Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo è destinato a professionisti IT e responsabili IT. Verranno fornite informazioni sull'architettura della soluzione BI nel COE e sulle diverse tecnologie usate. Le tecnologie includono Azure, Power BI ed Excel. Insieme, possono essere sfruttati per offrire una piattaforma di business intelligence cloud scalabile e basata sui dati.
La progettazione di una solida piattaforma BI è un po' come la creazione di un ponte; un bridge che connette i dati di origine trasformati e arricchiti ai consumer di dati. La progettazione di una struttura così complessa richiede una mentalità di ingegneria, anche se può essere una delle architetture IT più creative e gratificanti che è possibile progettare. In un'organizzazione di grandi dimensioni, un'architettura di soluzione di BI può essere composta da:
- Origini dati
- Inserimento dati
- Preparazione dei Big Data / preparazione dei dati
- Magazzino dati
- Modelli semantici BI
- Rapporti
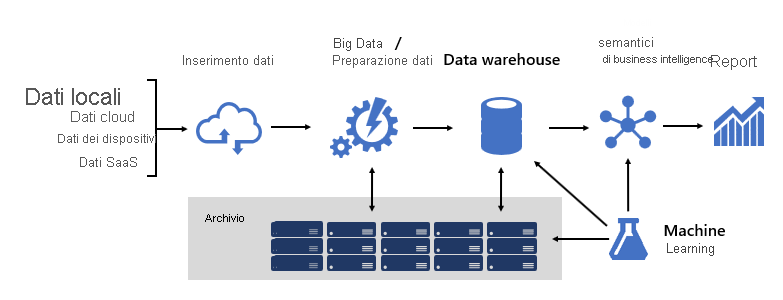
La piattaforma deve supportare richieste specifiche. In particolare, deve scalare e funzionare per soddisfare le aspettative dei servizi aziendali e dei consumatori di dati. Allo stesso tempo, deve essere sicuro fin dalle basi. E deve essere sufficientemente resiliente per adattarsi al cambiamento, perché è una certezza che nel tempo devono essere portati online nuovi dati e aree soggette.
Frameworks
Presso Microsoft, fin dall'inizio abbiamo adottato un approccio sistemico investendo nello sviluppo di framework. I framework dei processi tecnici e aziendali aumentano il riutilizzo della progettazione e della logica e offrono un risultato coerente. Offrono anche flessibilità nell'architettura sfruttando molte tecnologie e semplificano e riducono il sovraccarico di progettazione tramite processi ripetibili.
Abbiamo appreso che i framework ben progettati aumentano la visibilità sulla tracciabilità dei dati, sull'analisi dell'impatto, sulla manutenzione della logica di business, sulla gestione della tassonomia e sulla semplificazione della governance. Inoltre, lo sviluppo è diventato più veloce e la collaborazione tra team di grandi dimensioni è diventata più reattiva ed efficace.
In questo articolo verranno descritti diversi framework.
Modelli di dati
I modelli di dati consentono di controllare la struttura e l'accesso ai dati. Per i servizi aziendali e i consumer di dati, i modelli di dati sono la loro interfaccia con la piattaforma BI.
Una piattaforma bi può offrire tre diversi tipi di modelli:
- Modelli aziendali
- Modelli semantici BI
- Modelli di Machine Learning (ML)
Modelli aziendali
I modelli aziendali vengono creati e gestiti dagli architetti IT. Vengono talvolta definiti modelli dimensionali o data mart. In genere, i dati vengono archiviati in formato relazionale come tabelle delle dimensioni e dei fatti. Queste tabelle archiviano dati puliti e arricchiti consolidati da molti sistemi e rappresentano un'origine autorevole per la creazione di report e l'analisi.
I modelli aziendali offrono un'unica fonte di dati coerente per la creazione di report e Business Intelligence. Vengono compilati una volta e condivisi come standard aziendale. I criteri di governance garantiscono la sicurezza dei dati, quindi l'accesso a set di dati sensibili, ad esempio informazioni sui clienti o finanziari, è limitato in base alle esigenze. Adottano convenzioni di denominazione che garantiscono la coerenza, stabilendo così ulteriormente la credibilità dei dati e della qualità.
In una piattaforma di BI cloud, i modelli aziendali possono essere implementati in un pool Synapse SQL in Azure Synapse. Il pool SYNapse SQL diventa quindi la singola versione della verità su cui l'organizzazione può contare per ottenere informazioni rapide e affidabili.
Modelli semantici di Business Intelligence
I modelli semantici BI rappresentano un livello semantico sui modelli aziendali. Vengono compilati e gestiti da sviluppatori di business intelligence e utenti aziendali. Gli sviluppatori di business intelligence creano modelli semantici bi di base che originano i dati dai modelli aziendali. Gli utenti aziendali possono creare modelli indipendenti a scala ridotta oppure possono estendere modelli semantici di base BI con origini di reparto o esterne. I modelli semantici bi si concentrano in genere su una singola area di interesse e sono spesso ampiamente condivisi.
Le funzionalità aziendali non sono abilitate solo dai dati, ma da modelli semantici bi che descrivono concetti, relazioni, regole e standard. In questo modo, rappresentano strutture intuitive e facili da comprendere che definiscono le relazioni tra i dati e incapsulano le regole business come calcoli. Possono anche applicare autorizzazioni dettagliate per i dati, garantendo agli utenti giusti l'accesso ai dati corretti. In particolare, accelerano le prestazioni delle query, offrendo analisi interattive estremamente reattive, anche oltre terabyte di dati. Analogamente ai modelli aziendali, i modelli semantici bi adottano convenzioni di denominazione per garantire la coerenza.
In una piattaforma BI cloud, gli sviluppatori BI possono distribuire modelli semantici BI in Azure Analysis Services, nelle capacità di Power BI Premium o nelle capacità di Microsoft Fabric.
Importante
Questo articolo si riferisce a Power BI Premium o alle relative sottoscrizioni di capacità (SKU P). Attualmente, Microsoft sta consolidando le opzioni di acquisto e ritirerà gli SKU di Power BI Premium per capacità specifiche. I clienti nuovi ed esistenti dovrebbero invece prendere in considerazione l'acquisto di sottoscrizioni di capacità Fabric (SKU F).
Per altre informazioni, vedere Aggiornamento importante disponibile per le licenze Power BI Premium e Domande frequenti su Power BI Premium.
È consigliabile eseguire la distribuzione in Power BI quando viene usata come livello di report e analisi. Questi prodotti supportano diverse modalità di archiviazione, consentendo alle tabelle del modello di dati di memorizzare nella cache i dati o di usare DirectQuery, una tecnologia che passa le query all'origine dati sottostante. DirectQuery è una modalità di archiviazione ideale quando le tabelle del modello rappresentano volumi di dati di grandi dimensioni o è necessario fornire risultati quasi in tempo reale. Le due modalità di archiviazione possono essere combinate: i modelli compositi combinano tabelle che usano modalità di archiviazione diverse in un singolo modello.
Per i modelli sottoposti a query molto complesse, Azure Load Balancer può essere usato per distribuire uniformemente il carico delle query tra le repliche del modello. Consente anche di scalare le applicazioni e creare modelli semantici BI ad alta disponibilità.
Modelli di Machine Learning
I modelli di Machine Learning (ML) vengono creati e gestiti dai data scientist. Sono perlopiù sviluppati da fonti grezze nel data lake.
I modelli di apprendimento automatico addestrati possono rivelare schemi all'interno dei tuoi dati. In molte circostanze, questi modelli possono essere usati per eseguire stime che possono essere usate per arricchire i dati. Ad esempio, il comportamento di acquisto può essere usato per stimare la varianza dei clienti o segmentare i clienti. I risultati della stima possono essere aggiunti ai modelli aziendali per consentire l'analisi in base al segmento dei clienti.
In una piattaforma di BI su cloud è possibile usare Azure Machine Learning per addestrare, implementare, automatizzare, gestire e tenere traccia dei modelli di Machine Learning.
Magazzino dati
Al centro di una piattaforma di Business Intelligence si trova il data warehouse, che ospita i modelli aziendali. Si tratta di una fonte di dati autorizzati, sia come sistema di registrazione che come hub, al servizio di modelli aziendali per la creazione di reportistica, business intelligence e data science.
Molti servizi aziendali, incluse le applicazioni line-of-business (LOB), possono basarsi sul data warehouse come fonte autorevole e regolamentata di conoscenze aziendali.
Microsoft ospita il data warehouse in Azure Data Lake Storage Gen2 (ADLS Gen2) e Azure Synapse Analytics.
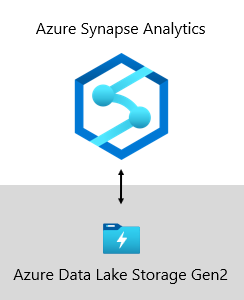
- ADLS Gen2 rende Archiviazione Azure la base per costruire data lake aziendali su Azure. Questo servizio è in grado di gestire diversi petabyte di informazioni supportando al tempo stesso centinaia di gigabit di velocità effettiva. Offre inoltre capacità e transazioni di archiviazione a basso costo. Inoltre, supporta l'accesso compatibile con Hadoop, che consente di gestire e accedere ai dati esattamente come si farebbe con un file system hadoop distribuito (HDFS). Infatti, Azure HDInsight, Azure Databricks e Azure Synapse Analytics possono accedere a tutti i dati archiviati in ADLS Gen2. In una piattaforma BI, è quindi consigliabile archiviare dati grezzi di origine, dati intermedi o di staging e dati pronti per la produzione. Viene usato per archiviare tutti i dati aziendali.
- Azure Synapse Analytics è un servizio di analisi che riunisce data warehousing aziendale e analisi di Big Data. Offre la libertà di eseguire query sui dati alle proprie condizioni, utilizzando risorse serverless su richiesta o risorse provisionate, il tutto su larga scala. Synapse SQL, un componente di Azure Synapse Analytics, supporta analisi complete basate su T-SQL, quindi è ideale ospitare modelli aziendali che comprendono le tabelle delle dimensioni e dei fatti. Le tabelle possono essere caricate in modo efficiente da ADLS Gen2 usando semplici query T-SQL polybase . Si ha quindi la potenza di MPP per eseguire analisi ad alte prestazioni.
Framework del motore delle regole di business
È stato sviluppato un framework bre (Business Rules Engine ) per catalogare qualsiasi logica di business che può essere implementata nel livello del data warehouse. Un bre può significare molte cose, ma nel contesto di un data warehouse è utile per creare colonne calcolate in tabelle relazionali. Queste colonne calcolate vengono in genere rappresentate come calcoli matematici o espressioni usando istruzioni condizionali.
L'intenzione è suddividere la logica di business dal codice BI core. Tradizionalmente, le regole aziendali sono incorporate direttamente nelle stored procedure SQL, quindi spesso richiede uno sforzo notevole per gestirle quando le esigenze aziendali cambiano. In un bre le regole business vengono definite una sola volta e usate più volte quando vengono applicate a entità di data warehouse diverse. Se la logica di calcolo deve cambiare, deve essere aggiornata solo in un'unica posizione e non in numerose stored procedure. C'è anche un vantaggio collaterale: un framework BRE guida la trasparenza e la visibilità sulla logica di business implementata, che può essere esposta tramite un set di report che generano documentazione che si autoaggiorna.
Origini dati
Un data warehouse può consolidare i dati da praticamente qualsiasi origine dati. È per lo più costruito su origini dati LOB, che sono comunemente database relazionali che memorizzano dati specifici per settore, come vendite, marketing, finanza, ecc. Questi database possono essere ospitati nel cloud oppure possono risiedere localmente. Altre origini dati possono essere basate su file, in particolare i log Web o i dati IOT originati dai dispositivi. Inoltre, i dati possono essere originati dai fornitori SaaS (Software-as-a-Service).
Microsoft, alcuni dei nostri sistemi interni generano dati operativi diretti ad ADLS Gen2 usando formati di file non elaborati. Oltre al data lake, altri sistemi di origine comprendono applicazioni LOB relazionali, cartelle di lavoro di Excel, altre origini basate su file e Master Data Management (MDM) e repository di dati personalizzati. I repository MDM consentono di gestire i dati master per garantire versioni autorevoli, standardizzate e convalidate dei dati.
Inserimento dati
Su base periodica, e in base ai ritmi dell'azienda, i dati vengono inseriti dai sistemi di origine e caricati nel data warehouse. Potrebbe essere una volta al giorno o a intervalli più frequenti. L'inserimento dati riguarda l'estrazione, la trasformazione e il caricamento dei dati. Oppure, forse l'altro modo: estrazione, caricamento e trasformazione dei dati. La differenza è la posizione in cui viene eseguita la trasformazione. Le trasformazioni vengono applicate per pulire, conformarsi, integrare e standardizzare i dati. Per altre informazioni, vedere Estrarre, trasformare e caricare (ETL).
In definitiva, l'obiettivo è caricare i dati corretti nel modello aziendale nel modo più rapido ed efficiente possibile.
Microsoft usa Azure Data Factory (ADF). I servizi vengono usati per pianificare e orchestrare le convalide, le trasformazioni e i caricamenti bulk dei dati dai sistemi di origine esterni nel data lake. È gestito da framework personalizzati per elaborare i dati in parallelo e su larga scala. Inoltre, la registrazione completa viene intrapresa per supportare la risoluzione dei problemi, il monitoraggio delle prestazioni e attivare le notifiche di avviso quando vengono soddisfatte condizioni specifiche.
Nel frattempo , Azure Databricks, una piattaforma di analisi basata su Apache Spark ottimizzata per la piattaforma dei servizi cloud di Azure, esegue trasformazioni specifiche per l'analisi scientifica dei dati. Compila ed esegue anche modelli di Machine Learning usando notebook Python. I punteggi di questi modelli di Machine Learning vengono caricati nel data warehouse per integrare stime con applicazioni e report aziendali. Poiché Azure Databricks accede direttamente ai file data lake, elimina o riduce al minimo la necessità di copiare o acquisire dati.
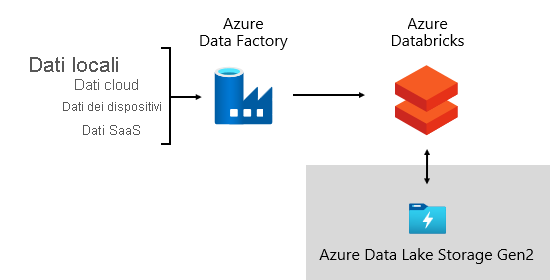
Framework di inserimento
È stato sviluppato un framework di inserimento come set di tabelle e procedure di configurazione. Supporta un approccio basato sui dati per acquisire grandi volumi di dati ad alta velocità e con codice minimo. In breve, questo framework semplifica il processo di acquisizione dei dati per caricare il data warehouse.
Il framework dipende dalle tabelle di configurazione che archiviano informazioni correlate all'origine dati e alla destinazione dati, ad esempio il tipo di origine, il server, il database, lo schema e i dettagli correlati alla tabella. Questo approccio di progettazione significa che non è necessario sviluppare pipeline ADF specifiche o pacchetti SSIS (SQL Server Integration Services). Le procedure vengono invece scritte nel linguaggio preferito per creare pipeline di Azure Data Factory generate e eseguite in modo dinamico in fase di esecuzione. L'acquisizione dei dati diventa quindi un esercizio di configurazione facilmente operativo. Tradizionalmente, sarebbero necessarie risorse di sviluppo significative per creare pacchetti ADF o SSIS hard-coded.
Il framework di inserimento è stato progettato per semplificare anche il processo di gestione delle modifiche dello schema di origine upstream. È facile aggiornare i dati di configurazione, manualmente o automaticamente, quando vengono rilevate modifiche dello schema per acquisire gli attributi appena aggiunti nel sistema di origine.
Framework di orchestrazione
È stato sviluppato un framework di orchestrazione per rendere operative e orchestrare le pipeline di dati. Il framework di orchestrazione usa una progettazione basata sui dati che dipende da un set di tabelle di configurazione. Queste tabelle archiviano i metadati che descrivono le dipendenze della pipeline e come eseguire il mapping dei dati di origine alle strutture di dati di destinazione. L'investimento nello sviluppo di questo framework adattivo si è ripagato; non è più necessario codificare manualmente ogni spostamento dei dati.
Archiviazione dei dati
Un data lake può archiviare grandi volumi di dati non elaborati per usarli in un secondo momento insieme alle trasformazioni dei dati di staging.
Microsoft usa ADLS Gen2 come singola fonte di verità. Archivia i dati non elaborati insieme ai dati di staging e ai dati pronti per la produzione. Offre una soluzione data lake altamente scalabile e conveniente per l'analisi dei Big Data. Combinando la potenza di un file system ad alte prestazioni con scalabilità elevata, è ottimizzato per i carichi di lavoro analitici dei dati, accelerando il tempo per ottenere informazioni dettagliate.
ADLS Gen2 offre il meglio di due mondi: è un'archiviazione BLOB e un file system ad alte prestazioni, che viene configurato con autorizzazioni di accesso granulari.
I dati perfezionati vengono quindi archiviati in un database relazionale per offrire un archivio dati altamente scalabile e a prestazioni elevate per i modelli aziendali, con sicurezza, governance e gestibilità. I data mart specifici al soggetto vengono archiviati in Azure Synapse Analytics e sono popolati da Azure Databricks o da query T-SQL di Polybase.
Utilizzo dei dati
A livello di report, i servizi aziendali usano i dati aziendali originati dal data warehouse. Accedono anche ai dati direttamente nel data lake per attività ad hoc di analisi o data science.
Le autorizzazioni a grana fine vengono applicate a tutti i livelli: nel data lake, nei modelli aziendali e nei modelli semantici BI. Le autorizzazioni assicurano che i consumer di dati possano visualizzare solo i dati a cui dispongono dei diritti di accesso.
Microsoft usa report e dashboard di Power BI e report impaginati di Power BI. Alcune attività di creazione di report e analisi ad hoc vengono eseguite in Excel, in particolare per la creazione di report finanziari.
Pubblichiamo dizionari di dati, che forniscono informazioni di riferimento sui nostri modelli di dati. Vengono resi disponibili agli utenti in modo da poter individuare informazioni sulla piattaforma BI. I dizionari progettano modelli di documenti, fornendo descrizioni su entità, formati, struttura, derivazione dei dati, relazioni e calcoli. Azure Data Catalog viene usato per rendere facilmente individuabili e comprensibili le origini dati.
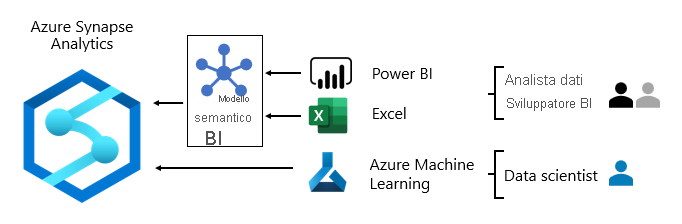
In genere, i modelli di utilizzo dei dati differiscono in base al ruolo:
- Gli analisti dei dati si connettono direttamente ai modelli semantici bi di base. Quando i modelli semantici di business intelligence di base contengono tutti i dati e la logica necessari, usano connessioni dinamiche per creare report e dashboard di Power BI. Quando devono estendere i modelli con i dati di reparto, creano modelli compositi di Power BI. Se sono necessari report in stile foglio di calcolo, si usa Excel per produrre report basati su modelli semantici BI di base o modelli semantici BI dipartimentali.
- Gli sviluppatori di business intelligence e gli autori di report operativi si connettono direttamente ai modelli aziendali. Usano Power BI Desktop per creare report analitici di connessione in tempo reale. Possono anche creare report BI di tipo operativo come report dettagliati di Power BI, scrivendo query SQL nativi per accedere ai dati dai modelli enterprise di Azure Synapse Analytics usando T-SQL, o modelli semantici di Power BI usando DAX o MDX.
- I data scientist si connettono direttamente ai dati nel data lake. Usano Azure Databricks e i notebook Python per sviluppare modelli di Machine Learning, che sono spesso sperimentali e richiedono competenze speciali per l'uso in produzione.
Contenuti correlati
Per altre informazioni su questo articolo, consultare le risorse seguenti:
- roadmap per l'adozione di Fabric: Centro di eccellenza
- BI aziendale in Azure con Azure Synapse Analytics
- Domande? Prova a chiedere alla Fabric Community
- Suggerimenti? Contribuire con idee per migliorare Fabric
Servizi professionali
I partner Power BI certificati sono disponibili per aiutare l'organizzazione a avere successo durante la configurazione di un COE. Possono fornire una formazione conveniente o una verifica dei tuoi dati. Per trovare un partner Power BI, visitare il portale dei partner di Microsoft Power BI .
È anche possibile interagire con partner di consulenza esperti. Possono essere utili per valutare , esaminareo implementare Power BI.