events
3月31日 23時 - 4月2日 23時
究極の Microsoft Fabric、Power BI、SQL、AI コミュニティ主導のイベント。 2025 年 3 月 31 日から 4 月 2 日。
今すぐ登録このブラウザーはサポートされなくなりました。
Microsoft Edge にアップグレードすると、最新の機能、セキュリティ更新プログラム、およびテクニカル サポートを利用できます。
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory でのコピー アクティビティのパフォーマンスに関する問題をトラブルシューティングする方法について説明します。
コピー アクティビティを実行した後、コピー アクティビティのモニタリング ビューで、実行結果とパフォーマンスの統計情報を収集できます。 以下に例を示します。
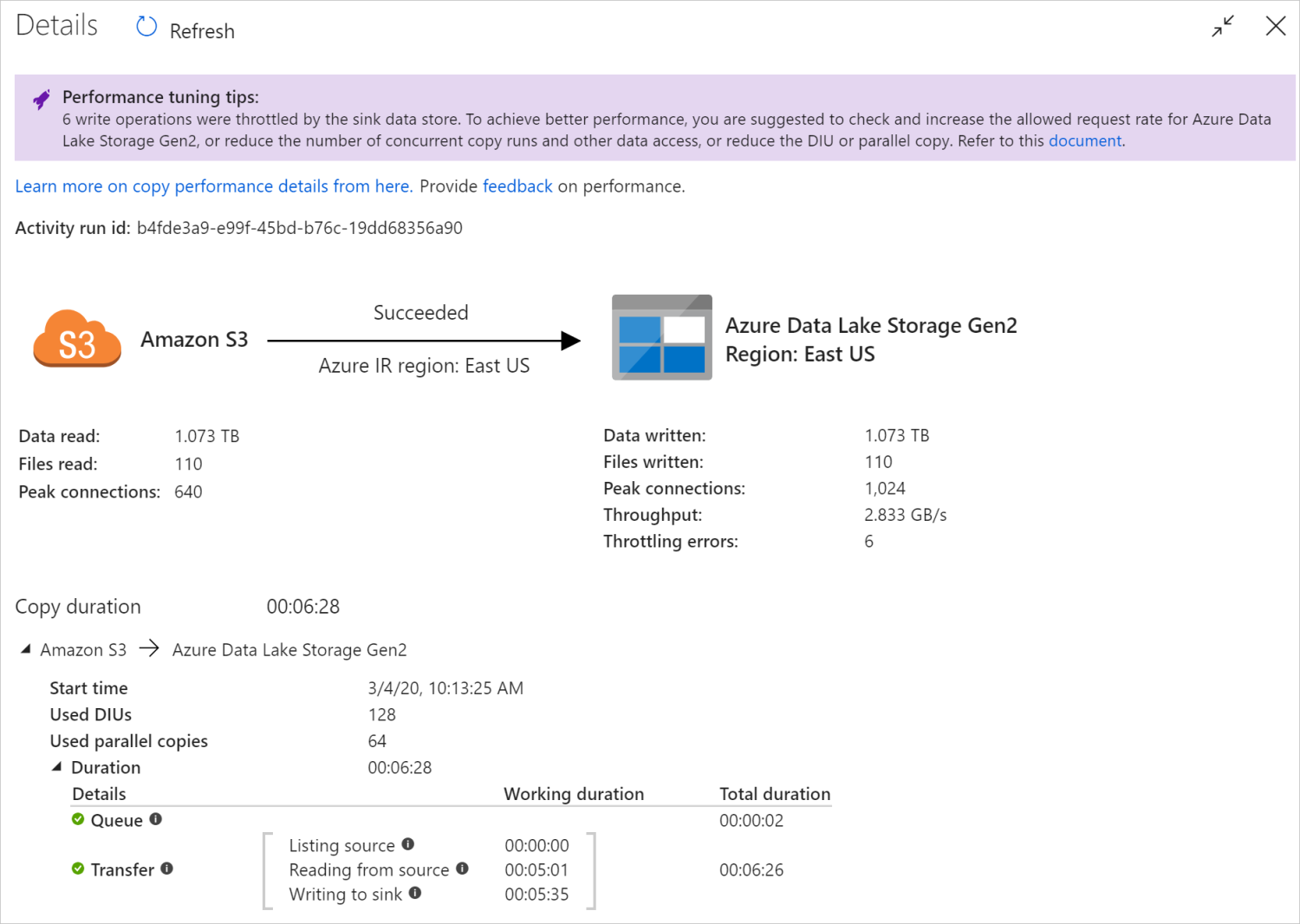
一部のシナリオでは、Copy アクティビティを実行するときに、上の例に示すように、上部に [パフォーマンスのチューニングのヒント] が表示されます。 このヒントでは、この特定のコピーの実行に対してサービスが特定したボトルネックと、コピーのスループットを向上させる方法についての提案を示しています。 推奨されている変更を行ってみてから、コピーを再度実行してください。
参考として、現在、パフォーマンス チューニングのヒントには、次のような場合の提案が示されています。
| カテゴリ | パフォーマンスのチューニングのヒント |
|---|---|
| データ ストア固有 | Azure Synapse Analytics へのデータ読み込み: 使用しない場合は、PolyBase または COPY ステートメントを使用することをお勧めします。 |
| Azure SQL Database との間でのデータのコピー: DTU の使用率が高い場合は、上位レベルへのアップグレードをお勧めします。 | |
| Azure Cosmos DB との間でのデータのコピー: RU の使用率が高い場合は、より大きな RU にアップグレードすることをお勧めします。 | |
| SAP テーブルからのデータのコピー: 大量のデータをコピーする場合は、SAP コネクタのパーティション オプションを利用して並列読み込みを有効にし、最大パーティション数を増やすことをお勧めします。 | |
| Amazon Redshiftからデータを取り込み: 使用されていない場合は、UNLOAD を使用することをお勧めします。 | |
| データ ストアの調整 | コピー中にデータ ストアによって多数の読み取り/書き込み操作が調整されている場合は、データ ストアに対して許可されている要求レートを確認して増やすか、同時実行ワークロードを減らすことをお勧めします。 |
| 統合ランタイム | セルフホステッド統合ランタイム (IR) を使用し、IR が実行可能なリソースを使用できるようになるまで、コピー アクティビティがキュー内で長時間待機している場合は、IR のスケールアウト/アップをお勧めします。 |
| 最適でないリージョンにある Azure Integration Runtime を使用して読み取り/書き込み速度が低下する場合は、別のリージョンの IR を使用するようにを構成することをお勧めします。 | |
| フォールト トレランス | フォールト トレランスを構成し、互換性のない行をスキップすると、パフォーマンスが低下します。ソースとシンクのデータに互換性があることを確認することをお勧めします。 |
| ステージング コピー | ステージング コピーが構成されていても、ソースシンク ペアには役に立たない場合は、削除することをお勧めします。 |
| Resume | コピー アクティビティが最後の障害点から再開されたが、元の実行後に DIU 設定を偶然に変更した場合は、新しい DIU 設定が有効にならないことに注意してください。 |
コピー アクティビティの監視ビューの下部にある [実行の詳細] と [期間] には、コピー アクティビティが通過するキー ステージが記述されています (この記事の冒頭にある例を参照してください)。これは、コピーのパフォーマンスのトラブルシューティングに特に役立ちます。 コピー実行のボトルネックは、実行時間が最も長いものです。 各ステージの定義について次の表を参照し、Azure IR のコピーアクティビティのトラブルシューティング と セルフホステッド IR でのコピーアクティビティのトラブルシューティング を行う方法については、この情報を参照してください。
| 段階 | 説明 |
|---|---|
| キュー | コピー アクティビティが統合ランタイムで実際に開始されるまでの経過時間。 |
| コピー前スクリプト | コピー アクティビティが IR で開始してから、コピー アクティビティによるシンク データ ストアでのコピー前スクリプトの実行が終了するまでの経過時間。 データベース シンクのコピー前スクリプトを構成するときに適用します。たとえば、データを Azure SQL Database に書き込む場合は、新しいデータをコピーする前にクリーンアップする必要があります。 |
| 転送 | 前のステップが終了してから、IR がソースからシンクにすべてのデータを転送するまでの経過時間。 転送のサブステップは並列に実行され、一部の操作 (ファイル形式の解析や生成など) は現在表示されません。 - 1 バイト目にかかる時間: ( )前の手順が終了してから、IR がソース データ ストアから最初のバイトを受信するまでの経過時間。 ファイルベース以外のソースに適用されます。 - ソースのリスト: ソース ファイルまたはデータ パーティションを列挙するために費やされた時間。 後者は、データベース ソースのパーティション オプションを構成するときに適用されます。たとえば、Oracle/SAP HANA/Teradata/Netezza などのデータベースからデータをコピーする場合です。 -ソースからの読み取り: ソース データ ストアからデータを取得するために費やされた時間。 - シンクへの書き込み: シンク データ ストアにデータを書き込むために費やされた時間。 現時点では、Azure AI Search、Azure Data Explorer、Azure Table Storage、Oracle、SQL Server、Common Data Service、Dynamics 365、Dynamics CRM、Salesforce/Salesforce Service Cloud など、一部のコネクタにはこのメトリックがないことに注意してください。 |
パフォーマンス チューニングの手順 に従って、シナリオのパフォーマンステストを計画および実施します。
コピー アクティビティのパフォーマンスが予想を満たさない場合、Azure Integration Runtime で実行されている単一のコピー アクティビティのトラブルシューティングを行うには、[コピーの監視] ビューに表示されているパフォーマンス チューニングのヒント が表示されたら、候補を適用して、もう一度お試しください。 それ以外の場合は、コピー アクティビティの実行の詳細を理解し、最長 期間を持つステージを確認し、以下のガイダンスを適用してコピーのパフォーマンスを向上させます。
"コピー前スクリプト" に長い時間がかかっています: シンク データベースで実行されているコピー前スクリプトが完了するまでに時間がかかることを意味します。 パフォーマンスを向上させるために、指定されたコピー前スクリプト ロジックを調整します。 スクリプトの改善についてさらに支援が必要な場合は、データベース チームにお問い合わせください。
"転送 - 最初のバイトまでの転送時間" に長い時間がかかっています: ソース クエリで任意のデータが返されるまでに時間がかかることを意味します。 クエリまたはサーバーを確認して最適化します。 さらに支援が必要な場合は、データ ストア チームにお問い合わせください。
"転送 - リスト ソース" の作業時間が長くなっています: これは、ソース ファイルまたはソース データベースのデータ パーティションの列挙に時間がかかることを意味します。
ファイルベースのソースからデータをコピーする場合、フォルダー パスまたはファイル名 (wildcardFolderPath または wildcardFileName) で ワイルドカード フィルター を使用するか、ファイルの最終変更時刻フィルター (modifiedDatetimeStart またはmodifiedDatetimeEnd) を使用すると、このようなフィルターにより、指定したフォルダーにあるすべてのファイルがクライアント側にリスト化されます。 このようなファイル列挙は、フィルター規則に一致するファイルのセットが少数しかない場合に、特にボトルネックになる可能性があります。
datetime パーティション分割されたファイルパスまたは名前に基づいてファイルをコピーできるかどうかを確認します。 このような方法では、ソース側のリスト化に負担がかかりません。
代わりに、データ ストアのネイティブ フィルターを使用できるかどうかを確認します。具体的には、Amazon S3/Azure Blob Storage/Azure Files では "prefix"、ADLS Gen1 では "listAfter/listBefore" です。 これらのフィルターはデータ ストアのサーバー側フィルターであり、パフォーマンスが大幅に向上します。
単一の大きなデータ セットをいくつかの小さいデータ セットに分割し、それらのコピー ジョブをデータの各部分の処理と同時に実行することを検討してください。 これは、Lookup/GetMetadata + ForEach + Copy を使用して行うことができます。 一般的な例として、「複数のコンテナーからファイルをコピーする」 または 「Amazon S3 から ADLS Gen2 ソリューションテンプレートにデータを移行する」を参照してください。
サービスがソースで調整エラーを報告するかどうか、またはデータ ストアの使用率が高い状態かどうかを確認します。 その場合は、データ ストアのワークロードを減らすか、データ ストアの管理者に連絡して調整制限または使用可能なリソースを増やしてみてください。
Azure IR をソース データ ストア領域と同じか近い場所で使用します。
"転送 - ソースからの読み取り" に長い時間がかかっています:
適用する場合は、コネクタ固有のデータ読み込みのベスト プラクティスを採用します。 たとえば、Amazon Redshiftからデータをコピーする場合は、Redshift UNLOAD を使用するように構成します。
サービスがソースで調整エラーを報告するかどうか、またはデータ ストアの使用率が高いかどうかを確認します。 その場合は、データ ストアのワークロードを減らすか、データ ストアの管理者に連絡して調整制限または使用可能なリソースを増やしてみてください。
コピー ソースとシンク パターンを確認します。
コピー パターンが 4 つを超えるデータ統合ユニット (DIU) をサポートしている場合、詳細についてはこのセクション を参照してください。通常、DIU を増やしてパフォーマンスを向上させることができます。
それ以外の場合は、単一の大きなデータ セットをいくつかの小さいデータ セットに分割し、それらのコピー ジョブをデータの各部分の処理と同時に実行することを検討してください。 これは、Lookup/GetMetadata + ForEach + Copy を使用して行うことができます。 詳細については、「複数のコンテナーからのファイルのコピー」、「Amazon S3 から ADLS Gen2 にデータを移行する」、または「一般例として管理テーブル ソリューションテンプレートを使用して一括コピーする」を参照してください。
Azure IR をソース データ ストア領域と同じか近い場所で使用します。
"転送 - シンクへの書き込み" で、長い処理時間がかかっている:
適用する場合は、コネクタ固有のデータ読み込みのベスト プラクティスを採用します。 たとえば、Azure Synapse Analytics にデータをコピーする場合は、PolyBase または COPY ステートメントを使用します。
サービスがシンクで調整エラーを報告するかどうか、またはデータ ストアの使用率が高いかどうかを確認します。 その場合は、データ ストアのワークロードを減らすか、データ ストアの管理者に連絡して調整制限または使用可能なリソースを増やしてみてください。
コピー ソースとシンク パターンを確認します。
シンク データ ストアのリージョンと同じまたは近くの Azure IR を使用します。
パフォーマンス チューニングの手順 に従って、シナリオのパフォーマンステストを計画および実施します。
コピー アクティビティのパフォーマンスが予想を満たさない場合、Azure Integration Runtime で実行されている単一のコピー アクティビティのトラブルシューティングを行うには、[コピーの監視] ビューに表示されているパフォーマンス チューニングのヒント が表示されたら、候補を適用して、もう一度お試しください。 それ以外の場合は、コピー アクティビティの実行の詳細を理解し、最長 期間を持つステージを確認し、以下のガイダンスを適用してコピーのパフォーマンスを向上させます。
"Queue" に長い時間がかかっています: セルフホステッド IR が実行するリソースを持つようになるまで、コピー アクティビティがキュー内で待機時間を待機することを意味します。 IR の容量と使用量を確認し、ワークロードに応じて スケールアップまたはスケールアウトします。
"転送 - 最初のバイトまでの転送時間" に長い時間がかかっています: ソース クエリで任意のデータが返されるまでに時間がかかることを意味します。 クエリまたはサーバーを確認して最適化します。 さらに支援が必要な場合は、データ ストア チームにお問い合わせください。
"転送 - リスト ソース" の作業時間が長くなっています: これは、ソース ファイルまたはソース データベースのデータ パーティションの列挙に時間がかかることを意味します。
セルフホスティッド IR マシンのソースデータストアへの接続の待機時間が短いかどうかを確認してください。 シンクが Azure にある場合は、このツール を使用して、セルフホステッド IR マシンから Azure リージョンへの待機時間を確認することができます。待機時間が少なければより優れています。
ファイルベースのソースからデータをコピーする場合、フォルダー パスまたはファイル名 (wildcardFolderPath または wildcardFileName) で ワイルドカード フィルター を使用するか、ファイルの最終変更時刻フィルター (modifiedDatetimeStart またはmodifiedDatetimeEnd) を使用すると、このようなフィルターにより、指定したフォルダーにあるすべてのファイルがクライアント側にリスト化されます。 このようなファイル列挙は、フィルター規則に一致するファイルのセットが少数しかない場合に、特にボトルネックになる可能性があります。
datetime パーティション分割されたファイルパスまたは名前に基づいてファイルをコピーできるかどうかを確認します。 このような方法では、ソース側のリスト化に負担がかかりません。
代わりに、データ ストアのネイティブ フィルターを使用できるかどうかを確認します。具体的には、Amazon S3/Azure Blob Storage/Azure Files では "prefix"、ADLS Gen1 では "listAfter/listBefore" です。 これらのフィルターはデータ ストアのサーバー側フィルターであり、パフォーマンスが大幅に向上します。
単一の大きなデータ セットをいくつかの小さいデータ セットに分割し、それらのコピー ジョブをデータの各部分の処理と同時に実行することを検討してください。 これは、Lookup/GetMetadata + ForEach + Copy を使用して行うことができます。 一般的な例として、「複数のコンテナーからファイルをコピーする」 または 「Amazon S3 から ADLS Gen2 ソリューションテンプレートにデータを移行する」を参照してください。
サービスがソースで調整エラーを報告するかどうか、またはデータ ストアの使用率が高い状態かどうかを確認します。 その場合は、データ ストアのワークロードを減らすか、データ ストアの管理者に連絡して調整制限または使用可能なリソースを増やしてみてください。
"転送 - ソースからの読み取り" に長い時間がかかっています:
セルフホスティッド IR マシンのソースデータストアへの接続の待機時間が短いかどうかを確認してください。 お使いのソースが Azure にある場合は、このツール を使用して、セルフホステッド IR マシンから Azure リージョンへの待機時間を確認することができます。待機時間が少なければより優れています。
データの読み取りと転送を効率的に行うために、セルフホステッド IR マシンに十分な受信帯域幅があるかどうかを確認します。 ソースデータストアが Azure にある場合は、このツール を使用してダウンロードの速度を確認できます。
Azure portal -> データ ファクトリまたは Synapse ワークスペース -> 概要ページで、セルフホステッド IR の CPU とメモリの使用量の傾向を確認します。 CPU 使用率が高い場合、または使用可能なメモリが少ない場合は、IR のスケールアップ/スケールアウト を検討してください。
適用する場合は、コネクタ固有のデータ読み込みのベスト プラクティスを採用します。 次に例を示します。
Oracle、Netezza、Teradata、SAP HANA、SAP Table、および SAP Open Hub) からデータをコピーする場合は、データ パーティション オプションを有効にすることで、データを並列にコピーできます。
HDFSからデータをコピーする場合は、DistCp を使用するように構成します。
例えば、Amazon Redshift からデータをコピーする場合は、Redshift UNLOAD を使用するように構成します。
サービスがソースで調整エラーを報告するかどうか、またはデータ ストアの使用率が高いかどうかを確認します。 その場合は、データ ストアのワークロードを減らすか、データ ストアの管理者に連絡して調整制限または使用可能なリソースを増やしてみてください。
コピー ソースとシンク パターンを確認します。
パーティションオプションが有効なデータ ストアからデータをコピーする場合は、並列コピー を段階的にチューニングすることを検討してください。並列コピーの数が多すぎると、パフォーマンスが低下する可能性があることに注意してください。
それ以外の場合は、単一の大きなデータ セットをいくつかの小さいデータ セットに分割し、それらのコピー ジョブをデータの各部分の処理と同時に実行することを検討してください。 これは、Lookup/GetMetadata + ForEach + Copy を使用して行うことができます。 詳細については、「複数のコンテナーからのファイルのコピー」、「Amazon S3 から ADLS Gen2 にデータを移行する」、または「一般例として管理テーブル ソリューションテンプレートを使用して一括コピーする」を参照してください。
"転送 - シンクへの書き込み" で、長い処理時間がかかっている:
適用する場合は、コネクタ固有のデータ読み込みのベスト プラクティスを採用します。 たとえば、Azure Synapse Analytics にデータをコピーする場合は、PolyBase または COPY ステートメントを使用します。
シンク データ ストアへの接続に、セルフホステッド IR マシンの待機時間が短いかどうかを確認してください。 シンクが Azure にある場合は、このツール を使用して、セルフホステッド IR マシンから Azure リージョンへの待機時間を確認することができます。待機時間が少なければより優れています。
セルフホステッド IR マシンに、データの転送とデータ書き込みを効率的に行うための十分な送信帯域幅があるかどうかを確認します。 シンク データ ストアが Azure にある場合は、このツール を使用してアップロード速度を確認できます。
Azure portal -> データ ファクトリまたは Synapse ワークスペース -> 概要ページで、セルフホステッド IR の CPU とメモリの使用量の傾向を確認します。 CPU 使用率が高い場合、または使用可能なメモリが少ない場合は、IR のスケールアップ/スケールアウト を検討してください。
サービスがシンクで調整エラーを報告するかどうか、またはデータ ストアの使用率が高いかどうかを確認します。 その場合は、データ ストアのワークロードを減らすか、データ ストアの管理者に連絡して調整制限または使用可能なリソースを増やしてみてください。
並列コピー を徐々に調整することを検討してください。並列コピーの数が多すぎると、パフォーマンスが低下する可能性があることに注意してください。
このセクションでは、特定のコネクタの種類または統合ランタイムに関するパフォーマンスのトラブルシューティング ガイドをいくつか紹介します。
データセットが異なる統合ランタイムに基づいている場合、アクティビティの実行時間は異なります。
現象:データセット内で [リンクされたサービス] ドロップダウンを切り替えるだけで、同じパイプライン アクティビティが実行されますが、実行時間は大幅に異なります。 データセットがマネージド仮想ネットワークの統合ランタイムに基づいている場合、既定の統合ランタイムに基づいているよりも時間がかかります。
原因:パイプライン実行の詳細を確認すると、低速のパイプラインはマネージド VNet (Virtual Network) IR で実行されている一方、通常のパイプラインは Azure IR で実行されていることがわかります。 設計上、サービス インスタンスごとに 1 つの計算ノードを予約していないため、マネージド VNet IR は Azure IR よりもキュー時間が長く、各 Copy アクティビティが開始するまでにウォームアップがあります。これは、Azure IR ではなく、主に VNet 参加で発生します。
現象:Azure SQL Database にデータをコピーすると、低速になります。
原因:問題の根本原因は、ほとんどの場合、Azure SQL Database 側のボトルネックによってトリガーされます。 以下のいくつかの原因が考えられます。
Azure SQL Database のレベルが十分ではありません。
Azure SQL Database の DTU の使用率が 100% に近づいています。 パフォーマンスを監視して、Azure SQL Database のレベルをアップグレードすることを検討できます。
インデックスが正しく設定されていません。 データが読み込まれる前にすべてのインデックスを削除し、読み込みの完了後に再作成します。
WriteBatchSize は、スキーマ行のサイズに適合するのに十分な大きさではありません。 問題のプロパティを拡大してみてください。
一括挿入ではなく、ストアド プロシージャが使用されているため、パフォーマンスが低下することが予想されます。
現象:
Excel データセットの作成、接続またはストアからのスキーマのインポート、データのプレビュー、ワークシートの一覧表示または更新を行う際、Excel ファイルのサイズが大きい場合は、タイムアウト エラーが発生することがあります。
コピー アクティビティを使用して、サイズの大きい Excel ファイル (>= 100 MB) から他のデータ ストアにデータをコピーすると、パフォーマンスが低下したり、OOM 問題が発生したりする可能性があります。
原因:
スキーマのインポート、データのプレビュー、Excel データセットでのワークシートの一覧表示などの操作では、タイムアウトは 100 秒で静的です。 大きな Excel ファイルでは、これらの操作がタイムアウト値内で完了しないことがあります。
Copy アクティビティは、Excel ファイル全体をメモリに読み込み、データを読み取る指定されたワークシートとセルを検索します。 サービスが使用する基盤となる SDK のために、このような動作になります。
解決方法:
スキーマをインポートする場合は、元のファイルのサブセットとなるより小さいサンプル ファイルを生成し、[接続/ストアからスキーマをインポートする] ではなく、[サンプル ファイルからスキーマをインポートする] を選択します。
ワークシートを一覧表示する場合は、ワークシートのドロップダウンで [編集] をクリックし、シート名/インデックスを入力します。
大きい Excel ファイル (> 100 MB) を他のストアにコピーするために、Data Flow Excel ソースを使用できます。これにより、ストリーミングの読み取りとパフォーマンスが向上します。
現象: 大きな JSON/Excel/XML ファイルを読み取ると、アクティビティの実行中にメモリ不足 (OOM) の問題が発生します。
原因:
推奨事項: 問題を解決するには、次のいずれかのオプションを適用します。
ここでは、サポートされているいくつかのデータ ストアについて、パフォーマンスの監視とチューニングに関するリファレンス情報を示します。
コピー アクティビティの他の記事を参照してください。
events
3月31日 23時 - 4月2日 23時
究極の Microsoft Fabric、Power BI、SQL、AI コミュニティ主導のイベント。 2025 年 3 月 31 日から 4 月 2 日。
今すぐ登録トレーニング
モジュール
Azure Data Factory を使用したペタバイト規模のインジェスト - Training
Azure Data Factory または Azure Synapse パイプラインを使用したペタバイト規模のインジェスト
認定資格
Microsoft Certified: Azure for SAP Workloads Specialty - Certifications
Azure リソースを活用しながら、Microsoft Azure で SAP ソリューションの計画、移行、運用を行う方法について説明します。
ドキュメント
コピー アクティビティのパフォーマンスとスケーラビリティに関するガイド - Azure Data Factory & Azure Synapse
コピー アクティビティを使用するときに、Azure Data Factory パイプラインおよび Azure Synapse Analytics パイプラインでのデータ移動のパフォーマンスに影響する主な要因について説明します。
コピー アクティビティ パフォーマンス最適化機能 - Azure Data Factory & Azure Synapse
Azure Data Factory と Azure Synapse Analytics のパイプラインでのコピー アクティビティのパフォーマンスを最適化するのに役立つ主な機能について説明します。
コピー アクティビティの監視 - Azure Data Factory & Azure Synapse
Azure Data Factory と Azure Synapse Analytics でのコピー アクティビティの実行を監視する方法について説明します。