Microsoft Fabric の Copilot は、Fabric プラットフォームのデータ分析エクスペリエンスを強化することを目的とした生成型 AI 支援技術です。 この記事は、Fabric の Copilot のしくみを理解するのに役立ちます。また、その使用方法に関する高度なガイダンスと考慮事項について説明します。
注
Copilot の機能は時間の経過と同時に進化しています。 Copilot を使用する予定の場合は、Fabric の毎月の更新プログラムと、Copilot エクスペリエンスに対する変更や発表を常に最新の状態に保つようにしてください。
この記事は、アーキテクチャやコストなど、Fabric の Copilot のしくみを理解するのに役立ちます。 この記事の情報は、お客様と組織が Copilot を効果的に使用および管理するためのガイドを目的としています。 この記事の主な対象者は、次のとおりです。
BI および分析ディレクターまたはマネージャー: BI プログラムと戦略の監督を担当し、Fabric やその他の AI ツールで Copilot を有効にして使用するかどうかを決定する意思決定者。
ファブリック管理者: Microsoft Fabric とそのさまざまなワークロードを監督する組織内のユーザー。 ファブリック管理者は、これらのワークロードごとに Fabric で Copilot を使用できるユーザーを監視し、Copilot の使用が使用可能なファブリック容量に与える影響を監視します。
データ アーキテクト: 組織内のデータと分析をサポートするプラットフォームとアーキテクチャの設計、構築、管理を担当する担当者。 データ アーキテクトは、アーキテクチャ設計における Copilot の使用を検討します。
センター オブ エクセレンス (COE)、IT、BI チーム: 組織内の Fabric などのデータ プラットフォームの導入と使用の成功を促進する役割を担うチーム。 これらのチームや個人は、Copilot 自体のような AI ツールを使用するだけでなく、組織内のセルフサービス ユーザーをサポートおよび指導して、その恩恵を受けることもあります。
Fabric での Copilot のしくみの概要
Copilot in Fabric は、Microsoft 365 Copilot、Microsoft Security Copilot、Power Platform の Copilot および生成 AI など、他の Microsoft Copilot と同様に機能します。 ただし、Fabric の Copilot のしくみに固有のいくつかの側面があります。
プロセスの概要図
次の図は、Fabric の Copilot のしくみの概要を示しています。
注
次の図は、Fabric の Copilot の一般的なアーキテクチャを示しています。 ただし、特定のワークロードとエクスペリエンスによっては、追加や違いがある可能性があります。
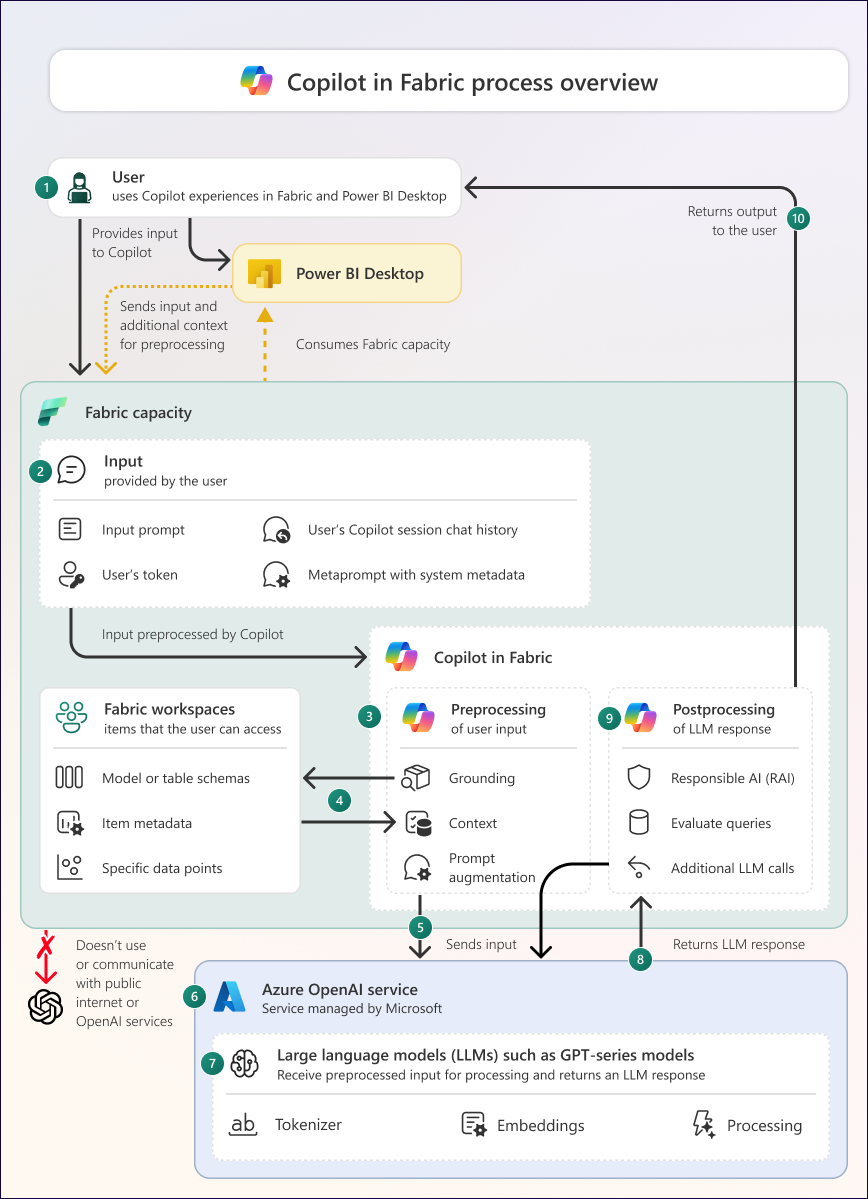
図は、次の部分とプロセスで構成されています。
| アイテム | 説明 |
|---|---|
| 1 | ユーザーは、Fabric、Power BI Desktop、または Power BI モバイル アプリで Copilot に入力を提供します。 入力には、プロンプトを書き込むか、プロンプトを生成する別の操作を指定できます。 Copilot との対話はすべてユーザー固有です。 |
| 2 | 入力には、プロンプト、ユーザーのトークン、ユーザーの Copilot セッション チャット履歴などのコンテキスト、およびユーザーの場所や Fabric または Power BI Desktop での実行内容など、システム メタデータを含むメタ プロンプトを含む情報が含まれます。 |
| 3 | Copilot は、ユーザー入力と大規模言語モデル (LLM) 応答の前処理と後処理をそれぞれ処理します。 前処理と後処理中に実行される特定の手順は、個人が使用している Copilot エクスペリエンスによって異なります。 それを使用するには、テナント設定でファブリック管理者が Copilot を有効にする必要があります。 |
| 4 | 前処理中に、Copilot は、最終的な LLM 応答の特定性と有用性を向上させるために、追加のコンテキスト情報を取得するための接地を実行します。 グラウンド データには、メタデータ (レイクハウスやセマンティック モデルのスキーマなど) やワークスペース内のアイテムのデータ ポイント、または現在の Copilot セッションのチャット履歴が含まれる場合があります。 Copilot は、ユーザーがアクセスできるグラウンド データのみを取得します。 |
| 5 | 前処理を行うと、最終的な入力 (最終的なプロンプトとグラウンド データ) が生成されます。 送信されるデータは、特定の Copilot エクスペリエンスとユーザーが求めている内容によって異なります。 |
| 6 | Copilot は入力を Azure OpenAI サービスに送信します。 このサービスは Microsoft によって管理されており、ユーザーが構成することはできません。 Azure OpenAI では、データを使用してモデルをトレーニングしません。 Azure OpenAI を地理的な領域で使用できなくても、 Azure OpenAI に送信されるデータを容量の地理的リージョン、コンプライアンス境界、または国内クラウド インスタンスの外部で処理できるテナント設定を有効にしている場合、Copilot はこれらの地理的領域の外部にデータを送信する可能性があります。 |
| 7 | Azure OpenAI では、GPT シリーズのモデルのような LLM がホストされます。 Azure OpenAI は OpenAI のパブリック サービスまたは API を使用せず、OpenAI はデータにアクセスできません。 これらの LLM は入力をトークン化し、トレーニング データからの埋め込みを使用して入力を応答に処理します。 LLM は、トレーニング データの範囲とスケールで制限されます。 Azure OpenAI には、LLM が入力を処理する方法と返される応答を決定する構成が含まれています。 お客様がこの構成を表示または変更することはできません。 OpenAI サービスへの呼び出しは、パブリック インターネット経由ではなく、Azure 経由で行われます。 |
| 8 | LLM 応答は、Azure OpenAI から Fabric の Copilot に送信されます。 この応答は、自然言語、コード、またはメタデータである可能性があるテキストで構成されます。 応答には、不正確または低品質の情報が含まれる場合があります。 また、非決定論的です。つまり、同じ入力に対して別の応答が返される可能性があります。 |
| 9 | Copilot は LLM 応答を後処理します。 後処理には、責任ある AI のフィルター処理が含まれますが、LLM 応答の処理と最終的な Copilot 出力の生成も含まれます。 後処理中に実行される具体的な手順は、個別に使用される Copilot エクスペリエンスによって異なります。 |
| "10" | Copilot は、最終的な出力をユーザーに返します。 出力には信頼性や正確性の指標が含まれていないので、ユーザーは使用する前に出力を確認します。 |
次のセクションでは、前の図に示した Copilot プロセスの 5 つの手順について説明します。 これらの手順では、Copilot がユーザー入力からユーザー出力にどのように行くかについて詳しく説明します。
手順 1: ユーザーが Copilot に入力を提供する
Copilot を使用するには、ユーザーが最初に 入力を送信する必要があります。 この入力は、ユーザーが自分で送信するプロンプトを記述することも、ユーザーが UI で対話型要素を選択したときに Copilot によって生成されるプロンプトである場合もあります。 他のユーザーが使用する特定の Fabric ワークロード、項目、および Copilot エクスペリエンスに応じて、Copilot に入力を提供するさまざまな方法があります。
次のセクションでは、ユーザーが Copilot に入力を提供する方法のいくつかの例について説明します。
Copilot チャット パネルを使用した入力
Fabric で多くの Copilot エクスペリエンスを使用すると、チャットボットやメッセージング サービスと同様に、自然言語を使用して Copilot と対話するように Copilot チャット パネルを拡張できます。 Copilot チャット パネルでは、Copilot で実行するアクションを説明する自然言語プロンプトを記述できます。 また、Copilot チャット パネルには、選択できるプロンプトが提案されたボタンが含まれている場合があります。 これらのボタンを操作すると、Copilot は対応するプロンプトを生成します。
次の図は、Copilot チャット パネルを使用して Power BI レポートに関するデータの質問をする例を示しています。

注
Microsoft Edge ブラウザーを使用する場合は、そこで Copilot にアクセスすることもできます。 Edge の Copilot では、ブラウザーで Copilot チャット パネル (またはサイドバー) を開くこともできます。 Edge の Copilot は、Fabric の Copilot エクスペリエンスとやり取りしたり、使用したりすることはできません。 どちらの Copilot も同様のユーザー エクスペリエンスを持ちますが、Edge の Copilot は Fabric の Copilot とは完全に分離されています。
コンテキスト依存のポップアップ ウィンドウを使用した入力
特定のエクスペリエンスでは、Copilot アイコンを選択して、Copilot と対話するポップアップ ウィンドウをトリガーできます。 たとえば、DAX クエリ ビューまたは Power BI Desktop の TMDL スクリプト ビューで Copilot を使用する場合などです。 このポップアップ ウィンドウには、自然言語プロンプト (Copilot チャット パネルと同様) を入力するための領域と、プロンプトを生成できるコンテキスト固有のボタンが含まれています。 このウィンドウには、DAX クエリ ビューで Copilot を使用する場合の DAX クエリや概念に関する説明など、出力情報が含まれている場合もあります。
次の図は、DAX クエリ ビューで Copilot エクスペリエンスを使用して、Power BI で Copilot を使用して生成されたクエリを説明するユーザーの例を示しています。

ユーザー入力の種類
Copilot の入力は、書き込まれたプロンプトまたは UI のボタンから行うことができます。
プロンプトの書き込み: ユーザーは、Copilot チャット パネルや、Power BI Desktop の DAX クエリ ビューなどの他の Copilot エクスペリエンスでプロンプトを記述できます。 書面によるプロンプトでは、ユーザーが Copilot の指示または質問を適切に説明する必要があります。 たとえば、Power BI で Copilot を使用する場合、ユーザーはセマンティック モデルやレポートについて質問できます。
ボタン: ユーザーは、Copilot チャット パネルまたは他の Copilot エクスペリエンスでボタンを選択して入力を提供できます。 その後、Copilot はユーザーの選択に基づいてプロンプトを生成します。 これらのボタンは、Copilot チャット パネルの提案など、Copilot への最初の入力にすることができます。 ただし、これらのボタンは、Copilot が提案や明確化を要求するセッション中にも表示される場合があります。 Copilot が生成するプロンプトは、現在のセッションのチャット履歴などのコンテキストによって異なります。 ボタン入力の例として、モデル フィールドのシノニムまたはモデル メジャーの説明を提案するように Copilot に依頼する場合があります。
さらに、さまざまなサービスまたはアプリケーションで入力を提供できます。
Fabric: Web ブラウザーから Fabric で Copilot を使用できます。 これは、Fabric で排他的に作成、管理、使用するアイテムに Copilot を使用する唯一の方法です。
Power BI Desktop: Power BI Desktop では、セマンティック モデルとレポートで Copilot を使用できます。 これには、Fabric の Power BI ワークロードの開発と使用の両方の Copilot エクスペリエンスが含まれます。
Power BI モバイル アプリ: Power BI モバイル アプリで Copilot を使用できるのは、レポートが、Copilot が有効になっているサポートされているワークスペース (またはそのワークスペースに接続されているアプリ) にある場合です。
注
Power BI Desktop で Copilot を使用するには、Fabric 容量でサポートされているワークスペースから Copilot の使用量を使用するように Power BI Desktop を構成する必要があります。 その後、Pro ワークスペースや PPU ワークスペースなど、任意のワークスペースに発行されたセマンティック モデルで Copilot を使用できます。
プロンプトが書かれたボタンを選択したときに Copilot によって生成されるプロンプトを変更することはできませんが、自然言語を使用して質問したり、指示を提供したりできます。 Copilot で得られる結果を改善する最も重要な方法の 1 つは、自分がやりたいことを正確に伝える明確で説明的なプロンプトを記述することです。
Copilot のプロンプトの書き込みを改善する
ユーザーが Copilot に送信するプロンプトの明確さと品質は、ユーザーが受け取る出力の有用性に影響する可能性があります。 適切なプロンプトの構成は、使用している特定の Copilot エクスペリエンスによって異なります。ただし、一般的にプロンプトを改善するために、すべてのエクスペリエンスに適用できる手法がいくつかあります。
Copilot に送信するプロンプトを改善するには、次のいくつかの方法があります。
英語のプロンプトを使用する: 現在、Copilot の機能は英語で最適に機能します。 これは、これらの LLM のトレーニング データのコーパスが主に英語であるためです。 他の言語も同様に動作しない可能性があります。 他の言語でプロンプトを記述することもできますが、最適な結果を得るには、英語のプロンプトを作成して送信することをお勧めします。
具体的に: 質問や指示のあいまいさを避けてください。 Copilot で実行するタスクと、予想される出力について説明するのに十分な詳細を含めます。
コンテキストを指定します。 必要に応じて、プロンプトに関連するコンテキスト (何を行おうとしているか、出力で回答する質問など) を指定します。 たとえば、適切なプロンプトの主要なコンポーネントには、次のようなものがあります。
- ゴール: Copilot で実現する出力。
- 文脈: その特定の出力で何を行おうとしているのか、その理由です。
- 期待: 出力は次のようになります。
- 源: Copilot で使用する必要があるデータまたはフィールド。
動詞を使用します。 "レポート ページの作成 " や "顧客キー アカウントへのフィルター処理 " など、Copilot が実行する特定のアクションを明示的に参照します。
適切で関連性の高い用語を使用します。 プロンプト内の適切な用語 (関数、フィールド、テーブル名、ビジュアルの種類、技術用語など) を明示的に参照します。 スペルミス、頭字語、省略形、余分な文法、Unicode 文字や絵文字などの非定型文字は避けてください。
反復処理とトラブルシューティング: 予想される結果が得られない場合は、プロンプトを調整して再送信して、出力が向上するかどうかを確認します。 一部の Copilot エクスペリエンスには、同じプロンプトを再送信して別の結果を確認するための [再試行 ] ボタンも用意されています。
重要
Copilot を有効にする前に、適切なプロンプトを記述するようにユーザーをトレーニングすることを検討してください。 有用な結果を生み出すことができる明確なプロンプトと、そうでないあいまいなプロンプトの違いをユーザーが理解していることを確認します。
また、Copilot やその他の多くの LLM ツールは 非決定論的です。 これは、同じグラウンド データを使用する同じプロンプトを送信する 2 人のユーザーが異なる結果を得ることができることを意味します。 この非決定主義は、生成型 AI の基盤となるテクノロジに固有のものであり、"2021 年 8 月の売上は何か" のようなデータの質問に対する答えなど、決定論的な結果を期待または必要とする場合に重要な考慮事項です。
Copilot が前処理に使用するその他の入力情報
Copilot は、ユーザーが提供する入力とは別に、次の手順で前処理に使用する追加情報も取得します。 この情報には、次のものが含まれます。
ユーザーのトークン。 Copilot は、システム アカウントまたは機関では動作しません。 Copilot に送信され、使用されるすべての情報は、ユーザーに固有のものです。Copilot では、ユーザーがまだ表示するアクセス許可を持っていないアイテムやデータの表示やアクセスを許可することはできません。
現在のセッションの Copilot セッション チャット履歴。 チャット エクスペリエンスまたは Copilot チャット パネルの場合、Copilot は常に、グラウンド データ コンテキストの一部として前処理に使用するためのチャット履歴を提供します。 Copilot は、以前のセッションのチャット履歴を記憶したり使用したりしません。
システム メタデータを含むメタ プロンプト。 メタプロンプトは、ユーザーがどこにいるか、Fabric または Power BI Desktop で何をしているかに関する追加のコンテキストを提供します。 このメタプロンプト情報は、前処理中に、Copilot がユーザーの質問に回答するために使用するスキルまたはツールを決定するために使用されます。
ユーザーが入力を送信すると、Copilot は次の手順に進みます。
手順 2: Copilot が入力を前処理する
プロンプトを Azure OpenAI サービスに送信する前に、Copilot によって 前処理されます 。 前処理は、入力を受信してから Azure OpenAI サービスでこの入力が処理されるまでの間に、Copilot によって処理されるすべてのアクションを構成します。 Copilot の出力が指示や質問に固有で適切であることを確認するには、前処理が必要です。
Copilot による前処理に影響を与えることはできません。 ただし、Copilot が使用するデータとその取得方法を把握できるように、前処理を理解することが重要です。 これは、Fabric の Copilot のコストを理解し、誤った結果または予期しない結果が発生する理由をトラブルシューティングする場合に関連します。
ヒント
特定のエクスペリエンスでは、項目に変更を加えて、その接地データが Copilot で使用できるように構造化されるようにすることもできます。 たとえば、セマンティック モデルで言語モデリングを実行したり、セマンティック モデルのメジャーと列にシノニムと説明を追加したりします。
次の図は、Fabric での Copilot による前処理中の動作を示しています。
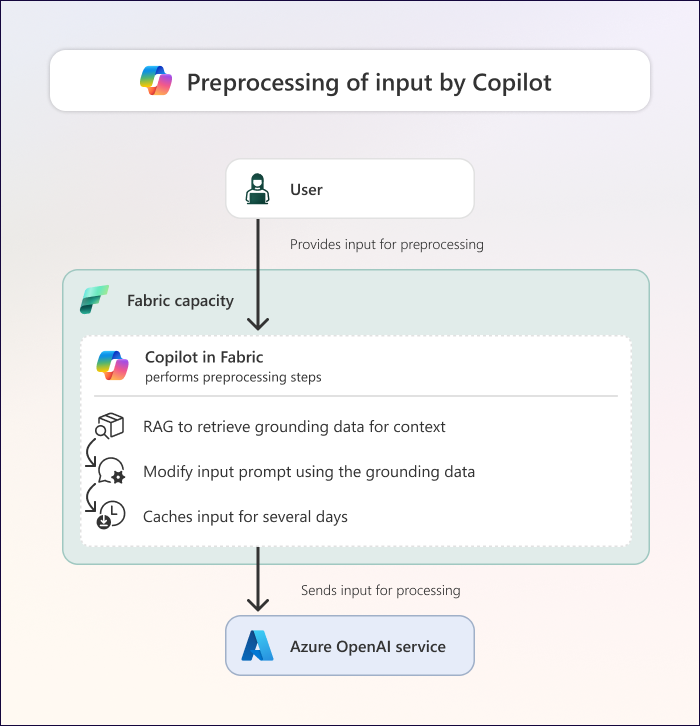
ユーザー入力を受け取った後、Copilot は前処理を実行します。これには次の手順が含まれます。
グランディング: Copilot は、グランディング データを収集するために、リトリーバル強化生成(RAG:Retrieval Augmented Generation)を実行します。 グラウンド データは、Fabric で Copilot を使用している現在のコンテキストからの関連情報で構成されます。 グラウンド データには、次のようなコンテキストが含まれる場合があります。
- Copilot との現在のセッションからのチャット履歴。
- Copilot で使用している Fabric アイテムに関するメタデータ (セマンティック モデルや lakehouse のスキーマ、レポート ビジュアルのメタデータなど)。
- レポート ビジュアルに表示されるデータ ポイントなど、特定のデータ ポイント。 ビジュアル構成のレポート メタデータにもデータ ポイントが含まれています。
- メタ プロンプト。これは、より具体的で一貫性のある出力を確保するために、各エクスペリエンスに対して提供される補足的な手順です。
プロンプト拡張: シナリオに応じて、Copilot は入力データと接地データに基づいてプロンプトを書き換えます (または 拡張します)。 拡張プロンプトは、元の入力プロンプトよりも適切でコンテキストに対応している必要があります。
キャッシュ: 特定のシナリオでは、プロンプトと基礎データがCopilotによって48時間キャッシュされます。 プロンプトをキャッシュすると、繰り返しのプロンプトがキャッシュ中に同じ結果を返し、これらの結果をより速く返し、同じコンテキストでプロンプトを繰り返すためだけに Fabric 容量を消費しないようにします。 キャッシュは、次の 2 つの異なる場所で行われます。
- ユーザーのブラウザー キャッシュ。
- テナントのホーム リージョン内の最初のバックエンド キャッシュ。監査用に格納されます。 Azure OpenAI サービスまたは GPU の場所にデータがキャッシュされません。 Fabric でのキャッシュの詳細については、 Microsoft Fabric のセキュリティに関するホワイトペーパーを参照してください。
Azure OpenAI への入力の送信: Copilot は、拡張プロンプトと関連する接地データを Azure OpenAI サービスに送信します。
Copilot がグラウンド処理を実行すると、ユーザーが通常どおりアクセスできるデータまたは項目からの情報のみが収集されます。 Copilot では、ワークスペースのロール、項目のアクセス許可、およびデータセキュリティが尊重されます。 また、Copilot は他のユーザーからのデータにアクセスすることもできません。Copilot との対話は、個々のユーザーに固有です。
接地プロセス中に Copilot が収集するデータと Azure OpenAI プロセスは、使用する特定の Copilot エクスペリエンスによって異なります。 詳細については、「 Copilot で使用されるデータとその処理方法」を参照してください。
前処理が完了し、Copilot が入力を Azure OpenAI に送信した後、Azure OpenAI サービスはその入力を処理して、Copilot に返される応答と出力を生成できます。
手順 3: Azure OpenAI がプロンプトを処理し、出力を生成する
すべての Copilot エクスペリエンスは、Azure OpenAI サービスを利用します。
Azure OpenAI サービスについて
Copilot では、OpenAI の一般公開サービスではなく Azure OpenAI を使用して、すべてのデータを処理し、応答を返します。 前述のように、この応答は LLM によって生成されます。 LLM は、ディープ ラーニングを使用して非構造化データのパターンを見つけて再現することに重点を置く、"狭い" AI に対する特定のアプローチです。具体的には、テキストです。 このコンテキストのテキストには、自然言語、メタデータ、コード、およびその他の意味的に意味のある文字の配置が含まれます。
Copilot は現在、OpenAI の Generative Pre-trained Transformer (GPT) シリーズのモデルを含む GPT モデルの組み合わせを使用しています。
注
他の基礎モデルや独自のモデルの使用を含め、Copilot が使用するモデルを選択または変更することはできません。 Fabric の Copilot では、さまざまなモデルが使用されます。 また、Fabric の Copilot と異なる動作をするように Azure OpenAI サービスを変更または構成することもできません。このサービスは Microsoft によって管理されます。
現時点では、Fabric の Copilot によって使用されるモデルでは、微調整は使用されていません。 代わりに、モデルは、基底データやメタプロンプトに依存して、より具体的で有用な出力を生成します。
現時点では、Fabric の Copilot によって使用されるモデルでは、微調整は使用されていません。 代わりに、モデルは、基底データやメタプロンプトに依存して、より具体的で有用な出力を生成します。
Microsoft は、Microsoft の Azure 環境で OpenAI モデルをホストしており、サービスは OpenAI (ChatGPT やパブリック OpenAI API など) によってパブリック サービスと対話しません。 お客様のデータはモデルのトレーニングには使用されず、他の顧客が使用することはできません。 詳細については、 Azure OpenAI サービスに関するページを参照してください。
トークン化について
Fabric の Copilot のコスト (つまり、Copilot が消費するファブリック容量) は、Copilot の入力と出力によって生成されたトークンの数によって決まるため、トークン化を理解することが不可欠です。
Copilot からのテキスト入力を処理するには、Azure OpenAI ではまず、その入力を数値表現に変換する必要があります。 このプロセスの重要なステップは トークン化です。これは、トークンと呼ばれる異なる小さな部分への入力テキストのパーティション分割 です。 トークンは一連の同時発生文字であり、LLM が出力を生成するために使用する情報の最小単位です。 各トークンには対応する数値 ID があります。これは、テキストを数値としてエンコードして使用するための LLM のボキャブラリになります。 テキストをトークン化する方法はさまざまで、LLM によって入力テキストはさまざまな方法でトークン化されます。 Azure OpenAI では、サブワード トークン化の方法である Byte-Pair エンコード (BPE) が使用されます。
トークンとは何か、プロンプトがトークンになるしくみについて理解を深めるために、次の例を考えてみましょう。 この例では、 OpenAI Platform トークナイザー (GPT4 の場合) を使用して推定される入力プロンプトとそのトークンを示します。 プロンプト テキストで強調表示されているトークンの下には、数値トークン ID の配列 (またはリスト) があります。

この例では、それぞれ異なる色の強調表示が 1 つのトークンを示しています。 前述のように、Azure OpenAI では サブワード トークン化が使用されるため、トークンは単語ではなく、文字でも固定文字数でもない。 たとえば 、"report" は 1 つのトークンですが、 "." も同じになります。
繰り返しになりますが、 Copilot (またはそのファブリックの容量消費率) のコストはトークンによって決まるため、トークンとは何かを理解する必要があります。 そのため、トークンとは何か、入力トークンと出力トークンがどのように作成されるかを理解することは、Copilot の使用によって Fabric CU がどのように消費されるかを理解し、予測するのに役立ちます。 Fabric での Copilot のコストの詳細については、この記事で後述する適切なセクションを参照してください。
次の図に示すように、Fabric の Copilot は入力トークンと出力トークンの両方を使用します。

Copilot は、次の 2 種類のトークンを作成します。
- 入力トークンは、 最終的なプロンプトとグラウンド データの両方をトークン化した結果です。
- 出力トークンは、 LLM 応答をトークン化した結果です。
一部の Copilot エクスペリエンスでは、複数の LLM 呼び出しが発生します。 たとえば、モデルとレポートに関するデータの質問をする場合、最初の LLM 応答はセマンティック モデルに対して評価されるクエリである可能性があります。 その後、Copilot はその評価されたクエリの結果を Azure OpenAI に再度送信し、概要を要求します。この概要は、Azure OpenAI が別の応答で返します。 これらの追加の LLM 呼び出しが処理され、後処理手順中に LLM 応答が結合される場合があります。
注
Fabric の Copilot では、入力プロンプトの変更を除き、セマンティック モデルで列を非表示にしたり、レポート内のビジュアルまたはページの数を減らしたりなど、関連する項目の構成を調整することによってのみ、入力トークンと出力トークンを最適化できます。 Copilot によって Azure OpenAI に送信される前に、グラウンド データをインターセプトまたは変更することはできません。
処理を理解する
Azure OpenAI の LLM がデータを処理して出力を生成する方法を理解しておくことが重要です。そのため、Copilot から特定の出力を取得する理由と、さらに使用または意思決定を行う前に、それらを批判的に評価する必要がある理由を理解しやすくなります。
注
この記事では、Copilot が使用する LLM (GPO など) の動作の概要を簡単に説明します。 技術的な詳細と、GPT モデルが入力を処理して応答を生成する方法、またはそのアーキテクチャについて詳しく理解するには、Ashish Vaswani などの研究論文 「要注意 (2017 年)」を参照し、言語モデルは Tom Brown などの Few-Shot Learners (2020) です。
Copilot (および LLM 全般) の目的は、ユーザーが提供する入力とその他の関連する接地データに基づいて、コンテキストに適した有用な出力を提供することです。 LLM は、トレーニング データで見られるように、同様のコンテキストでトークンの意味を解釈することによってこれを行います。 トークンの意味のあるセマンティックな理解を得るために、LLM は 、著作権で保護されたドメイン情報とパブリック ドメイン情報の両方を構成すると考えられる大規模なデータセットに対してトレーニングされています。 ただし、このトレーニング データはコンテンツの鮮度、品質、スコープの観点から制限されており、LLM と、それらを使用するツール (Copilot など) に制限が生まれます。 これらの制限の詳細については、この記事で後述 する「Copilot と LLM の制限事項 について」を参照してください。
トークンのセマンティックな意味は、 埋め込みと呼ばれる数学的コンストラクトでキャプチャされ、トークンを実数の高密度ベクトルに変換します。 より簡単な用語では、埋め込みによって、LLM は、その周囲の他のトークンに基づいて、特定のトークンのセマンティック意味を提供します。 この意味は、LLM トレーニング データによって異なります。 トークンは一意の構成要素と考えますが、埋め込みは LLM がいつどのブロックを使用するかを知るのに役立ちます。
トークンと埋め込みを使用して、Azure OpenAI の LLM によって入力が処理され、応答が生成されます。 この処理は、コストの発生元となる大量のリソースを必要とする計算負荷の高いタスクです。 LLM は一度に 1 つのトークンに応答を生成し、入力コンテキストに基づいて計算された確率を使用して各トークンを選択します。 生成された各トークンは、次のトークンを生成する前にその既存のコンテキストにも追加されます。 したがって、LLM の最終的な応答は常にテキストである必要があります。これは、Copilot が後で後でユーザーにとってより有用な出力を行うために後で処理する可能性があります。
この生成された応答に関するいくつかの重要な側面を理解することが重要です。
- これは非決定論的です。同じ入力によって異なる応答が生成される場合があります。
- ユーザーのコンテキストでは、低品質または不正と解釈できます。
- これは LLM トレーニング データに基づいており、その範囲は有限であり、制限されています。
Copilot と LLM の制限事項を理解する
Copilot の制限事項と、それを使用する基盤となるテクノロジを理解し、確認することが重要です。 これらの制限事項を理解することは、Copilot から価値を得る一方で、使用に固有のリスクを軽減するのに役立ちます。 Fabric で Copilot を効果的に使用するには、このテクノロジに最適なユース ケースとシナリオを理解する必要があります。
Fabric で Copilot を使用する場合は、次の考慮事項に留意することが重要です。
Fabric の Copilot は非決定論的です。 プロンプトとその出力がキャッシュされる場合を除き、同じ入力によって異なる出力が生成される可能性があります。 レポート ページ、コード パターン、概要など、さまざまな出力を受け入れる場合、これは問題の少なくなります。これは、応答に対して許容でき、さまざまなことが予想される場合があるためです。 ただし、正しい回答が 1 つだけ必要なシナリオでは、Copilot に代わるアプローチを検討することをお望みかもしれません。
Fabric の Copilot では、低品質または不正確な出力が生成される可能性があります。 すべての LLM ツールと同様に、Copilot では、正しくない、予想される、またはシナリオに適していない出力を生成できます。 つまり、機密性の高いデータやリスクの高い領域では、Fabric で Copilot を使用しないようにする必要があります。 たとえば、Copilot の出力を使用して、ビジネスクリティカルなプロセスに関するデータの質問に回答したり、個人や集団の幸福に影響を与える可能性のあるデータ ソリューションを作成したりしないでください。 ユーザーは、Copilot の出力を使用する前に確認して検証する必要があります。
Copilot は、"正確さ" または "真実性" を理解しません。 Copilot が提供する出力は、信頼性、信頼性、または同様のセンチメントを示していません。 基になるテクノロジにはパターン認識が含まれており、その出力の品質や有用性を評価することはできません。 ユーザーは、他の作業や意思決定でこれらの出力を使用する前に、出力を重大に評価する必要があります。
Copilot では、入力を超えて、意図を推論したり、意図を理解したり、コンテキストを知ったりすることはできません。 Copilot の接地プロセスでは、出力がより具体的であることを保証しますが、接地だけでは、自分の質問に答えるために必要なすべての情報を Copilot に提供することはできません。 たとえば、Copilot を使用してコードを生成する場合、Copilot はそのコードで何を行うかを知りません。 つまり、コードは 1 つのコンテキストで動作する可能性がありますが、別のコンテキストでは動作しない可能性があり、ユーザーはこれに対処するために出力またはプロンプトを変更する必要があります。
Copilot の出力は、使用する LLM のトレーニング データによって制限 されます。コードを生成する場合など、特定の Copilot エクスペリエンスでは、新しくリリースされた関数またはパターンを使用してコードを生成することが必要な場合があります。 ただし、Copilot は、使用する GPT モデルのトレーニング データに例がない場合、これを効果的に行うことはできません。これは、過去にカットオフが設定されています。 これは、Power BI Desktop で TMDL エディターで Copilot を使用する場合など、トレーニング データに疎なコンテキストに Copilot を適用しようとしたときにも発生します。 これらのシナリオでは、品質の低い出力や不正確な出力に対して特に注意深く、批判的である必要があります。
警告
これらの制限と考慮事項のリスクを軽減し、Copilot、LLM、およびジェネレーティブ AI が新しいテクノロジであるという事実を軽減するために、自律的、高リスク、またはビジネスクリティカルなプロセスと意思決定に Fabric で Copilot を使用 しないでください 。
詳細については、 LLM のセキュリティ ガイダンスを参照してください。
Azure OpenAI サービスは、入力を処理して応答を生成すると、この応答を Copilot への出力として返します。
手順 4: Copilot が出力に対して後処理を実行する
Azure OpenAI から応答を受け取ると、Copilot は追加の後処理を実行して、応答が適切であることを確認します。 後処理の目的は、不適切なコンテンツを除外することにあります。
後処理を実行するために、Copilot は次のタスクを実行する場合があります。
責任ある AI チェック: Copilot が Microsoft の責任ある AI 標準に準拠していることを確認します。 詳細については、「Copilot を責任を持って使用するために知っておくべきこと」を参照してください。
Azure コンテンツ モデレーションを使用したフィルター処理: 応答をフィルター処理して、Copilot がシナリオとエクスペリエンスに適した応答のみを返すようにします。 Copilot が Azure コンテンツ モデレーションを使用してフィルター処理を実行する方法の例を次に示します。
- 意図しない、または不適切な使用: コンテンツ モデレーションにより、使用しているワークロード、アイテム、エクスペリエンスの範囲外の他のトピックに関する質問など、意図しない方法や不適切な方法で Copilot を使用できなくなります。
- 不適切または不快な出力: Copilot は、許容できない言語、用語、または語句を含む可能性がある出力を防ぎます。
- プロンプト挿入の試行: Copilot は、ユーザーがセマンティック モデルのオブジェクト名、説明、コード コメントなど、データのグラウンド処理で破壊的命令を非表示にしようとするプロンプト挿入を防ぎます。
シナリオ固有の制約: 使用する Copilot エクスペリエンスによっては、出力を受け取る前に LLM 応答の追加のチェックと処理が行われる場合があります。 Copilot がシナリオ固有の制約を適用する方法の例を次に示します。
- コード パーサー: 生成されたコードはパーサーを通じて配置され、低品質の応答とエラーをフィルターで除外して、コードが確実に実行されるようにすることができます。 これは、Power BI Desktop の DAX クエリ ビューで Copilot を使用して DAX クエリを生成するときに発生します。
- ビジュアルとレポートの検証: Copilot は、ビジュアルとレポートを出力に返す前にレンダリングできることを確認します。 Copilot では、結果が正確か有用か、または結果のクエリがタイムアウト (およびエラーを生成) するかどうかは検証されません。
応答の処理と使用: 応答を取得し、追加情報を追加するか、他のプロセスで使用して出力をユーザーに提供します。 後処理中に Copilot が応答を処理して使用する方法の例を次に示します。
- Power BI レポート ページの作成: Copilot では、LLM 応答 (レポートビジュアル メタデータ) と他のレポート メタデータが組み合わせられます。その結果、新しいレポート ページが作成されます。 また、レポートにビジュアルをまだ作成していない場合は、 Copilot テーマ を適用することもできます。 テーマは LLM 応答の一部ではなく、背景イメージと、色とビジュアル スタイルが含まれています。 ビジュアルを作成した場合、Copilot は Copilot テーマを適用せず、既に適用したテーマを使用します。 レポート ページを変更すると、Copilot は既存のページも削除し、調整が適用された新しいページに置き換えます。
- Power BI データに関する質問: Copilot は、セマンティック モデルに対してクエリを評価します。
- Data Factory データフロー gen2 変換ステップの提案: Copilot は、新しいステップを挿入するように項目メタデータを変更し、クエリを調整します。
追加の LLM 呼び出し: 特定のシナリオでは、Copilot が追加の LLM 呼び出しを実行して出力をエンリッチする場合があります。 たとえば、Copilot は、評価されたクエリの結果を新しい入力として LLM に送信し、説明を要求する場合があります。 この自然言語の説明は、クエリ結果と共にパッケージ化され、ユーザーが Copilot チャット パネルに表示する出力になります。
出力でコンテンツが除外された場合、Copilot は新しいプロンプト、変更されたプロンプトを再送信するか、標準応答を返します。
新しいプロンプトを再送信します。 応答がシナリオ固有の制約を満たしていない場合、Copilot はもう一度やり直す変更されたプロンプトを生成します。 状況によっては、Copilot は、新しい出力を生成するプロンプトを送信する前に、ユーザーが選択するための新しいプロンプトをいくつか提案することがあります。
標準応答: この場合の標準応答は、一般的なエラーを示します。 シナリオによっては、Copilot が追加情報を提供して、ユーザーが別の入力を生成するように誘導する場合があります。
注
Azure OpenAI からの元のフィルター処理された応答を表示したり、Copilot からの標準応答や動作を変更したりすることはできません。 これは Microsoft によって管理されます。
後処理が完了すると、Copilot はユーザーに出力を返します。
手順 5: Copilot がユーザーに出力を返す
ユーザーの出力は、自然言語、コード、またはメタデータの形式をとることができます。 通常、このメタデータは、Copilot が Power BI ビジュアルを返したり、レポート ページを提案したりする場合など、Fabric または Power BI Desktop の UI でレンダリングされます。 Power BI エクスペリエンスの一部の Copilot では、ユーザーは Power BI モバイル アプリを介して Copilot に入力と出力の両方を提供できます。
一般に、出力は、ユーザーの介入を許可するか、完全に自律的に行い、ユーザーが結果を変更できないようにすることができます。
ユーザーの介入: これらの出力を使用すると、ユーザーは評価または表示する前に結果を変更できます。 ユーザーの介入を可能にする出力の例を次に示します。
- ユーザーが保持または実行を選択できる DAX クエリや SQL クエリなどのコードの生成。
- セマンティック モデルでのメジャーの説明の生成。ユーザーは保持、変更、または削除を選択できます。
自主的な: これらの出力は、ユーザーが変更することはできません。 コードが Fabric アイテムに対して直接評価される場合や、ウィンドウでテキストを編集できない場合があります。 自律出力の例を次に示します。
- Copilot チャット パネルのセマンティック モデルまたはレポートに関するデータの質問に回答します。このパネルでは、モデルに対するクエリが自動的に評価され、結果が表示されます。
- コード、項目、またはデータの概要または説明。集計と説明を自動的に選択し、結果を表示します。
- レポート ページの作成。レポートにページとビジュアルが自動的に作成されます。
場合によっては、出力の一部として、Copilot は、明確化の要求や別の提案など、追加のフォローアップ プロンプトを提案する場合もあります。 これは通常、生成されたコードを理解するための概念の説明のように、ユーザーが結果を改善したり、特定の出力に取り組み続けたりする場合に便利です。
Copilot からの出力には、低品質または不正確なコンテンツが含まれている可能性があります
Copilot には、出力の有用性や精度を評価または示す方法はありません。 そのため、Copilot を使用するときは常にユーザーが自分でこれを評価することが重要です。
Copilot における LLM の幻覚によるリスクや課題を軽減するには、次のアドバイスを検討してください。
LLM を活用する Copilot やその他の同様のツールを使用するようにユーザーをトレーニングします。 次のトピックでトレーニングすることを検討してください。
- Copilot ができることとできないこと。
- Copilot を使用する場合と使用しない場合。
- より適切なプロンプトを記述する方法。
- 予期しない結果をトラブルシューティングする方法。
- 信頼できるオンライン ソース、手法、またはリソースを使用して出力を検証する方法。
これらの項目を使用できるようにする前に、Copilot で項目をテストします。 特定の項目では、Copilot で適切に動作するように、特定の準備タスクが必要です。
自律的、高リスク、またはビジネスクリティカルな意思決定プロセスでは、Copilot を使用しないでください。
重要
さらに、 Fabric の補足プレビュー条項を確認します。これには、Microsoft Generative AI サービス プレビューの使用条件が含まれます。 これらのプレビュー機能を試して試すことができますが、運用ソリューションではプレビューで Copilot 機能を使用しないことをお勧めします。
プライバシー、セキュリティ、責任ある AI
Microsoft は、AI システムが AI の原則 と 責任ある AI Standard によって導かれることを保証することに取り組んでいます。 詳細な概要については 、「Fabric での Copilot のプライバシー、セキュリティ、責任ある使用 」を参照してください。 Azure OpenAI に固有の詳細については、Azure OpenAI サービスのデータ、プライバシー、セキュリティに関するページも参照してください。
各 Fabric ワークロードの概要については、次の記事を参照してください。
- Data Factory での責任ある使用
- データ サイエンスとデータ エンジニアリングでの責任ある使用
- データ ウェアハウスでの責任ある使用
- Power BI での責任ある使用
- Real-Time インテリジェンスでの責任ある使用
Copilot in Fabric のコスト
他の Microsoft Copilots とは異なり、Fabric の Copilot では、ユーザーごとまたは容量ごとの追加ライセンスは必要ありません。 代わりに、Copilot in Fabric は、使用可能な Fabric 容量ユニット (CU) から使用します。 Copilot の消費率は、Fabric のさまざまなエクスペリエンスで使用する場合の入力と出力のトークンの数によって決まります。
ファブリック容量がある場合は、 従量課金制または予約済みインスタンスを使用しています。 どちらの場合も、Copilot の消費量は同じように動作します。 従量課金制のシナリオでは、容量を一時停止するまで容量がアクティブである 1 秒単位で課金されます。 課金レートは、Fabric CU の使用状況と関係がありません。容量が完全に使用されているか、完全に使用されていない場合は、同じ金額を支払います。 そのため、Copilot には、Azure の課金に直接のコストや影響はありません。 代わりに、Copilot は、他の Fabric ワークロードや項目も共有する利用可能な CU を消費します。使いすぎると、ユーザーのパフォーマンスが低下し、制限がかかります。 繰越と呼ばれる CU 債務の状態を入力することもできます。 調整と繰り越しの詳細については、「スロットル トリガーとスロットル ステージ」を参照してください。
次のセクションでは、Fabric での Copilot の消費を理解して管理する方法について詳しく説明します。
注
詳細については、「Copilot in Fabric 消費量」を参照してください。
Fabric での Copilot の使用量はトークンによって決まります
Copilot は、使用可能なファブリック CU (一般に 容量、 コンピューティング、または リソースとも呼ばれます) を使用します。 消費は、使用する際の入力トークンと出力トークンによって決まります。 確認するには、次のトークン化の結果として、入力トークンと出力トークンを理解できます。
- 入力トークン: 書き込まれたプロンプトとグラウンド データのトークン化。
- 出力トークン: 入力に基づく Azure OpenAI 応答のトークン化。 出力トークンは、 入力トークンの 3 倍のコストがかかります。
短いプロンプトを使用して入力トークンの数を制限できますが、Copilot が前処理に使用するグラウンド データや、Azure OpenAI の LLM が返す出力トークンの数を制御することはできません。 たとえば、Power BI の Copilot の レポート作成エクスペリエンス は、(モデル スキーマのような) 接地データを使用し、詳細出力 (レポート メタデータ) を生成する可能性があるため、高い消費率を持つことが期待できます。
入力、出力、および接地データはトークンに変換されます
この記事の前のセクションで繰り返し説明するには、どの種類の入力と出力が最も高い消費量を生成するかを把握できるように 、トークン化プロセス を理解することが重要です。
プロンプト トークンを最適化することは、Copilot のコストに大きな影響を与える可能性はありません。 たとえば、書き込まれたユーザー プロンプト内のトークンの数は、通常、グラウンド データと出力のトークンよりもはるかに小さくなります。 Copilotは接地データと出力を自律的に処理します。これらのトークンを最適化したり、影響を与えたりすることはできません。 たとえば、Power BI で Copilot を使用する場合、Copilot では、セマンティック モデルのスキーマまたはレポートのメタデータを前処理中のグラウンド データとして使用できます。 このメタデータは、最初のプロンプトよりも多くのトークンで構成される可能性があります。
Copilot は、入力トークンと出力トークンを減らすために、さまざまなシステム最適化を実行します。 これらの最適化は、使用している Copilot エクスペリエンスによって異なります。 システム最適化の例を次に示します。
スキーマの削減: Copilot は、セマンティック モデルまたは lakehouse テーブルのスキーマ全体を送信しません。 代わりに、埋め込みを使用して送信する列を決定します。
プロンプト拡張: 前処理中にプロンプトを書き直すと、Copilot は、より具体的な結果を返す最終的なプロンプトを生成しようとします。
さらに、Copilot が見て使用できる接地データを制限するために実装できるさまざまなユーザー最適化があります。 これらのユーザーの最適化は、使用している項目とエクスペリエンスによって異なります。 ユーザーの最適化の例を次に示します。
セマンティック モデルでフィールドを非表示にするか、テーブルを プライベート としてマークする: 非表示オブジェクトまたはプライベート オブジェクトは、Copilot では考慮されません。
レポート ページまたはビジュアルを非表示にする: 同様に、レポート ブックマークの背後に非表示になっている非表示のレポート ページやビジュアルも、Copilot では考慮されません。
ヒント
ユーザーの最適化は主に、Copilot のコストを最適化するのではなく、Copilot 出力の有用性を向上させるために効果的です。 詳細については、さまざまなワークロードと Copilot エクスペリエンスに固有の記事を参照してください。
トークン化プロセスの可視性がなく、入力トークンと出力トークンにのみ影響を与えることができます。 そのため、Copilot の使用量を管理し、 調整 を回避するための最も効果的な方法は、Copilot の使用を管理することです。
Copilot は、スムーズ化されたバックグラウンド操作です
Fabric での Copilot の同時使用 (多くの個人が同時に使用している場合) は、 スムージングと呼ばれるプロセスによって処理されます。 Fabric では、 バックグラウンド操作 として分類された操作の CU 消費量は、操作の時刻からちょうど 24 時間後まで、24 時間の期間で分割されます。 これは、平準化されていない Power BI レポートを使用する個人からのセマンティック モデル クエリなどの 対話型操作とは対照的です。
注
理解を簡素化するために、バックグラウンド操作と対話型操作は、Fabric で発生するさまざまなことを課金目的で分類します。 名前からわかるように、項目または機能が "ユーザーに対して対話型" であるか、"バックグラウンドで行われている" かに必ずしも関連しているとは限りません。
たとえば、バックグラウンド操作で 48 個の CU を使用すると、現在は 2 CU、現在から 24 時間まで 1 時間ごとに 2 CU が消費されます。 対話型操作で 48 個の CU を使用すると、現在使用されている 48 個の CU が観察され 、 将来の消費には影響しません。 ただし、スムージングは、Copilot または他の Fabric ワークロードの使用率が十分に高い場合に、 そのウィンドウに CU 消費量が蓄積される可能性があることを意味します。
スムーズ化とその Fabric CU 消費量への影響をより深く理解するには、次の図を検討してください。

この図は、対話型操作の同時使用が多いシナリオの例を示しています (これはスムーズではありません)。 対話型操作は、調整の制限 (使用可能なファブリック容量) を超え、繰り越しを開始します。 これは、スムージングなしのシナリオです。 対照的に、Copilot のようなバックグラウンド操作では、消費量が 24 時間にわたって分散しています。 その 24 時間以内の後続の操作は"スタック" され、その期間の累積消費量の合計に寄与します。 この例の平滑化されたシナリオでは、Copilot のようなバックグラウンド操作は将来の CU 消費に寄与しますが、調整をトリガーしたり、制限を超えたりすることはありません。
Fabric での Copilot 消費量の監視
ファブリック管理者は、 Microsoft Fabric Capacity Metrics アプリを使用して、Fabric 容量で発生している Copilot 消費量を監視できます。 このアプリでは、Fabric 管理者はアクティビティとユーザー別に内訳を表示でき、高消費期間中に集中する必要がある可能性がある個人と領域を特定するのに役立ちます。
ヒント
CU へのトークンなどの抽象計算を検討するのではなく、使用した Fabric 容量の割合 に注目することをお勧めします。 このメトリックは、100% 利用率に達すると 制限が発生する可能性があるため、理解して対処するのが最も簡単です。
この情報は、 アプリのタイムポイント ページで確認できます。
注
容量を一時停止すると、スムーズな使用は、容量が一時停止するタイムポイントに圧縮されます。 この平滑化された消費量の圧縮により、実際の使用量が反映されない、観察された消費量のピークが発生します。 多くの場合、このピーク時には、使用可能な Fabric 容量を使い果たしたという通知と警告が生成されますが、これらは誤検知です。
高い使用率と調整を軽減する
Copilot は Fabric CU を消費します。スムージングを行っても、使用率が高い状況になる可能性があります。これにより、消費量が増え、他の Fabric ワークロードの調整が生じる可能性があります。 次のセクションでは、このシナリオでの Fabric 容量への影響を軽減するために使用できるいくつかの戦略について説明します。
ユーザー トレーニングと許可リスト
ツールの効果的な導入を確実にする重要な方法は、ユーザーに十分なメンタリングとトレーニングを提供し、ユーザーがそのようなトレーニングを完了するにつれて徐々にアクセスをロールアウトすることです。 効果的なトレーニングは、Copilot を効果的に使用する方法と何をしないかについてユーザーに教育することで、高い使用率と調整を先取りして回避するための予防措置です。
Fabric テナント設定から機能にアクセスできるユーザーの 許可リスト を作成することで、Fabric で Copilot を使用できるユーザーを最適に制御できます。 つまり、Fabric で Copilot を有効にできるのは、特定のセキュリティ グループに属しているユーザーに対してのみです。 必要に応じて、ファブリック ワークロードごとに個別のセキュリティ グループを作成できます。この場合、Copilot でどの Copilot エクスペリエンスを使用できるかをきめ細かく制御できます。 セキュリティ グループの作成の詳細については、「セキュリティ グループの 作成、編集、または削除」を参照してください。
Copilot テナント設定に特定のセキュリティ グループを追加したら、ユーザー向けのオンボード トレーニングをまとめることができます。 Copilot トレーニング コースでは、次のような基本的なトピックについて説明する必要があります。
ヒント
LLM と生成 AI に関する基本的な概念の概要トレーニングを作成し、ユーザー向けのワークロード固有のトレーニングを作成することを検討してください。 必ずしも関連がない場合、すべてのユーザーがすべての Fabric ワークロードについて学習する必要があるわけではありません。
LLM: LLM とは何か、およびそのしくみの基本について説明します。 技術的な詳細に進むべきではありませんが、プロンプト、グラウンド、トークンなどの概念を説明する必要があります。 また、LLM が入力から意味を得て、トレーニング データのためにコンテキストに適した応答を生成する方法を説明することもできます。 これをユーザーに教えることは、テクノロジのしくみと、その機能とできないことを理解するのに役立ちます。
Copilot やその他の生成 AI ツールは次の目的で使用されます。 Copilot は自律的なエージェントではなく、タスクで人間を置き換えることを意図したものではなく、現在のタスクをより適切かつ迅速に実行できるように個人を強化することを目的としていることを説明する必要があります。 また、特定の例を使用して、Copilot が適さないケースを強調し、それらのシナリオでの問題に対処するために個人が使用する可能性のある他のツールや情報について説明する必要があります。
Copilot の出力を批判的に適用する方法: Copilot の出力を検証する方法についてユーザーをガイドすることが重要です。 この検証は、使用している Copilot エクスペリエンスによって異なりますが、一般的には、次の点を強調する必要があります。
- 使用する前に、各出力を確認してください。
- 出力が正しいかどうかを評価し、自分に問い合わせてください。
- 生成されたコードにコメントを追加して、そのしくみを理解します。 または、必要に応じてそのコードの説明を Copilot に依頼し、信頼できるソースでその説明を相互参照します。
- 出力で予期しない結果が発生した場合は、さまざまなプロンプトを使用して、または手動検証を実行してトラブルシューティングを行います。
LLM と生成 AI のリスクと制限事項: Copilot、LLM、およびジェネレーティブ AI の主なリスクと制限事項について説明する必要があります(この記事で説明するものなど)。
- これらは非決定論的です。
- 正確さ、信頼性、または真実性を示したり保証したりしません。
- これらは、不正確または低品質の出力を幻覚させ、生成する可能性があります。
- トレーニング データの範囲外の情報を生成することはできません。
Copilot in Fabric を見つける場所: 他のユーザーが使用する可能性があるさまざまなワークロード、項目、および Copilot エクスペリエンスの概要を示します。
容量をスケーリングする
Copilot の消費量やその他の操作によって Fabric で調整が発生した場合は、上位の SKU に容量を一時的にスケーリング (またはサイズ変更) することができます。 これは、スロットリングまたは繰り越しによる短期的な問題を軽減するためにコストを一時的に上げる反応的な措置です。 これは、消費 (およびそれによる影響) が 24 時間にわたって広がる可能性があるため、主にバックグラウンド操作による調整が発生する場合に特に役立ちます。
分割キャパシティ戦略
(大規模な組織など) Fabric で Copilot の使用率が高くなるシナリオでは、他の Fabric ワークロードから Copilot の消費量を分離することを検討できます。 この分割容量シナリオでは、専用の Copilot エクスペリエンスにのみ使用する別の F64 以上の SKU でのみ Copilot を有効にすることで、Copilot の消費が他のファブリック ワークロードに悪影響を与えないようにします。 この分割容量戦略ではコストが高くなりますが、Copilot の使用状況の管理と管理が容易になる場合があります。
ヒント
Copilot をサポートまたは有効化していない他の容量の項目で、何らかの Copilot エクスペリエンスを使用できます。 たとえば、Power BI Desktop では、F64 SKU Fabric 容量を持つワークスペースにリンクした後、F2 または PPU ワークスペースのセマンティック モデルに接続できます。 その後、Power BI Desktop で Copilot エクスペリエンスを使用でき、Copilot の使用量は F64 SKU にのみ影響します。
次の図は、Power BI Desktop の Copilot のようなエクスペリエンスで Copilot の消費量を分離するための分割容量戦略の例を示しています。

また、Copilot の使用量を別の容量に割り当てることで、分割容量ソリューションを使用することもできます。 Copilot の使用量を別の容量に割り当てると、Copilot の使用率が高く、他の Fabric ワークロードやそれらに依存するビジネス クリティカルなプロセスに影響を与えることはありません。 もちろん、分割容量戦略を使用するには、既に 2 つ以上の F64 以上の SKU が必要です。 そのため、この戦略は、データ プラットフォームに費やす予算が限られている小規模な組織や組織では管理できない可能性があります。
Copilot の管理方法に関係なく、最も重要なのは、ファブリック容量で Copilot の消費量を監視することです。