Azure SQL Database を除くすべてのソースについて、選択した値として 現在のパーティション分割を使用 することをお勧めします。 他のすべてのソース システムから読み取る場合、データ フローはデータのサイズに基づいてデータを均等に分割します。 約 128 MB のデータに対して新しいパーティションが作成されます。 データ サイズが大きくなると、パーティションの数が増加します。
カスタム パーティション分割は、Spark がデータを読み取った 後 に行われ、データ フローのパフォーマンスに悪影響を与えます。 データは読み取り時に均等にパーティション分割されるため、最初にデータの形状とカーディナリティを理解しない限り、推奨されません。
注
読み取り速度は、ソース システムのスループットによって制限できます。
Azure SQL Database のソース
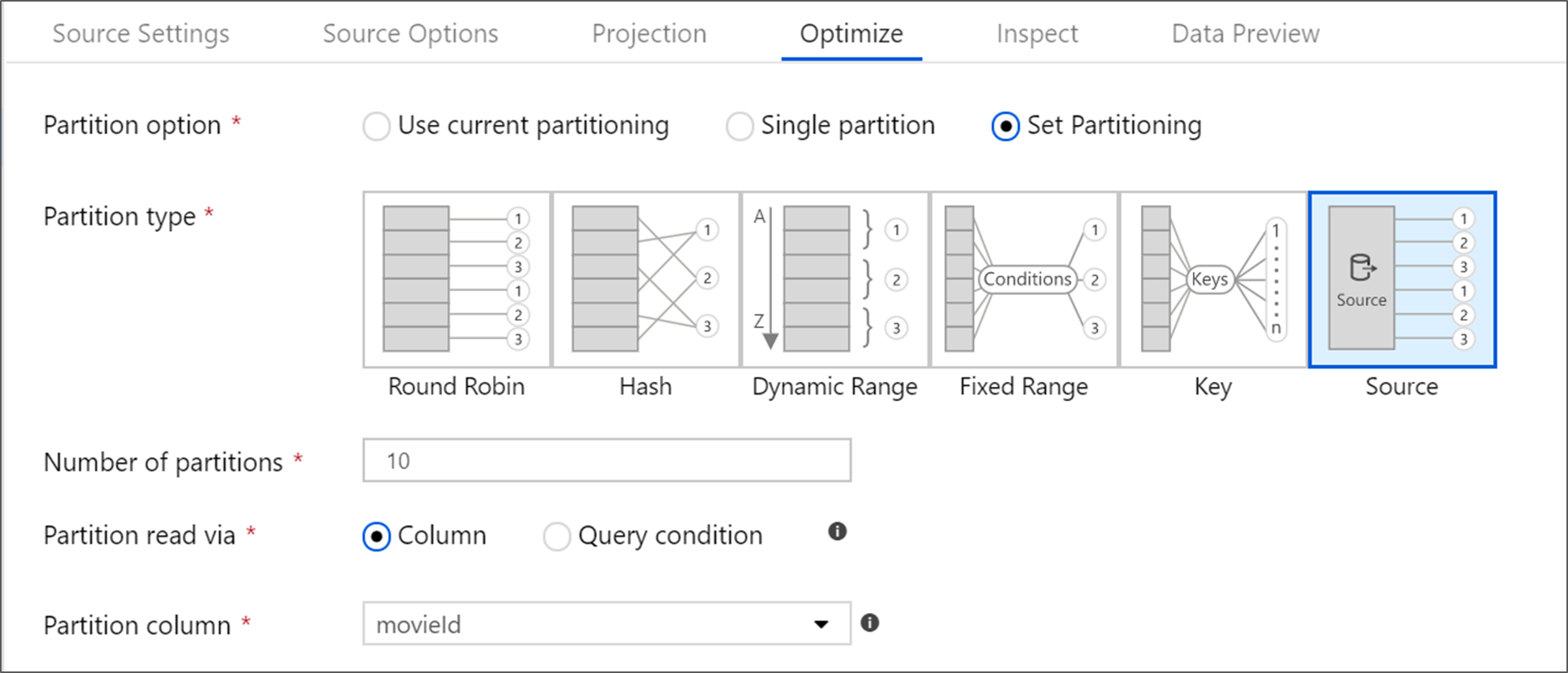
Azure SQL Database には、"ソース" パーティション分割と呼ばれる一意のパーティション分割オプションがあります。 ソースパーティション分割を有効にすると、ソース システムで並列接続を有効にすることで、Azure SQL Database からの読み取り時間を短縮できます。 パーティションの数とデータのパーティション分割方法を指定します。 カーディナリティが高いパーティション列を使用します。 また、ソース テーブルのパーティション構成に一致するクエリを入力することもできます。
ヒント
ソースパーティション分割の場合、SQL Server の I/O がボトルネックになります。 パーティションを追加しすぎると、ソース データベースが飽和する可能性があります。 通常、このオプションを使用する場合は、4 つまたは 5 つのパーティションが最適です。
分離レベル
Azure SQL ソース システムでの読み取りの分離レベルは、パフォーマンスに影響します。 [Read uncommitted] (コミットされていない読み取り) を選択すると、パフォーマンスが最も速く、データベース ロックが防止されます。 SQL 分離レベルの詳細については、「分離 レベルについて」を参照してください。
クエリを使用した読み取り
テーブルまたは SQL クエリを使用して、Azure SQL Database から読み取ることができます。 SQL クエリを実行する場合は、変換を開始する前にクエリを完了する必要があります。 SQL クエリは、より高速に実行できる操作をプッシュダウンし、SELECT、WHERE、JOIN ステートメントなどの SQL Server から読み取られるデータの量を減らす場合に役立ちます。 操作をプッシュダウンすると、データがデータ フローに入る前に、変換の系列とパフォーマンスを追跡する機能が失われます。
Azure Synapse Analytics ソース
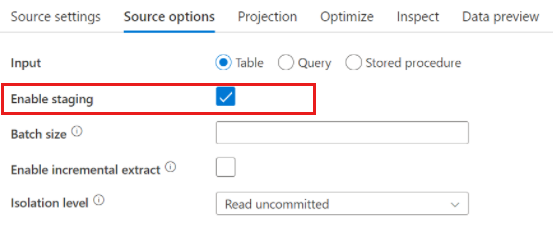
Azure Synapse Analytics を使用する場合は、ソース オプションに [ステージングを有効にする] という設定が存在します。 これにより、サービスは Staging を使用して Synapse から読み取ることができます。これにより、CETAS や COPY コマンドなどの最もパフォーマンスの高い一括読み込み機能を使用して読み取りパフォーマンスが大幅に向上します。
Stagingを有効にするには、データ フロー アクティビティの設定で Azure Blob Storage または Azure Data Lake Storage gen2 のステージング場所を指定する必要があります。
ファイル ベースのソース
Parquet と区切りテキストの比較
データ フローではさまざまな種類のファイルがサポートされますが、読み取りと書き込みの最適な時間を実現するために、Spark ネイティブの Parquet 形式をお勧めします。
一連のファイルで同じデータ フローを実行している場合は、フォルダーからの読み取り、ワイルドカード パスの使用、またはファイルの一覧からの読み取りをお勧めします。 1 つのデータ フロー アクティビティの実行で、すべてのファイルをバッチ処理できます。 これらの設定を構成する方法の詳細については、Azure Blob Storage コネクタのドキュメントのソース変換セクションを参照してください。
可能であれば、For-Each アクティビティを使用して一連のファイルに対してデータ フローを実行することは避けてください。 これにより、for-each の各イテレーションが独自の Spark クラスターを起動します。これは、多くの場合、不要であり、コストがかかる可能性があります。
インライン データセットと共有データセット
ADF データセットと Synapse データセットは、ファクトリとワークスペース内の共有リソースです。 ただし、区切りテキストと JSON ソースを使用して多数のソース フォルダーとファイルを読み取る場合は、Projection | 内で [ユーザー投影スキーマ] オプションを設定することで、データ フロー ファイルの検出のパフォーマンスを向上させることができます。[スキーマ オプション] ダイアログ。 このオプションにより、ADF の既定のスキーマ自動検出がオフになり、ファイル検出のパフォーマンスが大幅に向上します。 このオプションを設定する前に、プロジェクション用の既存のスキーマが ADF に含まれるように、プロジェクションをインポートしてください。 このオプションは、スキーマ ドリフトでは機能しません。
関連するコンテンツ
パフォーマンスに関連するその他のデータ フローに関する記事を参照してください。