Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere leinformazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Altre informazioni sulle Azure Machine Learning.
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Converte i dati di testo in funzioni con codifica numero intero usando la libreria Vowpal Wabbit
Categoria: Analisi del testo
Nota
Si applica a: solo Machine Learning Studio (versione classica)
I moduli di trascinamento e rilascio simili sono disponibili in Azure Machine Learning finestra di progettazione.
Panoramica del modulo
Questo articolo descrive come usare il modulo Hashing funzionalità in Machine Learning Studio (versione classica), per trasformare un flusso di testo in inglese in un set di funzionalità rappresentate come interi. È quindi possibile passare questa funzionalità hash impostata su un algoritmo di Machine Learning per eseguire il training di un modello di analisi del testo.
La funzionalità di hashing delle funzionalità fornita in questo modulo è basata sul framework Wabbit di Vowpal. Per altre informazioni, vedere Training Vowpal Wabbit 7-4 Model o Train Vowpal Wabbit7-10 Model.
Altre informazioni sull'hash delle funzionalità
L'hash delle funzionalità funziona convertendo token univoci in interi. Opera sulle stringhe esatte fornite come input e non esegue alcuna analisi linguistica o pre-elaborazione.
Ad esempio, prendere un set di frasi semplici come queste, seguito da un punteggio di sentiment. Si supponga di voler usare questo testo per compilare un modello.
| USERTEXT | SENTIMENTO |
|---|---|
| Mi è piaciuto questo libro | 3 |
| Ho odiato questo libro | 1 |
| Questo libro era fantastico | 3 |
| Amo i libri | 2 |
Internamente, il modulo Hashing funzionalità crea un dizionario di n-grammi. Ad esempio, l'elenco di bigram per questo set di dati sarà simile al seguente:
| TERM (bigrams) | FREQUENZA |
|---|---|
| Questo libro | 3 |
| Mi è piaciuto | 1 |
| Ho odiato | 1 |
| Amo | 1 |
È possibile controllare le dimensioni dei n-grammi usando la proprietà N-grams . Se si sceglie bigrams, vengono calcolati anche gli unigrammi. Pertanto, il dizionario includerebbe anche termini singoli come questi:
| Termine (unigrammi) | FREQUENZA |
|---|---|
| libro | 3 |
| I | 3 |
| books | 1 |
| Era | 1 |
Dopo aver compilato il dizionario, il modulo Hashing funzionalità converte i termini del dizionario in valori hash e calcola se una funzionalità è stata usata in ogni caso. Per ogni riga di dati di testo, il modulo restituisce un set di colonne, una colonna per ogni funzionalità hash.
Ad esempio, dopo l'hashing, le colonne di funzionalità potrebbero avere un aspetto simile al seguente:
| Classificazione | Funzione hash 1 | Funzionalità di hashing 2 | Funzionalità di hashing 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Se il valore nella colonna è 0, la riga non contiene la funzionalità hash.
- Se il valore è 1, la riga contiene la funzionalità.
Il vantaggio dell'uso dell'hash delle funzionalità è che è possibile rappresentare documenti di testo di lunghezza variabile come vettori di funzionalità numerici di lunghezza uguale e ottenere una riduzione della dimensione. Al contrario, se si tenta di usare la colonna di testo per il training come è, verrà considerato come una colonna di funzionalità categorica, con molti valori distinti.
Gli output numerici consentono inoltre l'uso di molti metodi diversi di Machine Learning con i dati, tra cui classificazione, clustering o recupero delle informazioni. Poiché le operazioni di ricerca possono usare hash interi anziché confronti di stringhe, ottenere i pesi delle funzionalità è anche molto più veloce.
Come configurare l'hash delle funzionalità
Aggiungere il modulo Feature Hashing all'esperimento in Studio (versione classica).
Connessione il set di dati contenente il testo da analizzare.
Suggerimento
Poiché l'hash delle funzionalità non esegue operazioni lessicali, ad esempio stemming o troncamento, a volte è possibile ottenere risultati migliori eseguendo la pre-elaborazione del testo prima di applicare l'hash delle funzionalità. Per suggerimenti, vedere le sezioni Procedure consigliate e Note tecniche .
Per Colonne di destinazione selezionare le colonne di testo che si desidera convertire in funzionalità hash.
Le colonne devono essere il tipo di dati stringa e devono essere contrassegnate come colonna Funzionalità .
Se si sceglie più colonne di testo da usare come input, può avere un effetto enorme sulla dimensionalità delle funzionalità. Ad esempio, se viene usato un hash a 10 bit per una singola colonna di testo, l'output contiene 1024 colonne. Se viene usato un hash a 10 bit per due colonne di testo, l'output contiene 2048 colonne.
Nota
Per impostazione predefinita, Studio (versione classica) contrassegna la maggior parte delle colonne di testo come funzionalità, quindi se si selezionano tutte le colonne di testo, è possibile che vengano visualizzate troppe colonne, incluse molte che non sono effettivamente testo libero. Usare l'opzione Cancella funzionalità in Modifica metadati per impedire l'hash di altre colonne di testo.
Usare bitsize hash per specificare il numero di bit da usare durante la creazione della tabella hash.
La dimensione di bit predefinita è 10. Per molti problemi, questo valore è più adeguato, ma se è sufficiente per i dati dipende dalle dimensioni del vocabolario n-grammi nel testo di training. Con un vocabolario di grandi dimensioni, potrebbe essere necessario più spazio per evitare collisioni.
È consigliabile provare a usare un numero diverso di bit per questo parametro e valutare le prestazioni della soluzione di Machine Learning.
Per N-grammi, digitare un numero che definisce la lunghezza massima dei n-grammi da aggiungere al dizionario di training. Un n-gram è una sequenza di n parole, trattato come un'unità unica.
N-grammi = 1: Unigrammi o parole singole.
N-grammi = 2: Bigrams, o sequenze a due parole, più unigrammi.
N-grammi = 3: trigrammi o sequenze a tre parole, più bigram e unigrammi.
Eseguire l'esperimento.
Risultati
Al termine dell'elaborazione, il modulo restituisce un set di dati trasformato in cui la colonna di testo originale è stata convertita in più colonne, ognuna delle quali rappresenta una funzionalità nel testo. A seconda della dimensione del dizionario, il set di dati risultante può essere estremamente grande:
| Nome colonna 1 | Tipo di colonna 2 |
|---|---|
| USERTEXT | Colonna di dati originale |
| SENTIMENTO | Colonna di dati originale |
| USERTEXT - Funzionalità hash 1 | Colonna delle funzionalità con hash |
| USERTEXT - Funzionalità hash 2 | Colonna delle funzionalità con hash |
| USERTEXT - Funzionalità di hashing n | Colonna delle funzionalità con hash |
| USERTEXT - Funzionalità hash 1024 | Colonna delle funzionalità con hash |
Dopo aver creato il set di dati trasformato, è possibile usarlo come input per il modulo Train Model ,insieme a un modello di classificazione valido, ad esempio Two-Class Support Vector Machine.
Procedure consigliate
Alcune procedure consigliate che è possibile usare durante la modellazione dei dati di testo sono illustrate nel diagramma seguente che rappresenta un esperimento
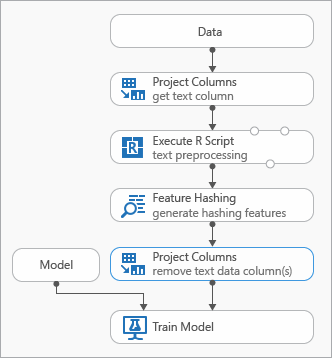
Per la pre-elaborazione del testo di input può essere necessario aggiungere un modulo Execute R Script prima di usare Feature Hashing. Con lo script R è anche possibile usare vocabolari personalizzati o trasformazioni personalizzate.
È necessario aggiungere un modulo Select Columns in Dataset (Seleziona colonne nel set di dati ) dopo il modulo Feature Hashing per rimuovere le colonne di testo dal set di dati di output. Non sono necessarie le colonne di testo dopo la generazione delle funzionalità di hash.
In alternativa, è possibile usare il modulo Modifica metadati per cancellare l'attributo della funzionalità dalla colonna di testo.
Considerare anche l'uso di queste opzioni di pre-elaborazione del testo per semplificare i risultati e migliorare l'accuratezza:
- word breaking
- stop word removal
- normalizzazione del case
- rimozione della punteggiatura e dei caratteri speciali
- Derivanti.
Il set ottimale di metodi di pre-elaborazione da applicare in qualsiasi singola soluzione dipende dal dominio, dal vocabolario e dalle esigenze aziendali. È consigliabile sperimentare i dati per vedere quali metodi di elaborazione del testo personalizzati sono più efficaci.
Esempio
Per esempi di come viene usato l'hashing delle funzionalità per l'analisi del testo, vedere Azure AI Gallery:
Categorizzazione notizie: usa l'hashing delle funzionalità per classificare gli articoli in un elenco predefinito di categorie.
Società simili: usa il testo degli articoli di Wikipedia per classificare le aziende.
Classificazione del testo: questo esempio in cinque parti usa il testo dei messaggi di Twitter per eseguire l'analisi del sentiment.
Note tecniche
Questa sezione contiene informazioni dettagliate sull'implementazione, suggerimenti e risposte alle domande frequenti.
Suggerimento
Oltre a usare l'hashing delle funzionalità, è possibile usare altri metodi per estrarre le funzionalità dal testo. Ad esempio:
- Usare il modulo Pre-elabora testo per rimuovere artefatti come errori di ortografia o per semplificare la preparazione del testo all'hashing.
- Usare Extract Key Phrase (Estrai frasi chiave ) per usare l'elaborazione del linguaggio naturale per estrarre frasi.
- Usare Riconoscimento entità denominate per identificare le entità importanti.
Machine Learning Studio (versione classica) fornisce un modello di classificazione del testo che consente di usare il modulo Hashing funzionalità per l'estrazione delle funzionalità.
Dettagli dell'implementazione
Il modulo Feature Hashing usa un framework di Machine Learning rapido denominato Vowpal Wabbit che esegue l'hashing delle parole in indici in memoria, usando una funzione hash open source comune denominata murmurhash3. Questa funzione hash è un algoritmo di hashing non crittografico che esegue il mapping degli input di testo a numeri interi ed è molto diffuso perché offre buone prestazioni in una distribuzione casuale di chiavi. A differenza delle funzioni hash crittografiche, può essere facilmente invertito da un antagonista, in modo che non sia adatto a scopi crittografici.
Lo scopo dell'hashing consiste nel convertire documenti di testo di lunghezza variabile in vettori di funzioni numeriche di lunghezza uguale per supportare la riduzione della dimensionalità e accelerare la ricerca dei pesi delle funzioni.
Ogni funzionalità di hashing rappresenta una o più caratteristiche di testo n-gram (unigrammi o singole parole, bi-grammi, tri-grammi e così via), a seconda del numero di bit (rappresentati come k) e del numero di n grammi specificati come parametri. Proietta i nomi delle funzionalità alla parola senza segno dell'architettura del computer usando l'algoritmo murmurhash v3 (solo a 32 bit), che quindi è AND-ed con (2^k)-1. Ovvero, il valore hash viene proiettato fino ai primi k bit in ordine inferiore e i bit rimanenti vengono azzerato. Se il numero specificato di bit è 14, la tabella hash può contenere 2 vocida 14 a 1 (o 16,383).
Per molti problemi, la tabella hash predefinita (bitsize = 10) è più che adeguata; Tuttavia, a seconda delle dimensioni del vocabolario n-grammi nel testo di training, potrebbe essere necessario più spazio per evitare collisioni. È consigliabile provare a usare un numero diverso di bit per il parametro Hashing bitsize e valutare le prestazioni della soluzione di Machine Learning.
Input previsti
| Nome | Tipo | Descrizione |
|---|---|---|
| Set di dati | Tabella dati | Set di dati di input |
Parametri del modulo
| Name | Intervallo | Type | Predefinito | Descrizione |
|---|---|---|---|---|
| Target columns | Qualsiasi | ColumnSelection | StringFeature | Scegliere le colonne a cui verrà applicato l'hashing. |
| Hashing bitsize | [1;31] | Integer | 10 | Digitare il numero di bit da usare per l'hashing delle colonne selezionate |
| N-grams | [0;10] | Integer | 2 | Specificare il numero di N-grammi generati durante l'hashing. Per impostazione predefinita, vengono estratti sia gli unigrammi che i digrammi |
Output
| Nome | Tipo | Descrizione |
|---|---|---|
| Set di dati trasformato | Tabella dati | Set di dati di output con colonne con hash |
Eccezioni
| Eccezione | Descrizione |
|---|---|
| Errore 0001 | L'eccezione si verifica se non è possibile trovare una o più colonne specificate del set di dati. |
| Errore 0003 | L'eccezione si verifica se uno o più input sono null o vuoti. |
| Errore 0004 | L'eccezione si verifica se un parametro è inferiore o uguale a un valore specifico. |
| Errore 0017 | Si verifica un'eccezione se il tipo di una o più colonne specificate non è supportato dal modulo attuale. |
Per un elenco degli errori specifici dei moduli di Studio (versione classica), vedere Machine Learning Codici di errore.
Per un elenco delle eccezioni API, vedere Machine Learning codici di errore dell'API REST.