この記事では、IT プロフェッショナルと IT マネージャーを対象にしています。 COE の BI ソリューション アーキテクチャと、採用されているさまざまなテクノロジについて学習します。 テクノロジには、Azure、Power BI、Excel が含まれます。 これらを組み合わせることで、スケーラブルでデータドリブンなクラウド BI プラットフォームを提供できます。
堅牢な BI プラットフォームの設計は、ブリッジの構築に似ています。変換およびエンリッチされたソース データをデータ コンシューマーに接続するブリッジ。 このような複雑な構造の設計にはエンジニアリングの考え方が必要ですが、設計できる最も創造的でやりがいのある IT アーキテクチャの 1 つです。 大規模な組織では、BI ソリューション アーキテクチャは次で構成できます。
- データ ソース
- データ インジェスト
- ビッグ データ/データ準備
- データ ウェアハウス
- BI セマンティック モデル
- 報告書
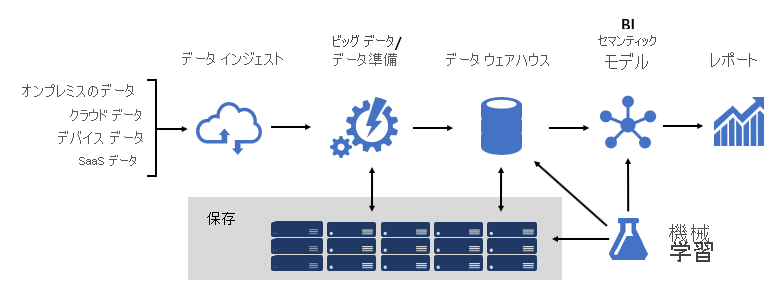
プラットフォームは、特定の要求をサポートする必要があります。 具体的には、ビジネス サービスとデータ コンシューマーの期待に合わせてスケーリングおよび実行する必要があります。 同時に、基礎から安全である必要があります。 また、変更に適応するには十分な回復力が必要です。これは、新しいデータと対象領域をオンラインにする必要があることは確実であるためです。
フレームワーク
Microsoft では当初から、フレームワーク開発に投資することでシステムに似たアプローチを採用しました。 技術的およびビジネス プロセスフレームワークは、設計とロジックの再利用を増やし、一貫した結果を提供します。 また、多くのテクノロジを活用したアーキテクチャの柔軟性も提供し、反復可能なプロセスによってエンジニアリングのオーバーヘッドを合理化および削減します。
適切に設計されたフレームワークにより、データ系列、影響分析、ビジネス ロジックのメンテナンス、分類の管理、ガバナンスの合理化の可視性が向上することを学習しました。 また、開発が速くなり、大規模なチーム間のコラボレーションの応答性と効果が向上しました。
この記事では、いくつかのフレームワークについて説明します。
データ モデル
データ モデルを使用すると、データの構造化とアクセス方法を制御できます。 ビジネス サービスとデータ コンシューマーにとって、データ モデルは BI プラットフォームとのインターフェイスです。
BI プラットフォームでは、次の 3 種類のモデルを提供できます。
- エンタープライズ モデル
- BI セマンティック モデル
- Machine Learning (ML) モデル
エンタープライズ モデル
エンタープライズ モデル は、IT アーキテクトによって構築および管理されます。 ディメンション モデルまたはデータ マートと呼ばれることもあります。 通常、データはリレーショナル形式でディメンション テーブルとファクト テーブルとして格納されます。 これらのテーブルには、多くのシステムから統合されたクレンジングおよびエンリッチメントされたデータが格納され、レポートと分析の権限のあるソースを表します。
エンタープライズ モデルは、レポートと BI 用の一貫性のある単一のデータ ソースを提供します。 これらは 1 回ビルドされ、企業標準として共有されます。 ガバナンス ポリシーにより、データがセキュリティで保護されるため、顧客情報や財務などの機密データ セットへのアクセスはニーズに応じて制限されます。 一貫性を確保する名前付け規則を採用しているため、データと品質の信頼性がさらに確立されます。
クラウド BI プラットフォームでは、エンタープライズ モデルを Azure Synapse の Synapse SQL プールにデプロイできます。 Synapse SQL プールは、組織が頼りにできる唯一の真実の情報源となり、迅速かつ堅牢な分析情報を提供します。
BI セマンティック モデル
BI セマンティック モデル は、エンタープライズ モデル上のセマンティック レイヤーを表します。 これらは、BI 開発者とビジネス ユーザーによって構築および管理されています。 BI 開発者は、エンタープライズ モデルからデータをソースとするコア BI セマンティック モデルを作成します。 ビジネス ユーザーは、小規模で独立したモデルを作成できます。また、部門または外部ソースを使用してコア BI セマンティック モデルを拡張することもできます。 BI セマンティック モデルは、一般的に 1 つのサブジェクト領域に焦点を当て、多くの場合、広く共有されます。
ビジネス機能は、データだけでなく、概念、リレーションシップ、ルール、標準を記述する BI セマンティック モデルによって有効になります。 これにより、データ リレーションシップを定義し、ビジネス ルールを計算としてカプセル化する、直感的でわかりやすい構造が表されます。 また、きめ細かいデータアクセス許可を適用して、適切なユーザーが適切なデータにアクセスできるようにすることもできます。 重要なのは、クエリのパフォーマンスを高速化し、テラバイトを超えるデータであっても、非常に応答性の高い対話型分析を提供することです。 エンタープライズ モデルと同様に、BI セマンティック モデルでは、一貫性を確保する名前付け規則が採用されています。
クラウド BI プラットフォームでは、BI 開発者は、Microsoft Fabric容量の Power BI Premium 容量である Azure Analysis Services に BI セマンティック モデルをデプロイできます。
Von Bedeutung
この記事では、Power BI Premium またはその容量サブスクリプション (P SKU) について説明します。 現在、Microsoft は購入オプションを統合し、容量ごとの Power BI Premium SKU を廃止しています。 新規および既存のお客様は、代わりに Fabric 容量サブスクリプション (F SKU) の購入をご検討ください。
詳細については、「Power BI Premium ライセンスに関する重要な更新」と「Power BI Premium のよく寄せられる質問」を参照してください。
レポートおよび分析レイヤーとして使用される場合は、Power BI にデプロイすることをお勧めします。 これらの製品では、さまざまなストレージ モードがサポートされており、データ モデル テーブルでデータをキャッシュしたり、基になるデータ ソースにクエリを渡すテクノロジである DirectQuery を使用したりできます。 DirectQuery は、モデル テーブルが大量のデータを表す場合や、ほぼリアルタイムの結果を提供する必要がある場合に理想的なストレージ モードです。 2 つのストレージ モードを組み合わせることができます。 複合モデル は、1 つのモデルで異なるストレージ モードを使用するテーブルを結合します。
クエリが多いモデルの場合、 Azure Load Balancer を 使用して、モデル レプリカ間でクエリ負荷を均等に分散できます。 また、アプリケーションをスケーリングし、高可用性 BI セマンティック モデルを作成することもできます。
機械学習モデル
Machine Learning (ML) モデル は、データ サイエンティストによって構築および管理されます。 これらは主に、データ レイク内の生のソースから開発されています。
トレーニング済みの ML モデルでは、データ内のパターンを明らかにできます。 多くの場合、これらのパターンを使用して、データのエンリッチメントに使用できる予測を行うことができます。 たとえば、購入行動を使用して、顧客離れを予測したり、顧客をセグメント化したりできます。 予測結果をエンタープライズ モデルに追加して、顧客セグメント別の分析を可能にすることができます。
クラウド BI プラットフォームでは、 Azure Machine Learning を使用して、ML モデルのトレーニング、デプロイ、自動化、管理、追跡を行うことができます。
データ ウェアハウス
BI プラットフォームの中核となるのは、エンタープライズ モデルをホストするデータ ウェアハウスです。 これは、レポート、BI、およびデータ サイエンス用のエンタープライズ モデルを提供する、記録のシステムとして、ハブとして承認されたデータのソースです。
基幹業務 (LOB) アプリケーションを含む多くのビジネス サービスは、エンタープライズナレッジの権限のある管理されたソースとしてデータ ウェアハウスに依存できます。
Microsoft では、データ ウェアハウスは Azure Data Lake Storage Gen2 (ADLS Gen2) と Azure Synapse Analytics でホストされています。
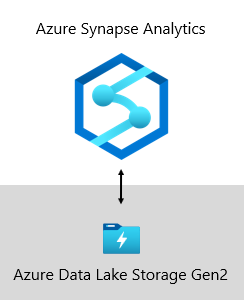
- ADLS Gen2 は、Azure Storage を Azure 上にエンタープライズ データ レイクを構築するための基盤となります。 それは、数百ギガビットのスループットを維持しながら、数ペタバイトの情報を提供するように設計されています。 また、低コストのストレージ容量とトランザクションを提供します。 さらに、Hadoop と互換性のあるアクセスがサポートされており、Hadoop 分散ファイル システム (HDFS) と同様にデータを管理およびアクセスできます。 実際、 Azure HDInsight、 Azure Databricks、Azure Synapse Analytics は、ADLS Gen2 に格納されているすべてのデータにアクセスできます。 そのため、BI プラットフォームでは、生のソース データ、半処理またはステージング データ、運用対応データを格納することをお勧めします。 すべてのビジネス データを格納するために使用します。
- Azure Synapse Analytics は、エンタープライズ データ ウェアハウスとビッグ データ分析を統合する分析サービスです。 サーバーレスオンデマンドまたはプロビジョニングされたリソースを柔軟に活用して、大規模にデータを自在に照会できます。 Azure Synapse Analytics のコンポーネントである Synapse SQL は、完全な T-SQL ベースの分析をサポートしているため、ディメンションとファクト テーブルで構成されるエンタープライズ モデルをホストするのが理想的です。 単純な Polybase T-SQL クエリを使用して、ADLS Gen2 からテーブルを効率的に読み込むことができます。 その後、高パフォーマンス分析を実行する MPP の機能が得られます。
ビジネス規則エンジンフレームワーク
データ ウェアハウス レイヤーに実装できるビジネス ロジックをカタログ化するためのビジネス ルール エンジン (BRE) フレームワークを開発しました。 BRE は多くのことを意味しますが、データ ウェアハウスのコンテキストでは、リレーショナル テーブルで計算列を作成する場合に便利です。 これらの計算列は、通常、条件付きステートメントを使用して数学的な計算または式として表されます。
この目的は、ビジネス ロジックをコア BI コードから分割することです。 従来、ビジネス ルールは SQL ストアド プロシージャにハードコーディングされているため、多くの場合、ビジネス ニーズが変化したときにそれらを維持するために多くの労力が必要になります。 BRE では、ビジネス ルールは 1 回定義され、異なるデータ ウェアハウス エンティティに適用されるときに複数回使用されます。 計算ロジックを変更する必要がある場合は、多数のストアド プロシージャではなく、1 か所でのみ更新する必要があります。 また、BRE フレームワークによって、実装されたビジネス ロジックの透明性と可視性が促進され、自己更新ドキュメントを作成する一連のレポートを介して公開されるという利点もあります。
データ ソース
データ ウェアハウスは、実質的にあらゆるデータ ソースのデータを統合できます。 これは主に LOB データ ソース上に構築されています。これは、一般的に、販売、マーケティング、財務などの対象固有のデータを格納するリレーショナル データベースです。これらのデータベースは、クラウドでホストすることも、オンプレミスに配置することもできます。 その他のデータ ソースは、ファイル ベース、特にデバイスからソース化された Web ログまたは IOT データである場合があります。 さらに、データはサービスとしてのソフトウェア (SaaS) ベンダーから入手できます。
Microsoft では、一部の内部システムは、未加工のファイル形式を使用して、運用データを ADLS Gen2 に直接出力します。 データ レイクに加えて、他のソース システムは、リレーショナル LOB アプリケーション、Excel ブック、その他のファイル ベースのソース、マスター データ管理 (MDM) とカスタム データ リポジトリで構成されます。 MDM リポジトリを使用すると、マスター データを管理して、権限のある標準化された検証済みのバージョンのデータを確保できます。
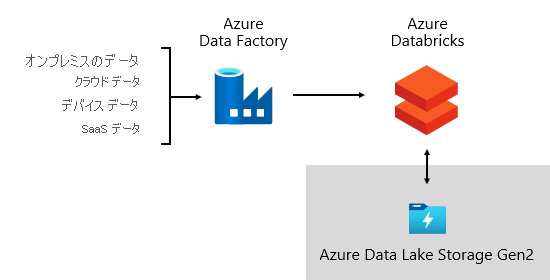
データ インジェスト
定期的に、ビジネスのリズムに従って、データはソース システムから取り込まれ、データ ウェアハウスに読み込まれます。 1 日に 1 回、またはより頻繁な間隔で指定できます。 データ インジェストは、データの抽出、変換、読み込みに関係します。 または、データの抽出、読み込み、変換などの逆の方法があります。 変換が行われる場所が違いを生むのです。 変換は、データのクレンジング、準拠、統合、標準化に適用されます。 詳細については、「 抽出、変換、読み込み (ETL)」を参照してください。
最終的には、適切なデータを可能な限り迅速かつ効率的にエンタープライズ モデルに読み込むのが目標です。
Microsoft では、 Azure Data Factory (ADF) を使用しています。 このサービスは、外部ソース システムからデータ レイクへのデータ検証、変換、一括読み込みをスケジュールおよび調整するために使用されます。 データを並列かつ大規模に処理するカスタム フレームワークによって管理されます。 さらに、トラブルシューティング、パフォーマンスの監視をサポートし、特定の条件が満たされたときにアラート通知をトリガーするために、包括的なログ記録が実行されます。
一方、 Azure Databricks は、Azure クラウド サービス プラットフォーム用に最適化された Apache Spark ベースの分析プラットフォームであり、データ サイエンス専用の変換を実行します。 また、Python ノートブックを使用して ML モデルをビルドして実行します。 これらの ML モデルのスコアは、予測をエンタープライズ アプリケーションやレポートと統合するためにデータ ウェアハウスに読み込まれます。 Azure Databricks はデータ レイク ファイルに直接アクセスするため、データのコピーや取得の必要性を排除または最小限に抑えます。
インジェスト フレームワーク
一連の構成テーブルと手順として インジェスト フレームワーク を開発しました。 これは、高速かつ最小限のコードで大量のデータを取得するためのデータドリブン アプローチをサポートします。 つまり、このフレームワークにより、データ ウェアハウスを読み込むデータ取得プロセスが簡略化されます。
フレームワークは、ソースの種類、サーバー、データベース、スキーマ、テーブル関連の詳細など、データ ソースとデータ変換先に関連する情報を格納する構成テーブルに依存します。 この設計アプローチは、特定の ADF パイプラインや SQL Server Integration Services (SSIS) パッケージを開発する必要がないようにすることを意味します。 代わりに、実行時に動的に生成および実行される ADF パイプラインを作成するために、プロシージャは選択した言語で記述されます。 そのため、データの取得は、簡単に運用可能な構成演習になります。 従来、ハードコーディングされた ADF または SSIS パッケージを作成するには、広範な開発リソースが必要です。
インジェスト フレームワークは、アップストリームのソース スキーマの変更を処理するプロセスも簡略化するように設計されています。 ソース システムで新しく追加された属性を取得するためにスキーマの変更が検出された場合は、構成データを手動または自動で簡単に更新できます。
オーケストレーション フレームワーク
データ パイプラインを運用化および調整するための オーケストレーション フレームワーク を開発しました。 オーケストレーション フレームワークは、一連の構成テーブルに依存するデータ ドリブン設計を使用します。 これらのテーブルには、パイプラインの依存関係と、ソース データをターゲット データ構造にマップする方法を説明するメタデータが格納されます。 この適応型フレームワークの開発への投資は、すでに元が取れています。各データ移動をハードコーディングする必要はなくなりました。
データ ストレージ
Data Lake は、後でステージング データ変換と共に使用するために、大量の生データを格納できます。
Microsoft では、単一の情報源として ADLS Gen2 を使用しています。 生データは、ステージングデータおよび運用準備が整ったデータと共に格納されます。 ビッグ データ分析用に、拡張性とコスト効率に優れたデータ レイク ソリューションを提供します。 ハイ パフォーマンス ファイル システムの機能と大規模なスケールを組み合わせることで、データ分析ワークロードに最適化され、分析情報を得る時間が短縮されます。
ADLS Gen2 は、BLOB ストレージと高パフォーマンスのファイル システム名前空間という 2 つの長所を提供します。この名前空間は、きめ細かいアクセス許可で構成します。
その後、洗練されたデータはリレーショナル データベースに格納され、セキュリティ、ガバナンス、管理容易性を備えた、エンタープライズ モデル向けの高パフォーマンスで拡張性の高いデータ ストアを提供します。 サブジェクト固有のデータ マートは、Azure Synapse Analytics に格納されます。これは、Azure Databricks または Polybase T-SQL クエリによって読み込まれます。
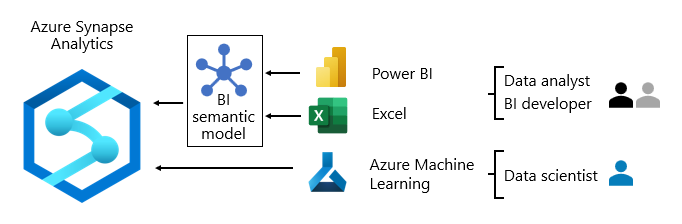
データの使用
レポート レイヤーでは、ビジネス サービスはデータ ウェアハウスからソース化されたエンタープライズ データを使用します。 また、アドホック分析またはデータ サイエンス タスクのために、データ レイク内のデータに直接アクセスします。
詳細なアクセス許可は、データ レイク、エンタープライズ モデル、BI セマンティック モデルなど、すべてのレイヤーで適用されます。 アクセス許可により、データ コンシューマーはアクセス権を持つデータのみを表示できます。
Microsoft では、Power BI レポートとダッシュボード、および Power BI のページ分割されたレポートを使用します。 一部のレポートとアドホック分析は、特に財務レポート用に Excel で実行されます。
データ モデルに関する参照情報を提供するデータ ディクショナリを発行します。 ユーザーが BI プラットフォームに関する情報を見つけることができるように、ユーザーが利用できるようになります。 ディクショナリは、エンティティ、形式、構造、データ系列、リレーションシップ、計算に関する説明を提供するモデル 設計を文書化します。 Azure Data Catalog を使用して、データ ソースを簡単に検出して理解できるようにします。
通常、データ消費パターンはロールによって異なります。
- データ アナリストは、 コア BI セマンティック モデルに直接接続します。 コア BI セマンティック モデルに必要なすべてのデータとロジックが含まれている場合、ライブ接続を使用して Power BI レポートとダッシュボードを作成します。 部門別データを使用してモデルを拡張する必要がある場合は、Power BI 複合モデルを作成します。 スプレッドシート スタイルのレポートが必要な場合は、Excel を使用して、コア BI セマンティック モデルまたは部門別 BI セマンティック モデルに基づいてレポートを生成します。
- BI 開発者 と運用レポート作成者は、エンタープライズ モデルに直接接続します。 Power BI Desktop を使用して、ライブ接続分析レポートを作成します。 また、運用型の BI レポートを Power BI のページ分割されたレポートとして作成したり、T-SQL を使用して Azure Synapse Analytics エンタープライズ モデルのデータにアクセスするためのネイティブ SQL クエリを記述したり、DAX または MDX を使用して Power BI セマンティック モデルを作成したりすることもできます。
- データ サイエンティストは、 Data Lake 内のデータに直接接続します。 Azure Databricks と Python ノートブックを使用して ML モデルを開発します。ML モデルは、多くの場合、試験的であり、運用環境で使用するために特別なスキルが必要です。
関連コンテンツ
この記事の詳細については、次のリソースを参照してください。
- ファブリック導入ロードマップ: センター オブ エクセレンス
- Azure Synapse Analytics を使用した Azure のエンタープライズ BI
- 質問がありますか? Fabric コミュニティに問い合わせしてみてください
- ご提案はありますか? Fabric の を向上させるためにアイデアを投稿する
プロフェッショナル サービス
認定 Power BI パートナーは、COE の設定時に組織の成功を支援するために使用できます。 コスト効率の高いトレーニングやデータの監査を提供できます。 Power BI パートナーを見つけるには、Microsoft Power BI パートナー ポータルにアクセスします。
経験豊富なコンサルティング パートナーと連携することもできます。 Power BI の査定、評価、または実装を手伝ってくれます。