Azure Data Factory と Azure Synapse Analytics パイプラインのマッピング データ フローでの変換のパフォーマンスを最適化するには、次の戦略を使用します。
結合、存在、参照の最適化
放送
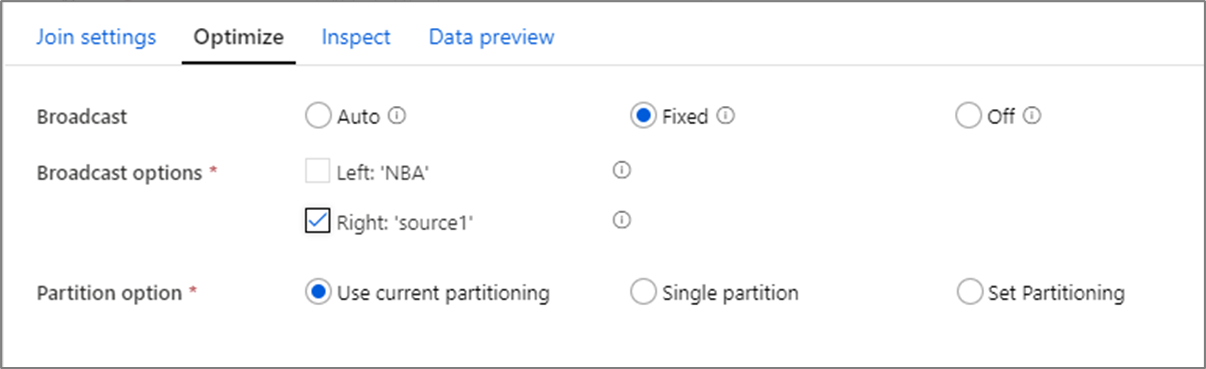
結合、参照、および存在する変換では、一方または両方のデータ ストリームがワーカー ノード メモリに収まるほど小さい場合は、 ブロードキャストを有効にすることでパフォーマンスを最適化できます。 ブロードキャストは、クラスター内のすべてのノードに小さなデータ フレームを送信する場合です。 これにより、Spark エンジンは、大きなストリーム内のデータを再シャッフせずに結合を実行できます。 既定では、Spark エンジンは、結合の一方の側をブロードキャストするかどうかを自動的に決定します。 受信データを理解していて、1 つのストリームが他のストリームよりも小さいことがわかっている場合は、[ 固定 ブロードキャスト] を選択できます。 固定ブロードキャストを使用すると、選択したストリームが Spark で強制的にブロードキャストされます。
ブロードキャストされたデータのサイズが Spark ノードに対して大きすぎる場合は、メモリ不足エラーが発生する可能性があります。 メモリ不足エラーを回避するには、 メモリ最適化クラスターを 使用します。 データ フローの実行中にブロードキャスト タイムアウトが発生した場合は、ブロードキャストの最適化をオフにすることができます。 ただし、その結果、データ フローのパフォーマンスが低下します。
大規模なデータベース クエリなど、クエリに時間がかかる可能性があるデータ ソースを操作する場合は、結合のブロードキャストをオフにすることをお勧めします。 クエリ時間が長いソースでは、クラスターがコンピューティング ノードへのブロードキャストを試みると、Spark のタイムアウトが発生する可能性があります。 ブロードキャストをオフにするもう 1 つの良い選択肢は、後で参照変換で使用するために値を集計するストリームがデータ フローにある場合です。 このパターンでは、Spark オプティマイザーが混乱し、タイムアウトが発生する可能性があります。
クロス結合
結合条件でリテラル値を使用する場合、または結合の両側で複数の一致がある場合、Spark はクロス結合として結合を実行します。 クロス結合は、完全なデカルト積であり、結合された値を除外します。 これは、他の結合の種類よりも遅くなります。 パフォーマンスへの影響を回避するために、結合条件の両側に列参照があることを確認します。
結合前の並べ替え
SSIS などのツールでのマージ結合とは異なり、結合変換は必須のマージ結合操作ではありません。 結合キーは、変換の前に並べ替えを必要としません。 マッピング データ フローで並べ替え変換を使用することはお勧めしません。
ウィンドウ変換のパフォーマンス
マッピング データ フローのウィンドウ変換では、変換設定のover()句の一部として選択した列の値によってデータがパーティション分割されます。 Windows 変換で公開される多くの一般的な集計関数と分析関数があります。 ただし、使用例がデータセット全体に対してランク付け rank() または行番号 rowNumber()ウィンドウを生成する場合は、代わりに Rank 変換 と サロゲート キー変換を使用することをお勧めします。 これらの変換は、これらの関数を使用して、データセットの完全な操作をもう一度実行する方が優れています。
偏ったデータの再パーティショニング
結合や集計などの特定の変換により、データ パーティションが再シャッフされ、データが歪む場合があります。 歪んだデータは、データがパーティション間で均等に分散されていないことを意味します。 データの歪みが大きいと、ダウンストリームの変換とシンクの書き込みが遅くなる可能性があります。 監視表示で変換をクリックすると、データ フロー実行の任意の時点でデータの歪みを確認できます。
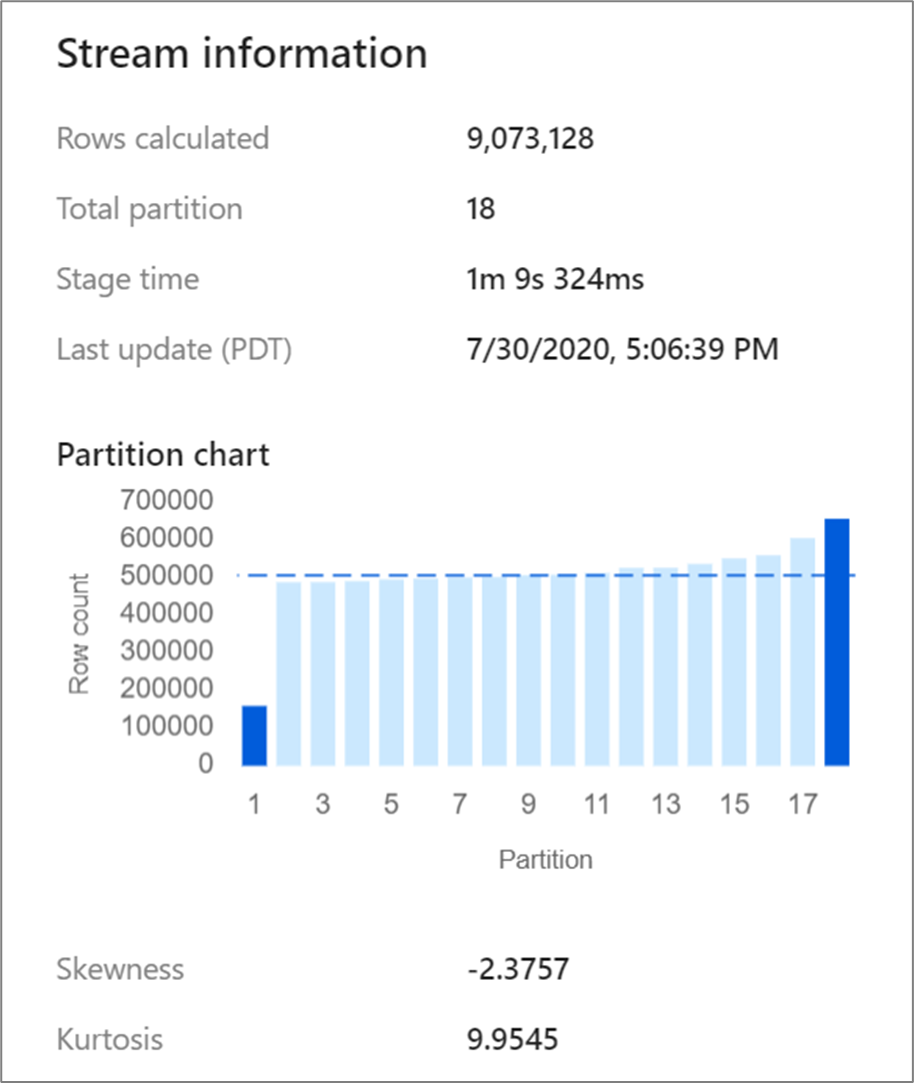
監視表示では、データが各パーティションに分散される方法と、歪度と尖度という 2 つのメトリックが表示されます。 歪度 は、データがどの程度非対称であるかの尺度であり、正、ゼロ、負、または未定義の値を持つことができます。 負の傾斜は、左の尾が右よりも長くなることを意味します。 尖度は、データが大幅に非対称であるか、または軽度に非対称であるかを示す尺度です。 高い尖度値は望ましくありません。 歪みの理想的な範囲は -3 と3の間にあり、尖度の範囲は10未満である。 これらの数値を解釈する簡単な方法は、パーティション グラフを見て、残りの部分よりも 1 つの棒が大きいかどうかを確認することです。
変換後にデータが均等にパーティション分割されていない場合は、[ 最適化] タブ を使用してパーティションを再分割できます。 データの再シャッフルには時間がかかり、データ フローのパフォーマンスが向上しない可能性があります。
ヒント
データを再パーティション化する場合、その後の変換でデータを再配置する必要がある場合は、結合キーとして使用される列にハッシュパーティションを使用します。
注
データ フロー内の変換 (シンク変換を除く) では、保存データのファイルとフォルダーのパーティション分割は変更されません。 各変換でパーティション分割すると、ADF がデータ フローの実行ごとに管理する一時サーバーレス Spark クラスターのデータ フレーム内のデータが再パーティション分割されます。
関連するコンテンツ
パフォーマンスに関連するその他のデータ フローに関する記事を参照してください。