Azure Data Factory を使用して Amazon S3 から Azure Storage にデータを移行する
適用対象: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory には、Amazon S3 から Azure Blob Storage または Azure Data Lake Storage Gen2 に大量のデータを移行することができる、パフォーマンスと信頼性が高くコスト効率に優れたメカニズムが用意されています。 この記事では、データ エンジニアと開発者向けに次の情報を提供します。
- パフォーマンス
- 回復性のコピー
- ネットワークのセキュリティ
- 概要ソリューション アーキテクチャ
- 実装のベスト プラクティス
パフォーマンス
ADF には、さまざまなレベルで並列処理を可能にするサーバーレス アーキテクチャが用意されています。そのため、開発者は、ネットワーク帯域幅、およびストレージの IOPS と帯域幅を利用して、データ移動のスループットが環境に合わせて最大限になるパイプラインを構築できます。
複数のお客様が、スループットを 2 GBps 以上に維持したまま、Amazon S3 から Azure Blob Storage に数百万個単位のファイルで構成されるペタバイト単位のデータを移行することに成功しています。
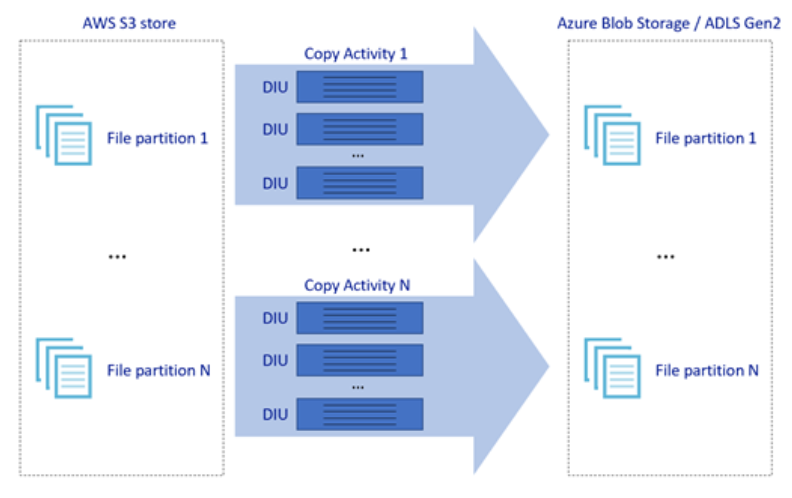
上の図は、さまざまなレベルの並列処理で優れたデータ移動速度を実現する方法を示しています。
- 1 回のコピー アクティビティで、スケーラブルなコンピューティング リソースを利用できます。Azure Integration Runtime を使用する場合は、サーバーレス方式で各コピー アクティビティに対して最大 256 DIU を指定できます。セルフホステッド統合ランタイムを使用する場合は、手動でマシンをスケールアップするか、複数のマシン (最大 4 ノード) にスケールアウトすることができます。また、1 回のコピー アクティビティによって、すべてのノードでファイル セットがパーティション分割されます。
- 1 回のコピー アクティビティで、複数のスレッドを使用したデータ ストアの読み取りと書き込みが行われます。
- ADF 制御フローでは、複数のコピー アクティビティを並列して開始できます。たとえば、For Each ループを使用します。
回復力
ADF には、1 回のコピー アクティビティの実行で、データ ストアまたは基になるネットワークの特定のレベルの一時的なエラーを処理できる組み込みの再試行メカニズムがあります。
S3 から BLOB へ、および S3 から ADLS Gen2 へのバイナリ コピーを実行すると、ADF ではチェックポイント処理が自動的に実行されます。 コピー アクティビティの実行が失敗した場合、またはタイムアウトした場合、後続の再試行では、最初から開始するのではなく、最後の障害個所からコピーが再開されます。
ネットワークのセキュリティ
ADF の既定では、HTTPS プロトコル経由の暗号化された接続を使用して、Amazon S3 から Azure Blob Storage または Azure Data Lake Storage Gen2 へデータを転送します。 HTTPS によって転送中のデータが暗号化され、盗聴や中間者攻撃が防止されます。
また、パブリック インターネット経由でデータを転送しない場合は、AWS Direct Connect と Azure Express Route 間をプライベート ピアリング リンク経由でデータを転送することで、より高いセキュリティを実現できます。 これを実現する方法については、次のセクションのソリューション アーキテクチャを参照してください。
ソリューションのアーキテクチャ
パブリック インターネット経由でデータを移行する:
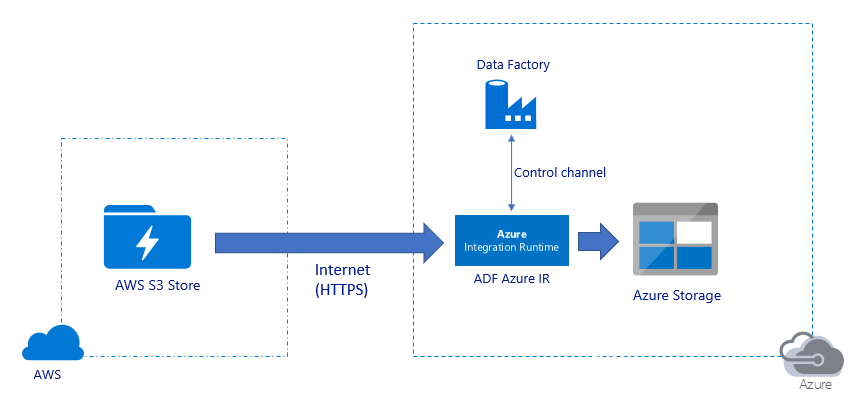
- このアーキテクチャでは、データはパブリック インターネット経由で HTTPS を使用して安全に転送されます。
- ソースの Amazon S3 と、宛先の Azure Blob Storage または Azure Data Lake Storage Gen2 の両方が、すべてのネットワーク IP アドレスからのトラフィックを許可するように構成されています。 特定の IP 範囲へのネットワーク アクセスを制限する方法については、このページで後述する 2 つ目のアーキテクチャを参照してください。
- サーバーレス方式で馬力を簡単にスケールアップしてネットワークとストレージの帯域幅を最大限に活用できるので、お使いの環境に最適なスループットを実現できます。
- 初回のスナップショット移行と差分のデータ移行は、このアーキテクチャを使用して実現できます。
プライベート リンク経由でデータを移行する:
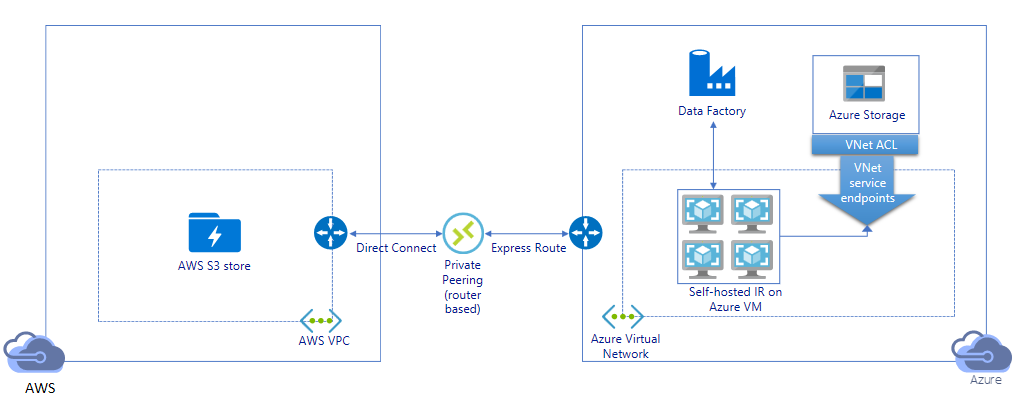
- このアーキテクチャでは、データの移行は AWS Direct Connect と Azure Express Route 間のプライベート ピアリング リンクを介して行われるので、データがパブリック インターネット経由で転送されることはありません。 この場合、AWS VPC と Azure Virtual ネットワークを使用する必要があります。
- このアーキテクチャを実現するには、Azure 仮想ネットワーク内の Windows VM に ADF セルフホステッド統合ランタイムをインストールする必要があります。 セルフホステッド IR VM を手動でスケールアップするか、複数の VM (最大 4 ノード) にスケールアウトすることで、ネットワークとストレージの IOPS/帯域幅を完全に活用できます。
- 初回のスナップショット移行と差分の移行は、このアーキテクチャを使用して実現できます。
実装のベスト プラクティス
認証と資格情報の管理
- Amazon S3 アカウントに対して認証するには、IAM アカウントのアクセス キーを使用する必要があります。
- Azure Blob Storage に接続するには、複数の認証の種類がサポートされています。 Azure リソース用マネージド ID を使用することを強くお勧めします。Microsoft Entra ID で自動的に管理される ADF ID を基にして構築されており、リンク サービス定義で資格情報を指定せずにパイプラインを構成できます。 また、サービス プリンシパル、共有アクセス署名、またはストレージ アカウント キーを使用して Azure Blob Storage に対する認証を行うこともできます。
- Azure Data Lake Storage Gen2 に接続するには、複数の認証の種類がサポートされています。 サービス プリンシパルまたはストレージ アカウント キーを使用することもできますが、Azure リソースのマネージド ID を使用することを強くお勧めします。
- Azure リソースに対してマネージド ID を使用していない場合は、Azure Key Vault に資格情報を保存して、ADF のリンクされたサービスを変更せずに、キーを一元的に管理およびローテーションすることを強くお勧めします。 これは、CI/CD のベスト プラクティスの1 つでもあります。
初回のスナップショット データ移行
データのパーティションは、100 TB を超えるデータを移行する場合に特に推奨されます。 データをパーティション分割するには、"プレフィックス" 設定を使用し、名前を指定して Amazon S3 内のフォルダーとファイルをフィルター処理し、各 ADF コピー ジョブで一度に 1 つのパーティションをコピーします。 複数の ADF コピー ジョブを同時に実行して、スループットを向上させることができます。
ネットワークまたはデータ ストアの一時的な問題によってコピー ジョブが失敗した場合は、失敗したコピー ジョブを再実行して、AWS S3 から特定のパーティションを再度読み込むことができます。 他のパーティションを読み込む他のすべてのコピー ジョブには影響しません。
差分のデータ移行
AWS S3 から新規または変更されたファイルを識別する最も効果的な方法は、時間でパーティション分割された名前付け規則を使用することです。AWS S3 のデータが、ファイル名またはフォルダー名のタイム スライス情報でパーティション分割されている場合 (たとえば、/yyyy/mm/dd/file.csv)、パイプラインによって増分的にコピーされるファイル/フォルダーが簡単に識別されます。
また、AWS S3 のデータが時間でパーティション分割されていない場合、ADF では LastModifiedDate によって新しいファイルまたは変更されたファイルが識別されます。 これは、ADF で AWS S3 からすべてのファイルがスキャンされ、最後に変更されたタイム スタンプが特定の値よりも大きい新しいファイルと更新されたファイルのみがコピーされるというしくみです。 S3 に多数のファイルがある場合、フィルター条件に一致するファイルの数に関係なく、初回のファイル スキャンに時間がかかる可能性があります。 この場合は、初回のスナップショットの移行に同じ "プレフィックス" 設定を使用してデータを最初にパーティション分割することをお勧めします。こうすることで、ファイルのスキャンが並列処理されるようになります。
Azure VM でセルフホステッド統合ランタイムが必要なシナリオの場合
プライベート リンクを使用してデータを移行する場合か、Amazon S3 ファイアウォールで特定の IP 範囲を許可するかにかかわらず、Azure Windows VM にセルフホステッド統合ランタイムをインストールする必要があります。
- 各 Azure VM に対して最初に推奨される構成は、32 vCPU と 128 GB のメモリが搭載された Standard_D32s_v3 です。 データ移行中に IR VM の CPU とメモリの使用状況を監視して、パフォーマンスを向上させるために VM をさらにスケールアップするか、コストを節約するために VM をスケールダウンするかを確認できます。
- また、1 つのセルフホステッド IR に最大 4 つの VM ノードを関連付けてスケールアウトすることもできます。 セルフホステッド IR に対して実行される 1 回のコピー ジョブで、ファイル セットが自動的にパーティション分割され、すべての VM ノードを使用してファイルが並列してコピーされます。 高可用性を実現するには、データ移行中の単一障害点を回避するために、2 台の VM ノードから始めることをお勧めします。
レート制限
ベスト プラクティスとして、代表的なサンプル データセットを使用してパフォーマンス POC を実施し、適切なパーティションのサイズを決定できるようにします。
既定の DIU 設定を使用して、1 つのパーティションと 1 回のコピー アクティビティから始めます。 ネットワークの帯域幅制限またはデータ ストアの IOPS/帯域幅制限に達するまで、または1 回のコピー アクティビティで許可される最大 256 DIU に達するまで、DIU 設定を徐々に増やします。
次に、環境の制限に達するまで、同時コピー アクティビティの数を徐々に増やします。
ADF のコピー アクティビティによって報告された調整エラーが発生した場合は、ADF の同時接続数または DIU の設定を減らすか、ネットワークとデータ ストアの帯域幅/IOPS の制限値を大きくすることを検討してください。
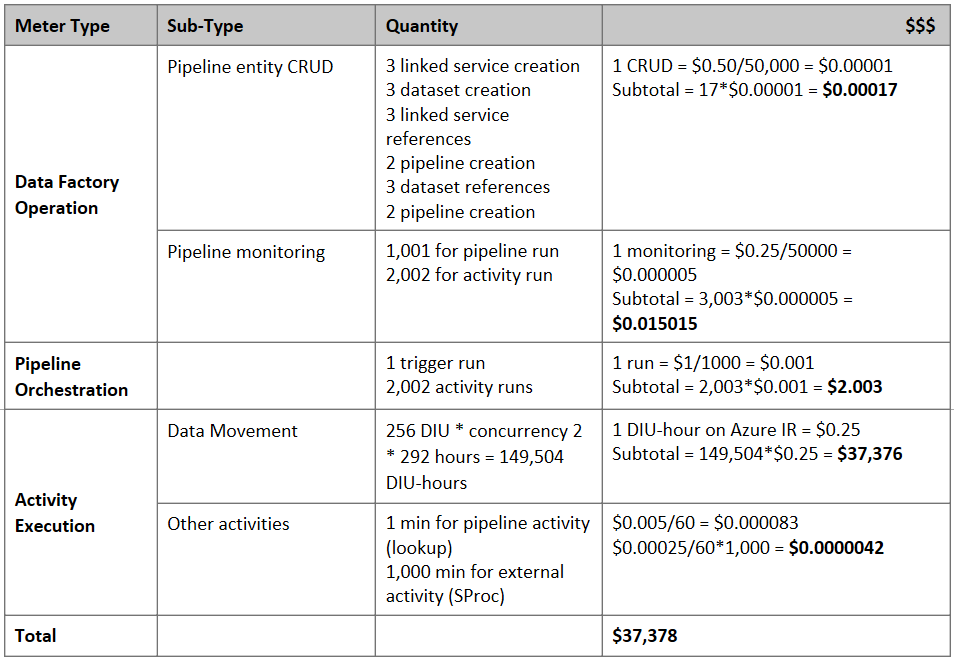
料金の見積り
注意
これは仮定の料金例です。 実際の料金は、環境の実際のスループットによって変わります。
S3 から Azure Blob Storage にデータを移行するために、次のパイプラインが構築されているとします。
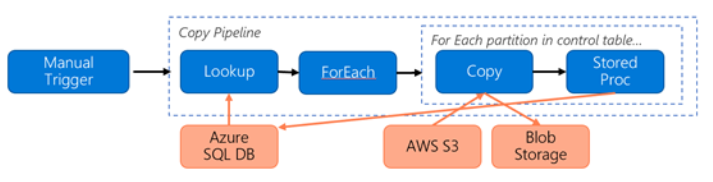
ここでは、次のことを想定しています。
- 合計データ量は 2 PB
- 最初のソリューション アーキテクチャを使用して HTTPS 経由でデータを移行する
- 2 PB は 1 KB パーティションに分割され、各コピーで 1 つのパーティションが移行される
- 各コピーは、DIU = 256 で構成され、1 GBps スループットを実現する
- ForEach の同時実行数は 2 に設定され、合計スループットは 2 GBps
- 合計では、移行が完了するまでに 292 時間かかる
上記の前提条件に基づく推定料金は次のとおりです。
その他の参照情報
- Amazon Simple Storage Service コネクタ
- Azure Blob Storage コネクタ
- Azure Data Lake Storage Gen2 コネクタ
- コピー アクティビティのパフォーマンスとチューニングに関するガイド
- セルフホステッド統合ランタイムの作成と構成
- セルフホステッド統合ランタイム HA とスケーラビリティ
- データ移動のセキュリティに関する考慮事項
- Azure Key Vault への資格情報の格納
- 時間でパーティション分割されたファイル名に基づいてファイルを増分コピーする
- LastModifiedDate に基づいて新しいファイルと変更されたファイルをコピーする
- ADF 料金ページ
Template
数億ものファイルで構成されるペタバイト規模のデータの Amazon S3 から Azure Data Lake Storage Gen2 への移行を開始するには、こちらのテンプレートをご覧ください。
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示