Azure Databricks ワークフローでは、Databricks Data Intelligence プラットフォームでデータ処理、機械学習、分析のパイプラインが調整されます。 ワークフローには、Azure Databricks ワークスペースで非対話型コードを実行する Azure Databricks ジョブと、信頼性が高く、保守が容易な ETL パイプラインを構築するための Delta Live Tables などの Databricks プラットフォームに統合されたフル マネージド オーケストレーション サービスがあります。
Databricks プラットフォームを使用してワークフローを調整するメリットの詳細については、「Databricks ワークフロー」を参照してください。
Azure Databricks ワークフローの例
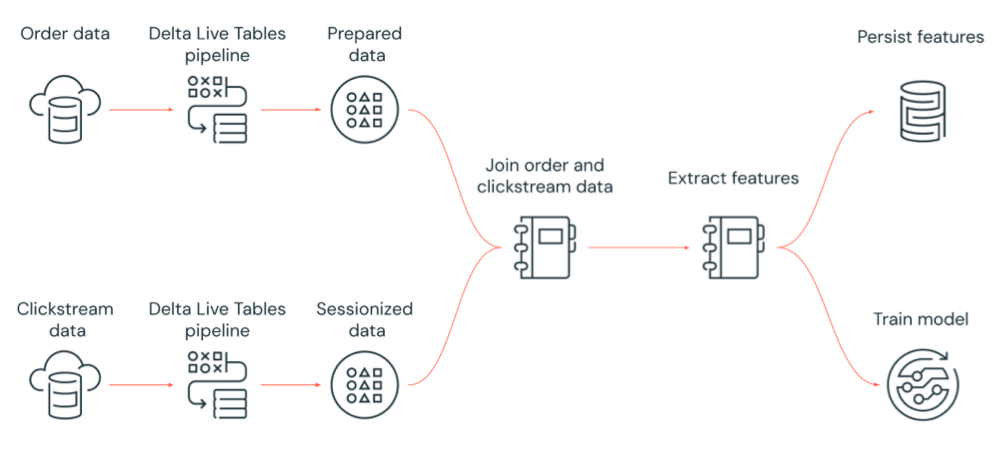
次の図は、Azure Databricks ジョブによって調整され、次を実行するワークフローを示しています。
- クラウド ストレージから生のクリックストリーム データを取り込み、データをクリーンアップして準備し、データをセッション化し、最終的なセッション化されたデータ セットを Delta Lake に保持する Delta Live Tables パイプラインを実行します。
- クラウド ストレージから注文データを取り込み、処理のためにデータをクリーンアップして変換し、最終的なデータ セットを Delta Lake に保持する Delta Live Tables パイプラインを実行します。
- 注文とセッション化されたクリックストリーム データを結合して、分析用の新しいデータ セットを作成します。
- 準備されたデータから特徴を抽出します。
- 特徴を保持し、機械学習モデルをトレーニングするタスクを並行して実行します。
Azure Databricks ジョブとは
Azure Databricks ジョブは、Azure Databricks ワークスペースでデータ処理および分析アプリケーションを実行する方法です。 ジョブは単一タスクで構成するか、複雑な依存関係がある大規模なマルチタスク ワークフローで構成できます。 Azure Databricks が、すべてのジョブのタスク オーケストレーション、クラスター管理、監視、およびエラー レポートを管理します。 ジョブは、すぐに、または使いやすいスケジュール システムを使用して定期的に、または新しいファイルが外部の場所に到着するたびに、またはジョブのインスタンスが常に実行されているように継続的に実行できます。 ノートブック UI でジョブを対話形式で実行することもできます。
ジョブを作成および実行するには、ジョブ UI、Databricks CLI を使用するか、Jobs API を呼び出します。 UI または API を使用して、失敗したジョブまたは取り消されたジョブを修復して再実行できます。 UI、CLI、API、通知 (メール、Webhook の宛先、Slack 通知など) を使用して、ジョブの実行結果を監視できます。
Databricks CLI の使用については、「Databricks CLI とは」を参照してください。 Jobs API の使用方法については、「Jobs API」をご覧ください。
次のセクションでは、Azure Databricks ジョブの重要な機能について説明します。
重要
- 1 つのワークスペースでのタスクの同時実行は、1000 に制限されています。 すぐに開始できない実行を要求した場合は、
429 Too Many Requests応答が返されます。 - 1 時間に 1 つのワークスペースで作成できるジョブの数は、10000 に制限されます ("実行の送信" を含む)。 この制限は、REST API およびノートブック ワークフローによって作成されるジョブにも影響します。
ジョブ タスクを使用してデータ処理および分析を実装する
タスクを使用して、データ処理および分析ワークフローを実装します。 ジョブは、1 つ以上のタスクで構成されます。 ノートブック、JARS、Delta Live Tables パイプライン、または Python、Scala、Spark submit、および Java アプリケーションを実行するジョブ タスクを作成できます。 ジョブのタスクでは、Databricks SQL クエリ、アラートとダッシュボードを調整して、分析と視覚化を作成することも、dbt タスクを使用してワークフローで dbt 変換を実行することもできます。 レガシ Spark Submit アプリケーションもサポートされています。
別のジョブを実行するジョブにタスクを追加することもできます。 この機能を使用すると、大規模なプロセスを複数の小さなジョブに分割したり、複数のジョブで再利用できる一般化されたモジュールを作成したりできます。
タスク間の依存関係を指定することにより、タスクの実行順を制御します。 シーケンスまたは並列で実行するようにタスクを構成できます。
対話形式で、継続的に、またはジョブ トリガーを使用してジョブを実行する
ジョブは、Jobs UI、API、または CLI から対話形式で実行することも、継続的ジョブを実行することもできます。 スケジュールを作成してジョブを定期的に実行したり、Amazon S3、Azure Storage、Google Cloud Storage などの外部の場所に新しいファイルが到着したときにジョブを実行したりできます。
通知を使用してジョブの進行状況を監視する
ジョブまたはタスクの開始、完了、または失敗時に通知を受け取ることができます。 通知は、1 つ以上のメール アドレスまたはシステムの宛先 (Webhook の宛先や Slack など) に送信できます。 「ジョブ イベントのメール通知とシステム通知を追加する」を参照してください。
システム テーブルを使用してジョブ コストとアクティビティを監視する
システム テーブルには、アカウント内のジョブ アクティビティに関連するレコードを表示できる workflow スキーマが含まれています。 「ジョブ システム テーブル リファレンス」を参照してください。
ジョブ システム テーブルを課金テーブルと結合し、アカウント全体のジョブ コストを監視することもできます。 「システム テーブルを使用してジョブ コストを監視する」を参照してください。
Azure Databricks コンピューティング リソースを使用してジョブを実行する
Databricks クラスターと SQL ウェアハウスでは、ジョブのコンピューティング リソースが提供されます。 ジョブ クラスター、汎用クラスター、または SQL ウェアハウスを使用してジョブを実行できます。
- ジョブ クラスターは、ジョブまたは個々のジョブ タスク専用クラスターです。 ジョブでは、すべてのタスクで共有されるジョブ クラスターを使用することも、タスクを作成または編集するときに個々のタスク用にクラスターを構成することもできます。 ジョブ クラスターは、ジョブまたはタスクの開始時に作成され、ジョブまたはタスクの終了時に終了します。
- 汎用クラスターは、手動で開始および終了され、複数のユーザーとジョブで共有できる共有クラスターです。
リソースの使用を最適化するために、Databricks ではジョブにジョブ クラスターを使用することをお勧めします。 クラスターの起動の待機に費やす時間を短縮するには、汎用クラスターの使用を検討してください。 「ジョブで Azure Databricks コンピューティングを使用する」を参照してください。
クエリ、ダッシュボード、アラートなどの Databricks SQL タスクを実行するには、SQL ウェアハウスを使用します。 さらに dbt タスクで dbt 変換を実行するためにも SQL ウェアハウスを使用することができます。
次の手順
Azure Databricks ジョブの使用を開始するには:
クイックスタートを使用して、最初の Azure Databricks ジョブを作成します。
Azure Databricks ジョブ ユーザー インターフェイスを使用してワークフローを作成して実行する方法を確認します。
サーバーレス ワークフローを使用して、Azure Databricks コンピューティング リソースを構成せずにジョブを実行する方法について説明します。
Azure Databricks ジョブ ユーザー インターフェイスでのジョブの実行の監視について確認します。
ジョブの構成オプションについて確認します。
Azure Databricks ジョブを使用したワークフローの構築、管理、トラブルシューティングの詳細について確認します。
- タスク値を使用して Azure Databricks ジョブ内のタスク間で情報を通信する方法について説明します。
- タスク パラメーター変数を使用して、ジョブの実行に関するコンテキストをジョブ タスクに渡す方法を確認します。
- タスクの依存関係の状態に基づいて条件付きで実行されるようにジョブ タスクを構成する方法について説明します。
- 失敗したジョブのトラブルシューティングと修正を行う方法について説明します。
- ジョブの実行が開始、完了、または失敗したときに、ジョブ実行通知によって通知を受け取ります。
- カスタム スケジュールでジョブをトリガーするか、継続的ジョブを実行します。
- ファイル到着トリガーを使用して新しいデータが到着したときに Azure Databricks ジョブを実行する方法を確認します。
- Databricks コンピューティング リソースを使用してジョブを実行する方法を確認します。
- Azure Databricks ジョブでワークフローの作成と管理をサポートするための「Jobs API の更新」を確認します。
- 攻略ガイドとチュートリアルを使用して、Azure Databricks ジョブによるデータ ワークフローの実装の詳細を確認します。
Delta Live Tables とは
注意
Delta Live Tables には Premium プランが必要です。 詳細については、Databricks アカウント チームにお問い合わせください。
Delta Live Tables は、ETL とストリーミング データ処理を簡素化するフレームワークです。 Delta Live Tables では、自動ローダーの組み込みサポート、データ変換の宣言型実装をサポートする SQL および Python インターフェイス、および変換されたデータを Delta Lake に書き込むためのサポートを備えた、効率的なデータ インジェストが提供されます。 データに対して実行する変換を定義すると、Delta Live Tables によってタスク オーケストレーション、クラスター管理、監視、データ品質、およびエラー処理が管理されます。
使用を開始するには、「Delta Live Tables とは」を参照してください。
Azure Databricks ジョブと Delta Live Tables
Azure Databricks ジョブと Delta Live Tables では、エンドツーエンドのデータ処理および分析ワークフローの構築とデプロイのための包括的フレームワークが提供されます。
データのすべてのインジェストと変換に Delta Live Tables が使用されます。 Azure Databricks ジョブを使用して、Delta Live Tables のインジェストや変換など、Databricks プラットフォームでの単一のタスクまたは複数のデータ処理および分析タスクから構成されるワークロードが調整されます。
ワークフロー オーケストレーション システムとして、Azure Databricks ジョブでは次もサポートされています。
- スケジュールに基づくワークフローの実行など、トリガー ベースでジョブを実行する。
- SQL クエリによるデータ分析、ノートブック、スクリプト、または外部ライブラリを使用した機械学習とデータ分析など。
- JAR にパッケージ化された Apache Spark ジョブの実行など、単一のタスクで構成されるジョブの実行。
Apache AirFlow を使用したワークフロー オーケストレーション
Databricks では Azure Databricks Jobs を使用してデータ ワークフローを調整することをお勧めしますが、Apache Airflow を使用してデータ ワークフローを管理およびスケジュールすることもできます。 Airflow では、Python ファイルにワークフローを定義すると、Airflow でワークフローのスケジュールと実行が管理されます。 「Apache Airflow を使用して Azure Databricks ジョブを調整する」を参照してください。
Azure Data Factory を使用したワークフロー オーケストレーション
Azure Data Factory (ADF) は、データの保管、移行、処理のサービスを自動化されたデータ パイプラインにまとめることができるクラウド データ統合サービスです。 ADF を使用すると、ADF パイプラインの一部として Azure Databricks ジョブを調整できます。
ADF から Azure Databricks に対して認証する方法など、ADF Web アクティビティを使用してジョブを実行する方法については、「Azure Data Factory から Azure Databricks ジョブ オーケストレーションを活用する」を参照してください。
ADF には、ADF パイプラインで Databricks ノートブック、Python スクリプト、または JAR にパッケージ化されたコードを実行するための組み込みのサポートも用意されています。
ADF パイプラインで Databricks ノートブックを実行する方法については、「Azure Data Factory で Databricks Notebook アクティビティを使用して Databricks ノートブックを実行する」と、次に「Databricks Notebook を実行してデータを変換する」を参照してください。
ADF パイプラインで Python スクリプトを実行する方法については、「Azure Databricks で Python アクティビティを実行してデータを変換する」を参照してください。
ADF パイプラインで JAR にパッケージ化されたコードを実行する方法については、「Azure Databricks で JAR アクティビティを実行してデータを変換する」を参照してください。