音声サービスでは、音声リソースを使用して、音声テキスト変換とテキスト読み上げの機能が提供されます。 音声を高い精度でテキストに文字起こしし、自然に聞こえるテキスト読み上げ音声を生成し、音声を翻訳し、会話中に話者認識を使用することができます。

カスタム音声を作成したり、ベース ボキャブラリに特定の単語を追加したり、独自のモデルを構築したりできます。 音声サービスは、クラウドやコンテナーのエッジの任意の場所で実行できます。 Speech CLI、Speech SDK、REST API を使用して、アプリケーション、ツール、デバイスを簡単に音声対応にできます。
音声のシナリオ
音声サービスの一般的なシナリオは次のとおりです。
- キャプション: キャプションを入力オーディオと同期する方法、不適切表現フィルターを適用する方法、部分的な結果を取得する方法、カスタマイズを適用する方法、多言語シナリオで音声言語を識別する方法について学習します。
- オーディオ コンテンツの作成: ニューラル音声を使用すると、チャットボットや音声エージェントとの対話をより自然で魅力的なものにしたり、電子書籍などのデジタル テキストをオーディオブックに変換したり、カー ナビゲーション システムを強化したりできます。
- コール センター: 通話をリアルタイムで文字起こしするか、通話をバッチ処理して、個人を識別する情報を編集し、感情などの分析情報を抽出して、コール センターのユース ケースに役立てます。
- 言語学習: 言語学習者に発音評価フィードバックを提供し、リモート学習の会話でのリアルタイムの文字起こしをサポートし、ニューラル音声を使用して教材を読み上げます。
- 音声ライブ: アプリケーションとエクスペリエンスのための自然で人間のような会話インターフェイスを作成します。 音声ライブ機能は、人間とエージェントの実装の間の高速で信頼性の高い対話を提供します。
Teamsでのキャプション、Office 365でのディクテーション、Microsoft Edge ブラウザーでの音声読み上げなど、多くのシナリオで Speech が使われます。
音声機能
以下のセクションでは、Speech の機能の概要と、詳細情報へのリンクを示します。
音声からテキストへ変換
音声テキスト変換を使用して、リアルタイムまたは非同期でのバッチ文字起こしで音声をテキストに文字起こしします。
ヒント
Speech Studio では、サインアップやコードの記述を行わずに、リアルタイムの音声テキスト変換を試すことができます。
マイク、オーディオ ファイル、BLOB ストレージなど、さまざまなソースからオーディオをテキストに変換します。 話者のダイアリゼーションを使用して、誰がいつ何を言ったかを判断します。 自動での書式設定と句読点を使用して、読み取り可能なトランスクリプトを取得します。
音声に周囲の雑音が含まれている場合や、業界や分野固有の専門用語が大量に含まれている場合は、基本モデルでは不十分な場合があります。 このような場合は、音響、言語、および発音データを使用して、カスタム音声モデルを作成してトレーニングできます。 カスタム音声モデルは非公開であり、競争上の優位性を提供できます。
リアルタイムの音声テキスト変換
リアルタイムの音声テキスト変換では、スピーチがマイクまたはファイルから認識されると、音声が文字起こしされます。 リアルタイムで音声を文字起こしする必要がある次のようなアプリケーションには、リアルタイムの音声テキスト変換を使用します。
- ライブ会議の文字起こし、キャプション、または字幕
- ダイアライゼーション
- 発音評価
- コンタクト センター エージェントの支援
- ディクテーション
- 音声エージェント
ファスト トランスクリプション API
ファスト トランスクリプション API は、オーディオ ファイルを文字起こしし、その結果を同期して返すために使用されます。これは、リアルタイム オーディオよりもはるかに高速です。 ファスト トランスクリプションは、オーディオ録音の文字起こしを予測可能な待機時間でできるだけ早く必要とする次のようなシナリオで使用されます。
- オーディオまたはビデオの文字起こし、字幕、編集を迅速に行う場合。
- ビデオの翻訳
ファスト トランスクリプションを使い始める場合は、「ファスト トランスクリプション API を使用する」をご覧ください。
バッチ文字起こし
バッチ文字起こしは、ストレージ内の大量のオーディオを文字起こしする場合に使用されます。 Shared Access Signatures (SAS) URI でオーディオ ファイルを示して、非同期に文字起こしの結果を受け取ることができます。 次のようなオーディオを一括で文字起こしする必要があるアプリケーションでは、バッチ文字起こしを使用します。
- 事前に録音されたオーディオの文字起こし、キャプション、または字幕
- コンタクト センターの通話後の分析
- ダイアライゼーション
テキスト読み上げ
テキスト読み上げを使うと、入力テキストを人間のような合成音声に変換できます。 ディープ ニューラル ネットワークを利用した、人間に似た音声であるニューラル音声を使用します。 音声合成マークアップ言語 (SSML) を使用して、ピッチ、発音、読み上げ速度、ボリュームなどを微調整します。
- 標準音声: 非常に自然な、すぐに使える音声。 音声ギャラリーの標準音声サンプルを確認し、ビジネス ニーズに適した音声を決定します。
- カスタム音声:標準の音声だけでなく、ブランドや製品に固有の カスタム音声 を作成することもできます。 カスタム音声はプライベートであり、競争上の利点を提供できます。 ここでカスタム音声サンプルを確認 します。
音声翻訳
音声翻訳を使用すると、音声のリアルタイムの多言語翻訳がアプリケーション、ツール、デバイスで可能になります。 この機能は、音声間や音声テキスト変換の翻訳に使います。
言語識別
言語識別は、サポートされている言語の一覧と照合する際に、オーディオで話されている言語を識別するために使用されます。 言語識別は、単独で、または音声テキスト変換認識や音声翻訳と一緒に使用します。
話者認識
話者認識は、固有の音声特性によって話者を検証および識別するアルゴリズムを提供します。 話者認識は、"誰が話しているのか" という質問に回答するために使用されます。
発音評価
発音評価ではスピーチの発音を評価し、話された音声の正確性と流暢性に関するフィードバックを話者に提供します。 言語学習者は、発音評価を使用して練習を行い、即座にフィードバックを得て、発音を改善することができます。そのため、自信を持って話し、発表することができます。
意図認識
意図認識: 会話言語理解で音声テキスト変換を使用して、文字起こしされた音声からユーザーの意図を汲み取り、音声コマンドに従って行動します。
配信とプレゼンス
Azure AI 音声の機能は、クラウドまたはオンプレミスにデプロイできます。
コンテナーを使用すると、コンプライアンス、セキュリティ、またはその他の運用上の理由により、データにいっそう近いところにサービスを持ってくることができます。
ソブリン クラウドでの音声サービスのデプロイは、一部の政府機関とそのパートナーで利用できます。 たとえば、Azure Government クラウドは、米国政府のエンティティとそのパートナーが利用できます。 21Vianet によって運営される Microsoft Azure クラウドは、中国で事業を展開している組織で利用できます。 詳細については、ソブリン クラウドを参照してください。
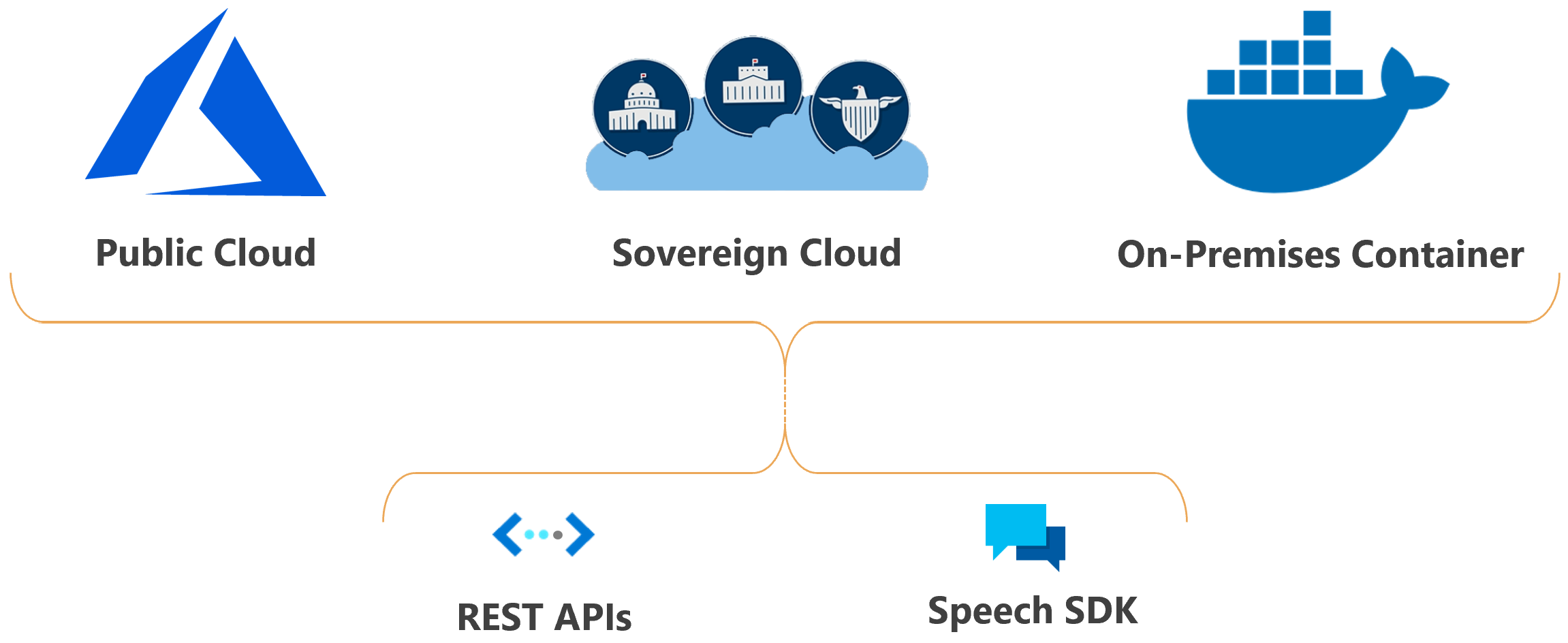
アプリケーションで Speech を使用する
Speech Studio は、アプリケーションで Azure AI 音声サービスの機能を構築および統合するための UI ベースのツールのセットです。 コーディングなしのアプローチを使用して Speech Studio でプロジェクトを作成し、Speech SDK、Speech CLI、または REST API を使用して、アプリケーション内のアセットを参照します。
Speech CLI は、コードを記述せずに Speech サービスを使用するためのコマンドライン ツールです。 Speech SDK の主な機能は、Speech CLI で利用できます。また、Speech CLI では、一部の高度な機能とカスタマイズが簡略化されています。
Speech SDK には、Speech サービスの各種機能が多数公開されており、これを使用して音声認識対応アプリケーションを開発できます。 Speech SDK は、多くのプログラミング言語と、すべてのプラットフォームで使用できます。
Speech SDK は使用できない場合や使用するべきではない場合があります。 そのような場合は、REST API を使用して Speech サービスにアクセスできます。 たとえば、バッチ文字起こしと話者認識のための REST API を使用します。
概要
多くの一般的なプログラミング言語でのクイックスタートを提供します。 それぞれのクイックスタートは、基本的な設計パターンを学び、10 分もかからずにコードを実行できるように作られています。 それぞれの機能のクイックスタートについては、次の記事を参照してください。
コード サンプル
Speech サービスのサンプル コードは、GitHub 上で入手できます。 これらのサンプルでは、ファイルやストリームからの音声の読み取り、連続的な認識と単発の認識、カスタム モデルの使用など、一般的なシナリオについて説明されています。 SDK と REST のサンプルを見るには、次のリンクを使用してください。
責任ある AI
AI システムには、テクノロジだけでなく、それを使用する人、それによって影響を受ける人、それがデプロイされる環境も含まれます。 「透明性に関するメモ」を読み、システムでの責任ある AI の使用とデプロイについて確認してください。
音声からテキストへ変換
発音評価
カスタム音声
- 透過性に関するメモとユースケース
- 特性と制限
- 制限付きアクセス
- 合成音声の責任あるデプロイ
- ボイス タレントの開示
- ガイドライン設計の開示
- 設計パターンの開示
- 倫理規定
- データ、プライバシー、セキュリティ