適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
Azure Data Factoryパイプラインと Synapse パイプラインのマッピング データ フローは、大規模なデータ変換を設計および実行するためのコード不要のインターフェイスを提供します。 マッピング データ フローに慣れていない場合は、「マッピングData Flowの概要を参照してください。 この記事では、パフォーマンスのベンチマークを満たすようにデータ フローを調整および最適化するさまざまな方法について説明します。
次のビデオでは、データ フローを使用してデータを変換するタイミングのサンプルを示します。
データ フローのパフォーマンスを監視する
デバッグ モードを使用して変換ロジックを確認したら、パイプラインでアクティビティとしてデータ フローをエンドツーエンドで実行します。 データ フローは、パイプラインでデータ フローの実行アクティビティを使用して運用可能にすることができます。 データ フロー アクティビティには、他のアクティビティと比較して独自の監視エクスペリエンスが用意されており、変換ロジックの詳細な実行プランとパフォーマンス プロファイルを表示できます。 データ フローの詳細な監視情報を表示するには、パイプラインのアクティビティの実行出力で眼鏡アイコンを選択します。 詳細については、マッピング データ フローの監視に関するページを参照してください。

データ フローのパフォーマンスを監視する場合、次の 4 つのボトルネックが考えられます:
- クラスターの起動時間
- ソースからの読み取り
- 変換時間
- シンクへの書き込み
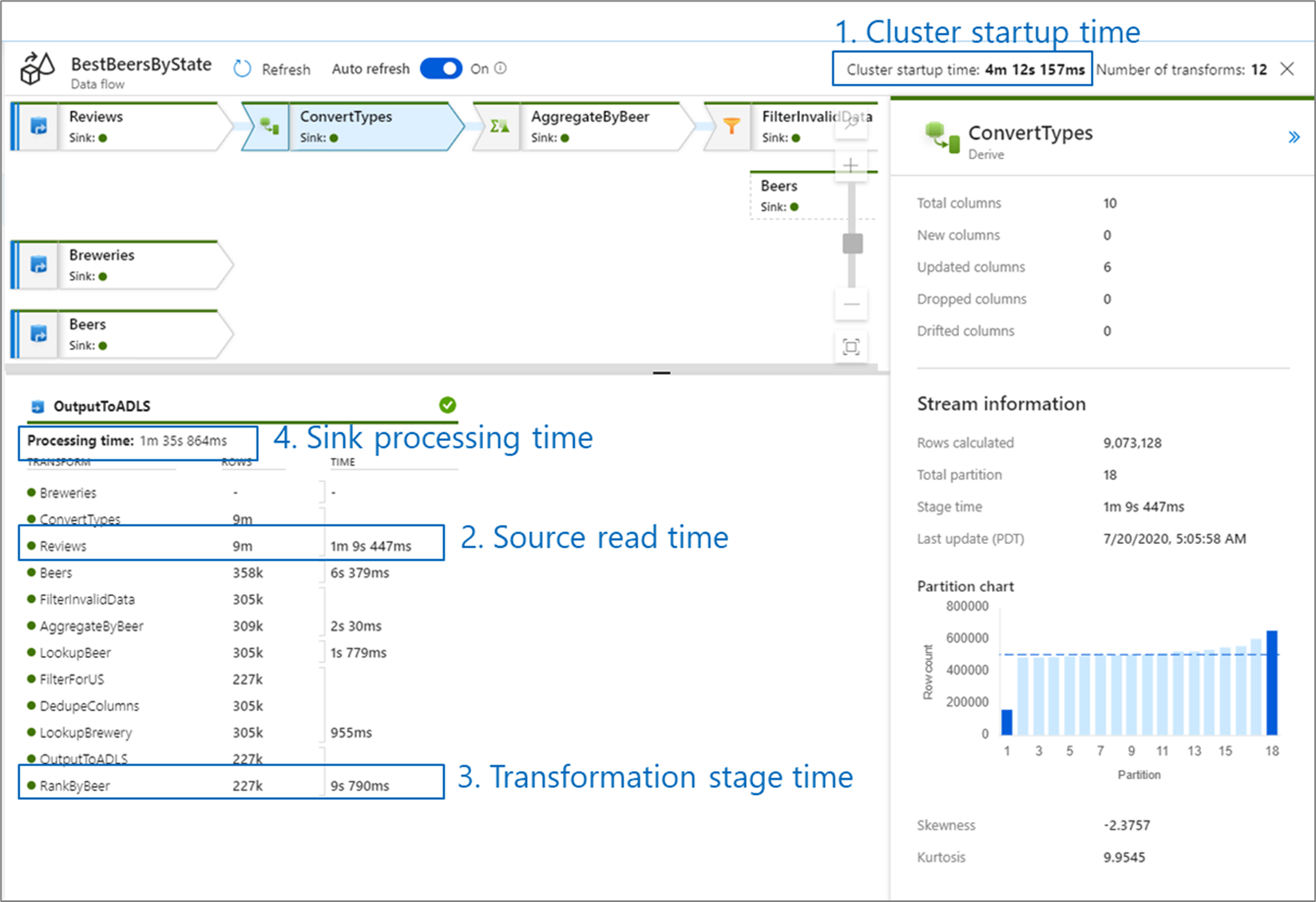
クラスターの起動時間は、Apache Spark クラスターをスピンアップするためにかかる時間です。 この値は、監視画面の右上隅にあります。 データ フローは、各ジョブが分離クラスターを使用する Just-In-Time モデルで実行されます。 通常、この起動時間は 3 ~ 5 分かかります。 継続するジョブの場合、Time to Live 値を有効にすることで、起動時間を短縮できます。 詳細については、「
データ フローには、可能な限り迅速な実行のためにビジネス ロジックを "ステージ" で並べ替えて実行する、Spark オプティマイザーが利用されます。 データ フローの書き込み先の各シンクについて、監視出力には、各変換ステージの期間と、シンクへのデータの書き込みにかかる時間が表示されます。 最大の時間は、データ フローのボトルネックになる可能性があります。 最も大きい変換ステージにソースが含まれている場合は、読み取り時間をさらに最適化を期待することができます。 変換に時間がかかる場合は、統合ランタイムのパーティションを再分割するか、サイズを大きくする必要があります。 シンクのプロセス時間が長い場合は、データベースをスケールアップするか、1 つのファイルに出力していないことを確認する必要があります。
データ フローのボトルネックを特定したら、以下の最適化戦略を使用してパフォーマンスを向上させます。
データ フローのロジックをテストする
UI からデータ フローを設計およびテストする場合、デバッグ モードを使用すると、ライブ Spark クラスターに対して対話形式でテストできます。これにより、クラスターのウォームアップを待たずにデータをプレビューし、データ フローを実行できます。 詳細については、デバッグ モードに関するページを参照してください。
[最適化] タブ
[最適化] タブには、Spark クラスターのパーティション分割を構成するための設定が含まれています。 データ フローのすべての変換に存在するこのタブでは、変換が完了した後にデータのパーティション再分割を行うかどうかを指定します。 パーティション分割を調整すると、全体的なデータ フローのパフォーマンスに好影響を与えることも、悪影響も与えることもある、各計算ノードへのデータの分散とデータの局所性の最適化を制御できます。
![パーティション オプション、パーティションの種類、パーティションの数が含まれる [最適化] タブが示されているスクリーンショット。](media/data-flow/optimize.png)
既定では、変換の現在の出力パーティション分割を維持するようサービスに指示する [Use current partitioning]\(現在のパーティション分割を使用する\) が選択されています。 データのパーティション再分割は時間がかかるため、ほとんどのシナリオでは、 [Use current partitioning]\(現在のパーティション分割を使用する\) をお勧めします。 データを再パーティション分割するシナリオとしては、集計と結合の後にデータが大幅に歪む場合や、SQL データベースでソース パーティション分割を使用する場合などがあります。
変換のパーティションを変更するには、[最適化] タブを選択し、[パーティションの設定] を選択します。 パーティション分割の一連のオプションが表示されます。 パーティション分割の最適な方法は、データ ボリューム、候補キー、null 値、およびカーディナリティに応じて異なります。
重要
すべての分散データを 1 つのパーティションに結合するのが単一パーティションです。 これは非常に低速な操作であると同時に、すべてのダウンストリームの変換と書き込みに大きな影響を及ぼします。 このオプションは、明示的なビジネス上の使用理由がない限り、推奨されません。
すべての変換で次のパーティション分割オプションを使用できます。
ラウンド ロビン
データを複数のパーティションに均等に分散するのがラウンド ロビンです。 堅固でスマートなパーティション分割戦略を実装するための適切な候補がないときは、ラウンド ロビンを使用します。 物理パーティションの数を設定できます。
ハッシュ
サービスでは、同様の値を持つ行が同じパーティション内に分類されるように、列のハッシュを生成して統一されたパーティションを生成します。 [ハッシュ] オプションを使用するときは、考えられるパーティションのスキューについてテストします。 物理パーティションの数を設定できます。
動的範囲
動的範囲では、指定した列または式に基づく Spark の動的範囲が使用されます。 物理パーティションの数を設定できます。
固定範囲
パーティション分割されたデータ列内の値に対する固定の範囲を提供する式を作成します。 パーティションのスキューを避けるため、このオプションを使用する際は、自分のデータについて十分に理解する必要があります。 式に入力する値は、パーティション関数の一部として使用されます。 物理パーティションの数を設定できます。
キー
データのカーディナリティを十分に理解している場合は、キー パーティション分割が適切な戦略になるでしょう。 キー パーティション分割では、列内の一意の値ごとにパーティションが作成されます。 パーティションの数は、データ内の一意の値に基づくため、設定することはできません。
ヒント
パーティション構成を手動で設定すると、データが再シャッフルされ、Spark オプティマイザーの利点が相殺される可能性があります。 必要な場合を除き、パーティション分割を手動で設定しないことをお勧めします。
ログ記録レベル
データ フロー アクティビティのすべてのパイプライン実行がすべての詳細なテレメトリ ログを完全にログ記録する必要がない場合は、必要に応じてログ レベルを "Basic" または "None" に設定できます。 データ フローを "Verbose" モード (既定値) で実行している場合、データ変換中に個別のパーティション レベルのそれぞれでアクティビティを完全にログ記録するように、サービスに要求していることになります。 これはコストのかかる操作であるため、トラブルシューティング中のみ詳細ログを有効にすることにより、データフローとパイプラインの全体的なパフォーマンスを向上させることができます。 「基本」 モードでは変換期間のみがログに記録され、「None」 は期間の概要のみを提供します。

関連するコンテンツ
パフォーマンスに関連するその他のData Flow記事を参照してください。