Important
Azure Cosmos DB for PostgreSQL は、新しいプロジェクトではサポートされなくなりました。 このサービスは、新しいプロジェクトには使用しないでください。 代わりに、次の 2 つのサービスのいずれかを使用します。
Azure Cosmos DB for NoSQL は、99.999% 可用性サービス レベル アグリーメント (SLA)、インスタント 自動スケール、および複数のリージョン間の自動フェールオーバーを使用する 大規模 なシナリオ向けに設計された分散データベース ソリューションに使用します。
オープンソースの Citus 拡張機能を使用して、シャード化された PostgreSQL 用の Azure Database For PostgreSQL のエラスティック クラスター機能 を使用します。
このチュートリアルでは、Azure Cosmos DB for PostgreSQL を使用して、次の方法を学習します。
- ハッシュ分散シャードを作成する
- テーブル シャードが配置されている場所を確認する
- 歪んだ分布を識別する
- 分散テーブルに対する制約の作成
- 分散データに対するクエリの実行
[前提条件]
このチュートリアルでは、2 つのワーカー ノードを備えた実行中のクラスターが必要です。 実行中のクラスターがない場合は、クラスターの作成に関するチュートリアルに従った後で、このチュートリアルに戻ってください。
ハッシュ分散データ
複数の PostgreSQL サーバー間でテーブル行を分散させるのは、Azure Cosmos DB for PostgreSQL でスケーラブルなクエリを実行するための主な手法です。 複数のノードを使用することにより、従来のデータベースよりも多くのデータを保持することができます。また、ワーカー CPU を並列で使用してクエリを実行できる場合も多くあります。 ハッシュ分散テーブルの概念は、行ベースのシャーディングとも呼ばれます。
前提条件のセクションでは、2 つのワーカー ノードを備えたクラスターを作成しました。
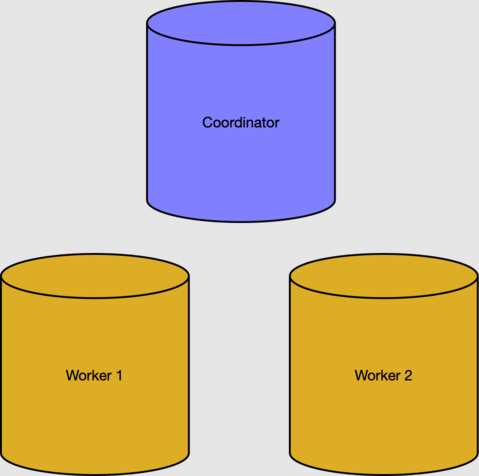
ワーカーと分散データは、コーディネーター ノードのメタデータ テーブルによって追跡されます。 アクティブなワーカーは、pg_dist_node テーブルで確認できます。
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
注記
Azure Cosmos DB for PostgreSQL におけるノード名は仮想ネットワーク内の内部 IP アドレスであり、表示される実際のアドレスは異なる場合があります。
行、シャード、配置
ワーカー ノードの CPU リソースとストレージ リソースを使用するには、クラスター全体にテーブル データを分散する必要があります。 テーブルを分散すると、各行は シャード と呼ばれる論理グループに割り当てられます。テーブルを作成し配布しましょう:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Azure Cosmos DB for PostgreSQL により、"分散列" (今回は email を指定) の値に基づいて各行がシャードに割り当てられます。 どの行も、いずれか 1 つのシャード内に含まれます。また、どのシャードにも複数の行を含めることができます。
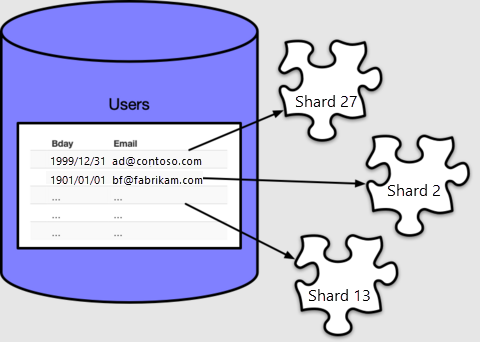
既定では、create_distributed_table() によって 32 個のシャードが作成されます。このことはメタデータ テーブル pg_dist_shard でカウントすることで確認できます。
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Azure Cosmos DB for PostgreSQL では、分散列の値のハッシュに基づき、pg_dist_shard テーブルを使用して行をシャードに割り当てます。 このチュートリアルでは、ハッシュの詳細は特に重要ではありません。 重要なのは、どの値がどのシャード ID にマッピングされているかをクエリで確認できるということです。
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
シャードへの行のマッピングは完全に論理的なものです。 シャードは、ストレージの特定のワーカー ノードに割り当てられている必要があります。このことは Azure Cosmos DB for PostgreSQL では "シャード配置" と呼ばれます。
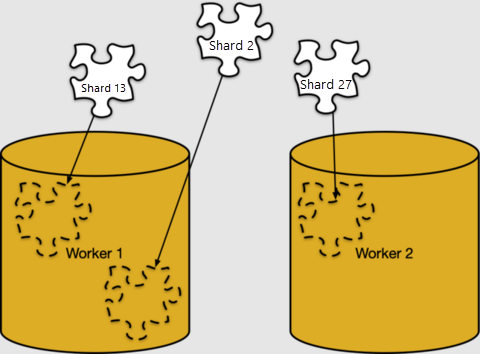
シャード配置は pg_dist_placement で確認できます。 これをこれまでに見てきた他のメタデータ テーブルと結合すると、各シャードが存在する場所がわかります。
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
データの偏り
クラスターは、ワーカー ノードにデータが均等に配置されたときと、関連するデータが同じワーカーに配置されたときに、最も効率的に実行されます。 このセクションでは、1 つ目の部分、つまり配置の統一性に焦点を当てます。
例として、users テーブルのサンプル データを作成してみましょう。
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
シャードのサイズを確認するには、シャード上でテーブル サイズ関数を実行します。
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
シャードのサイズが均等であることがわかります。 配置がワーカー間で均等に分散されていることが既に確認できているので、各ワーカー ノードにはほぼ同数の行が保持されていると推測できます。
users の例の行は、分散列 email の特性により、均等に分散されています。
- メール アドレスの数がシャードの数以上でした。
- メール アドレスあたりの行数が近似している (ここではメール アドレスをキーとして宣言したため、アドレスごとに 1 行のみ)。
どちらかの状態に当てはまらないテーブルや分散列を選ぶと、ワーカー上のデータ サイズが不均等になり、"データ スキュー" になります。
分散データに制約を追加する
Azure Cosmos DB for PostgreSQL を使用すると、リレーショナル データベースの安全性 (データベースの制約を含む) を引き続き享受できます。 ただし、次のような制限があります。 分散システムの性質により、Azure Cosmos DB for PostgreSQL では、ワーカー ノード間の一意性制約または参照整合性を相互参照しません。
users テーブルの例を、関連するテーブルと一緒に考えてみましょう。
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
効率を上げるために、books は所有者のメールアドレスを使用して users と同じ方法で分散させます。 類似した列の値による分散はコロケーションと呼ばれます。
キーが分散列にあったため、books を users への外部キーで分散させることに問題はありませんでした。 ただし、isbn キーの作成においては問題が発生します。
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
分散テーブルでは、分散列を基にして、列を一意にするのが最善の方法です。
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
上記の制約により、ユーザーごとに単に isbn が一意になります。 別の方法として、books を分散テーブルではなく参照テーブルにして、books を users に関連付ける別の分散テーブルを作成することもできます。
分散テーブルに対してクエリを実行する
前のセクションでは、分散テーブルの行がワーカー ノード上のシャードにどのように配置されているかを説明しました。 ほとんどの場合、データがクラスターのどこに、またはどのように格納されるかを把握しておく必要はありません。 Azure Cosmos DB for PostgreSQL には、通常の SQL クエリを自動的に分割する分散クエリ実行プログラムが備わっています。 これは、データの近くにあるワーカー ノード上で並列に実行されます。
たとえば、分散済みの users テーブルをコーディネーター上で通常のテーブルのように扱うことにより、ユーザーの平均年齢を調べるというクエリを実行することができます。
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
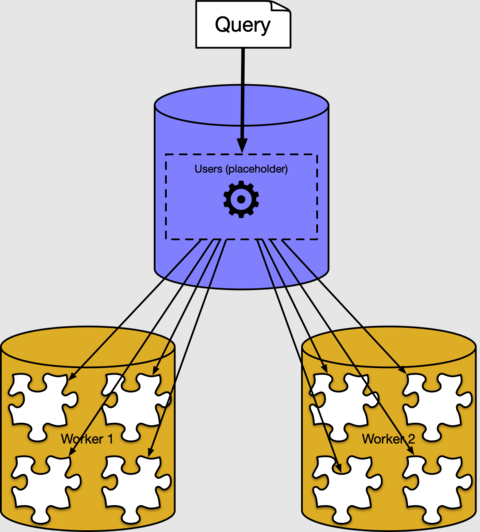
バックグラウンドでは、Azure Cosmos DB for PostgreSQL クエリ実行プログラムによって各シャードに対して個別のクエリが作成され、それらがワーカー上で実行され、結果が結合されています。 PostgreSQL の EXPLAIN コマンドを使用すると、次のように確認できます。
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
出力には、シャード 102040 (ワーカー 10.0.0.21 上のテーブル ) で実行中の "users_102040" の実行プランの例が示されています。 他のフラグメントは類似しているため、表示されません。 ワーカー ノードによってシャード テーブルがスキャンされ、集計が適用されていることがわかります。 最終的な結果の集計は、コーディネーター ノードによって結合されます。
次のステップ
このチュートリアルでは、分散テーブルを作成し、そのシャードと配置について学習しました。 一意性制約と外部キー制約を使用するという課題を確認し、最後に分散クエリが上位レベルで動作するしくみを確認しました。
- Azure Cosmos DB for PostgreSQL のテーブルの種類の詳細を確認する
- 分散列の選択に関する詳細なヒントを見る
- テーブル コロケーションのメリットを学ぶ