適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
Data Flow アクティビティを使用して、マッピング データ フローを使用してデータを変換および移動します。 データ フローを初めて使用する場合は、「Mapping Data Flowの概要」を参照してください>
UI を使用してData Flow アクティビティを作成する
パイプラインでData Flow アクティビティを使用するには、次の手順を実行します。
パイプライン アクティビティ ウィンドウで Data Flow を検索し、Data Flow アクティビティをパイプライン キャンバスにドラッグします。
キャンバス上の新しいData Flow アクティビティがまだ選択されていない場合は選択し、そのSettings タブを選択して詳細を編集します。
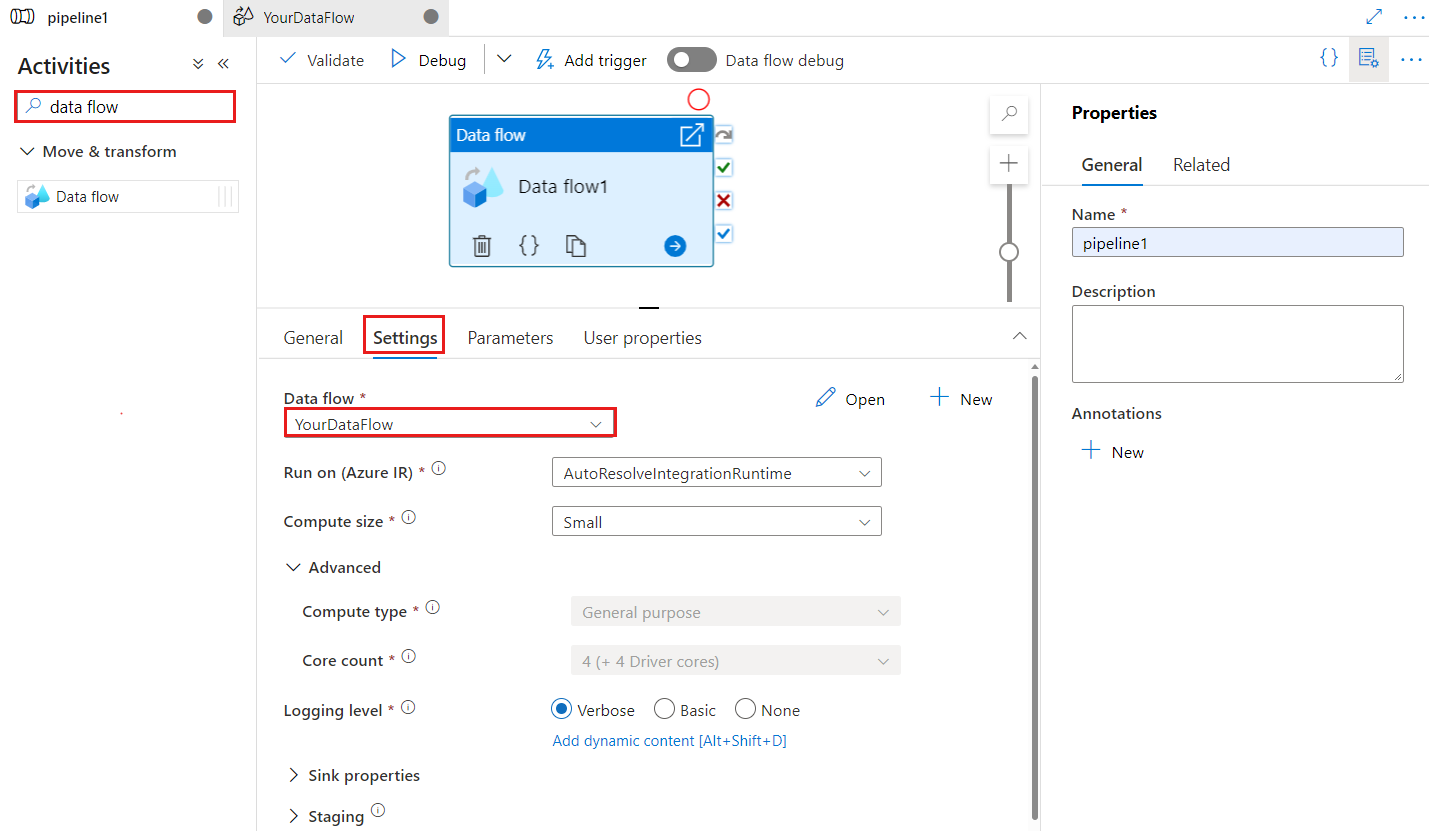
チェックポイント キーは、データ フローが変更されたデータ キャプチャに使用されるときにチェックポイントを設定するために使用されます。 上書きすることができます。 データ フロー アクティビティでは、"パイプライン名 + アクティビティ名" ではなくチェックポイント キーとして guid 値を使用するため、名前変更アクションがある場合でも、顧客の変更データ キャプチャの状態を常に追跡できます。 既存のすべてのデータ フロー アクティビティは、下位互換性のために古いパターン キーを使用します。 変更データ キャプチャが有効なデータ フロー リソースを使用して、新しいデータ フロー アクティビティをパブリッシュした後のチェックポイント キーのオプションを次に示します。
既存のデータ フローを選択するか、[新規作成] ボタンを使用して新しく作成します。 必要に応じてその他のオプションを選択し、構成を完了します。
構文
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
型のプロパティ
| プロパティ | 説明 | 使用できる値 | 必須 |
|---|---|---|---|
| データフロー | 実行中のData Flowへの参照 | DataFlowReference | はい |
| integrationRuntime | データ フローが実行されているコンピューティング環境です。 指定しない場合は、Azure 統合ランタイムの自動選択が使用されます。 | インテグレーションランタイムリファレンス | いいえ |
| compute.coreCount | Spark クラスター内で使用されるコアの数です。 Azure 統合ランタイムの自動解決が使用されている場合にのみ指定できます | 8、16、32、48、80、144、272 | いいえ |
| compute.computeType | Spark クラスター内で使用されるコンピューティングの種類です。 Azure 統合ランタイムの自動解決が使用されている場合にのみ指定できます | "一般" | いいえ |
| staging.linkedService | Azure Synapse Analyticsソースまたはシンクを使用している場合は、PolyBase ステージングに使用するストレージ アカウントを指定します。 Azure Storageが VNet サービス エンドポイントで構成されている場合は、ストレージ アカウントで "信頼されたMicrosoft サービスを許可する" が有効になっているマネージド ID 認証を使用する必要があります。 Azure storage で VNet サービス エンドポイントを使用する場合の詳細を参照してください。 また、Azure BLOB と Azure Data Lake Storage Gen2 に必要な構成についても説明します。 |
リンクドサービスリファレンス | データ フローがAzure Synapse Analyticsに対して読み取りまたは書き込みを行う場合のみ |
| staging.folderPath | Azure Synapse Analytics ソースまたはシンクを使用している場合は、PolyBase ステージングに使用する BLOB ストレージ アカウント内のフォルダー パス | String | データ フローが Azure Synapse Analytics に対して読み取りまたは書き込みを行う場合のみ |
| traceLevel | データ フロー アクティビティの実行のログ レベルを設定します | Fine、Coarse、None | いいえ |
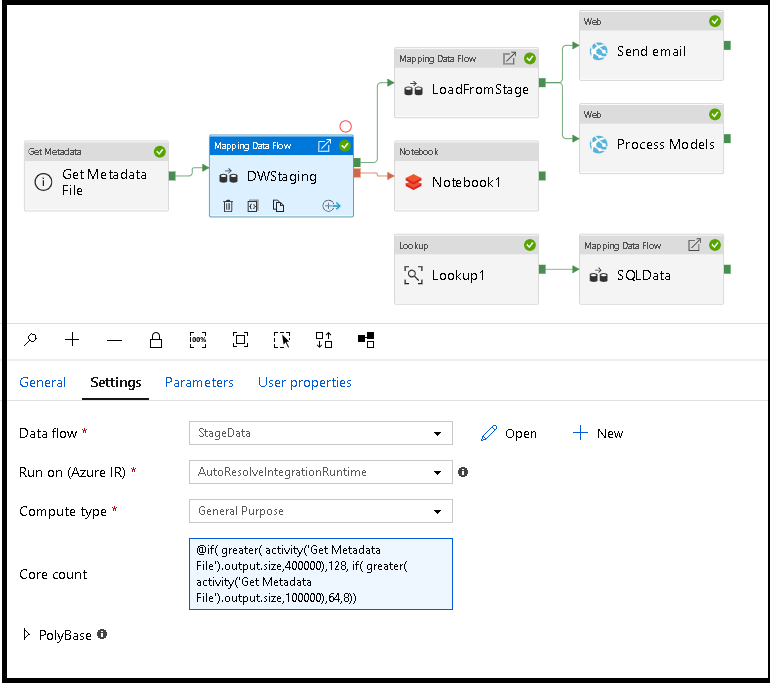
実行時、データ フロー コンピューティングのサイズを動的に設定する
Core Count プロパティと Compute Type プロパティは、実行時に入ってくるソース データのサイズに合わせて調整されるよう、動的に設定できます。 ソース データセット データのサイズを見つける目的で、Lookup や Get Metadata など、パイプライン アクティビティを使用します。 次に、Data Flow アクティビティのプロパティで動的コンテンツの追加を使用します。 小、中、または大規模のコンピューティング サイズを選択できます。 必要に応じて、[カスタム] を選択し、コンピューティングの種類とコア数を手動で構成します。
こちらの短い動画チュートリアルでこの手法について説明しています
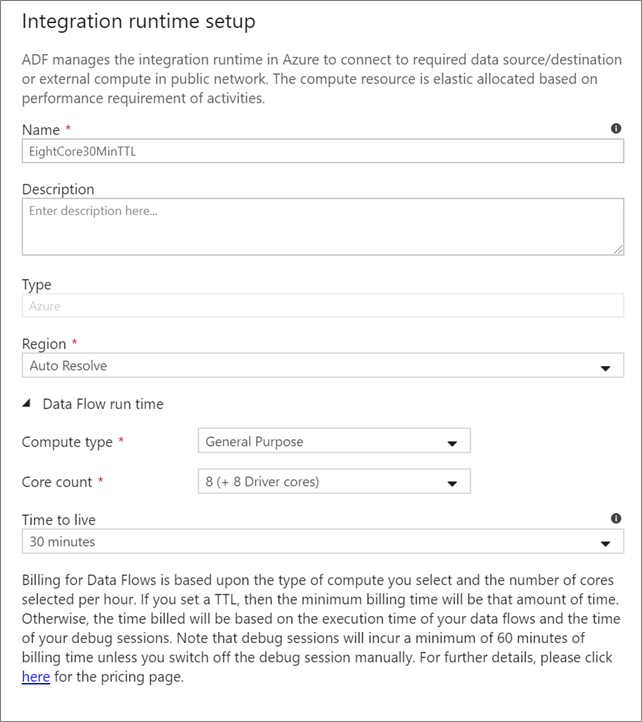
Data Flow統合ランタイム
Data Flow アクティビティの実行に使用するIntegration Runtimeを選択します。 既定では、サービスは、4 つのワーカー コアAzure統合ランタイムの自動解決を使用します。 この IR は汎用目的のコンピューティングの種類で、ご使用のサービス インスタンスと同じリージョンで実行します。 運用化されたパイプラインの場合は、データ フロー アクティビティの実行に特定のリージョン、コンピューティングの種類、コア数、TTL を定義する独自のAzure統合ランタイムを作成することを強くお勧めします。
General Purpose の最小コンピューティング タイプが 8 + 8 (合計 16 個の v コア) の構成で、ほとんどの運用ワークロードの最小推奨は 10 分の Time to live (TTL) です。 小さな TTL を設定することで、Azure IR はウォーム クラスターを維持でき、コールド クラスターの起動にかかる数分の遅延を回避できます。 詳細については、「Azure 統合ランタイムを参照してください。
重要
Data Flow アクティビティのIntegration Runtimeの選択は、パイプラインのトリガーされた実行にのみ適用されます。 データ フローを使用したパイプラインのデバッグは、デバッグ セッションで指定されたクラスターで実行されます。
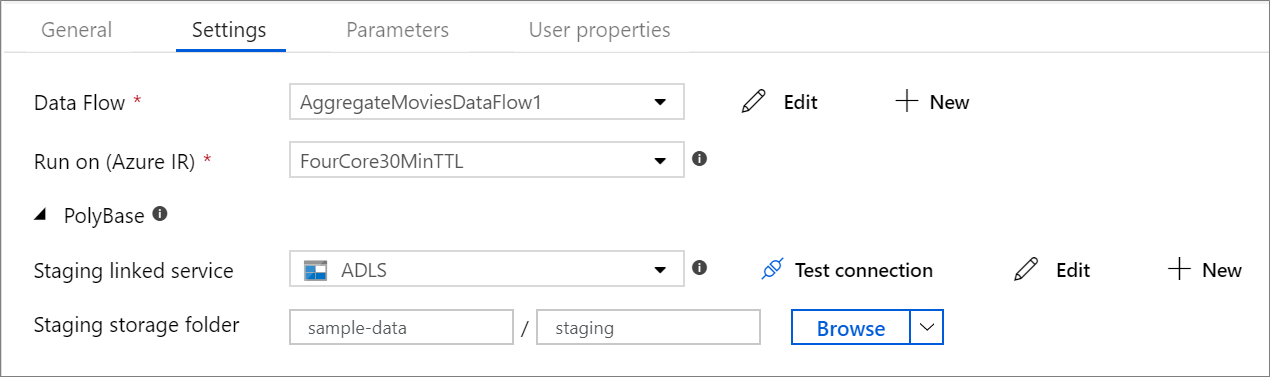
PolyBase
シンクまたはソースとしてAzure Synapse Analyticsを使用している場合は、PolyBase バッチ読み込みのステージング場所を選択する必要があります。 PolyBase を使用すると、データを行ごとに読み込む代わりに一括してバッチ読み込みを行うことができます。 PolyBase を使用すると、読み込み時間がAzure Synapse Analyticsに大幅に短縮されます。
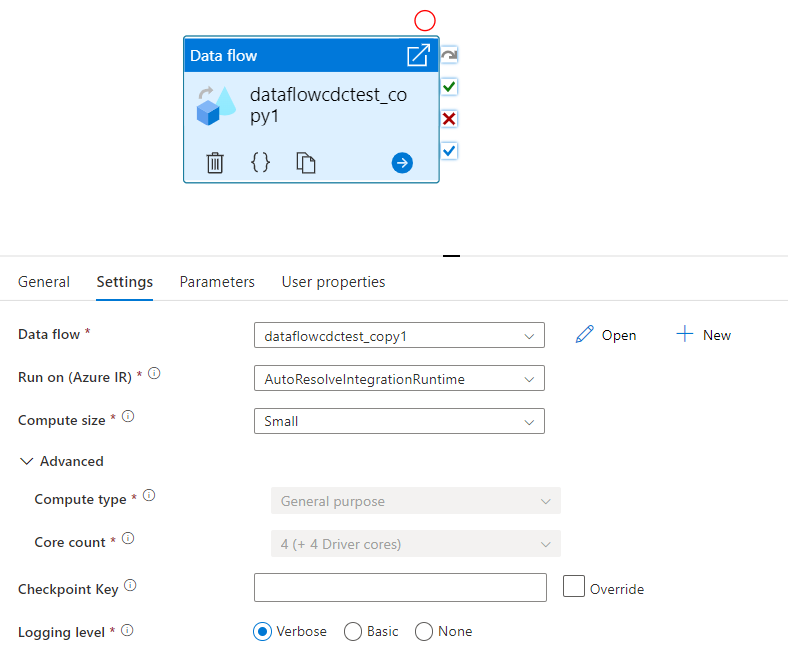
チェックポイント キー
データ フロー ソースの変更キャプチャ オプションを使用すると、ADF はユーザーの代わりに自動的にチェックポイントの保持と管理を行います。 既定のチェックポイント キーは、データ フロー名とパイプライン名のハッシュです。 ソース テーブルまたはフォルダーに動的パターンを使用する場合は、このハッシュを上書きして、独自のチェックポイント キーの値をここに設定することをお勧めします。
ログ記録レベル
データ フロー アクティビティのすべてのパイプライン実行がすべての詳細なテレメトリ ログを完全にログ記録する必要がない場合は、必要に応じてログ レベルを "Basic" または "None" に設定できます。 データ フローを "Verbose" モード (既定値) で実行している場合、データ変換中に個別のパーティション レベルのそれぞれでアクティビティを完全にログ記録するように、サービスに要求していることになります。 これはコストのかかる操作であるため、トラブルシューティング中のみ詳細ログを有効にすることにより、データフローとパイプラインの全体的なパフォーマンスを向上させることができます。 "Basic" モードは変換の実行時間だけをログ記録し、"None" は実行時間の要約だけを記録します。

シンクのプロパティ
データ フローのグループ化機能を使用すると、シンクの実行順序を設定できるだけでなく、同じグループ番号を使用してシンクをグループ化できます。 グループを管理しやすくするため、シンクを同じグループ内で並列で実行するように、サービスに要求できます。 また、いずれかのシンクでエラーが発生しても続行するようにシンク グループを設定することもできます。
データ フロー シンクの既定の動作では、各シンクが逐次実行され、シンクでエラーが発生した場合はデータ フローが失敗します。 さらに、データ フロー プロパティでシンクに異なる優先順位を設定しない限り、すべてのシンクは既定で同じグループに設定されます。

先頭行のみ
このオプションは、"アクティビティへの出力" でキャッシュ シンクが有効になっているデータ フローでのみ使用できます。 パイプラインに直接挿入されるデータ フローからの出力は、2 MB に制限されます。 "最初の行のみ" を設定すると、データ フロー アクティビティの出力をパイプラインに直接挿入する際に、データ フローからのデータ出力を制限することができます。
データ フローをパラメーター化する
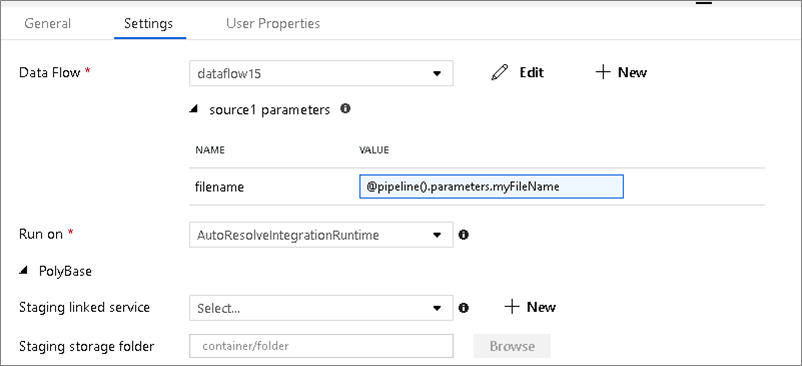
パラメーター化されたデータセット
データ フローでパラメーター化されたデータセットを使用する場合は、 [設定] タブでパラメーター値を設定します。
パラメーター化されたデータ フロー
データ フローがパラメーター化されている場合は、 [パラメーター] タブでデータ フロー パラメーターの動的な値を設定します。パイプライン式言語またはデータ フロー式言語のいずれかを使用して、動的パラメーター値またはリテラル パラメーター値を割り当てることができます。 詳細については、「Data Flow パラメーターを参照してください。
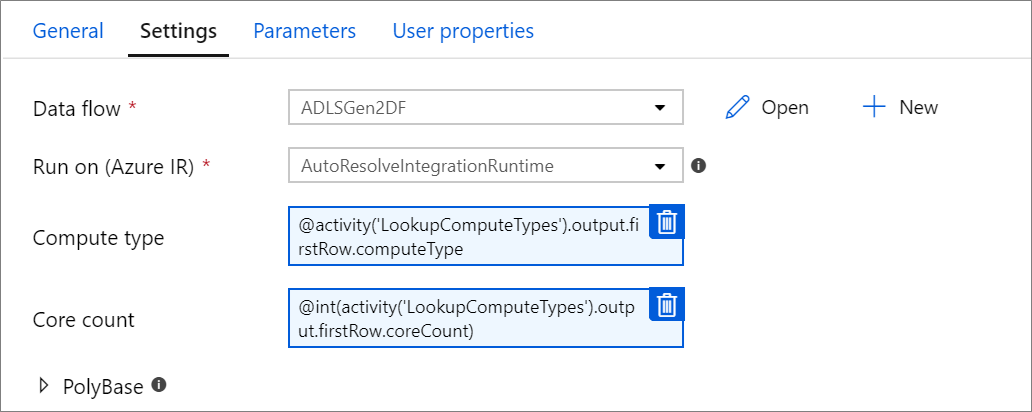
パラメーター化されたコンピューティングのプロパティ
統合ランタイムAzure自動解決を使用し、compute.coreCount と compute.computeType の値を指定する場合は、コア数またはコンピューティングの種類をパラメーター化できます。
Data Flow アクティビティのパイプライン デバッグ
データ フロー アクティビティを使用してデバッグ パイプラインを実行するには、上部バーの Data Flow Debug スライダーでデータフロー デバッグ モードをオンにする必要があります。 デバッグ モードでは、アクティブな Spark クラスターに対してデータ フローを実行できます。 詳細については、デバッグ モードに関するページを参照してください。
![[デバッグ] ボタンの場所を示すスクリーンショット](media/data-flow/debug-button-3.png)
デバッグ パイプラインは、Data Flow アクティビティ設定で指定された統合ランタイム環境ではなく、アクティブなデバッグ クラスターに対して実行されます。 デバッグ モードを開始するときに、デバッグ コンピューティング環境を選択できます。
Data Flow アクティビティの監視
Data Flow アクティビティには、パーティション分割、ステージ時間、およびデータ系列情報を表示できる特別な監視エクスペリエンスがあります。 [アクション] の下にある眼鏡アイコンを使用して、[監視] ウィンドウを開きます。 詳しくは、データ フローの監視に関するページを参照してください。
Data Flowアクティビティの結果を後続のアクティビティで使用する
データ フロー アクティビティは、各シンクに書き込まれた行の数と各ソースから読み取られた行に関するメトリックを出力します。 これらの結果は、アクティビティの実行結果の output セクションに返されます。 返されるメトリックは、以下の JSON の形式です。
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
たとえば、'dataflowActivity' という名前のアクティビティで、'sink1' という名前のシンクに書き込まれた行の数を取得するには、@activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten を使用します。
このシンクで使用されていた、'source1' という名前のソースから読み取られた行の数を取得するには、@activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead を使用します。
注意
シンクに書き込まれる行数がゼロの場合、メトリクスに表示されません。 存在を確認するには、contains 関数を使用します。 たとえば、contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') は、sink1 に何らかの行が書き込まれたかどうかを確認します。
関連するコンテンツ
サポートされている制御フロー アクティビティを参照してください。