検索ジョブを実行するには、Tables - Create または Update API を呼び出します。 この呼び出しには、作成される結果テーブルの名前が含まれています。 結果テーブルの名前は、_SRCH で終わる必要があります。
PUT https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/<TableName>_SRCH?api-version=2021-12-01-preview
PUT https://management.azure.com/subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Syslog_suspected_SRCH?api-version=2021-12-01-preview
GET https://management.azure.com/subscriptions/{subscriptionId}/resourcegroups/{resourceGroupName}/providers/Microsoft.OperationalInsights/workspaces/{workspaceName}/tables/<TableName>_SRCH?api-version=2021-12-01-preview
GET https://management.azure.com/subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Syslog_SRCH?api-version=2021-12-01-preview
Response
{
"properties": {
"retentionInDays": 30,
"totalRetentionInDays": 30,
"archiveRetentionInDays": 0,
"plan": "Analytics",
"lastPlanModifiedDate": "Mon, 01 Nov 2021 16:38:01 GMT",
"schema": {
"name": "Syslog_SRCH",
"tableType": "SearchResults",
"description": "This table was created using a Search Job with the following query: 'Syslog | where * has 'suspected.exe'.'",
"columns": [...],
"standardColumns": [...],
"solutions": [
"LogManagement"
],
"searchResults": {
"query": "Syslog | where * has 'suspected.exe'",
"limit": 1000,
"startSearchTime": "Wed, 01 Jan 2020 00:00:00 GMT",
"endSearchTime": "Fri, 31 Jan 2020 00:00:00 GMT",
"sourceTable": "Syslog"
}
},
"provisioningState": "Succeeded"
},
"id": "subscriptions/00000000-0000-0000-0000-00000000000/resourcegroups/testRG/providers/Microsoft.OperationalInsights/workspaces/testWS/tables/Syslog_SRCH",
"name": "Syslog_SRCH"
}
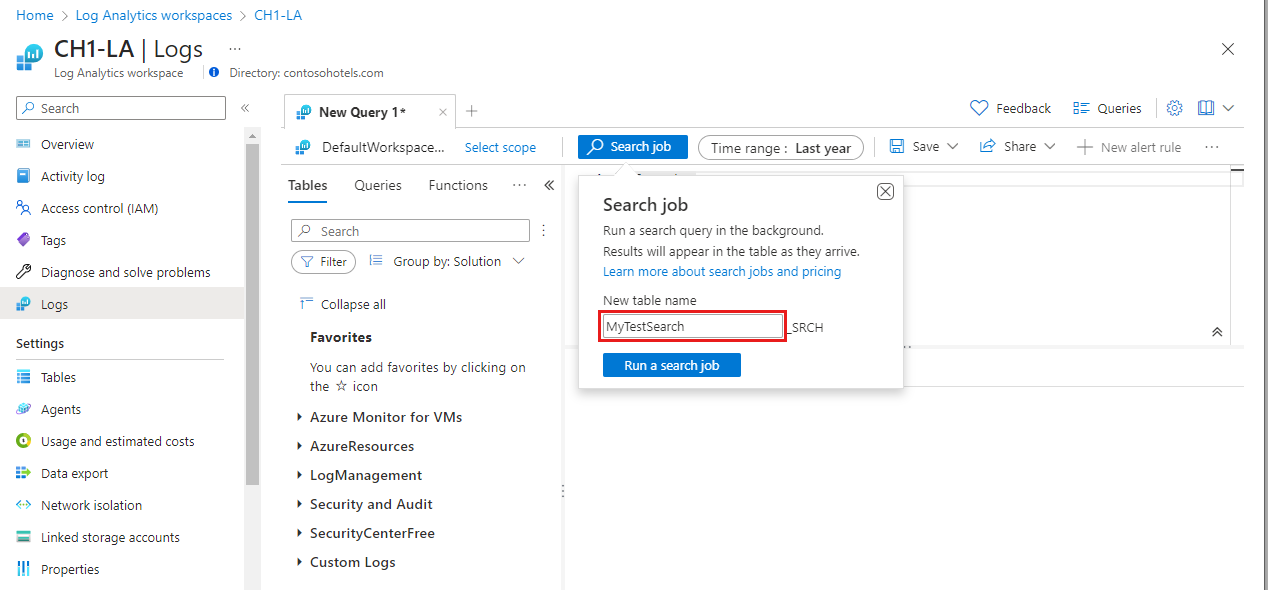
![[Search job mode] (検索ジョブ モード) スイッチが強調表示されている [ログ] 画面のスクリーンショット。](media/search-job/switch-to-search-job-mode.png)
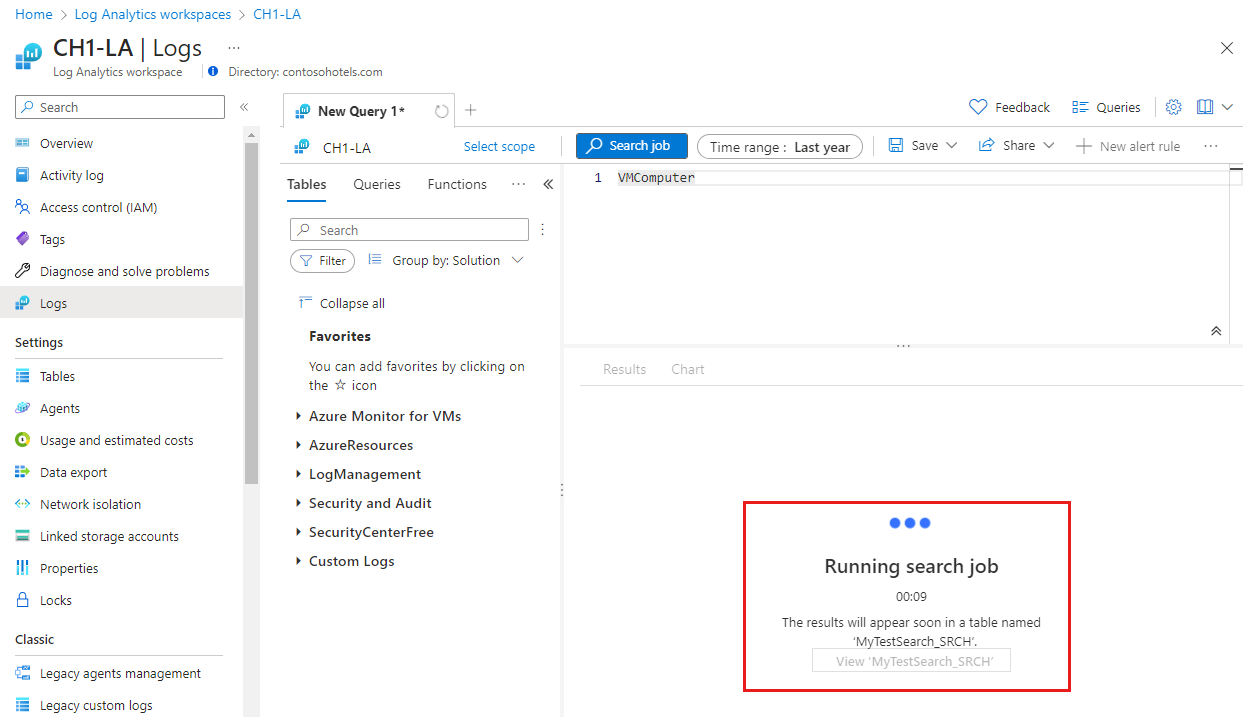
![[検索ジョブが完了しました] という Azure Monitor ログ メッセージを示すスクリーンショット。](media/search-job/search-job-done.png)
![[Search job mode] (検索ジョブ モード) スイッチが強調表示されている [ログ] 画面のスクリーンショット。](media/search-job/switch-to-search-job-mode.png#lightbox)




![[検索ジョブが完了しました] という Azure Monitor ログ メッセージを示すスクリーンショット。](media/search-job/search-job-done.png#lightbox)
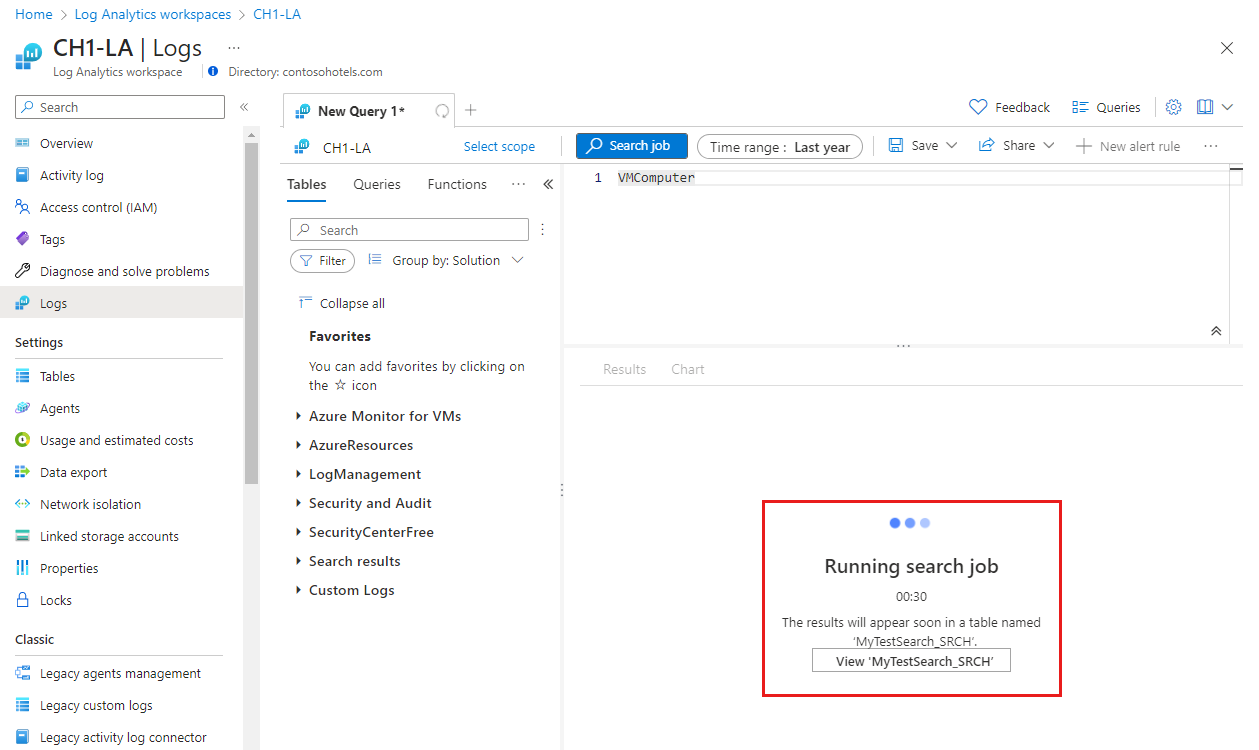
![Azure portal の [ログ] 画面の [テーブル] タブを示すスクリーンショット。[検索結果] の下に検索結果テーブルが一覧表示されています。](media/search-job/search-results-tables.png)
![Azure portal の [ログ] 画面の [テーブル] タブを示すスクリーンショット。[検索結果] の下に検索結果テーブルが一覧表示されています。](media/search-job/search-results-tables.png#lightbox)