Note
Azure AI 検索は、Azure ポータル、REST API、およびAzure SDKから使用できます。 また、Foundry IQ は、エンタープライズ コンテンツを、Microsoft Foundry ポータルのエージェントの再利用可能なアクセス許可に対応したナレッジ ベースに変換するマネージド ナレッジ レイヤーです。
Azure AI 検索 では、検索インデックスにデータをインポートするための 2 つの基本的な方法がサポートされています。プログラムによってデータをインデックスにプッシュするか、サポートされているデータ ソースにインデクサーをポイントしてデータをプルします。
このチュートリアルでは、プッシュ モデルを使用して効率的にデータのインデックスを作成する方法について説明します。その際、要求はバッチで処理し、エクスポネンシャル バックオフの再試行戦略を使用しています。 サンプル アプリケーションをダウンロードして実行できます。 このチュートリアルでは、アプリケーションの主な特徴と、データのインデックスを作成する際に考慮すべき事柄についても説明します。
このチュートリアルでは、C# と Azure.Search.Documents ライブラリを Azure SDK for .NET から使用して、次の操作を行います。
- インデックスを作成する
- さまざまなバッチ サイズをテストして最も効率的なサイズを特定する
- バッチに非同期でインデックスを付ける
- 複数のスレッドを使用してインデックスの作成速度を高める
- エクスポネンシャル バックオフの再試行戦略を使用して、失敗したドキュメントを再試行する
前提条件
- アクティブなサブスクリプションを持つ Azure アカウント。 無料でアカウントを作成できます。
- Visual Studio。
ファイルのダウンロード
このチュートリアルのソース コードは、Azure-Samples/azure-search-dotnet-scale GitHub リポジトリの optimize-data-indexing/v11 フォルダーにあります。
重要な考慮事項
次の要因は、インデックス作成の速度に影響します。 詳細については、「大きなデータ・セットのインデックス作成」を参照してください。
- 価格レベルとパーティション/レプリカの数: パーティションの追加またはレベルのアップグレードにより、インデックス作成の速度が向上します。
- インデックス スキーマの複雑さ: フィールドとフィールド プロパティを追加すると、インデックス作成が遅くなります。 インデックスが小さいほど、インデックス作成は速くなります。
- バッチ サイズ: 最適なバッチ サイズは、インデックス スキーマとデータセットによって異なります。
- スレッドまたはワーカーの数: シングル スレッドでは、インデックス作成の速さが十分に活用されません。
- 再試行戦略: 最適なインデックス作成のためには、エクスポネンシャル バックオフ再試行戦略がベスト プラクティスです。
- ネットワークのデータ転送速度: データ転送速度が制限要因になる場合があります。 データのインデックス作成を Azure 環境内から行えば、データの転送速度が上がります。
Search Service の作成
このチュートリアルには Azure AI 検索 サービスが必要です。このサービスは、Azure portal で作成することができます。 現在のサブスクリプションの既存のサービスを見つけることもできます。 インデックス作成の速度を正確にテストして最適化するには、運用環境で使用する予定と同じ価格レベルを使用することをお勧めします。
Azure AI 検索のための管理者キーと URL を取得する
このチュートリアルでは、キーベースの認証を使います。 管理者 API キーをコピーして、 appsettings.json ファイルに貼り付けます。
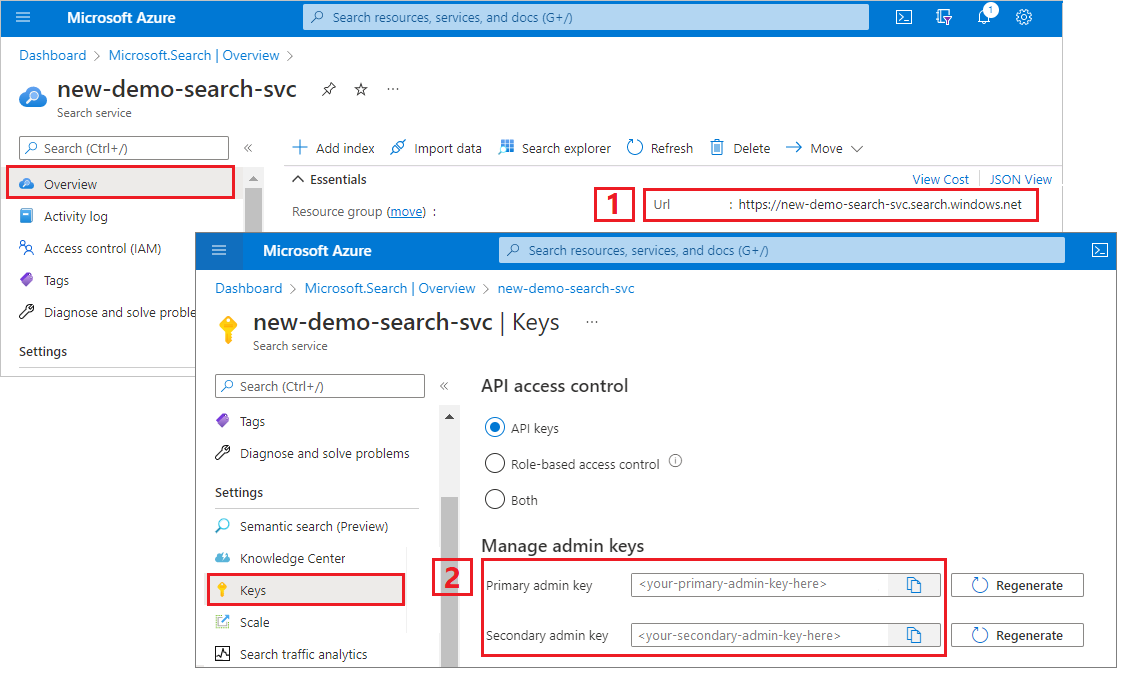
Azure portal で、Search サービスに移動します。
左側のウィンドウで [ 概要 ] を選択し、エンドポイントをコピーします。 次の形式にする必要があります。
https://my-service.search.windows.net左側のウィンドウで [設定]>[キー ]を選択し、サービスに対する完全な権限の管理キーをコピーします。 管理キーをロールオーバーする必要がある場合に備えて、2 つの交換可能な管理キーがビジネス継続性のために提供されています。 要求でいずれかのキーを使用して、オブジェクトの追加、変更、または削除を行うことができます。
環境を設定する
Visual Studio で
OptimizeDataIndexing.slnファイルを開きます。ソリューション エクスプローラーで、前の手順で収集した接続情報を使用して
appsettings.jsonファイルを編集します。{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
コードを調べる
appsettings.jsonを更新した後、OptimizeDataIndexing.slnのサンプル プログラムをビルドして実行する準備が整う必要があります。
このコードは、「 クイック スタート: フルテキスト検索」の C# セクションから派生しています。これは、.NET SDK の操作の基本に関する詳細情報を提供します。
この単純な C# または .NET コンソール アプリは次のタスクを実行します。
- C# の
Hotelクラスのデータ構造に基づいて、新しいインデックスを作成します (Addressクラスも参照します) - さまざまなバッチ サイズをテストして最も効率的なサイズを特定する
- データのインデックスを非同期的に作成する
- 複数のスレッドを使用してインデックスの作成速度を高める
- エクスポネンシャル バックオフの再試行戦略を使用して、失敗した項目を再試行する
プログラムを実行する前に、このサンプルのコードとインデックス定義を調べます。 関連するコードはいくつかのファイルにあります。
-
Hotel.csとAddress.csはインデックスを定義するスキーマを含んでいます -
DataGenerator.csには、大量のホテル データを簡単に作成するための単純なクラスが含まれています -
ExponentialBackoff.csには、この記事の説明に従ってインデックス作成プロセスを最適化するコードが含まれています -
Program.csには、Azure AI 検索 インデックスの作成と削除、データのバッチのインデックス作成、さまざまなバッチ サイズのテストを行う関数が含まれています
インデックスの作成
このサンプル プログラムでは、Azure SDK for .NET を使用して、Azure AI 検索 のインデックスを定義して作成します。
FieldBuilder クラスを利用して、C# データ モデル クラスからインデックス構造を生成します。
データ モデルは Hotel クラスによって定義されており、それには Address クラスへの参照も含まれます。
FieldBuilder は、複数のクラス定義をドリルダウンして、このインデックスの複雑なデータ構造を生成します。 メタデータ タグは、検索や並べ替えが可能かどうかなど、各フィールドの属性を定義するために使用されます。
Hotel.cs ファイルの次のスニペットでは、1 つのフィールドと別のデータ モデル クラスへの参照を指定します。
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
Program.cs ファイルでは、FieldBuilder.Build(typeof(Hotel)) メソッドによって生成された名前とフィールド コレクションを使用してインデックスが定義され、次のように作成されます。
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
データの生成
テスト用のデータを生成するために、 DataGenerator.cs ファイルに単純なクラスが実装されています。 インデックス作成用に一意の ID を持った大量のドキュメントを簡単に作成できるようにすることが、このクラスの目的です。
たとえば、一意の ID を持った 100,000 件のホテルのリストを取得する場合、次のコードを実行します。
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
このサンプルのテスト用に用意されたホテルには、small と large の 2 つのサイズがあります。
インデックスのスキーマは、インデックス作成の速度に影響します。 このチュートリアルを完了したら、このクラスを変換して、目的のインデックス スキーマに最も一致するデータを生成することを検討してください。
バッチ サイズをテストする
1 つまたは複数のドキュメントをインデックスに読み込むために、Azure AI 検索 で次の API がサポートされています。
ドキュメントのインデックスをバッチで作成すると、インデックス作成のパフォーマンスが大幅に向上します。 バッチの最大サイズは、1,000 ドキュメントまたは約 16 MB です。
実際のデータに最適なバッチ サイズを見極めることが、インデックスの作成速度を最適化するうえで重要な要素となります。 最適なバッチ サイズは主に、次の 2 つの要因によって左右されます。
- インデックスのスキーマ
- データのサイズ
最適なバッチ サイズはインデックスとデータによって異なるため、さまざまなバッチ サイズをテストしながら、実際のシナリオにおいてインデックスの作成速度が最速となるサイズを見極めるのが最善のアプローチとなります。
次の関数は、バッチ サイズをテストするための単純なアプローチを示したものです。
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
このサンプルではすべてのドキュメントが同じサイズですが、実際にはそうとは限らないため、検索サービスに送信するデータのサイズを見積もります。 これは、最初にオブジェクトを JSON に変換してからバイト単位のサイズを調べる、次のような関数を使って行うことができます。 この手法によって、インデックスの作成速度 (MB/秒) の観点から最も効率のよいバッチ サイズを特定することができます。
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
この関数には、SearchClient に加え、バッチ サイズごとのテストの試行回数を指定する必要があります。 各バッチのインデックス作成時間にはばらつきがあることが考えられるので、統計的に有意な結果を得るため、既定で各バッチを 3 回試みます。
await TestBatchSizesAsync(searchClient, numTries: 3);
この関数を実行すると、次の例に似た出力がコンソールに表示されます。
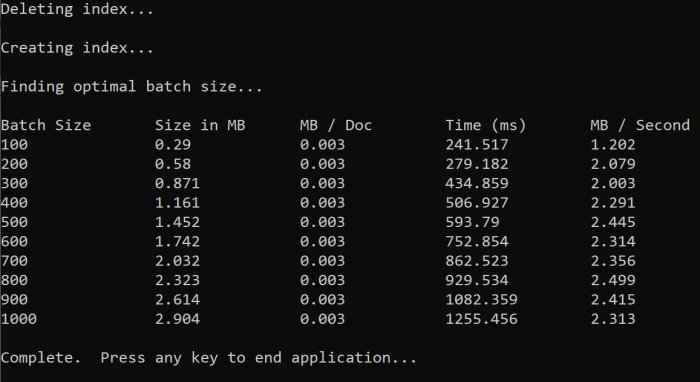
どのバッチ サイズが最も効率的であるかを見極めて、そのバッチ サイズをこのチュートリアルの次の手順で使用します。 バッチ サイズが異なっていても、1 秒あたりのバイト数 (MB) が頭打ちになっていることがわかります。
データのインデックスを作成する
使用するバッチ サイズがわかったので、次のステップではデータのインデックス作成を始めます。 データのインデックスを効率よく作成するために、このサンプルでは、次のことを行っています。
- 複数のスレッド (ワーカー) を使用する
- エクスポネンシャル バックオフの再試行戦略を実装する
41 行目から 49 行目までをコメント解除し、プログラムをもう一度実行します。 この実行では、パラメーターを変更せずにコードを実行した場合、サンプルにより、最大 100,000 個のドキュメントのバッチが生成され、送信されます。
複数のスレッド (ワーカー) を使用する
Azure AI 検索 のインデックス作成速度を生かすには、おそらく複数のスレッドを使用して、インデックス作成要求のバッチをサービスに対して同時に送信します。
重要な考慮事項のいくつかは、最適なスレッド数に影響する可能性があります。 さまざまなスレッド数でこのサンプルを変更、テストすることによって、実際のシナリオに最適なスレッド数を見極めてください。 ただし、複数のスレッドを同時に実行すれば、効率向上の利点はおおよそ活かすことができるはずです。
検索サービスに対する要求を増やしていくと、要求が完全には成功しなかったことを示す HTTP 状態コードが返されることがあります。 インデックスの作成時によく発生する HTTP 状態コードは次の 2 つです。
- 503 Service Unavailable: このエラーは、システムに大きな負荷がかかっており、この時点では要求を処理できないことを意味します。
- 207 Multi-Status: このエラーは、一部のドキュメントは成功しましたが、少なくとも 1 つは失敗したことを意味します。
エクスポネンシャル バックオフの再試行戦略を実装する
障害が発生した場合は、指数バックオフ再試行戦略を使用して要求を再試行する必要があります。
503 などで失敗した要求は、Azure AI 検索 の .NET SDK によって自動的に再試行されますが、207 には、独自の再試行ロジックを実装することをお勧めします。 Polly などのオープンソース ツールは、再試行戦略で役立ちます。
このサンプルでは、エクスポネンシャル バックオフの再試行戦略を独自に実装します。 まず、失敗した要求の maxRetryAttempts と delay (初期延期期間) を含め、いくつかの変数を定義します。
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
インデックス作成捜査の結果は変数 IndexDocumentResult result に格納されます。 この変数を使用すると、次の例に示すように、バッチ内のドキュメントが失敗したかどうかを確認できます。 部分的に失敗している場合、失敗したドキュメントの ID に基づいて新しいバッチが作成されます。
RequestFailedException 例外は、要求が完全に失敗し、再試行されたことを示しているため、キャッチする必要もあります。
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
ここからは、エクスポネンシャル バックオフのコードを呼び出しやすいように、関数にラップしています。
さらに、アクティブなスレッドを管理するための関数も別途作成します。 その関数は、簡潔にするためにここでは省略していますが、ExponentialBackoff.cs でご覧いただけます。 次のコマンドを使用して関数を呼び出すことができます。hotels はアップロードするデータ、1000 はバッチ サイズ、8 は同時実行スレッドの数です。
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
この関数を実行すると、次の例に似た出力が表示されます。
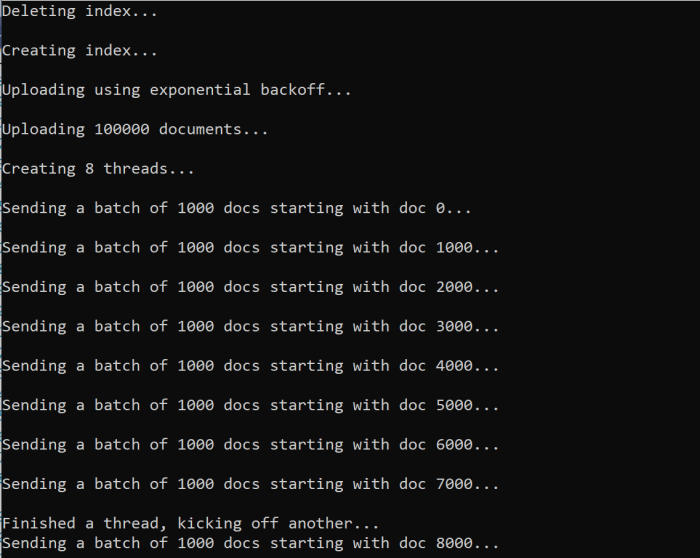
ドキュメントのバッチが失敗すると、エラーとバッチが再試行されていることを示すエラーが出力されます。
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
関数の実行が完了したら、すべてのドキュメントがインデックスに追加されたことを確認できます。
インデックスを調べる
プログラムの実行が完了したら、プログラムによって、または Azure portal の Search エクスプローラーを使用して、入力された検索インデックスを探索できます。
プログラムを使用する
インデックス内のドキュメント数は、主に 2 つの方法で確認できます。Count Documents API を使用する方法と Get Index Statistics API を使用する方法です。 どちらのパスも処理に時間がかかるため、最初に返されるドキュメント数が予想より少なくても心配する必要はありません。
ドキュメントのカウント
Count Documents 操作は、検索インデックス内のドキュメントの数を取得します。
long indexDocCount = await searchClient.GetDocumentCountAsync();
インデックス統計の取得
Get Index Statistics 操作は、現在のインデックスに対するドキュメントの数と記憶域の使用状況を返します。 インデックスの統計は、ドキュメント数よりも更新に時間がかかります。
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure portal
Azure portal の左側のウィンドウのインデックスの一覧で、最適化インデックス作成インデックスを見つけます。

[ドキュメント数] と [ストレージ サイズ] は、Get Index Statistics API から得られるため、更新に数分かかる場合があります。
リセットして再実行する
開発の初期の実験的な段階では、設計反復のための最も実用的なアプローチは、Azure AI 検索 からオブジェクトを削除してリビルドできるようにすることです。 リソース名は一意です。 オブジェクトを削除すると、同じ名前を使用して再作成することができます。
このチュートリアルのサンプル コードでは、コードを再実行できるよう、既存のインデックスをチェックしてそれらを削除しています。
インデックスは、Azure portal を使用して削除することもできます。
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
Azure portal で、左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
次のステップ
大量のデータのインデックス作成の詳細については、次のチュートリアルを試してください。