Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
si applica a:✅ Magazzino di dati in Microsoft Fabric
Questa esercitazione ti guida nella configurazione di dbt e nella distribuzione del tuo primo progetto in una Fabric Warehouse.
Introduction
Il framework open source dbt (Strumento di compilazione dati) semplifica la trasformazione dei dati e la progettazione dell'analisi. Si concentra sulle trasformazioni basate su SQL all'interno del livello di analisi, considerando SQL come codice. dbt supporta il controllo della versione, la modularizzazione, il test e la documentazione.
L'adapter dbt per Microsoft Fabric può essere usato per creare progetti dbt, che possono quindi essere distribuiti in un data warehouse di Fabric.
È anche possibile modificare la piattaforma di destinazione per il progetto dbt semplicemente modificando l'adattatore, ad esempio; Un progetto creato per il pool SQL dedicato di Azure Synapse può essere aggiornato in pochi secondi a un'istanza di Fabric Data Warehouse.
Prerequisiti per l'adapter dbt per Microsoft Fabric
Seguire questo elenco per installare e configurare i prerequisiti dbt:
Versione più recente dell'adattatore dbt-fabric dal repository PyPI (Indice pacchetti Python) utilizzando
pip install dbt-fabric.pip install dbt-fabricNote
Cambiare
pip install dbt-fabricinpip install dbt-synapsee, utilizzando le istruzioni seguenti, è possibile installare l'adapter dbt per il pool SQL dedicato di Synapse.Assicurarsi di verificare che dbt-fabric e le relative dipendenze siano installati tramite il
pip listcomando :pip listUn lungo elenco dei pacchetti e delle versioni correnti deve essere restituito da questo comando.
Se non ne hai già uno, crea un magazzino. È possibile usare la capacità di valutazione per questo esercizio: iscriversi alla versione di valutazione gratuita di Microsoft Fabric, creare un'area di lavoro e quindi creare un magazzino.
Introduzione all'adapter dbt-fabric
Questa esercitazione usa Visual Studio Code, ma è possibile usare lo strumento di vostra scelta.
Clonare il progetto demo dbt jaffle_shop nel computer.
- È possibile clonare un repository con il controllo del codice sorgente predefinito di Visual Studio Code.
- In alternativa, ad esempio, è possibile usare il
git clonecomando :
git clone https://github.com/dbt-labs/jaffle-shop-classic.gitAprire la cartella del
jaffle_shopprogetto in Visual Studio Code.
Se è già stato creato un warehouse, è possibile ignorare l'iscrizione.
Creare un file
profiles.yml. Aggiungere la configurazione seguente aprofiles.yml. Questo file configura la connessione al warehouse in Microsoft Fabric usando l'adapter dbt-fabric.config: partial_parse: true jaffle_shop: target: fabric-dev outputs: fabric-dev: authentication: CLI database: <put the database name here> driver: ODBC Driver 18 for SQL Server host: <enter your SQL analytics endpoint here> schema: dbo threads: 4 type: fabricNote
Modificare il
typedafabricasynapseper passare l'adattatore di database ad Azure Synapse Analytics, se desiderato. È possibile aggiornare qualsiasi piattaforma dati del progetto dbt esistente modificando l'adattatore di database. Per altre informazioni, vedere l'elenco dbt delle piattaforme dati supportate.Eseguire l'autenticazione in Azure nel terminale di Visual Studio Code.
- Eseguire
az loginnel terminale di Visual Studio Code se si usa l'autenticazione dell'interfaccia della riga di comando di Azure. - Per l'autenticazione di un'entità servizio o di un altro ID Microsoft Entra (in precedenza Azure Active Directory) in Microsoft Fabric, fare riferimento alla configurazione di dbt (Strumento di compilazione dati) e alle configurazioni delle risorse dbt. Per altre informazioni, vedere Autenticazione di Microsoft Entra come alternativa all'autenticazione SQL di Microsoft Fabric.
- Eseguire
A questo momento si è pronti per testare la connettività. Per testare la connettività al warehouse, eseguire
dbt debugnel terminale di Visual Studio Code.dbt debug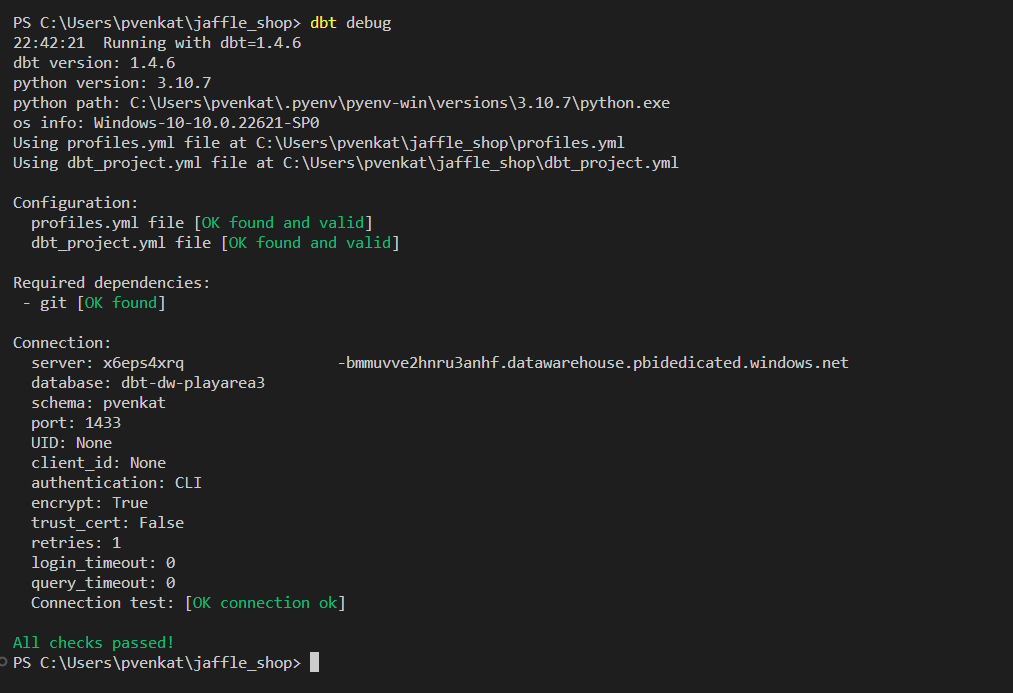
Tutti i controlli sono superati, il che significa che è possibile connettere il magazzino usando l'adattatore dbt-fabric dal progetto dbt
jaffle_shop.È ora possibile verificare se l'adattatore funziona o meno. Eseguire prima
dbt seedper inserire dati di esempio nel magazzino.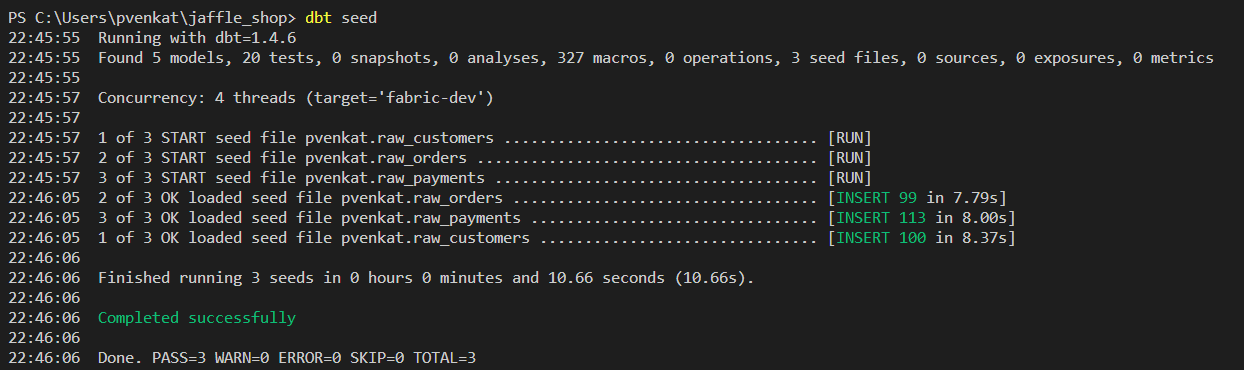
Eseguire
dbt runper eseguire i modelli definiti nel progetto demo dbt.dbt run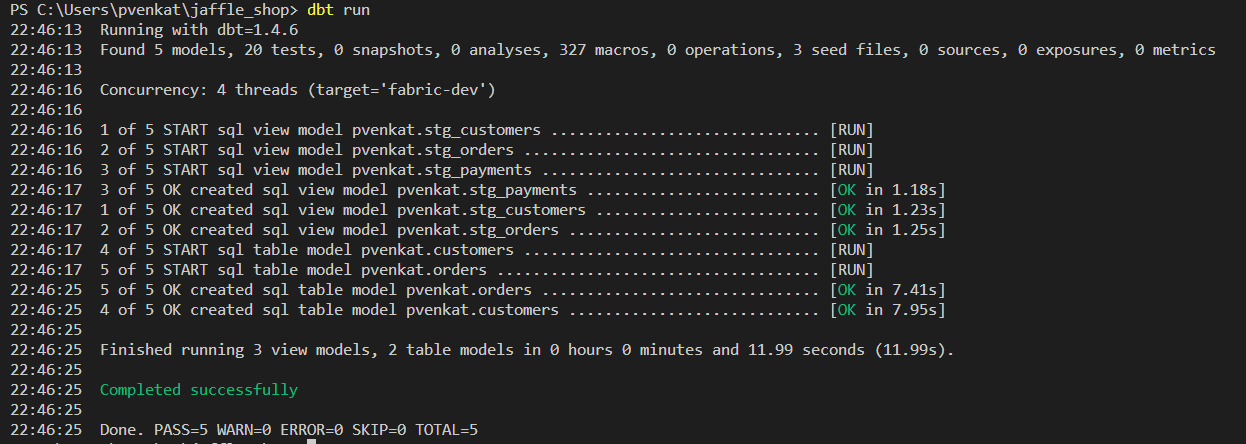
Eseguire
dbt testper convalidare i dati in base ad alcuni test.dbt test




È stato ora distribuito un progetto dbt in Fabric Data Warehouse.
Spostarsi tra magazzini diversi
È semplice spostare il progetto dbt tra magazzini diversi. È possibile eseguire rapidamente la migrazione di un progetto dbt in qualsiasi warehouse supportato con questo processo in tre passaggi:
Installare la nuova scheda. Per altre informazioni e istruzioni di installazione complete, vedere adapter dbt.
Aggiornare la
typeproprietà nelprofiles.ymlfile.Costruisci il progetto.
dbt in Fabric Data Factory
Se integrato con Apache Airflow, un sistema di gestione dei flussi di lavoro diffuso, dbt diventa uno strumento potente per orchestrare le trasformazioni dei dati. Le funzionalità di pianificazione e gestione delle attività di Airflow consentono ai team di dati di automatizzare le esecuzioni dbt. Garantisce aggiornamenti regolari dei dati e mantiene un flusso coerente di dati di alta qualità per l'analisi e la creazione di report. Questo approccio combinato, usando l'esperienza di trasformazione di dbt con la gestione del flusso di lavoro di Airflow, offre pipeline efficienti e affidabili, portando infine a decisioni più rapide e dettagliate basate sui dati.
Apache Airflow è una piattaforma open source usata per creare, pianificare e monitorare flussi di lavoro di dati complessi a livello di codice. Consente di definire un set di attività, denominate operatori, che possono essere combinati in grafici aciclici diretti (DAG) per rappresentare le pipeline.
Per altre informazioni sull'operazionalizzazione di dbt con il warehouse, vedere Trasformare i dati usando dbt con Data Factory in Microsoft Fabric.
Considerazioni
Aspetti importanti da considerare quando si usa l'adapter dbt-fabric:
Esaminare le limitazioni correnti del data warehousing di Microsoft Fabric.
Fabric supporta l'autenticazione di Microsoft Entra ID (in precedenza Azure Active Directory) per le entità utente, le identità utente e le entità servizio. La modalità di autenticazione consigliata per lavorare in modo interattivo nel data warehouse è l'uso di CLI (interfaccia della riga di comando) e delle entità servizio per l'automazione.
Esaminare i comandi T-SQL (Transact-SQL) non supportati nel Fabric Data Warehouse.
Alcuni comandi T-SQL sono supportati dall'adapter dbt-fabric usando
Create Table as Select(CTAS),DROPeCREATEcomandi, ad esempioALTER TABLE ADD/ALTER/DROP COLUMN,MERGE,TRUNCATE, .sp_renameVedere Tipi di dati non supportati per informazioni sui tipi di dati supportati e non supportati.
È possibile registrare i problemi nell'adapter dbt-fabric in GitHub visitando Problemi · microsoft/dbt-fabric · GitHub.