シンクの最適化
データ フローからシンクに書き込みを行なう場合、カスタム パーティション分割は書き込みの直前に発生します。 ソースと同様に、ほとんどの場合、[Use current partitioning] (現在のパーティション分割を使用する) を選択されたパーティション オプションとしてそのまま使用することをお勧めします。 パーティション分割されたデータは、書き込み先がパーティションに分割されていない場合でも、パーティション分割されていないデータよりもはるかに高速に書き込まれます。 以下に、さまざまなシンクの種類に関する個別の考慮事項を示します。
Azure SQL Database のシンク
Azure SQL Database では、ほとんどの場合、既定のパーティション分割が有効です。 シンクに含まれるパーティションが多すぎると SQL データベースで処理できないことがあります。 これが発生した場合は、SQL Database シンクによって出力されるパーティションの数を減らします。
ソースの存在しない行に基づいてシンクの行を削除するためのベスト プラクティス
以下は、この一般的なパターンを実現するために、終了、行の変更、シンクの変換でデータ フローを使用する方法についてのビデオ チュートリアルです。
エラー行の処理がパフォーマンスに及ぼす影響
シンク変換でエラー行の処理 ([エラーでも続行]) を有効にした場合、サービスによって追加の手順が実施されてから、互換性のある行が変換先テーブルに書き込まれます。 この追加の手順により 5% の範囲でパフォーマンスがわずかに低下します。また互換性のない行をログ ファイルに書き込むオプションを設定した場合は、パフォーマンスがさらにわずかに低下します。
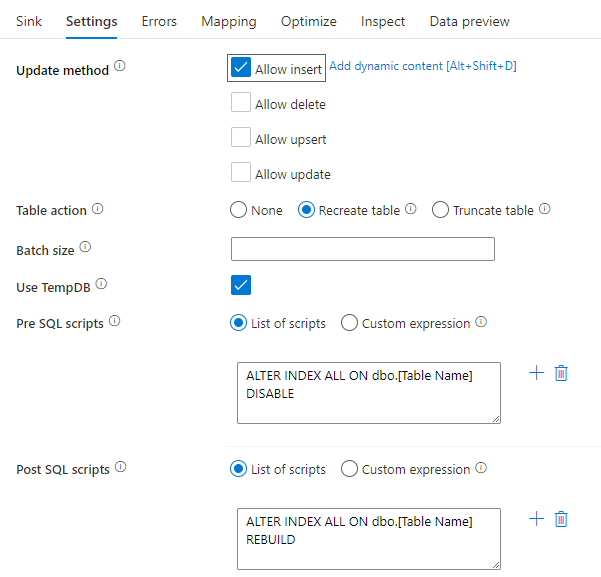
SQL スクリプトを使用したインデックスの無効化
SQL データベースで読み込み前にインデックスを無効にすると、テーブルへの書き込みのパフォーマンスが大幅に向上します。 SQL シンクに書き込む前に、次のコマンドを実行します。
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
書き込みが完了したら、次のコマンドを使用してインデックスを再構築します。
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
これらは両方とも、マッピング データ フローの Azure SQL Database または Synapse シンク内で、Post-SQL スクリプトを使用してネイティブに実行できます。
警告
インデックスを無効にすると、実質的にデータ フローでデータベースが制御されますが、クエリはこの時点では成功しない可能性があります。 その結果、この競合を回避するために、多くの ETL ジョブが夜間にトリガーされます。 詳細については、SQL インデックスの無効化に関する制約を参照してください
データベースのスケールアップ
DTU の制限に達したら、ソースとシンクの Azure SQL DB と DW のサイズ変更をスケジュールしてから、パイプラインを実行して、スループットを増やし、Azure スロットルを最小化します。 パイプラインの実行が完了したら、データベースのサイズを変更して通常のラン レートに戻します。
Azure Synapse Analytics のシンク
Azure Synapse Analytics に書き込むときは、 [Enable staging](ステージングの有効化) が true に設定されていることを確認してください。 これにより、サービスでは SQL COPY コマンドを使用した書き込みが可能になり、データが一括で効率的に読み込まれます。 ステージングを使用する場合は、データのステージングのために Azure Data Lake Storage gen2 または Azure Blob Storage アカウントを参照する必要があります。
ステージング以外でも、Azure Synapse Analytics に Azure SQL Database と同じベスト プラクティスが適用されます。
ファイルベースのシンク
データ フローではさまざまなファイルの種類がサポートされますが、読み取りと書き込みを最適に行なうために、Spark ネイティブの Parquet 形式をお勧めします。
データが均等に分散されている場合は、[Use current partitioning] (現在のパーティション分割を使用する) が、ファイルを書き込むための最も高速なパーティション分割オプションになります。
ファイル名のオプション
ファイルの作成時は、それぞれにパフォーマンスへの影響がある名前付けオプションを選択できます。
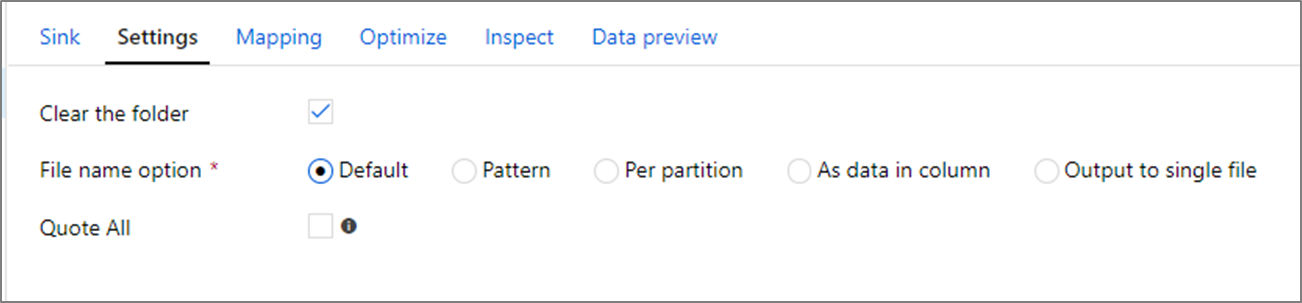
[既定] オプションを選択すると、書き込みが最速になります。 各パーティションは、Spark の既定の名前を持つファイルに相当します。 これは、データのフォルダーから読み取るだけの場合に便利です。
名前付けのパターンを設定すると、各パーティション ファイルの名前がわかりやすい名前に変更されます。 この操作は書き込み後に行われ、既定値を選択するよりも若干遅くなります。
パーティションごとに、個々のパーティションに手動で名前を指定できます。
列が希望するデータ出力方法に対応している場合は、[列データでファイルに名前を付ける] を選択できます。 これによりデータが再シャッフルされ、列が均等に分散されていない場合には、パフォーマンスに影響を与える可能性があります。
列がフォルダー名の生成方法に対応している場合は、 [列データでフォルダーに名前を付ける] を選択します。
[Output to single file](単一ファイルへの出力) では、すべてのデータが単一のパーティションに結合されます。 これにより、特に大規模なデータセットでは、書き込み時間が長くなります。 このオプションは、明示的なビジネス上の使用理由がない限りは推奨されません。
Azure Cosmos DB シンク
Azure Cosmos DB に書き込む場合、データ フローの実行中にスループットとバッチ サイズを変更すると、パフォーマンスが向上する可能性があります。 これらの変更はデータ フロー アクティビティの実行中にのみ有効になり、終了後に元のコレクション設定に戻ります。
バッチ サイズ: 通常、既定のバッチ サイズで開始するだけで十分です。 この値をさらに調整するには、データの大まかなオブジェクト サイズを計算し、オブジェクト サイズ * バッチ サイズが 2 MB 未満であることを確認します。 その場合は、バッチ サイズを増やしてスループットを向上できます。
スループット: ここでより高いスループットを設定して、Azure Cosmos DB にドキュメントを高速で書き込むことができるようにします。 高いスループットの設定に基づいて、RU コストが高くなることに注意してください。
書き込みスループット予算: 1 分あたりの RU の合計よりも小さい値を使用してください。 多数の Spark パーティションが含まれるデータ フローがある場合、予算のスループットを設定すると、これらのパーティション間でより均等にバランスを取ることができます。
関連するコンテンツ
パフォーマンスに関する Data Flow のその他の記事を参照してください。