この記事では、検索拡張生成を使用して、LLM がトレーニングを必要とせずにデータ ソースを知識として扱うことを可能にする方法について説明します。
LLM には、トレーニングを介した広範なナレッジ ベースがあります。 ほとんどのシナリオでは、要件に合わせて設計された LLM を選択できますが、これらの LLM では依然として、特定のデータを理解するために追加のトレーニングが必要です。 検索拡張生成を使用すると、最初にデータに関するトレーニングを行わずに LLM でデータを使用できるようになります。
RAG のしくみ
検索拡張生成を実行するには、データに関する一般的な質問と共に、データの埋め込みを作成します。 これは、その場で行うことができます。または、ベクトル データベース ソリューションを使用して埋め込みを作成して保存することもできます。
ユーザーが質問をすると、LLM は、埋め込みを使用してユーザーの質問をデータと比較し、最も関連性の高いコンテキストを見つけます。 その後、このコンテキストとユーザーの質問はプロンプトで LLM に移動し、LLM はデータに基づいて応答を提供します。
基本的な RAG プロセス
RAG を実行するには、検索に使用する各データ ソースを処理する必要があります。 基本的なプロセスは次のとおりです。
- 大きなデータを管理可能なチャンクにします。
- チャンクを検索可能な形式に変換します。
- 変換したデータを、効率的なアクセスが可能な場所に保存します。 さらに、LLM が応答を提供する場合は、引用や参照に関連するメタデータを格納することが重要です。
- 変換したデータをプロンプトで LLM にフィードします。
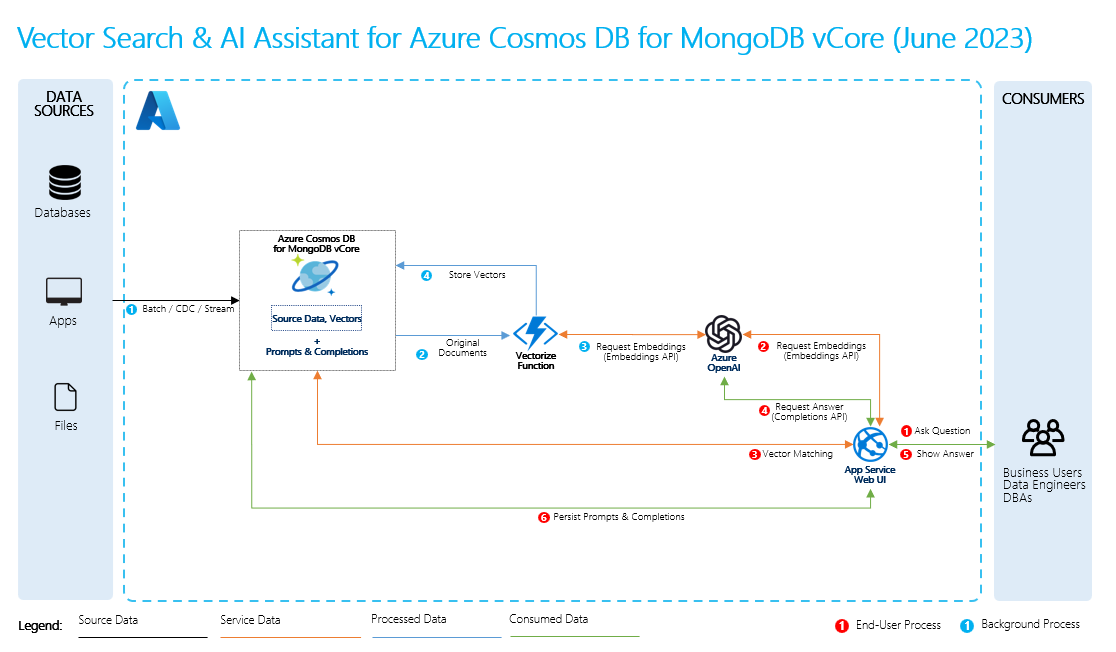
- ソース データ: データが存在する場所です。 これは、マシン上のファイル/フォルダー、クラウド ストレージ内のファイル、Azure Machine Learning データ資産、Git リポジトリ、または SQL データベースのいずれかです。
- データのチャンキング: ソース内のデータをプレーンテキストに変換する必要があります。 たとえば、単語文書や PDF を開いてテキストに変換する必要があります。 その後、テキストはより小さな部分にチャンクされます。
- テキストのベクトルへの変換: これは埋め込みです。 ベクトルは、数値シーケンスに変換された概念の数値表現であるため、コンピューターはそれらの概念間の関係を簡単に理解できます。
- ソース データと埋め込み間のリンク: この情報は、作成したチャンクにメタデータとして保存されます。これは、応答の生成中に LLM が引用を生成するのに役立ちます。
こちらも参照ください
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET