適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、コピーアクティビティを使用して、Amazon Simple Storage Service (Amazon S3) からデータをコピーし、Data Flow を使用して Amazon S3 のデータを変換する方法について説明します。 詳細については、Azure Data Factory と Synapse Analytics の概要記事を参照してください。
ヒント
Amazon S3 から Azure Storage へのデータ移行のシナリオの詳細については、「Amazon S3 から Azure Storage にデータを移行する」を参照してください。
サポートされる機能
この Amazon S3 コネクタは、次の機能でサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/-) | ① ② |
| マッピング データ フロー (ソース/シンク) | ① |
| Lookup アクティビティ | ① ② |
| GetMetadata アクティビティ | ① ② |
| アクティビティを削除する | ① ② |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
具体的には、この Amazon S3 コネクタでは、ファイルをそのままコピーするか、サポートされているファイル形式と圧縮コーデックを使用してファイルを解析することをサポートしています。 コピー時にファイル メタデータを保持することも選択できます。 S3 への要求を認証するために、コネクタでは AWS Signature Version 4 が使用されます。
ヒント
S3 と互換性のあるストレージ プロバイダーからデータをコピーする場合は、Amazon S3 と互換性のあるストレージに関する記事をご覧ください。
必要なアクセス許可
Amazon S3 からデータをコピーするには、Amazon S3 オブジェクト操作に対する次のアクセス許可が付与されている必要があります: s3:GetObject および s3:GetObjectVersion。
Data Factory UI を使用して作成する場合は、リンクされたサービスへの接続のテストやルートからの参照などの操作に対して、追加の s3:ListAllMyBuckets および s3:ListBucket/s3:GetBucketLocation アクセス許可が必要です。 これらのアクセス許可を付与しない場合は、UI から [ファイル パスへの接続をテスト] または [指定されたパスから参照] オプションを選択できます。
Amazon S3 のアクセス許可の完全な一覧については、ポリシーでのアクセス許可の指定に関する AWS サイトのページを参照してください。
作業の開始
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Amazon Simple Storage Service (S3) のリンク サービスを作成する
次の手順を使用して、Azure portal UI で Amazon S3 のリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンクされたサービス] を選択して、[新規] をクリックします。
Amazon を検索し、Amazon S3 コネクタを選択します。
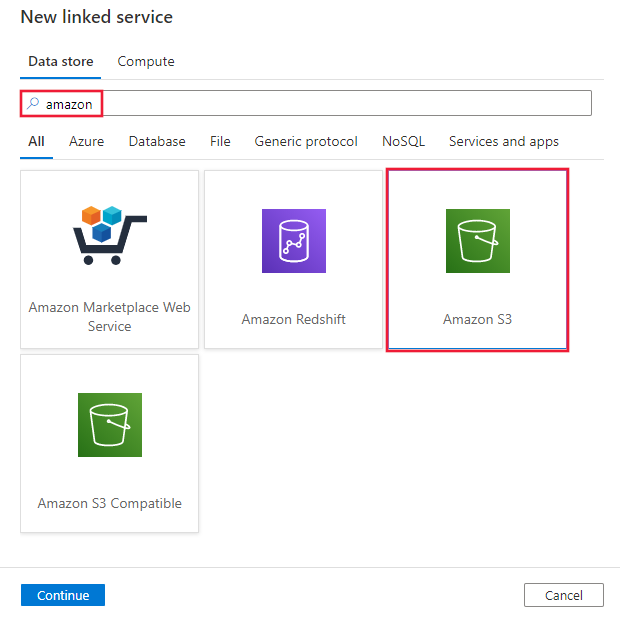
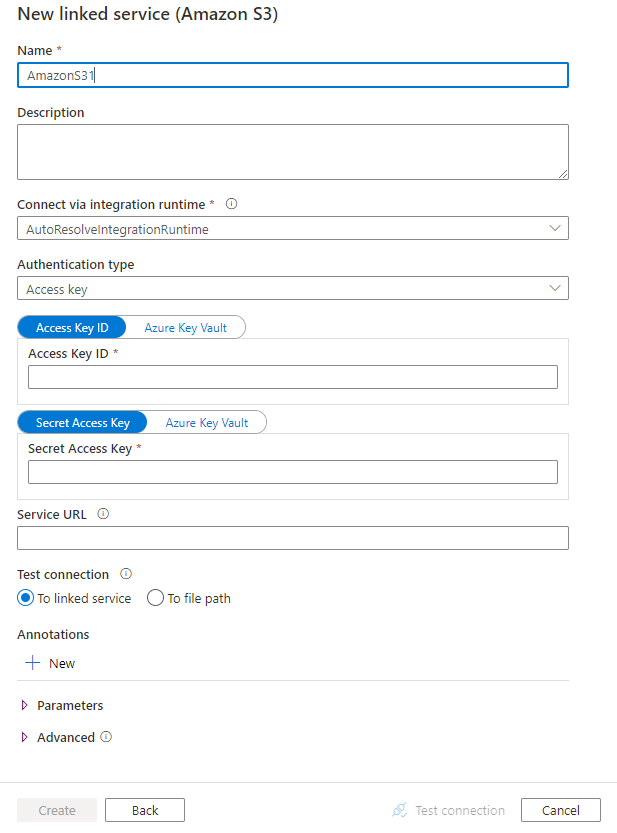
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
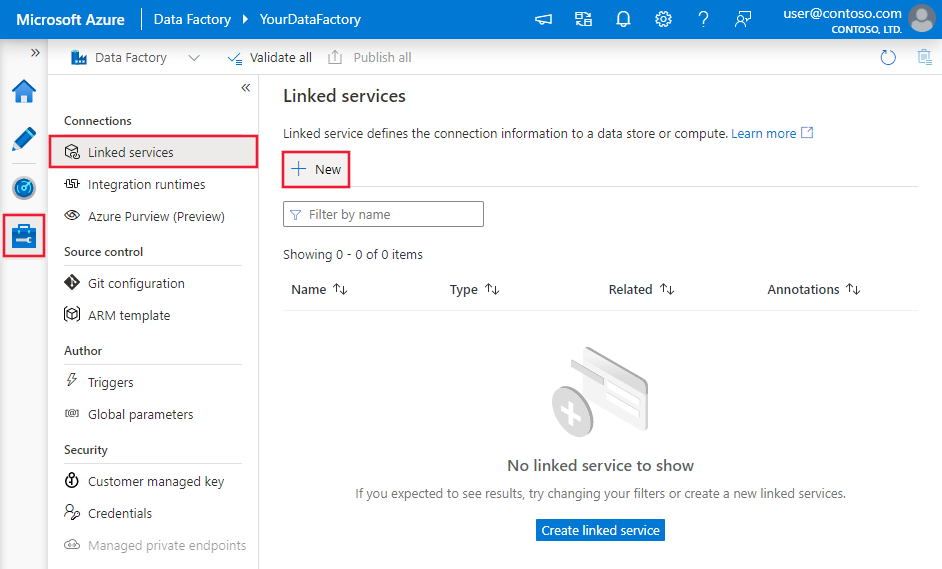
コネクタの構成の詳細
以下のセクションで、Amazon S3 に固有の Data Factory エンティティを定義するために使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Amazon S3 のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは AmazonS3 に設定する必要があります。 | はい |
| authenticationType | Amazon S3 への接続に使用する認証の種類を指定します。 AWS Identity and Access Management (IAM) アカウントのアクセス キー、または一時的なセキュリティ認証情報を使用することを選択できます。 使用できる値は、 AccessKey (既定値) と TemporarySecurityCredentials です。 |
いいえ |
| accessKeyId | シークレット アクセス キーの ID。 | はい |
| secretAccessKey | シークレット アクセス キー自体。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に保存されているシークレットを参照します。 | はい |
| sessionToken |
一時的なセキュリティ認証情報の認証を使用する場合に適用されます。 AWS から一時的なセキュリティ認証情報を要求する方法について学習します。 AWS の一時的な認証情報は、設定に基づいて 15 分から 36 時間で有効期限が切れることにご注意ください。 アクティビティの実行時、特に運用ワークロードの場合に、認証情報が有効であることを確認してください。たとえば、定期的に更新して Azure Key Vault に格納できます。 このフィールドを SecureString とマークして安全に保存するか、Azure Key Vault に保存されているシークレットを参照します。 |
いいえ |
| serviceUrl | カスタム S3 エンドポイント https://<service url> を指定します。別のサービス エンドポイントを試す場合、または https と http を切り替える場合にのみ変更します。 |
いいえ |
| connectVia | データ ストアに接続するために使用される統合ランタイム。 データ ストアがプライベート ネットワーク内にある場合、Azure Integration Runtime またはセルフホステッド統合ランタイムを使用できます。 このプロパティが指定されていない場合は、サービスでは、既定の Azure Integration Runtime が使用されます。 | いいえ |
例: アクセス キー認証の使用
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: 一時的なセキュリティ認証情報の認証の使用
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"authenticationType": "TemporarySecurityCredentials",
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"sessionToken": {
"type": "SecureString",
"value": "<session token>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
Amazon S3 では、形式ベースのデータセットの location 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの location の type プロパティは、AmazonS3Location に設定する必要があります。 |
はい |
| bucketName | S3 バケットの名前。 | はい |
| folderPath | 特定のバケットの下のフォルダーへのパス。 ワイルドカードを使用してフォルダーをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定でこれを指定します。 | いいえ |
| fileName | 特定のバケットおよびフォルダー パスの下のファイル名。 ワイルドカードを使用してファイルをフィルター処理する場合は、この設定をスキップし、アクティビティのソース設定でこれを指定します。 | いいえ |
| version | S3 のバージョン管理が有効になっている場合の S3 オブジェクトのバージョン。 指定しない場合は、最新バージョンがフェッチされます。 | いいえ |
例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3Location",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Amazon S3 ソースでサポートされているプロパティの一覧を示します。
ソースの種類としての Amazon S3
Azure Data Factory では次のファイル形式がサポートされます。 形式ベースの設定については、各記事を参照してください。
Amazon S3 では、形式ベースのコピー ソースの storeSettings 設定において、次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type |
storeSettings の type プロパティは AmazonS3ReadSettings に設定する必要があります。 |
はい |
| コピーするファイルを特定する: | ||
| オプション 1: 静的パス |
データセットに指定されている所定のバケットまたはフォルダー/ファイル パスからコピーします。 バケットまたはフォルダーからすべてのファイルをコピーする場合は、さらに * として wildcardFileName を指定します。 |
|
| オプション 2: S3 プレフィックス - prefix |
ソース S3 ファイルをフィルター処理するために、データセットで構成されている、指定されたバケットにある S3 キー名のプレフィックス。 名前が bucket_in_dataset/this_prefix で始まる S3 キーが選択されます。 ワイルドカード フィルターより優れたパフォーマンスを提供する S3 のサービス側フィルターを利用します。プレフィックスを使用して階層を保持した状態でファイルベースのシンクにコピーする場合は、プレフィックスの最後の "/" の後のサブパスが保持されます。 たとえば、ソース bucket/folder/subfolder/file.txt があり、プレフィックスを folder/sub で構成した場合、保持されるファイル パスは subfolder/file.txt です。 |
いいえ |
| オプション 3: ワイルドカード - wildcardFolderPath |
ソース フォルダーをフィルター処理するためにデータセットで構成されている、特定のバケットの下のワイルドカード文字を含むフォルダーのパス。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。 フォルダー名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
いいえ |
| オプション 3: ワイルドカード - wildcardFileName |
ソース ファイルをフィルター処理するための、特定のバケットおよびフォルダー パス (またはワイルドカード フォルダー パス) の下のワイルドカード文字を含むファイル名。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。 ファイル名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
はい |
| オプション 4: ファイルの一覧 - fileListPath |
指定されたファイル セットをコピーすることを示します。 コピーするファイルの一覧を含むテキスト ファイルをポイントします。データセットで構成されているパスへの相対パスであるファイルを 1 行につき 1 つずつ指定します。 このオプションを使用している場合は、データ セットにファイル名を指定しないでください。 その他の例については、ファイル リストの例を参照してください。 |
いいえ |
| 追加の設定: | ||
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。
recursive が true に設定され、シンクがファイル ベースのストアである場合、空のフォルダーおよびサブフォルダーはシンクでコピーも作成もされないことに注意してください。 使用可能な値: true (既定値) および false。 fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| deleteFilesAfterCompletion | 宛先ストアに正常に移動した後、バイナリ ファイルをソース ストアから削除するかどうかを示します。 ファイルの削除はファイルごとに行われるので、コピー操作が失敗した場合、一部のファイルが既に宛先にコピーされソースからは削除されているが、他のファイルはまだソース ストアに残っていることがわかります。 このプロパティは、バイナリ ファイルのコピー シナリオでのみ有効です。 既定値: false。 |
いいえ |
| modifiedDatetimeStart | ファイルは、属性 (最終変更日時) に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 プロパティは、ファイル属性フィルターをデータセットに適用しないことを意味する NULL にすることができます。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。
modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値未満であるファイルが選択されます。fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| modifiedDatetimeEnd | 上記と同じです。 | いいえ |
| enablePartitionDiscovery | パーティション分割されているファイルの場合は、ファイル パスのパーティションを解析し、それを追加のソース列として追加するかどうかを指定します。 指定できる値は false (既定値) と true です。 |
いいえ |
| partitionRootPath | パーティション検出が有効になっている場合は、パーティション分割されたフォルダーをデータ列として読み取るための絶対ルート パスを指定します。 これが指定されていない場合は、既定で次のようになります。 - ソース上のデータセットまたはファイルの一覧内のファイル パスを使用する場合、パーティションのルート パスはそのデータセットで構成されているパスです。 - ワイルドカード フォルダー フィルターを使用する場合、パーティションのルート パスは最初のワイルドカードの前のサブパスです。 - プレフィックスを使用する場合、パーティションのルート パスは最後の "/" の前のサブパスです。 たとえば、データセット内のパスを "root/folder/year=2020/month=08/day=27" として構成するとします。 - パーティションのルート パスを "root/folder/year=2020" として指定した場合は、コピー アクティビティによって、ファイル内の列とは別に、それぞれ "08" と "27" の値を持つ month と day という 2 つの追加の列が生成されます。- パーティションのルート パスが指定されない場合、追加の列は生成されません。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3ReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
フォルダーとファイル フィルターの例
このセクションでは、ワイルドカード フィルターを使用した結果のフォルダーのパスとファイル名の動作について説明します。
| bucket | key | recursive | ソースのフォルダー構造とフィルターの結果 (太字のファイルが取得されます) |
|---|---|---|---|
| bucket | Folder*/* |
false | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/* |
true | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/*.csv |
false | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/*.csv |
true | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
ファイル リストの例
このセクションでは、コピー アクティビティのソースでファイル リスト パスを使用した結果の動作について説明します。
次のソース フォルダー構造があり、太字のファイルをコピーするとします。
| サンプルのソース構造 | FileListToCopy.txt のコンテンツ | 構成 |
|---|---|---|
| bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv メタデータ FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
データセット内: - バケット: bucket- フォルダー パス: FolderAコピー アクティビティ ソース内: - ファイル リストのパス: bucket/Metadata/FileListToCopy.txt ファイル リストのパスは、コピーするファイルの一覧を含む同じデータ ストア内のテキスト ファイルをポイントします。データセットで構成されているパスへの相対パスで 1 行につき 1 つのファイルを指定します。 |
コピー中にメタデータを保存する
Amazon S3 から Azure Data Lake Storage Gen2 または Azure Blob ストレージにファイルをコピーする場合、ファイルのメタデータをデータと共に保存することもできます。 詳細については、メタデータの保存に関する記事を参照してください。
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換するときに、次の形式で Amazon S3 からファイルを読み取ることができます。
形式固有の設定は、各形式のドキュメントに記載されています。 詳細については、「マッピング データ フローのソース変換」を参照してください。
ソース変換
ソース変換では、Amazon S3 のコンテナー、フォルダー、または個々のファイルから読み取ることができます。 ファイルの読み取り方法を管理するには、 [ソース オプション] タブを使用します。
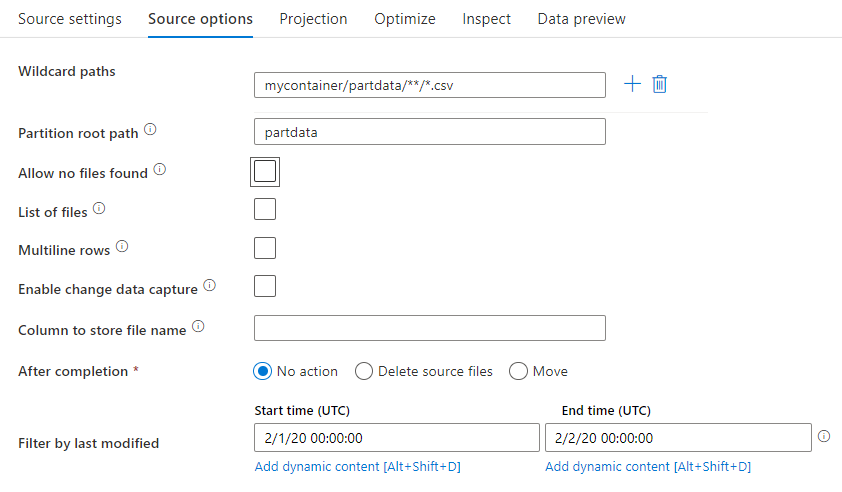
ワイルドカード パス: ワイルドカード パターンを使用して、1 回のソース変換で、一致するフォルダーとファイルをそれぞれループ処理するようサービスに指示します。 これは、単一のフロー内の複数のファイルを処理するのに効果的な方法です。 既存のワイルドカード パターンにマウス ポインターを合わせると表示されるプラス記号を使って、複数のワイルドカード一致パターンを追加します。
ソース コンテナーから、パターンに一致する一連のファイルを選択します。 データセット内で指定できるのはコンテナーのみです。 そのため、ワイルドカード パスには、ルート フォルダーからのフォルダー パスも含める必要があります。
ワイルドカードの例:
*- 任意の文字セットを表します。**- ディレクトリの再帰的な入れ子を表します。?- 1 文字を置き換えます。[]- 角カッコ内の 1 文字以上に一致します。/data/sales/**/*.csv- /data/sales の下のすべての .csv ファイルを取得します。/data/sales/20??/**/- 20 世紀のすべてのファイルを取得します。/data/sales/*/*/*.csv- /data/sales の 2 レベル下の .csv ファイルを取得します。/data/sales/2004/*/12/[XY]1?.csv- 前に 2 桁の数字が付いた X または Y で始まる、2004 年 12 月のすべての .csv ファイルを取得します。
Partition root path: ファイル ソース内のフォルダーを key=value 形式 (例えば year=2019) で分割している場合、その分割フォルダー ツリーの最上位をデータ フローのデータ ストリームの列名に割り当てることができます。
最初に、ワイルドカードを設定して、パーティション分割されたフォルダーと読み取るリーフ ファイルのすべてのパスを含めます。
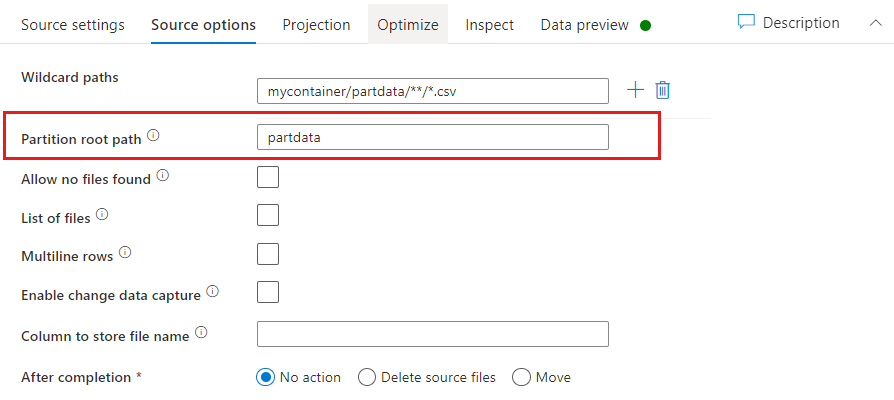
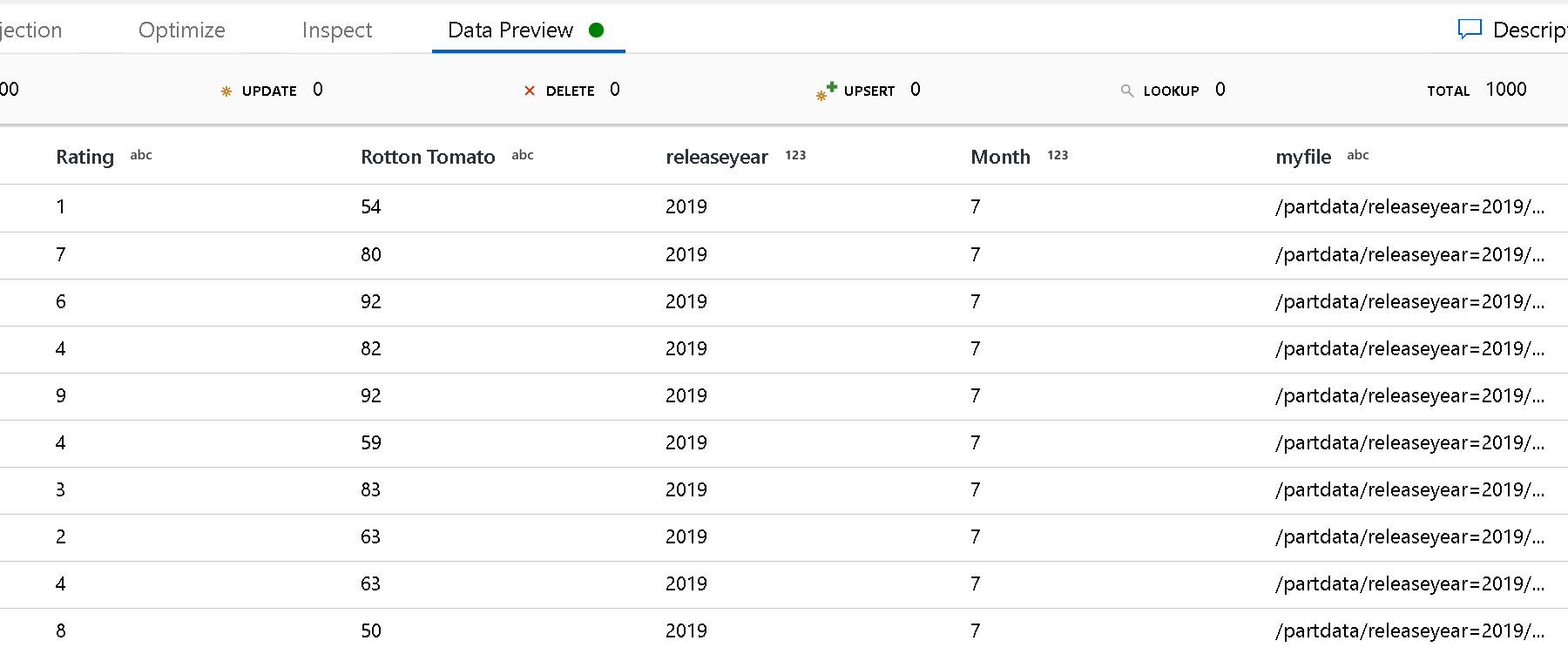
[Partition root path](パーティションのルート パス) 設定を使用して、フォルダー構造の最上位レベルを定義します。 データ プレビューでデータの内容を表示すると、各フォルダー レベルで見つかった解決済みのパーティションがサービスによって追加されることがわかります。
[List of files]: これはファイル セットです。 処理する相対パス ファイルの一覧を含むテキスト ファイルを作成します。 このテキスト ファイルをポイントします。
[Column to store file name](ファイル名を格納する列): ソース ファイルの名前をデータの列に格納します。 ファイル名文字列を格納するための新しい列名をここに入力します。
[After completion](完了後): データ フローの実行後にソース ファイルに何もしないか、ソース ファイルを削除するか、またはソース ファイルを移動することを選択します。 移動のパスは相対パスです。
後処理でソース ファイルを別の場所に移動するには、まず、ファイル操作の "移動" を選択します。 次に、"移動元" ディレクトリを設定します。 パスにワイルドカードを使用していない場合、"移動元" 設定はソース フォルダーと同じフォルダーになります。
ワイルドカードを含むソース パスがある場合、構文は次のようになります。
/data/sales/20??/**/*.csv
"移動元" は次のように指定できます。
/data/sales
"移動先" は次のように指定できます。
/backup/priorSales
この場合、ソースとして指定された /data/sales の下のすべてのファイルは /backup/priorSales に移動されます。
注意
ファイル操作は、パイプライン内のデータ フローの実行アクティビティを使用するパイプライン実行 (パイプラインのデバッグまたは実行) からデータ フローを開始する場合にのみ実行されます。 データ フロー デバッグ モードでは、ファイル操作は実行されません。
[Filter by last modified](最終更新日時でフィルター処理): 最終更新日時の範囲を指定することで、処理するファイルをフィルター処理できます。 日時はすべて UTC 形式です。
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
GetMetadata アクティビティのプロパティ
プロパティの詳細については、GetMetadata アクティビティに関するページを参照してください。
Delete アクティビティのプロパティ
プロパティの詳細については、Delete アクティビティに関するページを参照してください。
レガシ モデル
注意
次のモデルは、下位互換性のために引き続きそのままサポートされます。 前述の新しいモデルを使用することをお勧めします。 作成 UI は、新しいモデルの生成に切り替えられました。
レガシ データセット モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、AmazonS3Object を設定する必要があります。 | はい |
| bucketName | S3 バケットの名前。 ワイルドカード フィルターはサポートされていません。 | はい (Copy または Lookup アクティビティの場合)、いいえ (GetMetadata アクティビティの場合) |
| key | 指定されたバケットの下にある S3 オブジェクト キーの名前またはワイルドカード フィルターです。
prefix プロパティが指定されていないときにのみ適用されます。 ワイルドカード フィルターは、フォルダー部分とファイル名部分の両方に対してサポートされます。 使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。- 例 1: "key": "rootfolder/subfolder/*.csv"- 例 2: "key": "rootfolder/subfolder/???20180427.txt"「フォルダーとファイル フィルターの例」の他の例をご覧ください。 実際のフォルダーまたはファイル名にワイルドカードまたは ^ が含まれている場合は、このエスケープ文字を使用してエスケープします。 |
いいえ |
| prefix | S3 オブジェクト キーのプレフィックス。 キーがこのプレフィックスで始まるオブジェクトが選択されます。 key プロパティが指定されていないときにのみ適用されます。 | いいえ |
| version | S3 のバージョン管理が有効になっている場合の S3 オブジェクトのバージョン。 バージョンを指定しない場合は、最新バージョンがフェッチされます。 | いいえ |
| modifiedDatetimeStart | ファイルは、属性 (最終変更日時) に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 この設定を有効にすると、大量のファイルのフィルター処理を実行する場合にデータ移動の全体的なパフォーマンスに影響することに注意してください。 プロパティは、ファイル属性フィルターをデータセットに適用しないことを意味する NULL にすることができます。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。
modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値未満であるファイルが選択されます。 |
いいえ |
| modifiedDatetimeEnd | ファイルは、属性 (最終変更日時) に基づいてフィルター処理されます。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選択されます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 この設定を有効にすると、大量のファイルのフィルター処理を実行する場合にデータ移動の全体的なパフォーマンスに影響することに注意してください。 プロパティは、ファイル属性フィルターをデータセットに適用しないことを意味する NULL にすることができます。 modifiedDatetimeStart に datetime 値が設定されており、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値以上であるファイルが選択されます。
modifiedDatetimeEnd に datetime 値が設定されており、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値未満であるファイルが選択されます。 |
いいえ |
| format | ファイルベースのストア間でファイルをそのままコピー (バイナリ コピー) する場合は、入力と出力の両方のデータセット定義で format セクションをスキップします。 特定の形式のファイルを解析または生成する場合、サポートされるファイル形式の種類は、TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat です。 format の type プロパティをいずれかの値に設定します。 詳細については、Text 形式、Json 形式、Avro 形式、Orc 形式、Parquet 形式 の各セクションを参照してください。 |
いいえ (バイナリ コピー シナリオのみ) |
| compression | データの圧縮の種類とレベルを指定します。 詳細については、サポートされるファイル形式と圧縮コーデックに関する記事を参照してください。 サポートされる種類は、GZip、Deflate、BZip2、および ZipDeflate です。 サポートされるレベルは、Optimal と Fastest です。 |
いいえ |
ヒント
フォルダーの下のすべてのファイルをコピーするには、バケットに bucketName、フォルダー部分に prefix を指定します。
特定の名前の単一のファイルをコピーするには、バケットに bucketName、フォルダー部分とファイル名に key を指定します。
フォルダーの下のファイルのサブセットをコピーするには、バケットに bucketName、フォルダー部分とファイル名に key を指定します。
例: prefix の使用
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3Object",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"prefix": "testFolder/test",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
例: key と version の使用 (省略可能)
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"key": "testFolder/testfile.csv.gz",
"version": "XXXXXXXXXczm0CJajYkHf0_k6LhBmkcL",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
コピー アクティビティのレガシ ソース モデル
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティを FileSystemSource に設定する必要があります。 | はい |
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。
recursive が true に設定されていて、シンクがファイル ベースのストアである場合、空のフォルダーまたはサブフォルダーはシンクでコピーも作成もされないことに注意してください。 使用可能な値: true (既定値) および false。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon S3 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
関連するコンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するページを参照してください。