お客様のアクティビティが必要
インシデント前
Azure サービスの場合
- Azure portal で Azure Service Health の詳細を確認してください。 このページは、インシデント中に "ワンストップ ショップ" として機能します
- Azure インシデントが発生したときに自動的に通知を生成するように構成できる Service Health アラートの使用を検討してください
Power BI 用
- Microsoft 365 管理センターで Service Health の詳細を確認してください。 このページは、インシデント中に "ワンストップ ショップ" として機能します
- 自動的なサービス インシデント アラート通知を取得するために Microsoft 365 管理モバイル アプリの使用を検討してください
インシデント中
Azure サービスの場合
- Azure 管理ポータル内の Azure Service Health で、最新の更新プログラムが提供されます
- Service Health へのアクセスに問題がある場合は、「Azure の状態」ページを参照してください
- [状態] ページへのアクセスに問題がある場合は、X (旧称 Twitter) で @AzureSupport にアクセスしてください
- 影響/問題がインシデントと一致しない (または軽減策後も持続する) 場合は、サポートに連絡してサービス サポート チケットを発行してください
Power BI 用
- Microsoft 365 管理センター内の [Service Health] ページで、最新の更新プログラムが提供されます
- Service Health へのアクセスに問題がある場合は、Microsoft 365 の状態ページを参照してください
- 影響/問題がインシデントと一致しない (または軽減策後も問題が持続する) 場合は、サービス サポート チケットを発行してください。
Microsoft の復旧後
この詳細については、以下のセクションをご覧ください。
インシデント後
Azure サービスの場合
- Microsoft は、レビューのために Azure portal - Service Health に PIR を発行します
Power BI 用
- Microsoft は、レビューのために Microsoft 365 管理 - Service Health に PIR を発行します
Microsoft を待機するプロセス
"Microsoft を待機する" プロセスでは、影響を受けたプライマリ リージョン内のすべてのコンポーネントとサービスを Microsoft が復旧させるのをただ待機します。 復旧したら、データ プラットフォームのエンタープライズ共有またはその他のサービスへのバインドと、データセットの日付を検証し、システムを現在の日付まで更新するプロセスを実行します。
このプロセスが完了すると、技術的およびビジネス上の SME の検証を完了して、サービスの回復に対する利害関係者の承認を有効にできます。
災害発生時の再配置
"災害発生時の再配置" 方法は、次のおおまかなプロセス フローで説明できます。
Contoso の復旧 - エンタープライズ共有サービスとソース システム

- この手順は、データ プラットフォームの復旧の前提条件です
- この手順は、エンタープライズ共有サービスと運用ソース システムを担当するさまざまな Contoso 運用サポート グループによって実行されます
Azure サービスの復旧 Azure サービスとは、Azure クラウド オファリングを構成するアプリケーションとサービスを指し、セカンダリ リージョン内で配置に使用できます。

Azure サービスとは、Azure クラウド オファリングを構成するアプリケーションとサービスを指し、セカンダリ リージョン内で配置に使用できます。
- この手順は、データ プラットフォームの復旧の前提条件です
- この手順は、Microsoft および他の PaaS/SaaS パートナーによって実行されます
データ プラットフォーム基盤の復旧
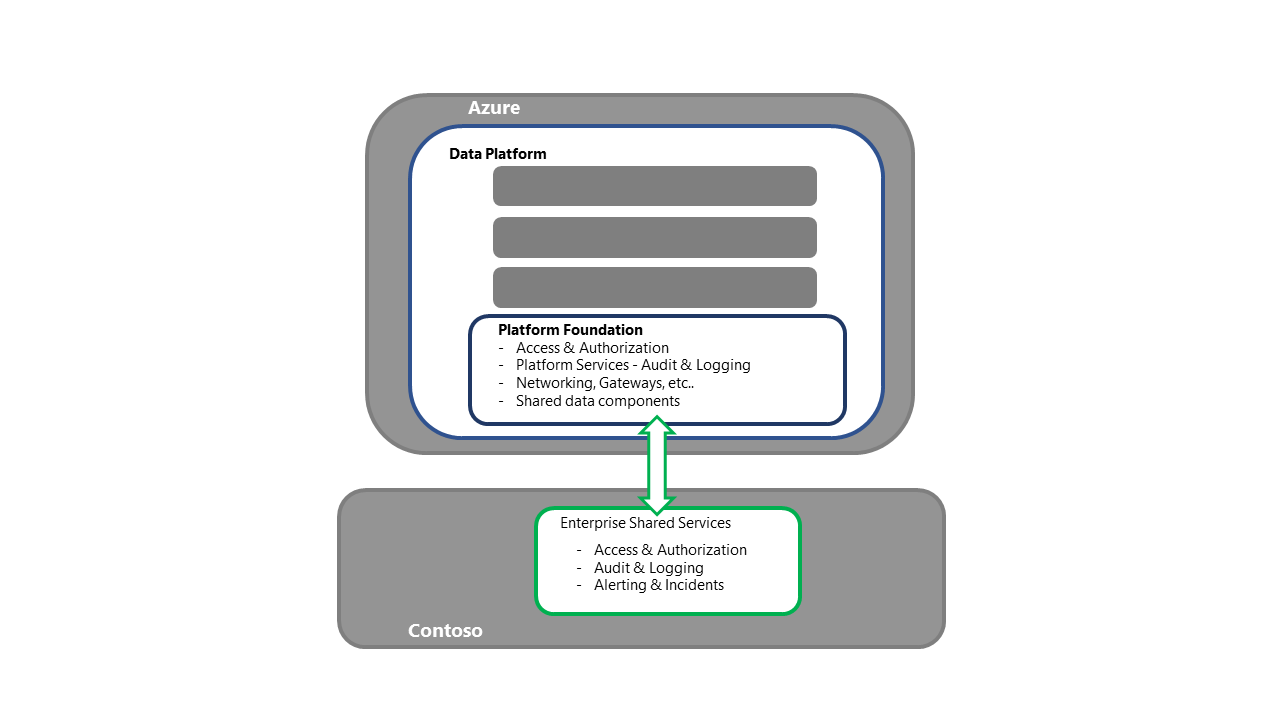
- この手順は、プラットフォーム回復アクティビティのエントリ ポイントです
- 再配置方法では、必要な各コンポーネント/サービスが調達され、セカンダリ リージョンに配置されます
- コンポーネントと配置方法の詳細な内訳については、このシリーズの Azure サービスとコンポーネントのセクションを参照してください。
- このプロセスには、エンタープライズ共有サービスへのバインド、アクセス/認証への接続の確保、ログ オフロードの動作の検証などのアクティビティも含める必要があります。同時に、アップストリームとダウンストリームの両方のプロセスの接続を確保する必要があります。
- データ/処理を確認する必要があります。 たとえば、復旧されたプラットフォームのタイムスタンプの検証です
- データの整合性に関する疑問がある場合は、新しい処理を実行してプラットフォームを最新の状態にする前に、さらに時間をさかのぼるロールバックを決定することも考えられます
- (ビジネスへの影響に基づいて) プロセスの優先順位を付けると、復旧の調整に役立ちます
- この手順は、ビジネス ユーザーがサービスと直接やり取りする場合を除き、技術的な検証によって締めくくる必要があります。 直接アクセスする場合は、ビジネス上の検証手順が必要です
- 検証が完了すると、個々のソリューション チームに引き継がれ、独自の DR 回復プロセスが開始されます
- この引き継ぎには、データ/プロセスの現在のタイムスタンプの確認を含める必要があります
- 中核のエンタープライズ データ プロセスを実行する場合は、個々のソリューションがそのことを認識する必要があります (受信/送信フローなど)
プラットフォームによってホストされている個々のソリューションの復旧
- 個々のソリューションには、独自の DR Runbook が必要です。 Runbook には、少なくとも、指名されたビジネス利害関係者が含まれている必要があります。サービスの回復が完了したことをテストして確認する人物です
- リソースの競合や優先順位に応じて、主要なソリューション/ワークロードが他のソリューションよりも優先される (アドホック ラボより中核のエンタープライズ プロセスなど) 場合があります
- 検証手順が完了すると、ダウンストリーム ソリューションに引き継がれ、DR 回復プロセスが開始されます
ダウンストリームの依存システムへの引き継ぎ
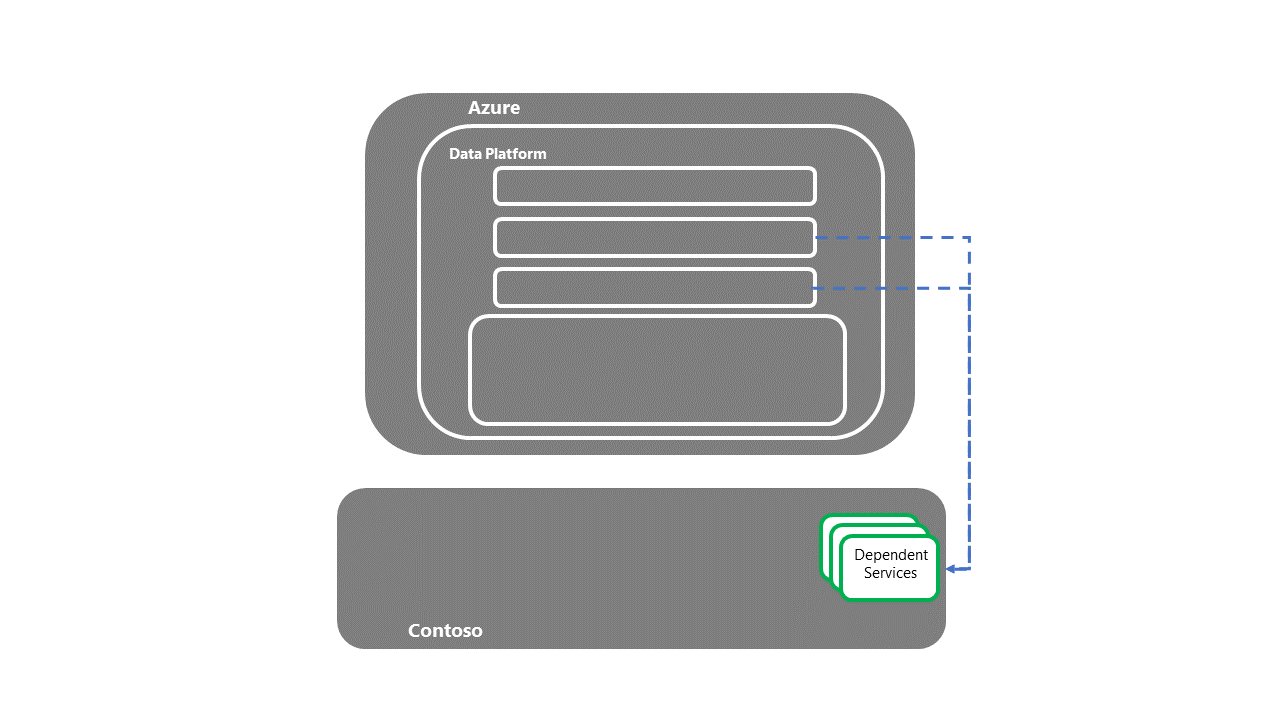
- 依存サービスが復旧されると、E2E DR 復旧プロセスが完了します
Note
E2E DR プロセスを完全に自動化することは理論的には可能ですが、イベントのリスクと E2E プロセスをカバーするために必要な SDLC アクティビティのコストを考えると、現実的ではありません
プライマリ リージョンへのフォールバック フォールバックとは、データ プラットフォーム サービスとそのデータが平常業務で使用可能になったときに、それをプライマリ リージョンに戻すプロセスです。
ソース システムとさまざまなデータ プロセスの性質によっては、データ プラットフォームのフォールバックを、データ エコシステムの他の部分とは別個に行うことができます。
適切な決定を行うために、お客様自身のデータ プラットフォームの依存関係 (アップストリームとダウンストリームの両方) を確認することをお勧めします。 次のセクションでは、データ プラットフォームを別個に復旧することを想定しています。
- 必要なすべてのコンポーネント/サービスがプライマリ リージョンで使用できるようになったら、お客様はスモーク テストを実行して Microsoft の復旧を検証します
- コンポーネント/サービス構成が検証されます。 差分は、ソース管理からの再配置によって解消されます
- プライマリ リージョンのシステム日付が、ステートフル コンポーネント間で確立されます。 確立された日付とセカンダリ リージョンの日付/タイムスタンプの間の差分は、その時点からデータ インジェスト プロセスを再実行または再生することによって解消する必要があります
- ビジネスと技術の両方の利害関係者からの承認により、フォールバック ウィンドウが選択されます。 システム アクティビティと処理が発生していない時間中が理想的です
- フォールバック中、システムが切り替えられる前に、プライマリ リージョンがセカンダリ リージョンと同期されます
- 並列実行の期間後、セカンダリ リージョンはシステムからオフラインになります
- セカンダリ リージョン内のコンポーネントは、選択した DR 方法に応じて切断または削除されます
ウォーム スペア プロセス
"ウォーム スペア" 方法の場合、おおまかなプロセス フローは "災害発生時の再配置" のものと非常に類似しています。主な違いは、セカンダリ リージョンでコンポーネントが既に調達されていることです。 この方法では、そのリージョンで独自の DR を実行しようとしている他の組織からのリソース競合のリスクがなくなります。
ホット スペア プロセス
"ホット スペア" 方法とは、プライマリ システムと並行してセカンダリ システムが実行されるため、災害時にも PaaS および IaaS システムを含むプラットフォーム サービスが持続することです。 "ウォーム スペア" 方式の場合と同様方法に、この方法では、そのリージョンで独自の DR を実行しようとしている他の組織からのリソース競合のリスクがなくなります。
ホット スペアのお客様は、プライマリ リージョンのコンポーネント/サービスの Microsoft の復旧を監視します。 完了すると、お客様はプライマリ リージョン システムを検証し、プライマリ リージョンへのフォールバックを完了します。 このプロセスは、DR フェールオーバー プロセスに似ています。つまり、使用可能なコードベースとデータを確認し、必要に応じて再配置します。
Note
ここで、システム メタデータが 2 つのリージョン間で一貫していることを特に注意して確認する必要があります。
- プライマリへのフォールバックが完了したら、システム ロード バランサーを更新して、プライマリ リージョンをシステム トポロジに戻すことができます。 使用可能な場合は、カナリア リリース アプローチを使用して、システムをプライマリ リージョンに段階的に切り替えることができます。
DR プランの構造
効果的な DR プランには、Azure 技術リソースによって実行できるサービス復旧のステップ バイ ステップ ガイドが示されます。 このような DR プランに推奨される MVP 構造を次に示します。
- プロセス要件
- DR の開始に必要な正しい承認、復旧に関する必要に応じた主要な決定 ("完了の定義" を含む)、サービス サポートの DR チケット参照、ウォー ルームの詳細などの、お客様の DR プロセス固有の詳細
- DR のリードと実行者の予備を含むリソースの確認。 すべてのリソースは、プライマリとセカンダリの連絡先、エスカレーション パス、および休暇カレンダーを含めて文書化する必要があります。 重大な DR 状況では、名簿システムを考慮する必要がある場合があります
- DR の実行者、DR の予備のノート PC、電源パック、予備電源、ネットワーク接続、携帯電話の詳細、およびエスカレーション ポイント
- プロセス要件のいずれかが満たされていない場合に従うプロセス
- 連絡先リスト
- DR のリーダーシップとサポート グループ
- 技術的な復旧のためのテスト/レビュー サイクルを実行するビジネス領域の専門家
- 影響を受けるビジネス所有者 (サービス復旧承認者を含む)
- 影響を受ける技術所有者 (技術復旧承認者を含む)
- プラットフォームによってホストされる主要なソリューションを含め、影響を受けるすべての領域にわたる領域の専門家サポート
- ダウンストリーム システムへの影響 – 運用サポート
- アップストリーム ソース システム – 運用サポート
- エンタープライズ共有サービスの連絡先。 たとえば、アクセス/認証のサポート、セキュリティの監視、ゲートウェイのサポートなどです
- クラウド プロバイダーのサポート連絡先を含む、外部またはサード パーティのベンダー
- アーキテクチャの設計
- E2E シナリオの詳細を記述し、関連するすべてのサポート ドキュメントを添付
- 依存関係
- すべてのコンポーネントの関係と依存関係をリスト
- DR の前提条件
- アップストリーム ソース システムが必要に応じて使用可能であることを確認
- スタック全体にわたって昇格されたアクセス権が DR の実行者リソースに付与されていること
- Azure サービスが必要に応じて利用できること
- 前提条件のいずれかが満たされていない場合に従うプロセス
- 技術的な復旧 - ステップ バイ ステップの手順
- 実行順序
- ステップの説明
- 手順の前提条件
- 各個別アクションの詳細なプロセス手順 (URL を含む)
- 検証手順 (必要な証拠を含む)
- 各ステップの完了に必要な予測時間 (余裕を持たせる)
- 手順が失敗した場合に従うプロセス
- エラーの場合のエスカレーション ポイントまたは領域の専門家サポート
- 技術的な復旧 - 事後要件
- 主要なコンポーネント全体にわたってシステムの現在の日付タイムスタンプを確認
- DR システムの URL と IP を確認
- ビジネス利害関係者のレビュー プロセスの準備 (システム アクセスの確認や、ビジネス領域の専門家による検証と承認の完了を含む)
- ビジネス利害関係者のレビューと承認
- ビジネス リソースの連絡先の詳細
- 上記の技術的な復旧に従ったビジネス検証手順
- ビジネス承認者が復旧を承認したことを示す必須の証拠証跡
- 復旧の事後要件
- データ プロセスを実行してシステムを最新の状態に保つための運用サポートへの引き継ぎ
- ダウンストリームのプロセスとソリューションへの引き継ぎ - DR システムの日付と接続の詳細を確認
- DR のリードと復旧プロセスが完了したことを確認 – 証拠証跡と完了した Runbook を確認
- 昇格されたアクセス権を DR チームから削除できることをセキュリティ管理者に通知
吹き出し
- 各手順のプロセスのシステム スクリーンショットを含めることをお勧めします。 これらのスクリーンショットは、タスクの実行をシステム領域の専門家に依存することを解消するのに役立ちます
- 急速に進化するクラウド サービスのリスクを軽減するため、DR プランは、Azure とそのサービスに関する最新の知識を持つリソースによって定期的に見直し、テストし、実行する必要があります
- 技術的な復旧手順には、組織に対するコンポーネントとソリューションの優先順位が反映されている必要があります。 たとえば、中核のエンタープライズ データ フローはアドホック データ分析ラボより前に復旧されます
- 技術的な復旧手順は、Key Vaultなどの基盤コンポーネント/サービスが復旧されたら、ワークフローの順序 (通常は左から右) に従う必要があります。 この方法により、アップストリームにある依存するものが使用可能になり、コンポーネントを適切にテストできるようになります
- ステップ バイ ステップのプランが完了したら、余裕を含めたアクティビティの合計時間を取得する必要があります。 この合計が合意された RTO を超える場合は、次のようないくつかの選択肢があります。
- 選択した復旧プロセスを自動化する (可能な場合)
- 選択した復旧手順を並列で実行する機会を探す (可能な場合)。 ただし、この方法には追加の DR の実行者リソースが必要になる場合があります。
- PaaS などのより高いレベルのサービス レベル (Microsoft がサービス復旧アクティビティに対してより大きな責任を負う) に主要なコンポーネントを引き上げる
- 利害関係者とともに RTO を延長する
DR テスト
Azure クラウド サービス オファリングの性質により、いずれの DR テスト シナリオにも制約が生じます。 そのため、セカンダリ リージョンで使用できるように、データ プラットフォーム コンポーネントに DR サブスクリプションを立ち上げることをお勧めします。
このベースラインから、DR プラン Runbook を選択的に実行することで、配置および検証できるサービスとコンポーネントに特化して注意を払うことができます。 このプロセスにはキュレーションされたテスト データセットが必要です。これにより、プランに従って技術面とビジネス面の検証チェックを確認できます。
DR プランは、最新の状態であることを確認するだけでなく、フェールオーバーと復旧アクティビティを実行するチームが "身体で覚える" ために、定期的に試運転する必要があります。
- データと構成の予備も定期的に検査して、復旧アクティビティをサポートする "目的に適合している" ことを確認する必要があります。
DR テスト中に注目する主要な領域は、定められた手順が今も正しく、予測されたタイミングが引き続き妥当であることを確認することです。
- 手順にコードではなくポータル画面が示されている場合は、クラウドでの変更の頻度により、少なくとも 12 か月ごとに手順を検証する必要があります。
目標は完全に自動化された DR プロセスを持つことですが、イベントがめったに発生しないために、完全な自動化は現実的ではない可能性があります。 そのため、プラットフォームの提供に使用される DSC IaC を使用して復旧ベースラインを確立し、新しいプロジェクトを構築するときに、そのベースラインを向上させることをお勧めします。
- 時間の経過とともにコンポーネントとサービスが拡張されて、NFR の適用が必要になると、運用環境への配置パイプラインをリファクタリングして DR に対応する必要があります。
Runbook のタイミングが RTO を超える場合は、次のようにいくつかの選択肢があります。
- 利害関係者とともに RTO を延長する
- 自動化、タスクの並列実行、またはより高いクラウド サーバー レベルへの移行により、復旧アクティビティに必要な時間を短縮する
Azure Chaos Studio
Azure Chaos Studio は、Azure アプリケーションに障害を挿入することで回復性を向上させるマネージド サービスです。 Chaos Studio を使用すると、実験を使用して、安全かつ制御された方法で Azure リソースでのフォールト挿入を調整できます。 現在サポートされている障害の種類の説明については、製品ドキュメントを参照してください。
Chaos Studio の現在のイテレーションでは、Azure コンポーネントとサービスの サブセットのみが対象となります。 より多くの障害ライブラリが追加されるまで、Chaos Studio は、全システムの DR テストではなく、分離された回復性テストに推奨されるアプローチです。
Chaos Studio の詳細については、こちらを参照してください。
Azure Site Recovery
IaaS コンポーネントの場合、Azure Site Recovery は、サポートされている VM または物理サーバーで実行されているほとんどのワークロードを保護します
次の強力なガイダンスがあります。
関連資料
- 回復性と可用性を考慮した設計
- 事業継続とディザスター リカバリー
- Azure アプリケーションのバックアップとディザスター リカバリー
- Azure の回復性
- サービス レベル アグリーメントのまとめ
- 障害を予測するための 5 つのベスト プラクティス
次のステップ
シナリオを展開する方法を学習したので、Azure データ プラットフォーム シリーズの DR のまとめを読むことができます。