivi in ritardo, rispetto al vero stato della variabile di arr_delay risultato.
AUC è l'area sottesa alla curva ROC (Receiver Operating Characteristic). Calcolarlo con roc_curve() e roc_auc(), dal pacchetto yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Creare un report Power BI
Il risultato del modello sembra buono. Usare i risultati della stima dei ritardi dei voli per creare una dashboard interattiva di Power BI. La dashboard mostra il numero di voli per vettore e il numero di voli per destinazione. Il pannello può filtrare in base ai risultati della previsione di ritardo.

Includere il nome del vettore e il nome dell'aeroporto nel set di dati dei risultati della stima:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Rivedere i dati:
glimpse(flights_clean)
Convertire i dati a un DataFrame Spark:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Scrivi i dati in una tabella delta nel tuo lakehouse.
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Usare la tabella delta per creare un modello semantico.
Nel riquadro di spostamento a sinistra selezionare l'area di lavoro, e nella casella di testo in alto a destra immettere il nome della lakehouse associata al tuo notebook. Lo screenshot seguente mostra che è stata selezionata l'area di lavoro personale:
Immettere il nome della lakehouse che hai collegato al tuo notebook. Immettere test_lakehouse1, come illustrato nello screenshot seguente:
Nell'area dei risultati filtrati selezionare la lakehouse, come illustrato nello screenshot seguente:
Screenshot che mostra una lakehouse selezionata.
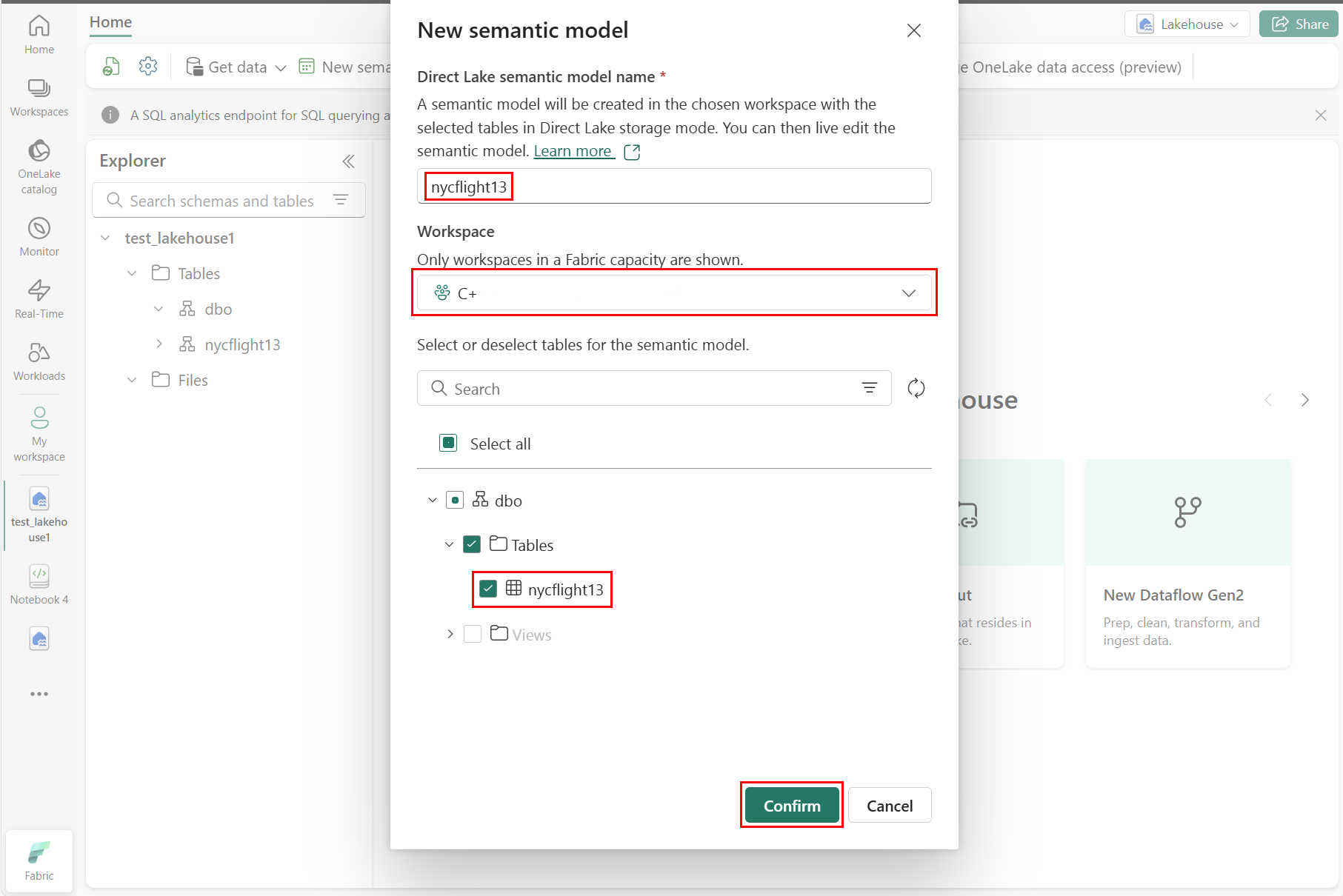
Selezionare Nuovo modello semantico come illustrato nello screenshot seguente:
Nel riquadro Nuovo modello semantico immettere un nome per il nuovo modello semantico, selezionare un'area di lavoro e selezionare le tabelle da usare per il nuovo modello, quindi selezionare Conferma, come illustrato nello screenshot seguente:
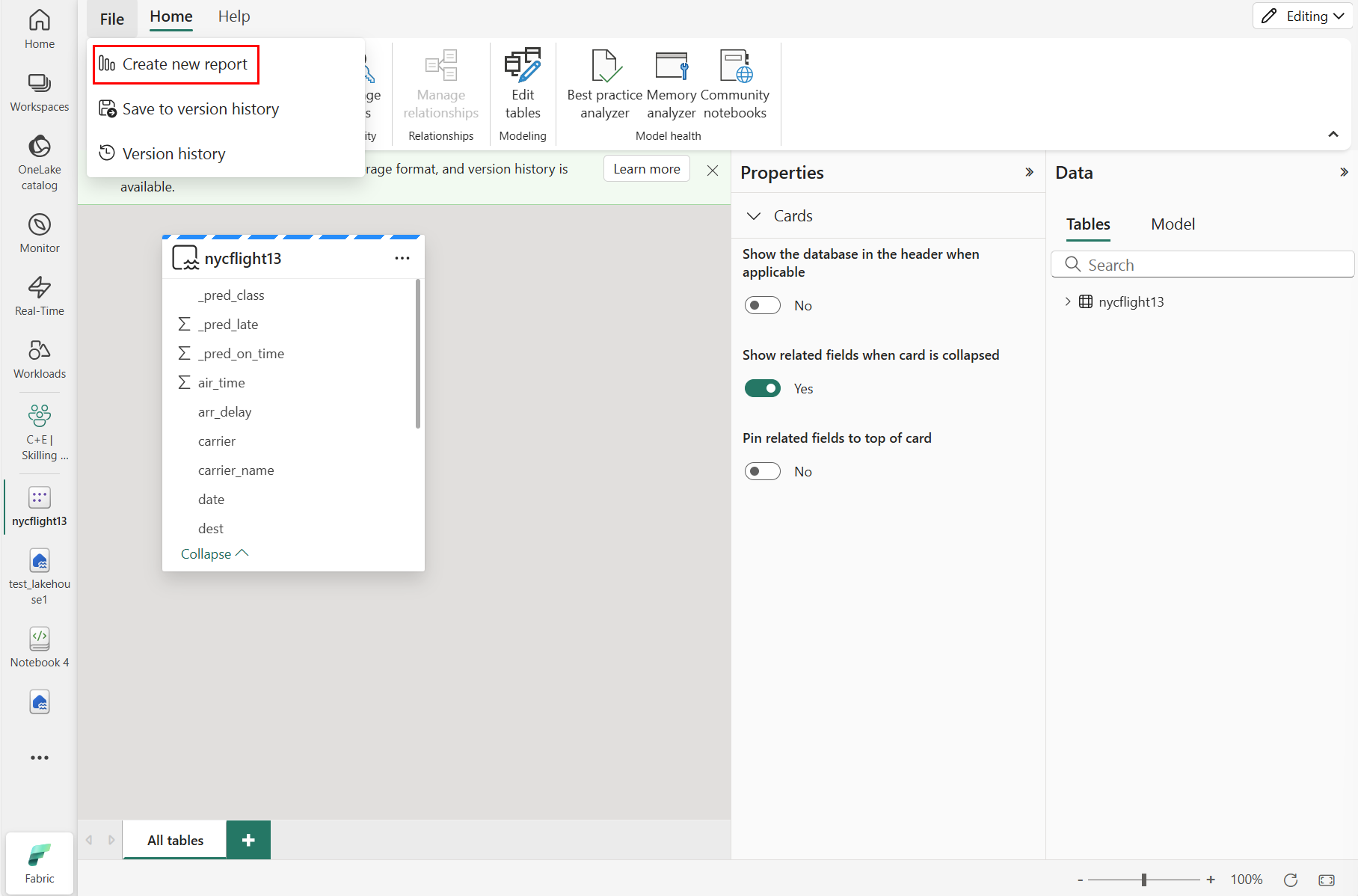
Per creare un nuovo report, selezionare Crea nuovo report, come illustrato nello screenshot seguente:
Selezionare o trascinare i campi dai riquadri Dati e Visualizzazioni nell'area di disegno del report per compilare il report
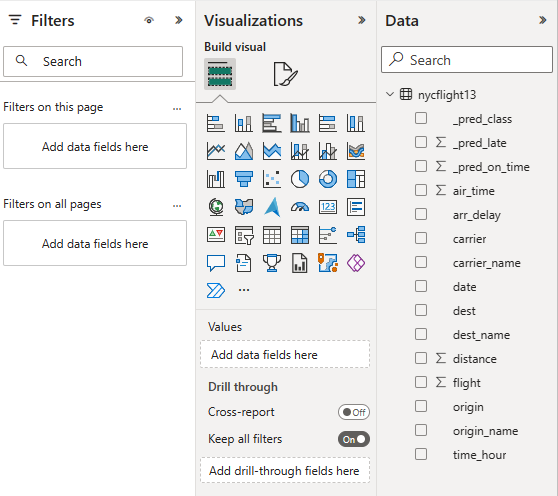 Screenshot che mostra i dettagli di dati e visualizzazione per un report.
Screenshot che mostra i dettagli di dati e visualizzazione per un report.





Per creare il report visualizzato all'inizio di questa sezione, usare queste visualizzazioni e dati:
 Grafico a barre in pila con:
Grafico a barre in pila con: - Asse Y: carrier_name
- Asse X: volo. Seleziona Conteggio per l'aggregazione
- Legenda: origin_name
- Grafico a barre in pila con:
- Asse Y: dest_name
- Asse X: volo. Seleziona Conteggio per l'aggregazione
- Legenda: origin_name
 Slicer con:
Slicer con: - Campo: _pred_class
- Slicer con:
- Campo: _pred_late
Contenuto correlato
- Come usare SparkR
- Come usare sparklyr
- Come usare Tidyverse
- Gestione della libreria R
- Visualizza i dati in R
- Esercitazione: usare R per fare una previsione del prezzo dell’avocado