Python で AutoML トレーニングを設定する

このガイドでは、Azure Machine Learning Python SDK で Azure Machine Learning 自動 ML を使用して自動機械学習 (AutoML) トレーニング実行を設定する方法を説明します。 自動 ML では、ユーザーに代わってアルゴリズムとハイパーパラメーターを選択し、デプロイ可能なモデルを生成します。 このガイドでは、自動 ML 実験の構成に使用できるさまざまなオプションについて詳しく説明しています。
エンドツーエンドの例は、AutoML による回帰モデルのトレーニングのチュートリアルに関する記事をご覧ください。
ノーコードで行いたい場合は、Azure Machine Learning スタジオでノーコードの Auto ML トレーニングを設定することもできます。
前提条件
この記事では、以下が必要です。
Azure Machine Learning ワークスペース。 ワークスペースを作成するには、「ワークスペース リソースの作成」を参照してください。
Azure Machine Learning Python SDK がインストールされていること。 SDK をインストールするには、次のいずれかを行います。
コンピューティング インスタンスを作成します。これにより、SDK が自動的にインストールされ、ML ワークフロー用に事前構成されます。 詳細については、「Azure Machine Learning コンピューティング インスタンスの作成と管理」を参照してください。
SDK の既定のインストールが含まれる、
automlパッケージを自分でインストールします。
重要
この記事の Python コマンドでは、最新の
azureml-train-automlパッケージ バージョンが必要です。- 最新の
azureml-train-automlパッケージをローカル環境にインストールします。 - 最新の
azureml-train-automlパッケージの詳細については、リリース ノートを参照してください。
警告
Python 3.8 は
automlと互換性がありません。
実験の種類を選択する
実験を始める前に、解決する機械学習の問題の種類を決める必要があります。 自動機械学習によって、classification、regression、forecasting というタスクの種類がサポートされています。 タスクの種類についての詳細情報を参照してください。
Note
自然言語処理 (NLP) タスクのサポート: 画像分類 (複数クラスおよび複数ラベル) と名前付きエンティティ認識は、パブリック プレビューで利用できます。 自動 ML における NLP タスクについてさらに学習します。
これらのプレビュー機能は、サービスレベル アグリーメントなしで提供されます。 一部の機能はサポートされていない、または機能が制限されている可能性があります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
次のコードでは、AutoMLConfig コンストラクターで task パラメーターが使用され、実験の種類が classification として指定されています。
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
データ ソースと形式
自動機械学習では、ローカル デスクトップ上またはクラウド (Azure Blob Storage など) に存在するデータがサポートされます。 データは、Pandas DataFrame または Azure Machine Learning TabularDataset に読み込むことができます。 データセットの詳細情報.
機械学習でのトレーニング データの要件:
- データは表形式である必要があります。
- 予測する値、ターゲット列は、データ内にある必要があります。
重要
自動 ML の実験では、ID ベースのデータ アクセスを使用するデータセットでのトレーニングはサポートされていません。
リモート実験の場合、トレーニング データにリモート コンピューティングからアクセスできる必要があります。 自動 ML により、リモート コンピューティングでの作業時に Azure Machine Learning TabularDatasets のみが受け入れられます。
Azure Machine Learning のデータセットによって、次の機能が公開されます。
- 静的ファイルまたは URL ソースからワークスペースにデータを簡単に転送する。
- クラウド コンピューティング リソースでの実行時にデータをトレーニング スクリプトで使用できるようにする。
Datasetクラスを使用してコンピューティング ターゲットにデータをマウントする例については、データセットを使ってトレーニングする方法を参照してください。
次のコードにより、Web URL から TabularDataset が作成されます。 ローカル ファイルやデータストアなどの他のソースからデータセットを作成する方法のコード例については、「TabularDataset を作成する」を参照してください。
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
ローカル コンピューティングの実験の場合、より高速な処理時間を実現するために、pandas dataframes をお勧めします。
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
トレーニング、検証、テストのデータ
AutoMLConfig コンストラクターでは、個別のトレーニング データと検証データのセットを直接指定できます。 自動 ML 実験の詳細については、トレーニング、検証、クロス検証、テストのデータの構成方法に関する記事を参照してください。
validation_data または n_cross_validation パラメーターを明示的に指定しない場合、自動 ML では、既定の手法を適用して検証の実行方法を決定します。 この決定は、training_data パラメーターに割り当てられたデータセット内の行の数によって異なります。
| トレーニング データのサイズ | 検証の方法 |
|---|---|
| 20,000 行を超える | トレーニング/検証データの分割が適用されます。 既定では、初期トレーニング データ セットの 10% が検証セットとして取得されます。 次に、その検証セットがメトリックの計算に使用されます。 |
| 20,000 行未満 | クロス検証アプローチが適用されます。 フォールドの既定の数は行数によって異なります。 データセットが 1,000 行より少ない場合は、10 個のフォールドが使用されます。 行が 1,000 から 20,000 の間の場合は、3 つのフォールドが使用されます。 |
ヒント
テスト データ (プレビュー) をアップロードすると、自動 ML によって生成されたモデルを評価することができます。 これらの機能は試験段階のプレビュー機能であり、いつでも変更される可能性があります。 具体的には、次の方法を学習します。
コードなしエクスペリエンスが望ましい場合は、スタジオ UI を使った自動 ML の設定に関する記事の手順 12 を参照してください。
大きなデータ
自動 ML でサポートされる限られた数のアルゴリズム数は、大きなデータのトレーニングに対応しており、小さな仮想マシン上でビッグ データのモデルを構築を成功させることができます。 自動 ML ヒューリスティックは、データ サイズ、仮想マシンのメモリ サイズ、実験のタイムアウト、特徴量化設定などのプロパティを利用して、大きなデータのアルゴリズムを適用すべきかどうかを決定します。 自動 ML でサポートされるモデルについてはこちらを参照してください。
回帰については、オンライン勾配降下リグレッサーおよび高速線形リグレッサーに関するページ
分類については、平均化パーセプトロン分類子および線形 SVM 分類子に関するページ。線形 SVM 分類子には大きなデータ用と小さなデータ用両方のバージョンがあります。
これらのヒューリスティックをオーバーライドする場合は、次の設定を適用します。
| タスク | 設定 | メモ |
|---|---|---|
| データ ストリーミング アルゴリズムをブロックする | AutoMLConfig オブジェクトに blocked_models。使用しないモデルを指定します。 |
実行エラーが発生するか実行時間が長くなります |
| データ ストリーミング アルゴリズムを使用する | AutoMLConfig オブジェクトに allowed_models。使用するモデルを指定します。 |
|
| データ ストリーミング アルゴリズムを使用する (スタジオ UI 実験) |
使用するビッグ データ アルゴリズムを除くすべてのモデルをブロックします。 |
実験を実行するために計算する
次に、モデルをトレーニングする場所を決定します。 自動 ML トレーニングの実験は、次のコンピューティング オプションで実行できます。
ローカル コンピューティングを選択する:小規模のデータと短いトレーニング (つまり、子実行あたり数秒または数分) を使用する、初期探索またはデモのためのシナリオの場合は、ローカル コンピューター上でのトレーニングが適している場合があります。 セットアップ時間はかからず、インフラストラクチャ リソース (お使いの PC または VM) を直接使用できます。 ローカル コンピューティングの例については、このノートブックを参照してください。
リモート ML コンピューティング クラスターを選択する:より長いトレーニングが必要なモデルを作成する運用環境でのトレーニングのように、より大きなデータセットを使用してトレーニングを行う場合、リモート コンピューティングを選択するとエンド ツー エンドの時間のパフォーマンスが大幅に向上します。
AutoMLによってクラスターのノード間でトレーニングが並列化されるためです。 リモート コンピューティングでは、内部インフラストラクチャの起動時間には、子実行あたり約 1.5 分に加え、VM がまだ稼働していない場合はクラスター インフラストラクチャ用の時間が追加されます。Azure Machine Learning マネージド コンピューティングは、Azure 仮想マシンのクラスターで機械学習モデルをトレーニングできるようにするマネージド サービスです。 コンピューティング インスタンスは、コンピューティング先としてもサポートされます。Azure サブスクリプション内の Azure Databricks クラスター。 詳細については、自動 ML のための Azure Databricks クラスターの構成に関する記事を参照してください。 Azure Databricks でのノートブックの例については、こちらの GitHub サイトをご覧ください。
使用するコンピューティング先を選択するときに、次の要素を考慮してください。
| 長所 (利点) | 短所 (欠点) | |
|---|---|---|
| ローカル コンピューティング先 | ||
| リモート ML コンピューティング クラスター |
実験の設定を構成する
自動 ML 実験を構成するときは、いくつかのオプションを使用できます。 これらのパラメーターは、AutoMLConfig オブジェクトをインスタンス化することによって設定します。 パラメーターの完全な一覧については、「AutoMLConfig クラス」をご覧ください。
次に分類タスクの例を示します。 実験では、主要メトリックとして重み付けされた AUC が使用され、実験のタイムアウトが 30 分に設定され、クロス検証フォールドは 2 つあります。
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
予測タスクを構成することもできますが、追加の設定が必要です。 詳細については、時系列予測用に AutoML を設定する方法に関する記事をご覧ください。
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
サポートされているモデル
自動機械学習によって、自動化とチューニングのプロセス中にさまざまなモデルとアルゴリズムが試行されます。 ユーザーは、アルゴリズムを指定する必要はありません。
3 つの異なる task パラメーター値によって、適用するアルゴリズムまたはモデルの一覧が決定されます。 使用可能なモデルを包含または除外してさらにイテレーションを変更するには、allowed_models または blocked_models パラメーターを使用します。
次の表は、サポートされるモデルをタスクの種類別にまとめたものです。
注意
自動 ML で作成したモデルを ONNX モデルとしてエクスポートすることを予定している場合、ONNX 形式に変換できるのは * (アスタリスク) の付いたアルゴリズムだけであることにご注意ください。 モデルの ONNX への変換の詳細についてご確認ください。
また、ONNX では現在、分類と回帰のタスクのみがサポートされていることにもご注意ください。
| 分類 | 回帰 | 時系列予測 |
|---|---|---|
| ロジスティック回帰* | Elastic Net* | AutoARIMA |
| Light GBM* | Light GBM* | Prophet |
| 勾配ブースティング* | 勾配ブースティング* | Elastic Net |
| デシジョン ツリー* | デシジョン ツリー* | Light GBM |
| K ニアレスト ネイバー* | K ニアレスト ネイバー* | 勾配ブースティング |
| Linear SVC* | LARS Lasso* | デシジョン ツリー |
| サポート ベクター分類 (SVC)* | 確率的勾配降下法 (SGD)* | Arimax |
| ランダム フォレスト* | ランダム フォレスト | LARS Lasso |
| Extremely Randomized Trees* | Extremely Randomized Trees* | 確率的勾配降下法 (SGD) |
| Xgboost* | Xgboost* | ランダム フォレスト |
| 平均化パーセプトロン分類子 | オンライン勾配降下リグレッサー | Xgboost |
| 単純ベイズ* | 高速線形リグレッサー | ForecastTCN |
| 確率的勾配降下法 (SGD)* | Naive | |
| Linear SVM Classifier* | SeasonalNaive | |
| Average | ||
| SeasonalAverage | ||
| ExponentialSmoothing |
主要メトリック
primary_metric パラメーターによって、モデルのトレーニング中に最適化のために使用されるメトリックが決まります。 選択できる使用可能メトリックは、選択したタスクの種類によって決まります。
自動 ML で何を primary metric (主要メトリック) に選ぶべきかは、多くの要素に左右されます。 最優先の考慮事項としてお勧めするのは、ビジネス ニーズを最も適切に表すメトリックを選択することです。 次に、メトリックがデータセット プロファイル (データのサイズ、範囲、クラスの分布など) に適しているかどうかを考慮します。 次のセクションでは、タスクの種類とビジネス シナリオに基づいて、推奨される主要メトリックをまとめています。
これらのメトリックの具体的な定義については、「自動化機械学習の結果の概要」を参照してください。
分類シナリオのメトリック
accuracy、recall_score_weighted、norm_macro_recall、precision_score_weighted などのしきい値に依存するメトリックでは、データセットが小さい場合や非常に大きいクラス傾斜 (クラスの不均衡) がある場合、または予期されるメトリック値が 0.0 または 1.0 に非常に近い場合に、適切に最適化されないことがあります。 このような場合、主要メトリックには AUC_weighted が適しています。 自動 ML が完了したら、業務上の必要に最も適したメトリックを基準にして、最適なモデルを選ぶことができます。
| メトリック | ユース ケースの例 |
|---|---|
accuracy |
画像分類、感情分析、チャーン予測 |
AUC_weighted |
不正行為の検出、画像分類、異常検出/スパム検出 |
average_precision_score_weighted |
センチメント分析 |
norm_macro_recall |
チャーン予測 |
precision_score_weighted |
回帰シナリオのメトリック
r2_score、normalized_mean_absolute_error、normalized_root_mean_squared_error は、いずれも予測誤差を最小限に抑えるためのものです。 r2_score と normalized_root_mean_squared_error はどちらも平均二乗誤差を最小化するものですが、normalized_mean_absolute_error は誤差の平均絶対値を最小化するものです。 絶対値の場合、すべての大きさの誤差は同様に扱われ、二乗誤差は絶対値が大きい誤差に対してはるかに大きなペナルティがあります。 より大きな誤差をより罰する必要があるかどうかに応じて、二乗誤差と絶対値誤差のどちらを最適化するかを選ぶことができます。
r2_score と normalized_root_mean_squared_error の主な違いは、正規化の方法とその意味です。 normalized_root_mean_squared_error は範囲で正規化された二乗平均平方根誤差であり、予測の平均誤差の大きさとして解釈できます。 r2_score はデータの分散の推定値で正規化された平均二乗誤差です。 これは、モデルでキャプチャできる変動の割合です。
注意
r2_score と normalized_root_mean_squared_error はプライマリ メトリックと同様に動作します。 固定の検証セットが適用されている場合、これら 2 つのメトリックによって同じターゲットである平均二乗誤差が最適化され、同じモデルによって最適化されます。 トレーニング セットのみが使用可能であり、相互検証が適用される場合、normalized_root_mean_squared_error のノーマライザーはトレーニング セットの範囲として固定されていますが、r2_score のノーマライザーは各フォールドの変性であるため、フォールドごとに異なり、両者は若干異なります。
正確な値ではなく順位に関心がある場合は、実際の値と予測値の順位相関を測定する spearman_correlation を選ぶことをお勧めします。
ただし、現在のところ、相対的な差に対応する回帰の主要なメトリックはありません。 r2_score、normalized_mean_absolute_error、normalized_root_mean_squared_error のいずれでも、これらの 2 つのデータ ポイントが回帰用の同じデータセット、または時系列識別子で指定された同じ時系列に属している場合、給料が 3 万ドルのワーカーと 2,000 万ドルのワーカーの 2 万ドルの予測誤差が同様に処理されます。 実際には、20000 ドルと隔たった 20000000 ドルの給与のみ予測することは非常に近く (相対差異は 0.1% で小さい)、一方 20000 ドルと隔たった 30000 ドルを予測することは近くありません (相対差異は 67% で大きい)。 相対差の問題を解決するには、使用可能な主要メトリックを使ってモデルをトレーニングしてから、mean_absolute_percentage_error または root_mean_squared_log_error が最適なモデルを選ぶことができます。
| メトリック | ユース ケースの例 |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
価格の予測 (家/製品/チップ)、レビュー スコアの予測 |
r2_score |
飛行機の遅延、給与の見積もり、バグの解決時間 |
normalized_mean_absolute_error |
時系列予測シナリオのメトリック
推奨事項は、回帰シナリオのものと似ています。
| メトリック | ユース ケースの例 |
|---|---|
normalized_root_mean_squared_error |
価格の予測 (予想)、在庫の最適化、需要の予測 |
r2_score |
価格の予測 (予想)、在庫の最適化、需要の予測 |
normalized_mean_absolute_error |
データの特徴付け
大きさの基準が異なる特徴量を使用する場合に影響を受ける特定のアルゴリズムが適切に機能するよう、自動 ML のすべての実験では、自動的にデータを係数で乗じて正規化します。 このスケーリングと正規化は特徴量化と呼ばれます。 詳細とコード例については、AutoML での特徴量化に関するページを参照してください。
注意
自動化された機械学習の特徴付け手順 (機能の正規化、欠損データの処理、テキストから数値への変換など) は、基になるモデルの一部になります。 このモデルを予測に使用する場合、トレーニング中に適用されたのと同じ特徴付けの手順がご自分の入力データに自動的に適用されます。
AutoMLConfig オブジェクトで実験を構成するときに、設定 featurization の有効と無効を切り替えることができます。 次の表は、AutoMLConfig プロジェクトの特徴量化で許可されている設定です。
| 特徴付けの構成 | 説明 |
|---|---|
"featurization": 'auto' |
前処理の一環として、データ ガードレールと特徴付けの手順が自動的に実行されることを示します。 既定の設定です。 |
"featurization": 'off' |
特徴量化の手順が自動的には実行されないことを示します。 |
"featurization": 'FeaturizationConfig' |
カスタマイズされた特徴付け手順を使用する必要があることを示します。 特徴付けをカスタマイズする方法の詳細。 |
アンサンブル構成
アンサンブル モデルは既定で有効になっており、AutoML の実行での最終実行イテレーションとして表示されます。 現在は VotingEnsemble と StackEnsemble がサポートされています。
投票では、加重平均を使用したソフト投票を実装します。 スタッキング実装は 2 層の実装を使用します。ここでは、第 1 層は投票アンサンブルと同じモデルを持ち、第 2 層のモデルは、第 1 層からのモデルの最適な組み合わせを見つけるために使用されます。
ONNX モデルを使用している場合、またはモデルの説明を有効にしている場合、スタッキングは無効になり、投票だけが使用されます。
アンサンブル トレーニングは、enable_voting_ensemble および enable_stack_ensemble のブール型パラメーターを使用して無効にすることができます。
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
既定のアンサンブル動作を変更するために、AutoMLConfig オブジェクトに kwargs として提供できる既定の引数が複数あります。
重要
次のパラメーターは、AutoMLConfig クラスの明示的なパラメーターではありません。
ensemble_download_models_timeout_sec:VotingEnsemble と StackEnsemble モデルの生成中に、以前の子実行の複数の適合モデルがダウンロードされます。AutoMLEnsembleException: Could not find any models for running ensemblingのエラーが発生した場合は、モデルのダウンロードにより長い時間が必要になることがあります。 既定値は、これらのモデルを並列でダウンロードする場合は 300 秒で、タイムアウトの上限はありません。 より長い時間が必要な場合は、このパラメーターを 300 秒より大きい値に設定します。注意
タイムアウトに達し、ダウンロードしたモデルがある場合は、アンサンブルはダウンロードしたモデルと同じ数だけ処理を続行します。 そのタイムアウト以内にすべてのモデルのダウンロードを終える必要はありません。 次のパラメーターは、StackEnsemble モデルにのみ適用されます。
stack_meta_learner_type: メタ学習器は、個々の異種モデルの出力でトレーニングされたモデルです。 既定のメタ学習器は、分類タスクにはLogisticRegression(またはクロス検証が有効になっている場合はLogisticRegressionCV) で、回帰/予測タスクにはElasticNet(またはクロス検証が有効になっている場合はElasticNetCV) です。 このパラメーターは、LogisticRegression、LogisticRegressionCV、LightGBMClassifier、ElasticNet、ElasticNetCV、LightGBMRegressor、またはLinearRegressionのいずれかの文字列になります。stack_meta_learner_train_percentage: メタ学習器のトレーニング用に予約されるトレーニング セットの割合を指定します。(トレーニングと、トレーニングの検証の種類を選択する場合)。 既定値は0.2です。stack_meta_learner_kwargs: メタ学習器の初期化子に渡す省略可能なパラメーター。 これらのパラメーターとパラメーターの型は、対応するモデル コンストラクターからのパラメーターとパラメーターの型を反映しており、モデル コンストラクターに転送されます。
次のコードは、AutoMLConfig オブジェクトでカスタムのアンサンブル動作を指定する例を示します。
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
終了基準
実験を終了するために AutoMLConfig で定義できるオプションはいくつかあります。
| 条件 | description |
|---|---|
| 基準なし | 終了パラメーターを定義しない場合、実験は、主なメトリックでそれ以上の進歩が見られなくなるまで続けられます。 |
| 一定の時間が経過後 | 設定で experiment_timeout_minutes を使用すると、実験の実行を継続する時間を分単位で定義できます。 実験のタイムアウト エラーを回避するため、最小値は 15 分です (行と列を掛けたサイズが 1,000 万を超える場合は 60 分)。 |
| スコアに達した | experiment_exit_score を使用すると、指定した主要メトリックのスコアに達した後に実験が完了します。 |
実験を実行する
警告
同じ構成設定とプライマリ メトリックを使用して実験を複数回実行した場合、各実験の最終的なメトリック スコアおよび生成されるモデルに変動が見られる可能性があります。 自動 ML のアルゴリズムには特有のランダム性があり、実験によって出力されるモデルおよび推奨モデルの最終的なメトリック スコア (精度など) にわずかな変動が生じる可能性があります。 また、モデル名が同じだが、使用されるハイパーパラメーターが異なる結果が表示される可能性もあります。
自動化された ML の場合は Experiment オブジェクトを作成します。これは、実験を実行するために使用される Workspace 内の名前付きオブジェクトです。
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
実験を送信して実行し、モデルを生成します。 モデルを生成するには、AutoMLConfig を submit メソッドに渡します。
run = experiment.submit(automl_config, show_output=True)
注意
最初に依存関係が新しいマシンにインストールされます。 出力が表示されるまで、最大で 10 分間かかる場合があります。
show_output を True に設定すると、コンソールに出力が表示されます。
クラスターでの複数回の子実行
自動 ML での子実行の実験は、既に別の実験が実行されているクラスターで実行することができます。 ただし、タイミングは、クラスターに含まれるノード数によって、および別の実験を実行するためにそれらのノードを使用できるかどうかによって異なります。
クラスター内の各ノードは、1 回のトレーニング実行を完了できる個別の仮想マシン (VM) として機能します。自動 ML の場合、これは子実行を意味します。 すべてのノードがビジー状態の場合は、新しい実験がキューに登録されます。 ただし、空きノードがある場合は、使用可能なノードと VM で、新しい実験によって自動 ML 子実行が並行して実行されます。
子実行とそれが実行されるタイミングを管理するには、実験ごとに専用のクラスターを作成し、実験の max_concurrent_iterations 数をクラスター内のノード数と一致させることをお勧めします。 このようにして、必要な同時子実行とイテレーションの数で、クラスターのノードをすべて同時に使用します。
AutoMLConfig オブジェクトで max_concurrent_iterations を構成します。 構成されていない場合は、1 回の実験につき 1 回の同時子実行とイテレーションのみが既定で許可されます。
コンピューティング インスタンスの場合は、max_concurrent_iterations をコンピューティング インスタンス VM 上のコア数と同じに設定できます。
モデルとメトリックを探索する
自動 ML では、トレーニング結果を監視および評価するためのオプションが提供されます。
トレーニング結果をウィジェットで、またはノートブックの場合はインラインで、表示できます。 詳細については、「自動機械学習の実行を監視する」を参照してください。
実行のたびに提供されるパフォーマンス グラフおよびメトリックの定義と例については、「自動化機械学習実験の結果を評価する」を参照してください。
特徴量化の概要を確認し、特定のモデルに追加された機能を理解するには、「特徴量化の透過性」を参照してください。
カスタム コード ソリューション print_model() を使用して、特定の自動 ML の実行に適用されるハイパーパラメーター、スケーリングと正規化の手法、およびアルゴリズムを表示できます。
ヒント
自動 ML を使用すると、自動ML でトレーニングされたモデルに対して生成されたモデル トレーニング コードを表示することもできます。 この機能はパブリック プレビューにあり、いつでも変更できます。
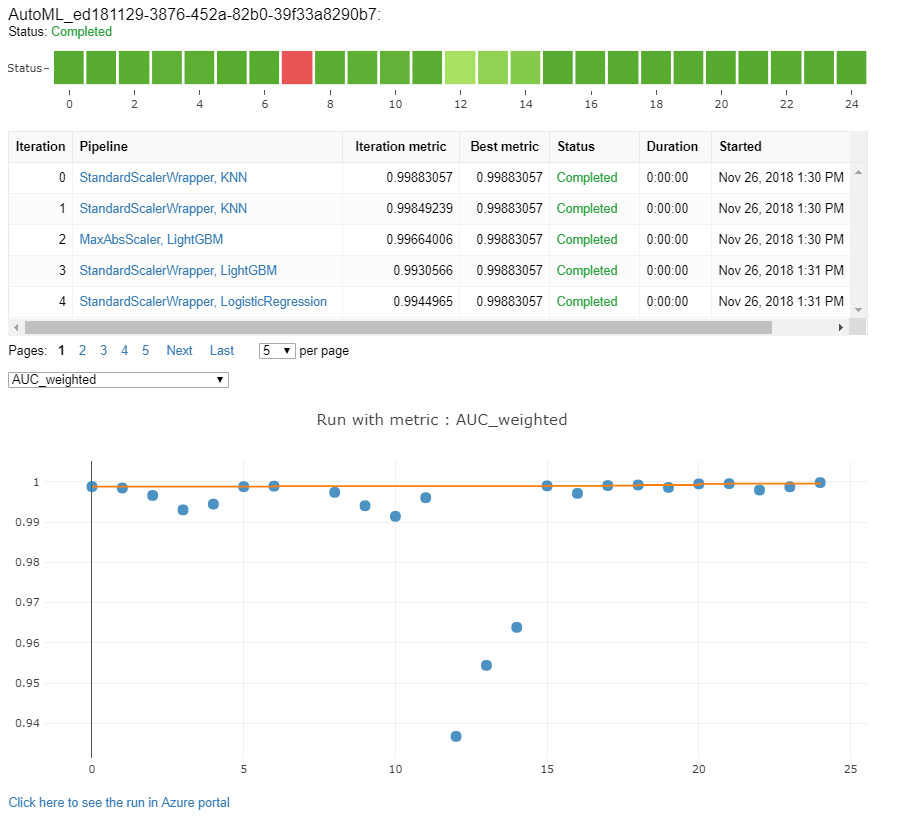
自動機械学習の実行を監視する
自動 ML の実行で、前回の実行のグラフにアクセスするには、<<experiment_name>> を適切な実験名に置き換えます。
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
モデルをテストする (プレビュー)
重要
自動 ML によって生成されたモデルを評価するために、テスト データセットを使ってモデルをテストすることは、プレビュー機能です。 この機能は試験段階のプレビュー機能であり、随時変更される可能性があります。
警告
この機能は、次の自動 ML シナリオでは使用できません
test_data または test_size のパラメーターを AutoMLConfig に渡すと、指定されたテスト データを使うリモート テストの実行が自動的にトリガーされ、実験終了時に自動 ML によって推奨される最適なモデルが評価されます。 このリモート テストの実行は、実験の最後に、最適なモデルが決まった時点で行われます。 テスト データを AutoMLConfig に渡す方法を参照してください。
テスト ジョブの結果を取得する
リモート テスト ジョブの予測値とメトリックは、Azure Machine Learning スタジオから、または次のコードを使って取得できます。
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
モデル テスト ジョブでは、predictions.csv ファイルが生成され、ワークスペースで作成された既定のデータストアに格納されます。 このデータストアは、同じサブスクリプションを持つすべてのユーザーに表示されます。 テスト ジョブは、テスト ジョブで使用または作成された情報を非公開にする必要があるシナリオにはお勧めできません。
既存の自動 ML モデルをテストする
作成された他の既存の自動 ML モデル、最適なジョブ、または子ジョブをテストするには、メインの自動 ML の実行が完了した後に ModelProxy() を使ってモデルをテストします。 ModelProxy() からは既に予測値とメトリックが返されているので、出力を取得するための追加の処理は必要ありません。
注意
ModelProxy は試験段階のプレビュー クラスであり、いつでも変更される可能性があります。
次のコードは、ModelProxy.test() メソッドを使い、任意の実行からモデルをテストする方法を示しています。 test() メソッドでは、include_predictions_only パラメーターを使ってテストの実行の予測のみを表示するかどうかを指定できます。
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
モデルを登録してデプロイする
モデルをテストし、運用環境で使うことを決めたら、後で使用できるようにモデルを登録することができます
自動化された ML 実行からモデルを登録するには、register_model() メソッドを使用します。
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
デプロイ構成を作成し、登録済みのモデルを Web サービスにデプロイする方法の詳細については、モデルをデプロイする方法と場所に関するページを参照してください。
ヒント
登録済みのモデルの場合、Azure Machine Learning スタジオを使用してワンクリックでデプロイできます。 登録済みのモデルをスタジオからデプロイする方法に関するページを参照してください。
モデルの解釈可能性
モデルの解釈機能を使用すると、モデルで予測が行われた理由や、基になる特徴の重要度の値を把握できます。 SDK には、トレーニングと推論時間の両方で、ローカル モデルとデプロイされたモデルについて、モデルの解釈可能性の特徴を有効にするためのさまざまなパッケージが含まれています。
自動 ML の実験で特に解釈可能性の機能を有効にする方法を参照してください。
自動機械学習ではない SDK の他の領域で、モデルの説明と特徴量の重要度を有効にする方法の一般情報については、解釈可能性の概念に関する記事を参照してください。
注意
現在、ForecastTCN モデルは説明クライアントではサポートされていません。 このモデルが最適なモデルとして返された場合、説明ダッシュボードは返されず、オンデマンドでの説明の実行はサポートされません。
次のステップ
モデルをデプロイする方法と場所についてさらに詳しく学習する。
自動機械学習を使用して回帰モデルをトレーニングする方法についてさらに詳しく学習する。