データフローは、セルフサービスによるクラウドベースのデータ準備テクノロジです。 この記事では、初めてのデータフローを作成し、データフローのデータを取得してから、データを変換してデータフローを発行します。
前提条件
開始するには、次の前提条件が必要です。
- アクティブなサブスクリプションを持つMicrosoft Fabric テナント アカウント。 無料アカウントの作成。
- Microsoft Fabric有効なワークスペースがあることを確認します: ワークスペースの作成。
データフローを作成する
このセクションでは、初めてのデータフローを作成します。
注
2026 年 4 月の時点で、すべての新しい Dataflow Gen2 項目は、既定で CI/CD と Git 統合のサポートを使用して作成されます。 CI/CD をサポートせずに Dataflow Gen2 項目を作成するオプションは使用できなくなりました。 既存の CI/CD 以外のデータフローは引き続き機能します。
Microsoft Fabric ワークスペースに移動し、Microsoft Fabric ポータルに移動し、左側のナビゲーション ウィンドウから Workspaces を選択し、一覧からワークスペースを選択します。
[+新しい項目] を選択し、[データフロー Gen2] を選択します。
![[Dataflow Gen2] の選択が強調表示されているスクリーンショット。](media/create-first-dataflow-gen2/select-dataflow-gen2.png)
データを取得する
データを取得してみましょう。 この例では、OData サービスからデータを取得します。 データフロー内のデータを取得するには、次の手順に従います。
データフロー エディターで、[データの取得] を選択し、[その他] を選択します。
![[データの取得] オプションが選択され、ドロップダウン ボックスで [その他] が強調表示されているスクリーンショット。](media/create-first-dataflow-gen2/select-more.png)
[データ ソースの選択] で、[さらに表示] を選択します。
![[データ ソースの取得] で [さらに表示] が強調表示されているスクリーンショット。](media/create-first-dataflow-gen2/view-more.png)
[新しいソース] で、データ ソースとして [その他]>[OData] を選択します。
![[データ ソースの取得] で、[その他] カテゴリと [OData] コネクタが強調されているスクリーンショット。](media/create-first-dataflow-gen2/select-odata-source.png)
URL
https://services.odata.org/v4/northwind/northwind.svc/を入力してから、[次へ] を選択します。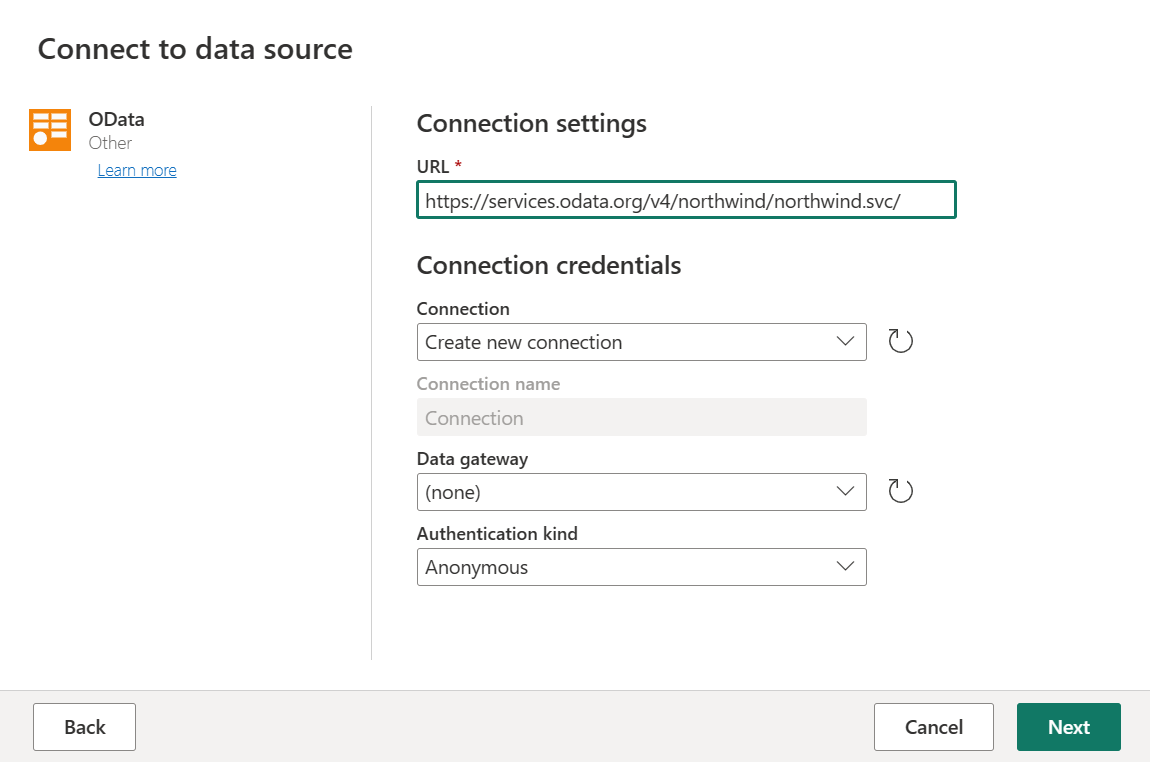
Orders テーブルと Customers テーブルを選択し、[作成] を選択します。
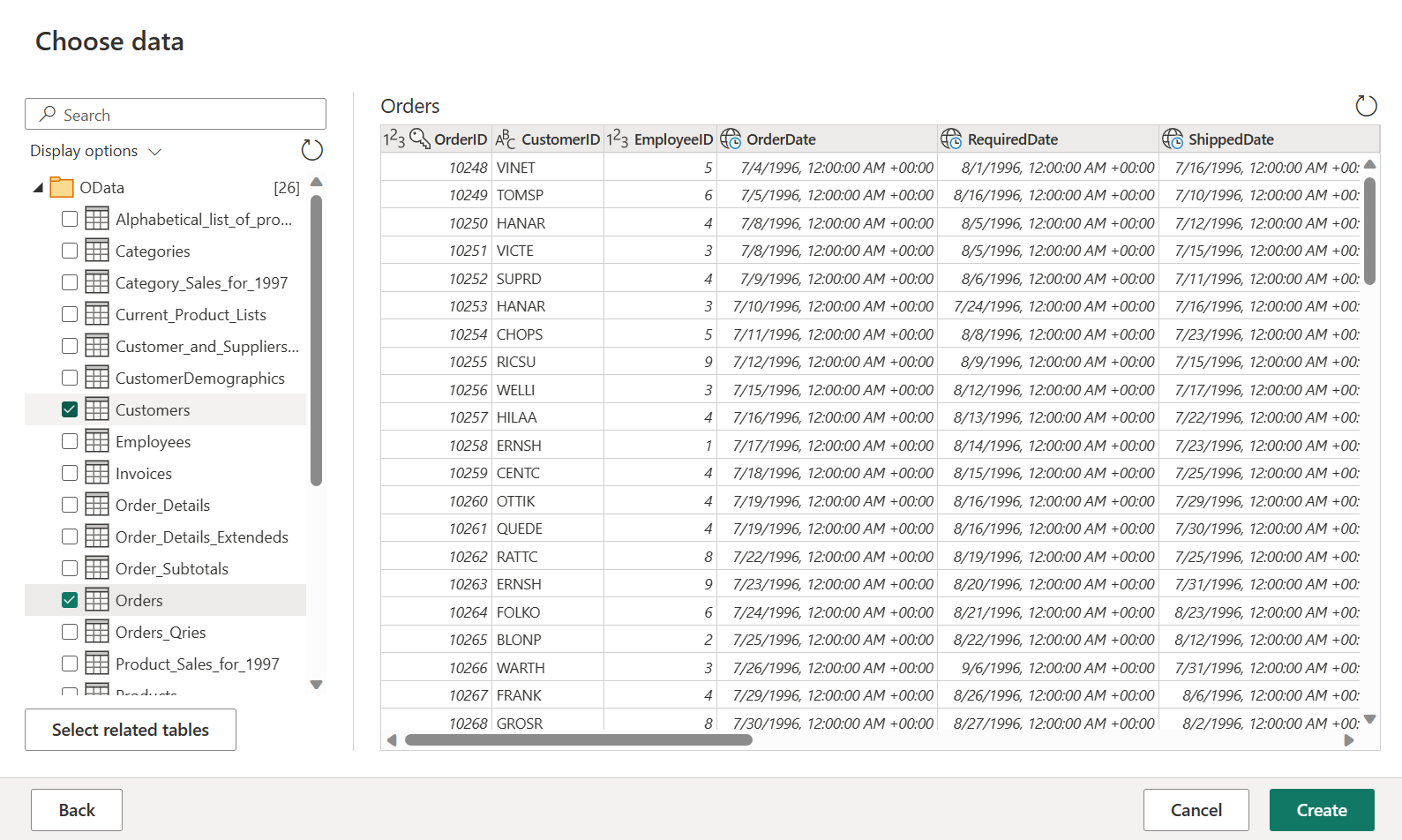
![[データ ソースの取得] で [さらに表示] が強調表示されているスクリーンショット。](media/create-first-dataflow-gen2/view-more.png#lightbox)
![[データ ソースの取得] で、[その他] カテゴリと [OData] コネクタが強調されているスクリーンショット。](media/create-first-dataflow-gen2/select-odata-source.png#lightbox)

データの取得エクスペリエンスと機能の詳細については、 データの取得の概要に関するページを参照してください。
変換を適用して発行する
最初のデータフローにデータを読み込んだ。 おめでとうございます! 次に、いくつかの変換を適用して、このデータを必要な図形に取り込みます。
Power Query エディターでデータを変換します。 Power Query エディターの詳細な概要については、Power Query ユーザー インターフェイスを参照してください。ただし、このセクションでは基本的な手順について説明します。
データ プロファイル ツールがオンになっていることを確認します。 [ホーム>オプション>グローバル オプション] に移動し、[列プロファイル] のすべてのオプションを選択します。
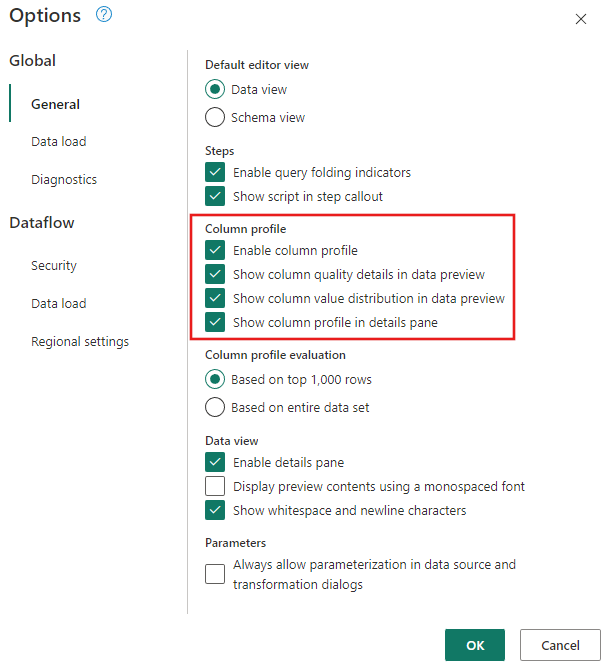
また、Power Query エディター リボンの
View タブの下にあるレイアウト構成を使用するか、Power Query ウィンドウの右下にあるダイアグラム ビュー アイコンを選択して、 diagram ビュー を有効にしてください。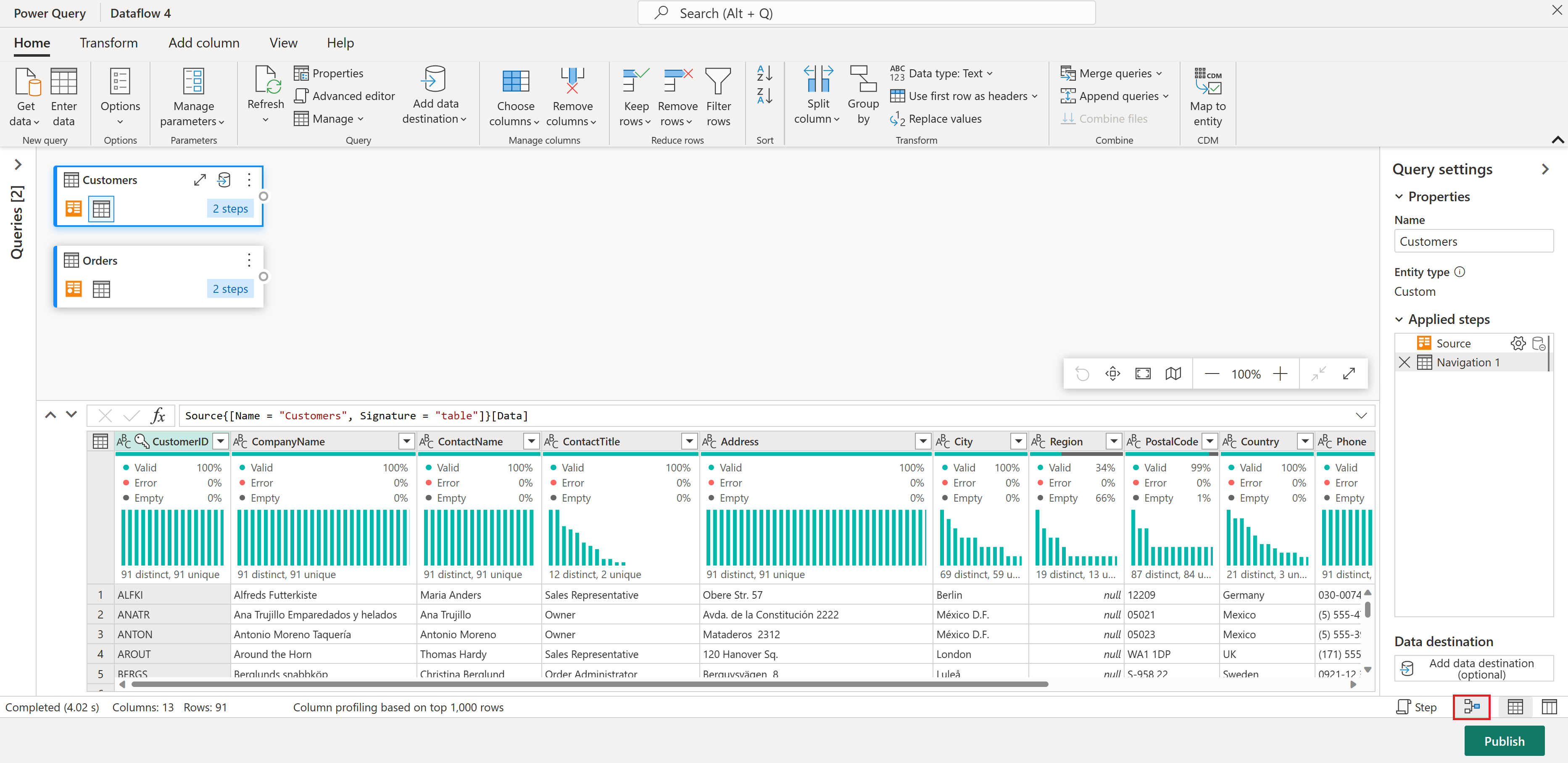
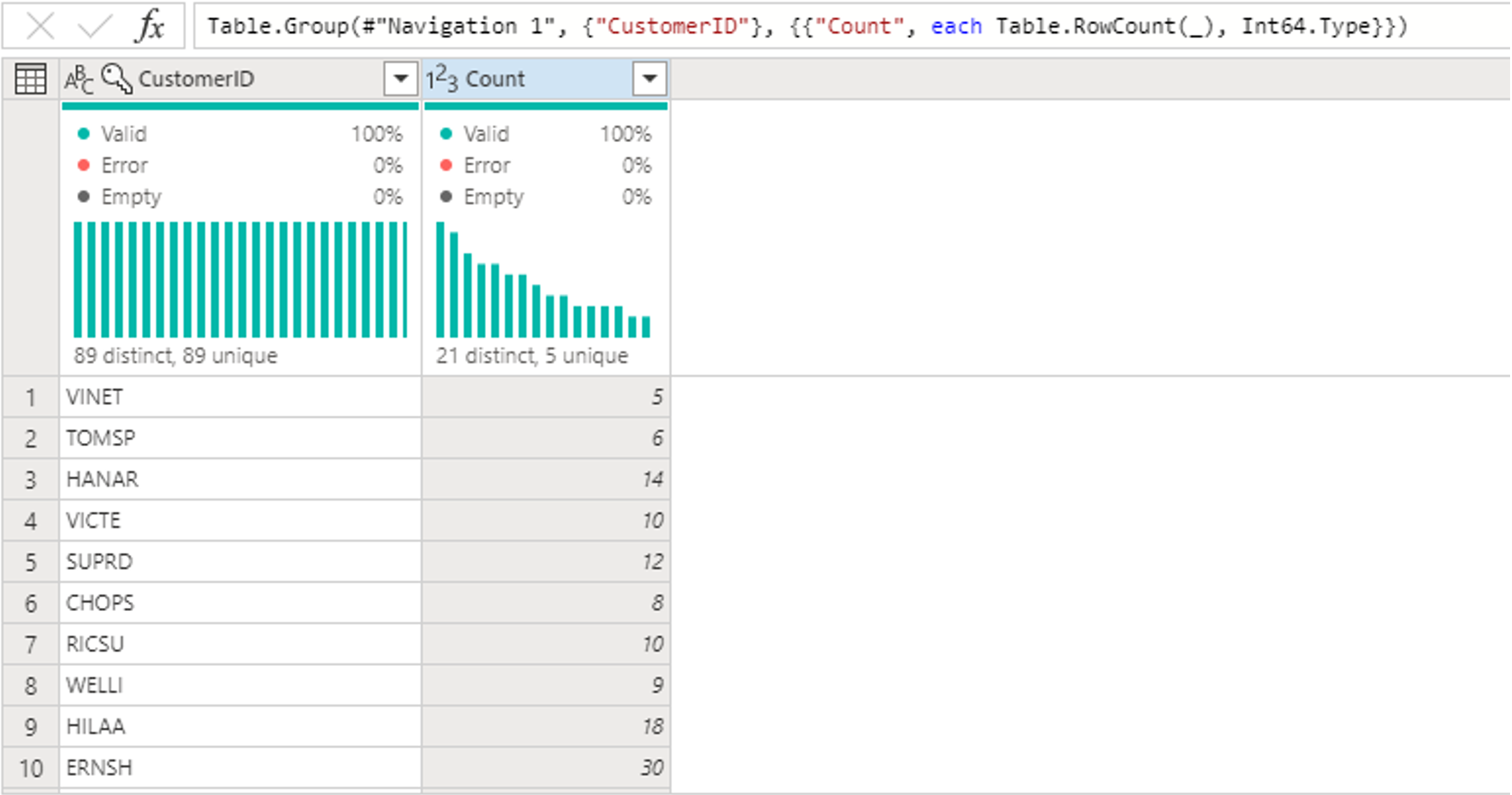
Orders テーブル内で、顧客ごとの注文の合計数を計算します。データ プレビューで CustomerID 列を選択し、リボンの [変換] タブで [グループ化] を選択します。
![Orders テーブルが選択され、[変換] タブで [グループ化] が強調表示されていることを示すスクリーンショット。](media/create-first-dataflow-gen2/calculate-orders.png)
Group By内で、集計として行数をカウントします。 グループ化機能の詳細については、「行のグループ化または集計」を参照してください。
![[グループ化] のスクリーンショットで、行数のカウント操作が選択されています。](media/create-first-dataflow-gen2/group-by-row-count.png)
Orders テーブルのデータをグループ化した後、CustomerID と Count が列として含まれる 2 列のテーブルを取得します。
次に、[顧客] テーブルのデータを顧客ごとの注文数と組み合わせます。ダイアグラム ビューで [顧客] クエリを選択し、[⋮] メニューを使用して 、新しい変換としてマージ クエリ にアクセスします。
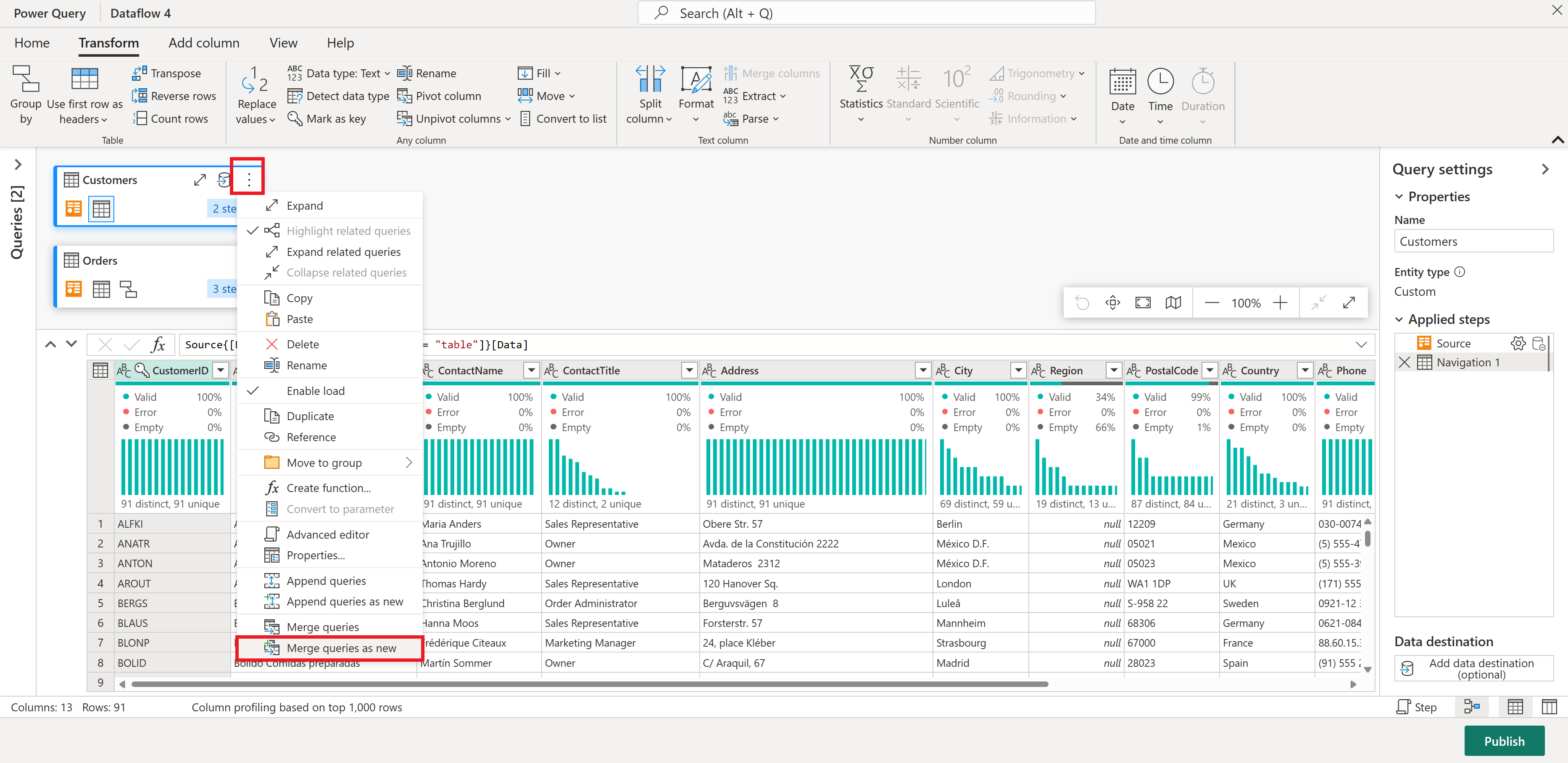
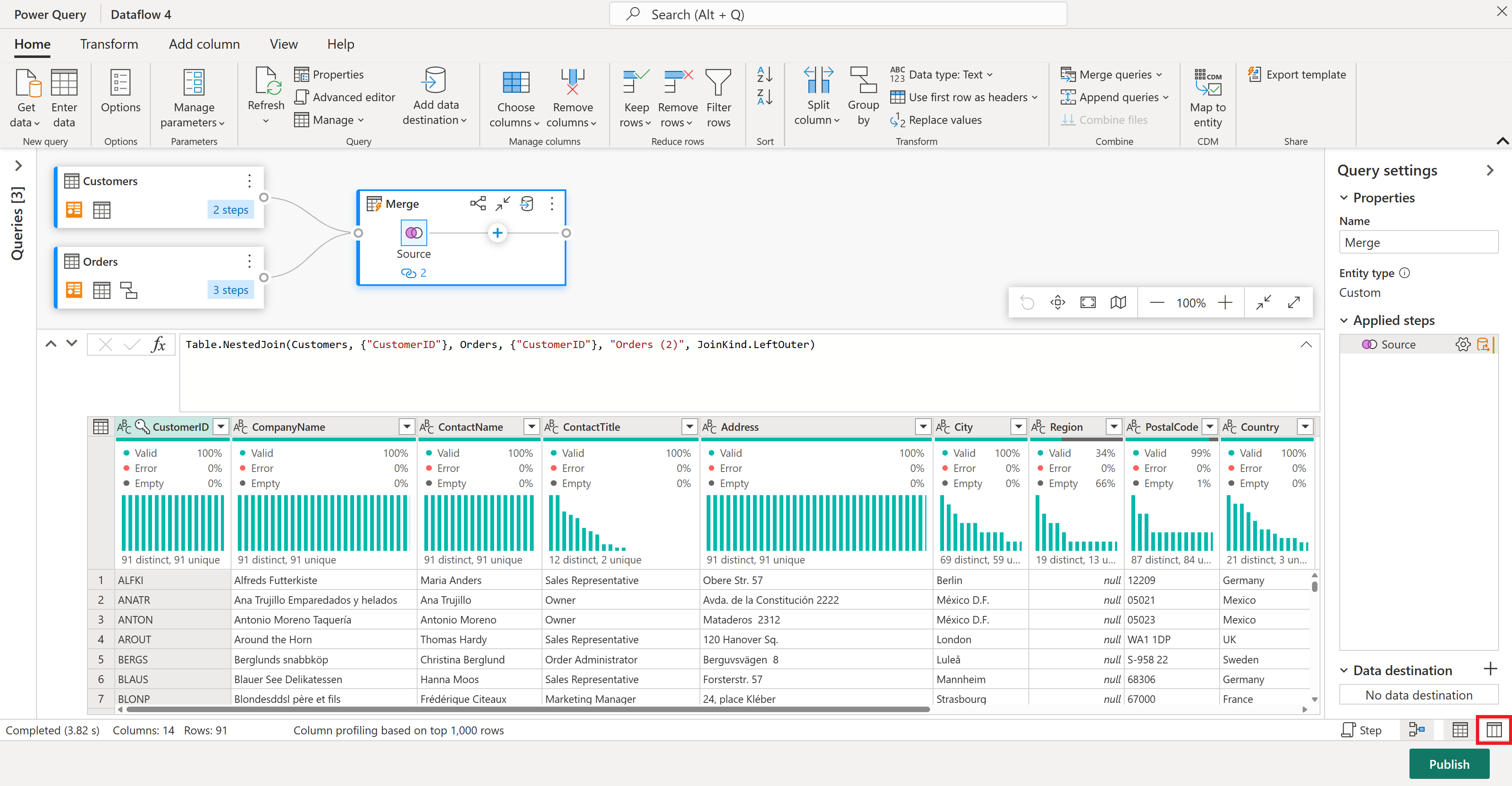
両方のテーブルで一致する列として CustomerID を選択して、マージ操作を構成します。 そして Ok を選択します。
![[マージ] ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/merge-customers.png)
[マージ] ウィンドウのスクリーンショット。[マージ用の左テーブル] が Customers テーブルに設定され、[マージ用の右テーブル] が Orders テーブルに設定されています。 CustomerID 列は、Customers テーブルと Orders テーブルの両方で選択されます。 また、[結合の種類] は [左外部] に設定されます。 その他の選択はすべて既定値に設定されます。
Customers テーブルのすべての列と、Orders テーブルの入れ子になったデータを含む 1 つの列を含む新しいクエリが作成されました。

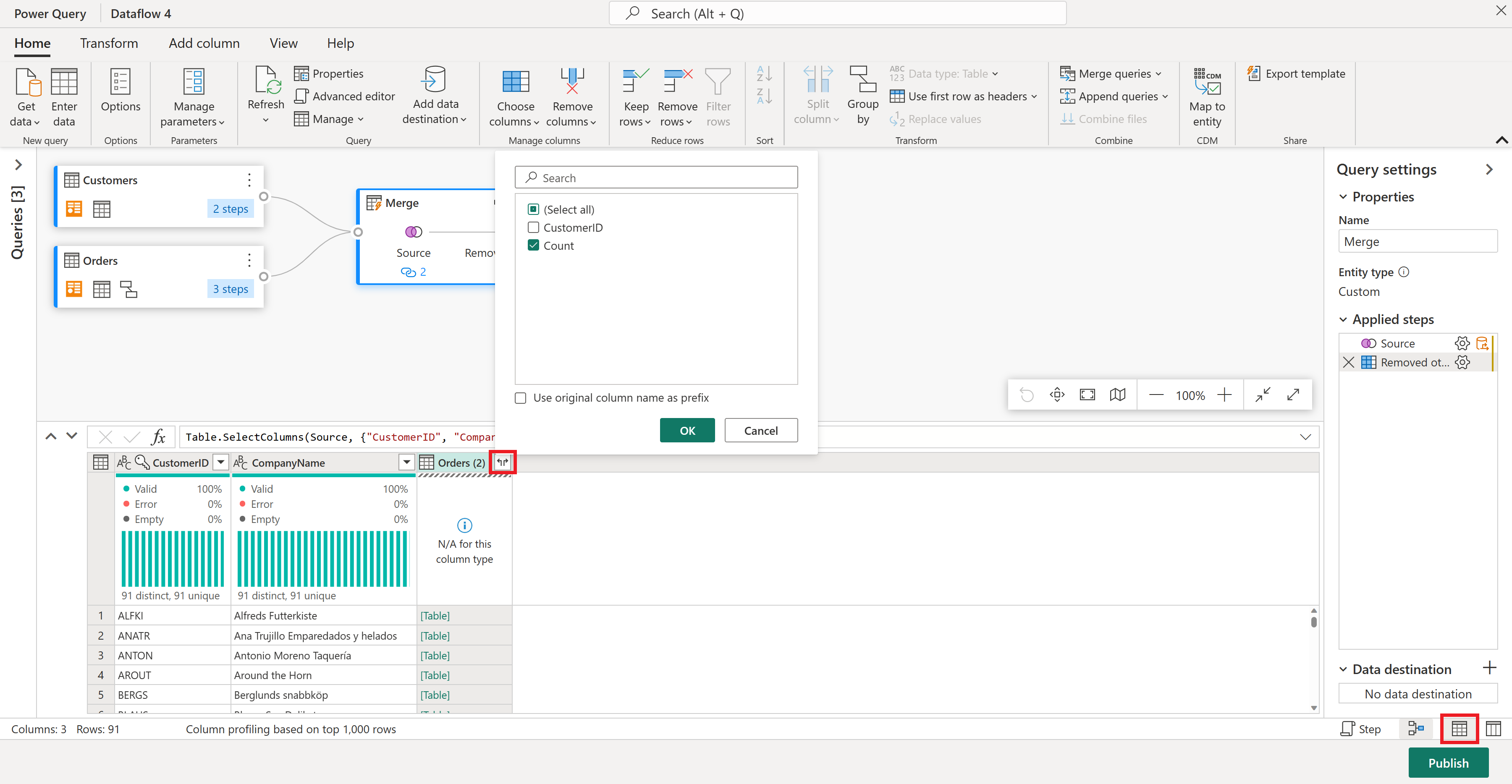
Customers テーブルの特定の列に注目しましょう。 これを行うには、データフロー エディターの右下隅にあるスキーマ ビュー ボタンを選択して、スキーマ ビューを有効にします。
スキーマ ビューには、テーブル内のすべての列が表示されます。 CustomerID、CompanyName、および Orders (2) を選択します。 次に、[ スキーマ ツール ] タブに移動し、[ 列の削除] を選択して、[ 他の列の削除] を選択します。 これにより、必要な列のみが保持されます。
![使用できるすべての列名が表示され、[CustomerID]、[CompanyName]、[Orders (2)] 列が強調表示されているスキーマ ビューのスクリーンショット。](media/create-first-dataflow-gen2/remove-columns-result.png)
![[他の列の削除] が強調表示されているスキーマ ツール メニューのスクリーンショット。](media/create-first-dataflow-gen2/remove-other-columns.png)
Orders (2) 列には、マージ ステップの追加の詳細が保持されます。 このデータを表示して使用するには、右下隅の [スキーマ ビューの表示] の横にある [ データ ビュー の表示] ボタンを選択 します。 次に、 Orders (2) 列ヘッダーで、[ 列の展開 ] アイコンを選択し、[ カウント ] 列を選択します。 これにより、各顧客の注文数がテーブルに追加されます。
次に、注文の数で顧客をランク付けしましょう。 [ カウント ] 列を選択し、[ 列の追加 ] タブに移動し、[ ランク列] を選択します。 これにより、注文数に基づいて各顧客のランクを示す新しい列が追加されます。
![[カウント] 列が選択されているデータフロー エディターのスクリーンショット。](media/create-first-dataflow-gen2/select-rank-column.png)
[順位列] の既定の設定のままにします。 次に、[OK] を選択してこの変換を適用します。
![すべての既定の設定が表示されている [順位] ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/default-rank-column.png)
次に、画面の右側にある [クエリの設定] ペインを使用して、結果のクエリの名前を「Ranked Customers」に変更します。
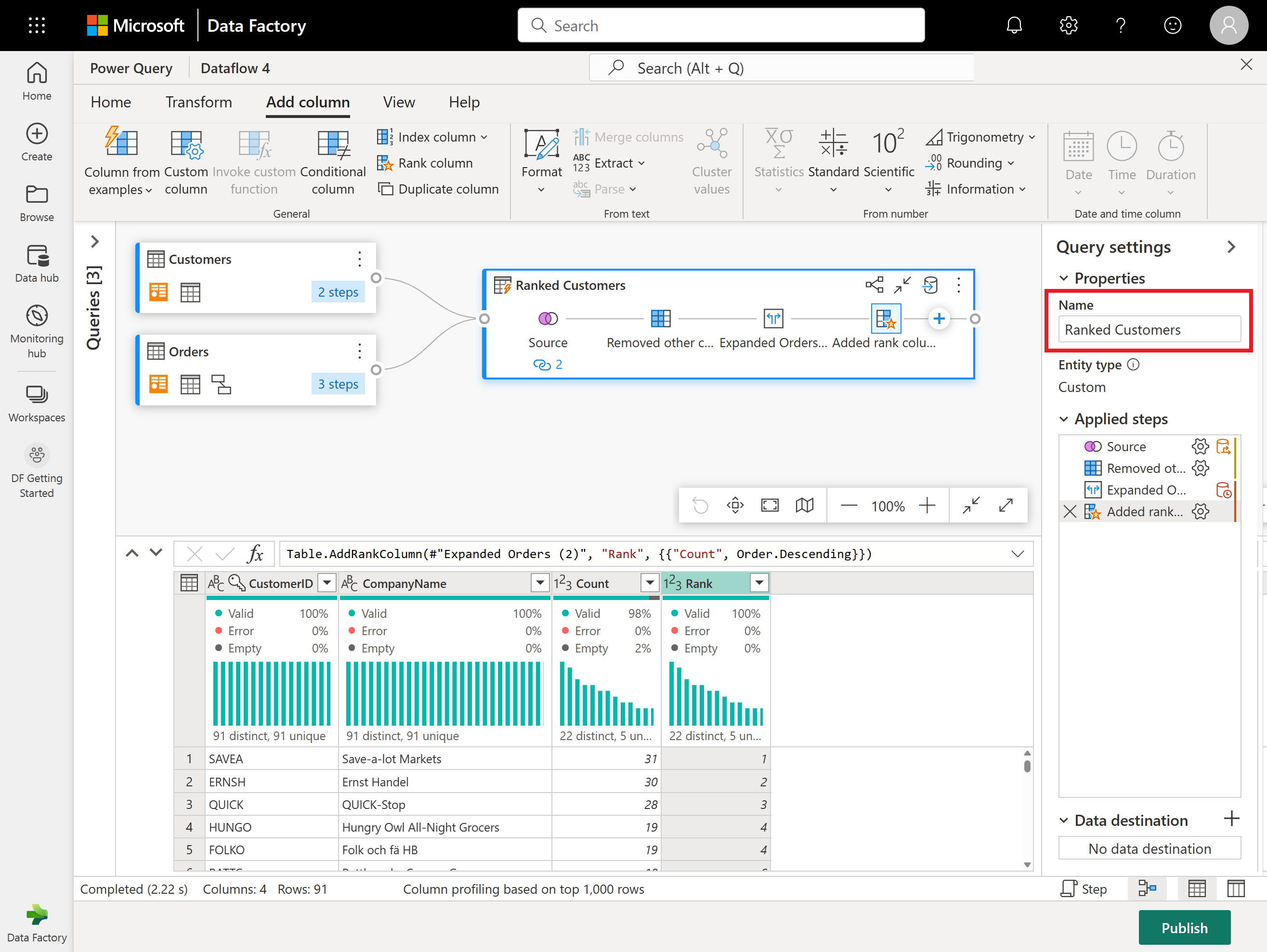
データの進む場所を設定する準備ができました。 [クエリ設定] ウィンドウで、一番下までスクロールし、[データ変換先の選択] を選択します。
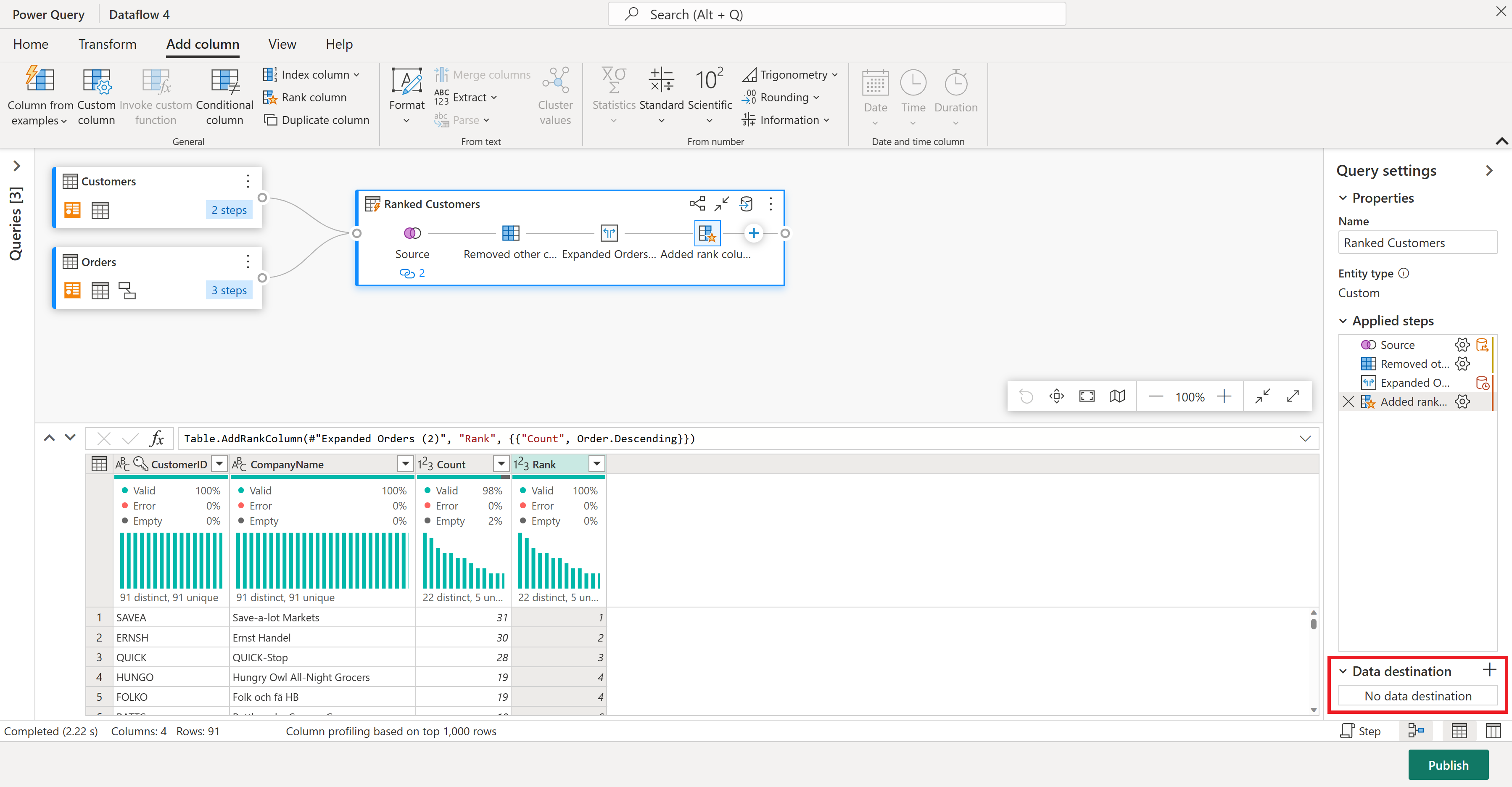
結果がある場合はレイクハウスに送信するか、そうでない場合はこの手順をスキップできます。 ここでは、データに使用するレイクハウスとテーブルを選択し、新しいデータを追加 (追加) するか、そこに置き換えるか (置換) を選択できます。
![レイクハウスが選択されている [データ変換先に接続] ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/configure-output.png)
![[宛先の設定を選択する] ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/choose-destination-settings.png)
これで、データフローを公開する準備が整いました。 ダイアグラム ビューでクエリを確認し、[発行] を選択します。
![右下の [発行] ボタンが強調されているデータフロー エディターのスクリーンショット。](media/create-first-dataflow-gen2/publish-dataflow.png)
右下隅にある [ 発行] を選択して、データフローを保存します。 ワークスペースに戻ると、データフロー名の横にあるスピナーアイコンが、発行中であることを示しています。 スピナーが消えると、データフローを更新する準備が整います。
重要
ワークスペースに Dataflow Gen2 を初めて作成しますと、Fabric がデータフローの実行に役立つ背景項目として、Lakehouse と Warehouse を設定します。 これらの項目はワークスペース内のすべてのデータフローによって共有されるため、削除しないでください。 これらは直接使用するためのものではなく、通常はワークスペースには表示されませんが、ノートブックや SQL 分析などの他の場所に表示される場合があります。
DataflowStagingで始まる名前を探して見つけ出します。ワークスペースで、[更新のスケジュール設定] アイコンを選択します。

スケジュール設定された更新をオンにし、[別の時刻を追加] を選択し、次のスクリーンショットに示すように更新を構成します。
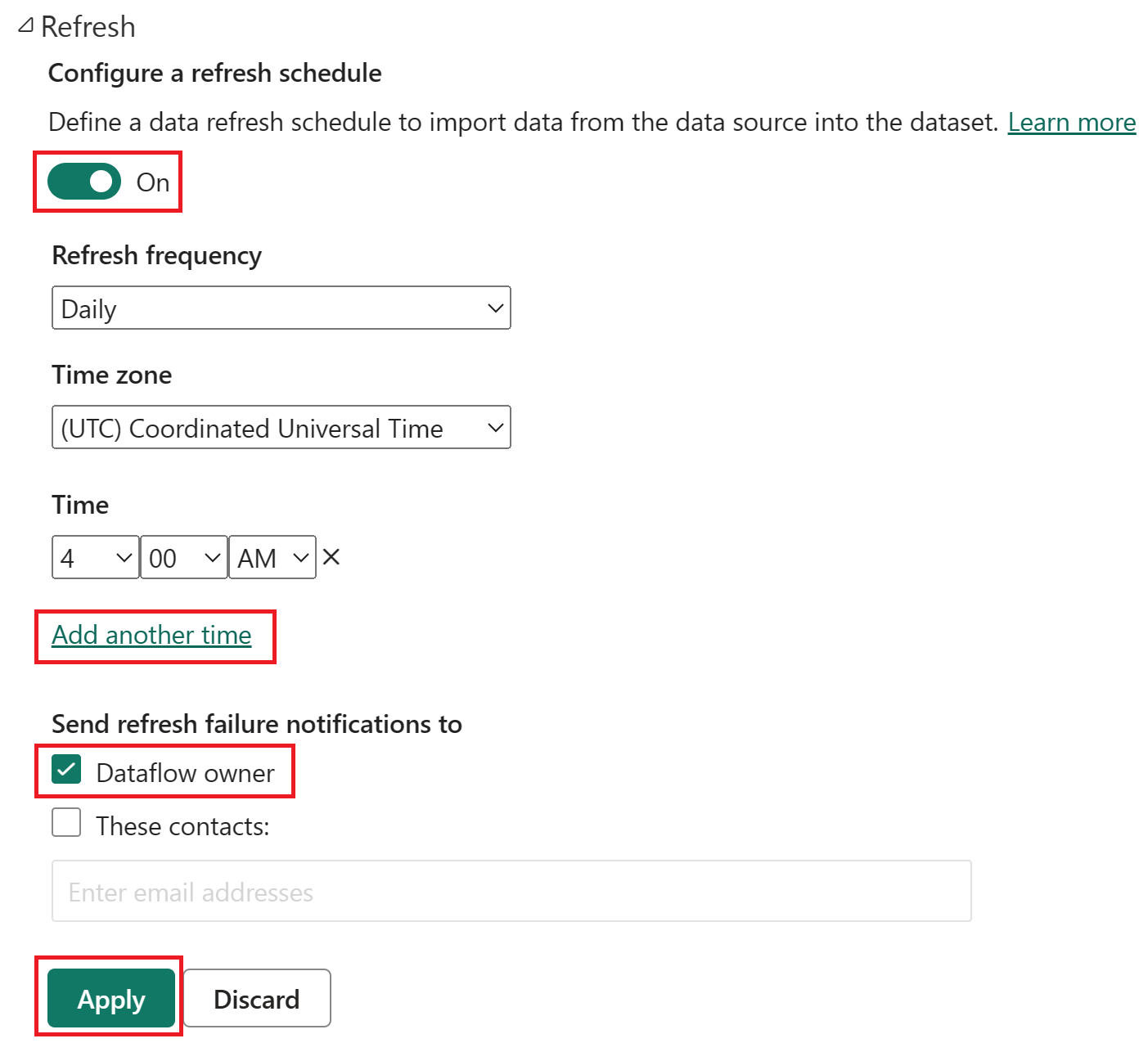
スケジュール設定された更新オプションのスクリーンショット。スケジュール設定された更新がオンで、更新頻度が [毎日] に設定され、タイム ゾーンが協定世界時に設定され、時刻が午前 4 時に設定されています。 オン ボタン、[別の時刻を追加] の選択、データフローの所有者、適用ボタンがすべて強調表示されています。

![Orders テーブルが選択され、[変換] タブで [グループ化] が強調表示されていることを示すスクリーンショット。](media/create-first-dataflow-gen2/calculate-orders.png#lightbox)




![使用できるすべての列名が表示され、[CustomerID]、[CompanyName]、[Orders (2)] 列が強調表示されているスキーマ ビューのスクリーンショット。](media/create-first-dataflow-gen2/remove-columns-result.png#lightbox)



![レイクハウスが選択されている [データ変換先に接続] ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/configure-output.png#lightbox)
![[宛先の設定を選択する] ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/choose-destination-settings.png#lightbox)
![右下の [発行] ボタンが強調されているデータフロー エディターのスクリーンショット。](media/create-first-dataflow-gen2/publish-dataflow.png#lightbox)
リソースをクリーンアップする
このデータフローを引き続き使用しない場合は、次の手順を使用してデータフローを削除します。
Microsoft Fabric ワークスペースに移動します。
データフローの名前の横にある垂直の 3 つの点を選択し、[削除] を選択します。
[削除] を選択して、データフローの削除を確認します。
![[削除] ボタンが強調表示されている [削除] データフロー ウィンドウのスクリーンショット。](media/create-first-dataflow-gen2/confirm-delete.png)
関連するコンテンツ
このサンプルのデータフローは、データフロー (Gen2) でデータを読み込んで変換する方法を示しています。 以下の方法を学習しました。
- データフロー (Gen2) を作成します。
- データを変換する。
- 変換されたデータの変換先の設定を構成します。
- パイプラインを実行し、スケジュールします。
最初のパイプラインを作成する方法については、次の記事に進んでください。