この記事では、Azure SQL データベースを参照として使用して、SQL Database ソースで Copy アクティビティを最適化するのに役立つ手法について説明します。 データ転送速度、コスト、監視、開発の容易さ、最適な成果を得るためのこれらのさまざまな考慮事項のバランスなど、最適化のさまざまな側面について説明します。
Copy アクティビティのオプション
注意
この記事に含まれるメトリックは、さまざまな機能間で動作を比較および対比するテスト ケースの結果であり、正式なエンジニアリング ベンチマークではありません。 すべてのテスト ケースは、米国東部 2 から米国西部 2 リージョンにデータを移動しています。
データ パイプライン Copy アクティビティから開始する場合は、開発を始める前に、ソース システムと移行先システムを理解しておくことが重要です。 最適化する対象を提示し、ソース、宛先、およびデータ パイプラインを監視して、最適なリソース使用率、パフォーマンス、消費を実現する方法を理解する必要があります。
Azure SQL データベースからソーシングする場合は、次の点を理解することが重要です:
- 1 秒あたりの入出力操作 (IOPS)
- データ量
- 1 つ以上のテーブルの DDL
- パーティション分割スキーマ
- 主キーまたはデータ (スキュー) の分布が適切なその他の列
- 割り当てられた制限や関連する制約、例えば同時接続数を計算する
同じことが目的地にも当てはまります。 両方を理解することで、優先順位に合わせて最適化しながら、ソースと宛先の両方の境界と制限内で動作するようにデータ パイプラインを設計できます。
注意
ソースと宛先の間のネットワーク帯域幅と、それぞれの 1 秒あたりの入出力 (IOPS) の両方がスループットのボトルネックになる可能性があり、これらの境界を理解することをお勧めします。 ただし、ネットワークはこの記事の範囲外です。
ソースと宛先の両方を理解したら、Copy アクティビティのさまざまなオプションを使用して、優先順位のパフォーマンスを向上させることができます。 これらのオプションには、次のものがあります:
- ソースパーティション分割オプション - なし、物理パーティション、ダイナミック レンジ
- ソース分離レベル - なし、読み込み未確定、読み込み確定、スナップショット
- インテリジェント スループットの最適化設定 - 自動、標準、バランス調整済み、最大
- コピーの並列処理度の設定 - 自動、指定された値
- 論理パーティション分割 - 複数の同時実行の Copy アクティビティを生成するパイプライン設計
ソースの詳細: Azure SQL データベース
具体的な例を示すために、Azure SQL データベースから Fabric Lakehouse (テーブル) テーブルと Fabric Warehouse テーブルの両方にデータを移動する複数のシナリオをテストしました。 これらの例では、4 個のソース テーブルをテストしました。 すべて同じスキーマとレコード数を持ちます。 1 つ目はヒープを、2 つ目はクラスター化インデックスを使用し、3 つ目と 4 つ目はそれぞれ 8 個と 85 個のパーティションを使用します。 この例では、Microsoft Fabric (米国西部 2) で試用版容量 (F64) を使用しました。
- サービスレベル: 汎用
- コンピューティング レベル: サーバーレス
- ハードウェア設定: Standard シリーズ (Gen5)
- 最大仮想コア数: 80
- 最小仮想コア数: 20
- レコード カウント: 1,500,000,000
- リージョン: 米国東部 2
既定の評価
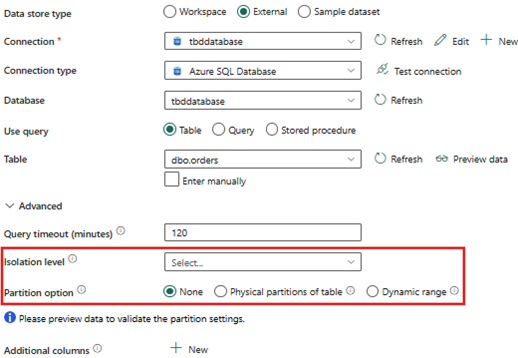
ソース [パーティション オプション] を設定する前に、Copy アクティビティの既定の動作を理解しておくことが重要です。
デフォルトの設定は次のとおりです。
ソース
- パーティション オプション - なし
- 分離レベル - なし
詳細設定
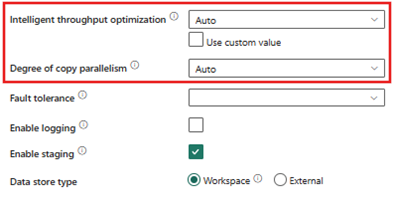
- インテリジェントなスループットの最適化 - 自動
- コピーの並列処理度 - 自動


将来の比較のために最初のベンチマークを設定するために、Copy アクティビティの実行に既定の設定を使用しました。この設定では、各宛先に 15 億件のレコードが読み込まれ、Copy アクティビティごとに 2 時間以上かかりました。
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Warehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Lakehouse | なし | 自動 | 1 | 02:10:37 |
この記事では、合計時間について重点的に説明します。 合計時間には、キュー、コピー前スクリプト、転送時間などの他のステージが含まれます。 これらのステージの詳細については、「Copy アクティビティ実行の詳細」を参照してください。 ソースとしての Azure SQL データベースの Copy アクティビティプロパティの広範な概要については、Copy アクティビティの「Azure SQL データベースのソース プロパティ」を参照してください。
設定
インテリジェントなスループットの最適化 (ITO)
ITO は、アクティビティが使用できる CPU、メモリ、およびネットワーク リソースの割り当ての最大量を決定します。 ITO を [最大] (または 256) に設定すると、最も最適化されたスループットを提供する最大値がサービスによって選択されます。 この記事では、すべてのテスト ケースで ITO が [最大] に設定されていますが、サービスでは必要なもののみが使用され、実際の値は 256 未満です。
ITO の詳細については、「インテリジェント スループットの最適化」を参照してください。
注意
Copy アクティビティ シンクが Fabric Warehouse の場合はステージングが必要です。 [コピーの並列処理度] や [インテリジェント スループットの最適化] などのオプションは、ソースからステージングへのその場合にのみ適用されます。 Lakehouse のテストケースでは、ステージングが有効化されていませんでした。
パーティション オプション
ソースが Azure SQL データベースのようなリレーショナル データベースの場合は、[詳細] セクションで [パーティション オプション]を指定できます。 既定では、この設定は [None] に設定され、[テーブルの物理パーティション] と [ダイナミック レンジ] の他の 2 種のオプションがあります。
動的範囲
ヒープ テーブル
ダイナミック レンジを使用すると、サービスはソースに対するクエリをインテリジェントに生成できます。 生成されるクエリの数は、実行時に選択されたサービスの 使用済み並列コピー の数と同じです。 ダイナミック レンジ パーティション オプションの使用を最適化するときは、コピーの並列処理度 と 使用済み並列コピー を考慮することが重要です。
パーティションの境界
パーティションの上限と下限は、パーティションのストライドを指定できるオプション フィールドです。 これらのテスト ケースでは、上限と下限の両方を事前に定義しました。 これらのフィールドが指定されていない場合、ソースに対してクエリを実行して範囲を特定する場合に、システムに追加のオーバーヘッドが発生します。 最適なパフォーマンスを得るために、特に 1 回限りの履歴読み込みの場合は、事前に境界を取得してください。
詳細については、Azure SQL データベース コネクタに関する記事の「SQL Database からの並列コピー」セクションのテーブルを参照してください。
次の SQL クエリは、範囲の最小値と最大値を決定します:

次に、これらの詳細を ダイナミック レンジ 構成で指定します。
![列、上限、下限が指定された [ダイナミック レンジ パーティション] オプションの選択を示すスクリーンショット。](media/copy-performance-sql-databases/dynamic-range.png#lightbox)
ダイナミック レンジ を使用して Copy アクティビティによって生成されるクエリの例を次に示します:
SELECT * FROM [dbo].[orders] WHERE [o_orderkey] > '4617187501' AND [o_orderkey] <= '4640625001'
コピー並列処理の次数
既定では、コピーの並列処理度 に 自動 が割り当てられます。 ただし、自動 では最適な並列コピー数が得られない場合があります。 並列コピー は、ソース データベースで確立されたセッションの数に関連付けられます。 生成される並列コピーが多すぎると、ソース データベースの CPU が過剰に割り当てられるリスクがあり、クエリが中断状態になります。
自動 を使用した ダイナミック レンジ の元のテスト ケースでは、サービスは実際には実行時に 251 個の並列コピーを生成しました。 コピーの並列処理度 に値を指定することで、並列コピーの最大数を設定します。 この設定を使用すると、ソースに対して同時実行のセッションの数を制限して、リソース管理をより適切に制御できます。 このようなテスト ケースでは、値として 50 を指定することで、合計時間とソース リソース使用率の両方が向上しました。
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計時間 |
|---|---|---|---|---|
| Fabric Warehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Warehouse | 動的範囲 | 50 | 50 | 00:13:05 |
ダイナミックレンジを持つ並列コピー度は、パフォーマンスを大幅に向上させることができます。 ただし、この設定を使用するには、境界を事前に定義するか、サービスが実行時に値を決定できるようにする必要があります。 サービスが実行時に値を決定できるようにすると、ソース テーブルの DDL とデータ ボリュームに応じて、合計時間に影響を与える可能性があります。 さらに、実行時にサービスが値を決定できるようにするには、ソースで処理できる並列コピーの数を理解する必要もあります。 値が大きすぎると、ソース システムと Copy アクティビティのパフォーマンスが低下する可能性があります。
並列コピーの詳細については、「Copy アクティビティのパフォーマンス機能: 並列コピー」を参照してください。
ダイナミックレンジを特徴とするファブリック・ウェアハウス
既定では、分離レベル は指定されず、並列処理度 は [自動] に設定されます。
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Warehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Warehouse | 動的範囲 | 自動 | 251 | 00:39:03 |
動的範囲を備えた Fabric Lakehouse (テーブル)
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Lakehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Lakehouse | 動的範囲 | 自動 | 251 | 00:36:40 |
| Fabric Lakehouse | 動的範囲 | 50 | 50 | 00:12:01 |
クラスター化したインデックス
ヒープ テーブルと比較して、ダイナミック レンジのパーティション列に対して選択された列のクラスター化キー インデックスを持つテーブルでは、パフォーマンスとリソース使用率が大幅に向上しました。 これは、コピーの並列処理度が [自動] に設定されている場合でも当てはまります。
クラスター化インデックスを備えた Fabric Warehouse
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Warehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Warehouse | 動的範囲 | 自動 | 251 | 00:09:02 |
| Fabric Warehouse | 動的範囲 | 50 | 50 | 00:08:38 |
クラスター化インデックスを備えた Fabric Lakehouse (テーブル)
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Lakehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Lakehouse | 動的範囲 | 自動 | 251 | 00:06:44 |
| Fabric Lakehouse | 動的範囲 | 50 | 50 | 00:06:34 |
論理パーティション設計
論理パーティションの設計パターンはより高度であり、開発者の労力が必要です。 ただし、この設計は、厳密なデータ読み込み要件があるシナリオで使用されます。 この設計は当初、1.5 時間以内に 180 GB のデータを読み込むオンプレミスの Oracle データベースのニーズを満たすために開発されました。 Copy アクティビティの既定値を使用した元のデザインには、65 時間以上かかりました。 論理パーティション分割設計を使用すると、同じデータが 1.5 時間以内に転送されます。
この設計は、このブログ シリーズでも使用されました: データ パイプラインのパフォーマンス向上パート 1: 時間間隔を秒に変換する方法)。 この設計は、大規模なソース テーブルを読み込み、ソース データの読み取りをパーティション分割するデータ範囲の設定などの手法を使用して最適な読み込みパフォーマンスが必要な場合に、環境内でエミュレートするのに適しています。 この設計では、多くのサブ日付範囲が生成されます。 次に、For-Each アクティビティを使用して範囲を反復処理すると、指定した範囲間のソース データに対して多くの Copy アクティビティが呼び出されます。 For-Each アクティビティ内では、すべての Copy アクティビティが並列で実行され (最大 50 個のバッチカウントまで)、コピー並列処理の次数が [自動] に設定されます。
下記の例では、パーティション分割された日付の値を次の値に設定しました:
- 開始値: 1992 年 1 月 1 日
- 終了値: 1992 年 8 月 2 日
- バケット間隔日数: 50
並列コピーと合計時間は、作成されたすべての 50 個の Copy アクティビティで観察された最大値です。 全 50 個が並列に実行されたので、[合計時間] の最大値は、すべての Copy アクティビティが並列で完了するまでにかかった時間です。
論理パーティション設計を備えたファブリック ウェアハウス
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Warehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Warehouse | 論理設計 | 自動 | 1 | 00:12:11 |
論理パーティション設計を備えた Fabric Lakehouse (テーブル)
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Lakehouse | なし | 自動 | 1 | 02:10:37 |
| Fabric Lakehouse | 論理設計 | 自動 | 1 | 00:09:14 |
テーブルの物理パーティション
注意
物理パーティションを使用する場合、パーティション列とメカニズムは、物理テーブル定義に基づいて自動的に決定されます。
テーブルの物理パーティションを使用するには、ソース テーブルをパーティション分割する必要があります。 パーティションの数がパフォーマンスに与える影響を理解するために、2 種のパーティション テーブルを作成しました。一方は 8 個のパーティションを持ち、他方はパーティションが 85 個です。
物理パーティションの数によって、コピーの並列処理度 が制限されます。 パーティションの数より小さい値を指定することで、引き続き数を制限できます。
物理パーティションを備えた Fabric Warehouse
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Warehouse | なし | 自動 | 1 | 02:23:21 |
| Fabric Warehouse | 物理 | 自動 | 8 | 00:26:29 |
| Fabric Warehouse | 物理 | 自動 | 85 | 00:08:31 |
物理パーティションを備えたファブリック・レイクハウス(テーブル)
| ディスティネーション | パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 |
|---|---|---|---|---|
| Fabric Lakehouse | なし | 自動 | 1 | 02:10:37 |
| Fabric Lakehouse | 物理 | 自動 | 8 | 00:36:36 |
| Fabric Lakehouse | 物理 | 自動 | 85 | 00:12:21 |
分離レベル
さまざまな 分離レベル 設定を指定してパフォーマンスに与える影響を比較してみましょう。 コピーの並列処理度 を [Auto] に設定して [分離レベル] を選択すると、Copy アクティビティはソース システムを過剰に構成し、失敗するリスクがあります。 コピーの並列処理度 を [自動] に設定したままにする場合は、分離レベル を [なし] のままにすることをお勧めします。
注意
Azure SQL データベースを既定で *[分離レベル] に設定するRead_Committed_Snapshot。
コピーの並列処理度 を [50] に設定して、ダイナミック レンジ のテスト ケースを拡張し、分離レベル がパフォーマンスに与える影響を確認してみましょう。
| 分離レベル | 合計期間 | 容量ユニット | DB の最大 CPU % | DB の最大セッション |
|---|---|---|---|---|
| なし (デフォルト) | 00:14:23 | 93,960 | 70 | 76 |
| コミットされていないものを読み取り | 00:13:46 | 89,280 | 81 | 76 |
| コミットされたものを読み取り | 00:25:34 | 97,560 | 81 | 76 |
データベース ソース クエリに対して選択する 分離レベル は、最適化パスではなく、より多くの要件になりますが、各オプションのパフォーマンスと容量ユニットの消費量の違いを理解することが重要です。
分離レベルの詳細については、**「分離レベル 列挙型」を参照してください。
ITO と容量の消費
並列コピー度 と同様に、インテリジェント スループット最適化 (ITO) も設定できる最大値です。 コストを最適化する場合、ITO は、目的の結果を満たすように調整することを検討するのに最適な設定です。
ITO の範囲:
| ITO | 最大値 |
|---|---|
| 自動 | 指定なし |
| 標準 | 64 |
| バランスが取れている | 128 |
| 最大値 | 256 |
ドロップダウンでは上記の設定が可能ですが、4 から 256 までのカスタム値を使用することもできます。
注意
実際に使用される ITO の数は、usedDataIntegrationUnits フィールドCopy アクティビティ出力にあります。
並列コピー度 が [自動] に設定された ダイナミック レンジ ヒープ テスト ケースでは、サービスは実際の値が 100 の [バランス調整済み] を選択しました。 カスタム値を 50 に指定して、ITO が半分にカットされた場合に何が起こるかを見てみましょう:
| ITO の指定 | 合計期間 | 容量ユニット | DB の最大 CPU % | DB の最大セッション | 最適化された処理能力を用いる |
|---|---|---|---|---|---|
| 最大 256 | 00:13:46 | 89,280 | 81 | 76 | バランス調整済み (100) |
| 50 | 00:18:28 | 48,600 | 76 | 61 | Standard (48) |
ITO を 50% 削減することで、合計時間は 34% 増加しました。しかし、サービスの容量ユニットの使用が 45.5% 削減されました。 合計時間 を短縮するために最適化していない場合、使用する容量ユニットを減らすには、ITO を小さい値に設定すると便利です。
まとめ
次のグラフは、Fabric Warehouse テーブルと Fabric Lakehouse テーブルの両方に読み込む動作をまとめたものです。 テーブルに物理パーティションがある場合は、[パーティション オプション] を使用します: テーブルの物理パーティション は、転送期間、容量ユニット、およびソースのコンピューティング オーバーヘッドで最もバランスの取れたアプローチになります。 この設定は、データ移動時にデータベースに対して実行されるセッションが多い場合に特に理想的です。
テーブルに物理パーティションがない場合でも、[パーティション オプション] の [ダイナミック レンジ] を使用できます。 このオプションでは、上限と下限を決定する前の手順が必要になりますが、容量消費量、ソース コンピューティング使用率、最適な 並列処理度 をテストする必要性を犠牲にして、既定のオプションと比較して転送期間が大幅に向上します。
コピー ジョブのパフォーマンスを最大化するもう 1 つの重要な要素は、単一のクラウド リージョン内でデータ移動を維持することです。 たとえば、米国西部のデータ ファクトリを使用して、米国西部のソースデータ ストアと移行先データ ストアからのデータ移動は、米国東部から米国西部にデータを移動するコピー ジョブよりも優れたパフォーマンスを発揮します。
最後に、速度が最適化の最も重要な側面である場合、ソース テーブルの DDL を最適化することは、物理パーティション オプションを使用する上で重要です。 パーティション分割されていないテーブルの場合は、ダイナミック レンジ を試してください。この設定は十分に高速ではありません。論理パーティション分割または論理パーティション分割とサブ連結内の ダイナミック レンジ のハイブリッドアプローチを検討してください。
ガイドライン
コスト インテリジェントなスループットの最適化と並列コピーの次数を調整します。 速度 パーティションテーブルの場合、適切な数のパーティションがある場合は、パーティション オプション の テーブルの物理パーティション を使用します。 そうでなければ、データが歪んでいる場合は、またはパーティションの数が限られている場合は、ダイナミック レンジ の使用を検討してください。 ヒープとインデックスを持つテーブルの場合は、ソースに対する中断されたクエリの数を制限する 並列コピー度 で ダイナミック レンジ を使用します。 パーティションの上限/下限を事前に定義できれば、パフォーマンスをさらに向上させることができます。
保全性と開発者の努力を検討してください。 既定のオプションのままにすると、データの移動に最も時間がかかりますが、特にソース テーブルの DDL が不明な場合は、既定値で実行することが最適なオプションである可能性があります。 これにより、適切な容量ユニットの使用量も提供されます。
テスト事例
Fabric Warehouse のテスト ケース
| パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 | 容量ユニット | 最大 CPU % | 最大セッション数: |
|---|---|---|---|---|---|---|
| なし | 自動 | 1 | 02:23:21 | 51,839 | < 1 | 2 |
| 物理 (8) | 自動 | 8 | 00:26:29 | 49,320 | 3 | 10 |
| 物理 (85) | 自動 | 85 | 00:08:31 | 108,000 | 15 | 83 |
| 動的範囲 (ヒープ) | 自動 | 242 | 00:39:03 | 282,600 | 100 | 272 |
| 動的範囲 (ヒープ) | 50 | 50 | 00:13:05 | 92,159 | 81 | 76 |
| ダイナミック レンジ (クラスター化インデックス) | 自動 | 251 | 00:09:02 | 64,080 | 9 | 277 |
| ダイナミック レンジ (クラスター化インデックス) | 50 | 50 | 00:08:38 | 55,440 | 10 | 77 |
| 論理設計 | 自動 | 1 | 00:12:11 | 226,108 | 91 | 50 |
Fabric Lakehouse (テーブル) のテスト ケース
| パーティション オプション | コピー並列処理の次数 | 使用済み並列コピー | 合計期間 | 容量ユニット | 最大 CPU % | 最大セッション数: |
|---|---|---|---|---|---|---|
| なし | 自動 | 1 | 02:10:37 | 47,520 | <1% | 2 |
| 物理 (8) | 自動 | 8 | 00:36:36 | 64,079 | 2 | 10 |
| 物理 (85) | 自動 | 85 | 00:12:21 | 275,759 | ||
| 動的範囲 (ヒープ) | 自動 | 251 | 00:36:12 | 280,080 | 100 | 276 |
| 動的範囲 (ヒープ) | 50 | 50 | 00:12:01 | 101,159 | 68 | 76 |
| ダイナミック レンジ (クラスター化インデックス) | 自動 | 251 | 00:06:44 | 59,760 | 11 | 276 |
| ダイナミック レンジ (クラスター化インデックス) | 50 | 50 | 00:06:34 | 54,760 | 10 | 76 |
| 論理設計 | 自動 | 1 | 00:09:14 | 164,908 | 82 | 50 |