데이터에 대한 Azure OpenAI
이 문서에서는 개발자가 엔터프라이즈 데이터를 보다 쉽게 연결, 수집 및 접지하여 개인화된 Copilot(미리 보기)을 빠르게 만들 수 있도록 하는 Azure OpenAI On Your Data에 대해 알아봅니다. 사용자 이해를 향상시키고, 작업 완료를 신속하게 처리하고, 운영 효율성을 향상시키고, 의사 결정을 지원합니다.
데이터에 대한 Azure OpenAI란?
Azure OpenAI On Your Data를 사용하면 모델을 학습하거나 미세 조정할 필요 없이 사용자 고유의 엔터프라이즈 데이터에서 GPT-35-Turbo 및 GPT-4와 같은 고급 AI 모델을 실행할 수 있습니다. 더 높은 정확도로 데이터를 기반으로 채팅하고 분석할 수 있습니다. 지정된 데이터 원본에서 사용할 수 있는 최신 정보를 기반으로 응답을 지원하는 원본을 지정할 수 있습니다. SDK 또는 Azure AI Foundry 포털의 웹 기반 인터페이스를 통해 REST API를 사용하여 Azure OpenAI On Your Data에 액세스할 수 있습니다. 데이터에 연결하는 웹앱을 만들어 향상된 채팅 솔루션을 사용하도록 설정하거나 Copilot Studio(미리 보기)에서 Copliot으로 직접 배포할 수도 있습니다.
Azure OpenAI On Your Data를 사용하여 개발
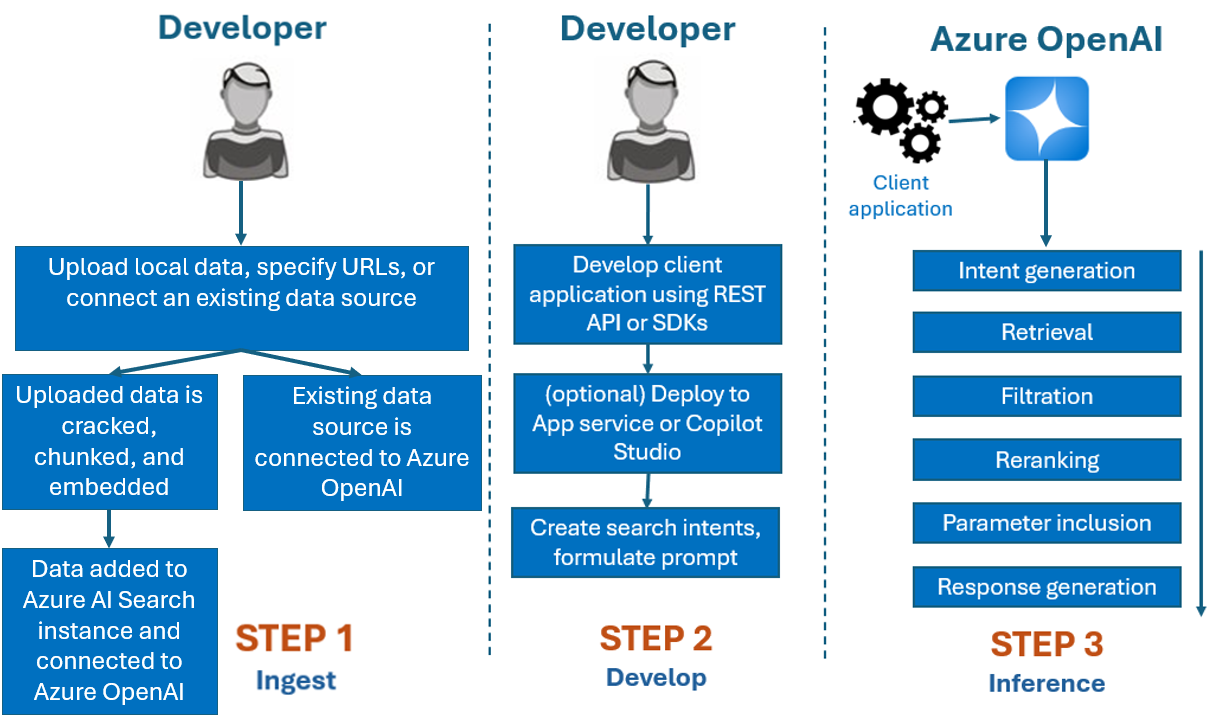
일반적으로 Azure OpenAI On Your Data에서 사용하는 개발 프로세스는 다음과 같습니다.
수집: Azure AI Foundry 포털 또는 수집 API를 사용하여 파일을 업로드합니다. 이렇게 하면 데이터를 Azure OpenAI 모델에서 사용할 수 있는 Azure AI Search 인스턴스에 크래킹, 청크 분할 및 포함할 수 있습니다. 기존 지원되는 데이터 원본이 있는 경우 직접 연결할 수도 있습니다.
개발: Azure OpenAI On Your Data를 시도한 후 여러 언어로 제공되는 사용 가능한 REST API 및 SDK를 사용하여 애플리케이션 개발을 시작합니다. Azure OpenAI 서비스에 전달할 프롬프트 및 검색 의도를 만듭니다.
추론: 애플리케이션이 기본 설정 환경에 배포된 후 응답을 반환하기 전에 Azure OpenAI에 프롬프트를 보내 여러 단계를 수행합니다.
의도 생성: 서비스는 적절한 응답을 확인하기 위해 사용자 프롬프트의 의도를 결정합니다.
검색: 서비스는 연결된 데이터 원본에서 쿼리하여 사용 가능한 데이터의 관련 청크를 검색합니다. 예를 들어 의미론적 검색 또는 벡터 검색을 사용하는 경우입니다. 검색할 문서 수 및 엄격성 등의 매개 변수 가 검색에 영향을 주는 데 사용됩니다.
필터링 및 재전송: 검색 단계의 검색 결과는 관련성을 구체화하기 위해 데이터의 순위를 지정하고 필터링하여 개선됩니다.
응답 생성: 결과 데이터가 LLM(대규모 언어 모델)에 시스템 메시지와 같은 다른 정보와 함께 제출되고 응답이 애플리케이션으로 다시 전송됩니다.
시작 하려면 Azure AI Foundry 포털을 사용하여 데이터 원본 을 연결하고 질문하고 데이터에 대한 채팅을 시작합니다.
데이터 원본을 추가하기 위한 Azure RBAC(Azure 역할 기반 액세스 제어)
Azure OpenAI On Your Data를 완전히 사용하려면 하나 이상의 Azure RBAC 역할을 설정해야 합니다. 자세한 내용은 Azure OpenAI On Your Data 구성을 참조하세요.
데이터 서식 및 파일 형식
Azure OpenAI On Your Data는 다음 파일 형식을 지원합니다.
.txt.md.html.docx.pptx.pdf
업로드 제한이 있으며 문서 구조 및 모델의 응답 품질에 미치는 영향에 대한 몇 가지 주의 사항이 있습니다.
지원되지 않는 형식에서 지원되는 형식으로 데이터를 변환하는 경우 변환을 확인하여 모델 응답의 품질을 최적화합니다.
- 데이터가 크게 손실되지는 않습니다.
- 데이터에 예기치 않은 노이즈를 추가하지 않습니다.
파일에 테이블, 열 또는 글머리 기호와 같은 특수 서식이 있는 경우 GitHub에서 사용할 수 있는 데이터 준비 스크립트를 사용하여 데이터를 준비합니다.
긴 텍스트가 있는 문서 및 데이터 세트의 경우 사용 가능한 데이터 준비 스크립트를 사용해야 합니다. 스크립트는 모델의 응답이 더 정확할 수 있도록 데이터를 청크합니다. 이 스크립트는 스캔한 PDF 파일 및 이미지도 지원합니다.
지원되는 데이터 원본
데이터를 업로드하려면 데이터 원본에 연결해야 합니다. 데이터를 사용하여 Azure OpenAI 모델과 채팅하려는 경우 사용자 쿼리에 따라 관련 데이터를 찾을 수 있도록 데이터가 검색 인덱스로 청크됩니다.
vCore 기반 Azure Cosmos DB for MongoDB의 통합 벡터 데이터베이스는 기본적으로 Azure OpenAI On Your Data와의 통합을 지원합니다.
로컬 컴퓨터에서 파일 업로드(미리 보기) 또는 Blob Storage 계정(미리 보기)에 포함된 데이터 업로드와 같은 일부 데이터 원본의 경우 Azure AI Search가 사용됩니다. 다음 데이터 원본을 선택하면 데이터가 Azure AI Search 인덱스에 수집됩니다.
| Azure AI 검색을 통해 수집된 데이터 | 설명 |
|---|---|
| Azure AI 검색 | Azure OpenAI On Your Data에서 기존 Azure AI Search 인덱스 사용 |
| 파일 업로드(미리 보기) | 로컬 컴퓨터에서 파일을 업로드하여 Azure Blob Storage 데이터베이스에 저장하고 Azure AI Search에 수집합니다. |
| URL/웹 주소(미리 보기) | URL의 웹 콘텐츠는 Azure Blob Storage에 저장됩니다. |
| Azure Blob Storage(미리 보기) | Azure Blob Storage에서 파일을 업로드하여 Azure AI Search 인덱스로 수집합니다. |

- Azure AI 검색
- Azure Cosmos DB for MongoDB의 벡터 데이터베이스
- Azure Blob Storage(미리 보기)
- 파일 업로드(미리 보기)
- URL/웹 주소(미리 보기)
- Elasticsearch (미리 보기)
- MongoDB Atlas(미리 보기)
다음 중 하나를 원할 때 Azure AI Search 인덱스 사용을 고려할 수 있습니다.
- 인덱스 만들기 프로세스를 사용자 지정합니다.
- 다른 데이터 원본에서 데이터를 수집하여 이전에 만든 인덱스를 다시 사용합니다.
참고 항목
- 기존 인덱스 사용하려면 검색 가능한 필드가 하나 이상 있어야 합니다.
- CORS 원본 형식 허용 옵션을
all로 설정하고 허용된 원본 옵션을*로 설정합니다.
검색 유형
Azure OpenAI On Your Data는 데이터 원본을 추가할 때 사용할 수 있는 다음과 같은 검색 유형을 제공합니다.
선택한 지역에서 사용할 수 있는 Ada 포함 모델을 사용하여 벡터 검색
벡터 검색을 사용하도록 설정하려면 Azure OpenAI 리소스에 배포된 기존 포함 모델이 필요합니다. 데이터를 연결할 때 포함 배포를 선택한 다음, 데이터 관리에서 벡터 검색 유형 중 하나를 선택합니다. Azure AI Search를 데이터 원본으로 사용하는 경우 인덱스의 벡터 열이 있는지 확인합니다.
사용자 고유의 인덱스 사용 중인 경우 데이터 원본을 추가할 때 필드 매핑을 사용자 지정하여 질문에 대답할 때 매핑될 필드를 정의할 수 있습니다. 필드 매핑을 사용자 지정하려면 데이터 원본을 추가할 때 데이터 원본 페이지에서 사용자 지정 필드 매핑 사용을 선택합니다.
Important
- 의미 체계 검색 추가 가격이 적용됩니다. 의미 체계 검색 또는 벡터 검색을 사용하도록 설정하려면 기본 이상의 SKU를 선택해야 합니다. 자세한 내용은 가격 책정 계층 차이 및 서비스 제한을 참조하세요.
- 정보 검색 및 모델 응답의 품질을 향상하려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어 및 아랍어와 같은 데이터 원본 언어에 대해 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
| 검색 옵션 | 검색 유형 | 추가 가격 책정 여부 | 이점 |
|---|---|---|---|
| keyword | 키워드 검색 | 추가 가격 책정은 없습니다. | 연산자 유무에 관계없이 지원되는 언어의 용어 또는 구를 사용하여 검색 가능한 필드에 대해 빠르고 유연한 쿼리 구문 분석 및 일치를 수행합니다. |
| 의미 체계 | 의미 체계 검색 | 의미 체계 검색 사용에 대한 추가 가격 책정. | AI 모델을 사용하여 초기 검색 순위에서 반환된 쿼리 용어 및 문서의 의미 체계적 의미를 이해하여 검색 결과의 정밀도와 관련성을 개선합니다. |
| 벡터 | 벡터 검색 | 포함 모델을 호출하여 Azure OpenAI 계정에 대한 추가 가격 책정 | 콘텐츠의 벡터 포함을 기준으로 지정된 쿼리 입력과 유사한 문서를 찾을 수 있습니다. |
| 하이브리드(벡터 + 키워드) | 벡터 검색 및 키워드 검색 하이브리드 | 포함 모델을 호출하여 Azure OpenAI 계정에 대한 추가 가격 책정 | 벡터 포함을 사용하여 벡터 필드에 대해 유사성 검색을 수행하는 동시에, 용어 쿼리를 사용하여 영숫자 필드에 대한 유연한 쿼리 구문 분석 및 전체 텍스트 검색을 지원합니다. |
| 하이브리드(벡터 + 키워드) + 의미 체계 | 벡터 검색, 의미 체계 검색 및 키워드 검색의 하이브리드입니다. | 포함 모델 호출에서 Azure OpenAI 계정의 추가 가격 책정 및 의미 체계 검색 사용에 대한 추가 가격 책정 | 벡터 포함, 언어 이해 및 유연한 쿼리 구문 분석을 사용하여 복잡하고 다양한 정보 검색 시나리오를 처리할 수 있는 풍부한 검색 환경 및 생성 AI 앱을 만듭니다. |
지능형 검색
Azure OpenAI On Your Data에는 데이터에 대해 지능형 검색이 활성화되어 있습니다. 의미 체계 검색과 키워드 검색이 모두 있는 경우 의미 체계 검색은 기본적으로 사용하도록 설정됩니다. 모델을 포함하는 경우 지능형 검색은 기본적으로 하이브리드 + 의미 체계 검색으로 설정됩니다.
문서 수준 액세스 제어
참고 항목
데이터 원본으로 Azure AI Search를 선택하면 문서 수준 액세스 제어가 지원됩니다.
Azure OpenAI On Your Data를 사용하면 Azure AI Search 보안 필터를 사용하여 다른 사용자에 대한 응답에 사용할 수 있는 문서를 제한할 수 있습니다. 문서 수준 액세스를 사용하도록 설정하면 Azure AI Search에서 반환되고 응답을 생성하는 데 사용되는 검색 결과가 사용자 Microsoft Entra 그룹 멤버 자격에 따라 잘립니다. 기존 Azure AI Search 인덱스에서만 문서 수준 액세스를 사용하도록 설정할 수 있습니다. 자세한 내용은 데이터 네트워크의 Azure OpenAI 및 액세스 구성을 참조하세요.
인덱스 필드 매핑
사용자 고유의 인덱스 사용 중인 경우 Azure AI Foundry 포털에서 데이터 원본을 추가할 때 질문에 대답하기 위해 매핑할 필드를 정의하라는 메시지가 표시됩니다. 콘텐츠 데이터에 대해 여러 필드를 제공할 수 있으며 사용 사례와 관련된 텍스트가 있는 모든 필드를 포함해야 합니다.

이 예에서 콘텐츠 데이터 및 제목에 매핑된 필드는 질문에 답하기 위한 정보를 모델에 제공합니다. 제목은 인용 텍스트의 제목을 지정하는 데에도 사용됩니다. 파일 이름에 매핑된 필드는 응답에 인용 이름을 생성합니다.
이러한 필드를 올바르게 매핑하면 모델의 응답 및 인용 품질이 향상되는 데 도움이 됩니다. 또한 fieldsMapping 매개 변수를 사용하여 API에서 구성할 수 있습니다.
검색 필터(API)
쿼리 실행에 대한 추가 값 기반 조건을 구현하려는 경우 REST APIfilter 매개 변수를 사용하여 검색 필터를 설정할 수 있습니다.
Azure AI 검색에 데이터를 수집하는 방법
2024년 9월 현재 수집 API는 통합 벡터화로 전환되었습니다. 이 업데이트는 기존 API 계약을 변경하지 않습니다. Azure AI Search의 새로운 제품인 통합 벡터화는 입력 데이터를 청크 및 포함하기 위해 미리 빌드된 기술을 활용합니다. Azure OpenAI On Your Data ingion Service는 더 이상 사용자 지정 기술을 사용하지 않습니다. 통합 벡터화로 마이그레이션한 후 수집 프로세스는 일부 수정을 거쳤으며 그 결과 다음 자산만 생성됩니다.
{job-id}-index-
{job-id}-indexer는 시간별 또는 일별 일정을 지정한 경우, 그렇지 않으면 수집 프로세스가 끝날 때 인덱서가 정리됩니다. {job-id}-datasource
이 기능은 이제 Azure AI Search에서 기본적으로 관리되므로 청크 컨테이너를 더 이상 사용할 수 없습니다.
데이터 연결
Azure OpenAI, Azure AI 검색 및 Azure Blob Storage에서 연결을 인증하는 방법을 선택해야 합니다. 시스템이 할당한 관리 ID 또는 API 키를 선택할 수 있습니다. 인증 유형으로 API 키를 선택하면 시스템에서 Azure AI 검색, Azure OpenAI 및 Azure Blob Storage 리소스에 연결할 수 있도록 API 키를 자동으로 채웁니다. 시스템이 할당한 관리 ID를 선택하면 보유한 역할 할당에 따라 인증이 이루어집니다. 보안을 위해 기본적으로 시스템이 할당한 관리 ID가 선택됩니다.

다음 단추를 선택하면 선택한 인증 방법을 사용하도록 자동으로 설정의 유효성을 검사합니다. 오류가 발생하면 역할 할당 문서를 참조하여 설정을 업데이트합니다.
설정을 수정한 후 다시 다음을 선택하여 유효성을 검사하고 계속 진행합니다. API 사용자는 할당된 관리 ID 및 API 키를 사용하여 인증을 구성할 수도 있습니다.










Copilot(미리 보기), Teams(미리 보기) 또는 웹앱에 배포
Azure OpenAI를 데이터에 연결한 후 Azure AI Foundry 포털의 배포 단추를 사용하여 배포할 수 있습니다.

이렇게 하면 솔루션을 배포하기 위한 여러 옵션이 제공됩니다.
Azure AI Foundry 포털에서 직접 Copilot Studio (미리 보기)의 부조종사에 배포하여 Microsoft Teams, 웹 사이트, Dynamics 365 및 기타 Azure Bot Service 채널과 같은 다양한 채널에 대화형 환경을 제공할 수 있습니다. Azure OpenAI 서비스 및 Copilot Studio(미리 보기)에서 사용되는 테넌트는 동일해야 합니다. 자세한 내용은 데이터에 대한 Azure OpenAI로 연결 사용을 참조하세요.
참고 항목
Copilot Studio의 부조종사에 배포(미리 보기)는 미국 지역에서만 사용할 수 있습니다.
데이터에서 Azure OpenAI에 대한 액세스 및 네트워킹 구성
Azure OpenAI On Your Data를 사용하고 Microsoft Entra ID 역할 기반 액세스 제어, 가상 네트워크 및 프라이빗 엔드포인트를 사용하여 데이터 및 리소스를 보호할 수 있습니다. Azure AI Search 보안 필터를 사용하여 다른 사용자에 대한 응답에 사용할 수 있는 문서를 제한할 수도 있습니다. 데이터 액세스 및 네트워크 구성에서 Azure OpenAI를 참조하세요.
모범 사례
다음 섹션을 사용하여 모델에서 제공하는 응답의 품질을 개선하는 방법을 알아봅니다.
수집 매개 변수
데이터가 Azure AI Search에 수집되면 스튜디오 또는 수집 API에서 다음을 추가하는 설정을 수정할 수 있습니다.
청크 크기(미리 보기)
Azure OpenAI On Your Data는 문서를 수집하기 전에 청크로 분할하여 처리합니다. 청크 크기는 검색 인덱스에 있는 모든 청크의 토큰 수 측면에서 최대 크기입니다. 청크 크기와 함께 검색된 문서 수는 모델로 전송되는 프롬프트에 포함된 정보(토큰)의 양을 제어합니다. 일반적으로 청크 크기에 검색된 문서 수를 곱한 값은 모델로 전송된 총 토큰 수입니다.
사용 사례에 대한 청크 크기 설정
기본 청크 크기는 1,024개의 토큰입니다. 그러나 데이터의 고유성을 고려할 때 다른 청크 크기(예: 256, 512 또는 1,536 토큰)가 더 효과적일 수 있습니다.
청크 크기를 조정하면 챗봇의 성능이 향상 될 수 있습니다. 최적의 청크 크기를 찾으려면 몇 가지 시행착오가 필요하지만 먼저 데이터 세트의 특성을 고려해야 합니다. 청크 크기가 작을수록 일반적으로 직접 팩트 및 컨텍스트가 적은 데이터 세트의 경우 더 나은 반면, 청크 크기가 클수록 검색 성능에 영향을 줄 수 있지만 더 많은 컨텍스트 정보에 도움이 될 수 있습니다.
256과 같은 작은 청크 크기는 더 세분화된 청크를 생성합니다. 또한 이 크기는 모델이 더 적은 토큰을 활용하여 출력을 생성한다는 것을 의미합니다(검색된 문서 수가 매우 높지 않은 경우). 잠재적으로 비용이 적게 듭니다. 또한 청크가 작을수록 모델이 긴 텍스트 섹션을 처리하고 해석할 필요가 없으므로 노이즈 및 방해가 줄어듭니다. 그러나 이러한 세분성과 포커스는 잠재적인 문제를 야기합니다. 특히 검색된 문서 수가 3과 같은 낮은 값으로 설정된 경우 중요한 정보가 검색된 상위 청크에 포함되지 않을 수 있습니다.
팁
청크 크기를 변경하려면 문서를 다시 수집해야 하므로 먼저 엄격성 및 검색된 문서 수와 같은 런타임 매개 변수를 조정하는 것이 유용합니다. 원하는 결과가 아직 표시되지 않는 경우 청크 크기를 변경하는 것이 좋습니다.
- 문서에 있어야 하는 답변이 포함된 질문에 대해 "알 수 없음"과 같은 응답이 많은 경우 청크 크기를 256 또는 512로 줄여 세분성을 개선하는 것이 좋습니다.
- 챗봇이 올바른 세부 정보를 제공하지만 다른 정보를 누락하면 인용에서 명백해지면 청크 크기를 1,536으로 늘리면 더 많은 컨텍스트 정보를 캡처하는 데 도움이 될 수 있습니다.
런타임 매개 변수
Azure AI Foundry 포털 및 API의 데이터 매개 변수 섹션에서 다음 추가 설정을 수정할 수 있습니다. 이러한 매개 변수를 업데이트할 때 데이터를 다시 수집할 필요가 없습니다.
| 매개 변수 이름 | 설명 |
|---|---|
| 데이터에 대한 응답 제한 | 이 플래그는 데이터 원본과 관련이 없거나 검색 문서가 완전한 답변을 제공하기에 불충분한 경우 쿼리를 처리하는 챗봇의 접근 방식을 구성합니다. 이 설정을 비활성화하면 모델은 문서 외에도 자체 지식으로 응답을 보완합니다. 이 설정을 사용 설정하면 모델은 응답을 문서에만 의존하려고 시도합니다. 이 매개 변수는 API의 inScope 매개 변수이며 기본적으로 true로 설정됩니다. |
| 검색된 문서 | 이 매개 변수는 3, 5, 10 또는 20으로 설정할 수 있는 정수로, 최종 응답을 작성하기 위해 대규모 언어 모델에 제공되는 문서 청크의 수를 제어합니다. 기본적으로 5로 설정됩니다. 검색 프로세스는 시끄럽고 때로는 청크 분할로 인해 관련 정보가 검색 인덱스의 여러 청크에 분산될 수 있습니다. 상위 K 번호(예: 5)를 선택하면 검색 및 청크의 고유 제한에도 불구하고 모델이 관련 정보를 추출할 수 있습니다. 그러나 숫자를 너무 높게 늘리면 모델에 방해가 될 수 있습니다. 또한 효과적으로 사용할 수 있는 최대 문서 수는 각각 다른 컨텍스트 크기와 문서 처리 용량을 가지기 때문에 모델 버전에 따라 달라집니다. 응답에 중요한 컨텍스트가 누락된 경우 이 매개 변수를 늘려 보세요. API의 topNDocuments 매개 변수이며 기본적으로 5입니다. |
| 엄격성 | 유사성 점수를 기반으로 검색 문서를 필터링하는 시스템의 공격성을 결정합니다. 시스템은 Azure Search 또는 기타 문서 저장소를 쿼리한 다음 ChatGPT와 같은 대규모 언어 모델에 제공할 문서를 결정합니다. 관련 없는 문서를 필터링하면 엔드투엔드 챗봇의 성능이 크게 향상됩니다. 일부 문서는 모델에 전달하기 전에 유사성 점수가 낮은 경우 상위 K 결과에서 제외됩니다. 이 값은 1에서 5 사이의 정수 값으로 제어됩니다. 이 값을 1로 설정하면 시스템이 사용자 쿼리와 검색 유사성에 따라 문서를 최소한으로 필터링합니다. 반대로 5로 설정하면 시스템이 매우 높은 유사성 임계값을 적용하여 문서를 적극적으로 필터링한다는 의미입니다. 챗봇이 관련 정보를 생략하는 것을 발견하면 필터의 엄격도를 낮추어(값을 1에 가깝게 설정) 더 많은 문서를 포함시키세요. 반대로 관련 없는 문서로 인해 응답에 방해가 된다면 임계값을 5에 가깝게 설정하세요. API의 strictness 매개 변수이며 기본적으로 3으로 설정됩니다. |
인용되지 않은 참조
모델은 데이터 원본에서 검색되지만 인용에 포함되지 않은 문서에 대해 API에 "TYPE":CONTENT 대신 "TYPE":"UNCITED_REFERENCE"을(를) 반환할 수 있습니다. 디버깅에 유용할 수 있으며 위에서 설명한 런타임 매개 변수를 검색된 문서와 엄격성을 수정하여 이 동작을 제어할 수 있습니다.
시스템 메시지
Azure OpenAI On Your Data를 사용할 때 모델의 회신을 조정하는 시스템 메시지를 정의할 수 있습니다. 이 메시지를 사용하면 Azure OpenAI On Your Data에서 사용하는 RAG(검색 보강 생성) 패턴을 기반으로 회신을 사용자 지정할 수 있습니다. 시스템 메시지는 내부 기본 프롬프트 외에도 사용되어 환경을 제공합니다. 이를 지원하기 위해 모델이 데이터를 사용하여 질문에 답변할 수 있도록 특정 토큰의 수 이후 시스템 메시지를 자릅니다. 기본 환경 위에 추가 동작을 정의하는 경우 시스템 프롬프트가 자세히 설명되고 정확한 예상 사용자 지정을 설명하는지 확인합니다.
데이터 세트 추가를 선택하면 Azure AI Foundry 포털의 시스템 메시지 섹션 또는 API의 role_information매개 변수를 사용할 수 있습니다.

잠재적 사용 패턴
역할 정의
도우미를 원하는 역할을 정의할 수 있습니다. 예를 들어 지원 봇을 빌드하는 경우 “사용자가 새로운 문제를 해결하는 데 도움이 되는 전문가 인시던트 지원 도우미입니다.”를 추가할 수 있습니다.
검색할 데이터 형식 정의
도우미에 제공하는 데이터의 특성을 추가할 수도 있습니다.
- “재무 보고서”, “학술지”, “인시던트 보고서”와 같은 데이터 세트의 주제나 범위를 정의합니다. 예를 들어 기술 지원을 위해 “검색된 문서에서 유사한 인시던트 정보를 사용하여 쿼리에 응답합니다.”를 추가할 수 있습니다.
- 데이터에 특정 특성이 있는 경우 시스템 메시지에 이러한 세부 정보를 추가할 수 있습니다. 예를 들어 문서가 일본어로 된 경우 “일본어 문서를 검색하고 일본어로 주의 깊게 읽고 일본어로 대답해야 합니다.”를 추가할 수 있습니다.
- 문서에 재무 보고서의 테이블과 같은 구조화된 데이터가 포함된 경우 시스템 프롬프트에 이 팩트를 추가할 수도 있습니다. 예를 들어 데이터에 테이블이 있는 경우 “재무 결과와 관련된 테이블 형식의 데이터가 제공되고 사용자 질문에 대답하기 위해 계산을 수행하기 위해 테이블 줄을 읽어야 합니다.”를 추가할 수 있습니다.
출력 스타일 정의
시스템 메시지를 정의하여 모델의 출력을 변경할 수도 있습니다. 예를 들어 도우미 답변이 프랑스어로 되어 있는지 확인하려면 다음과 같은 프롬프트를 추가할 수 있습니다. "프랑스어를 이해하는 사용자가 정보를 찾는 데 도움이 되는 AI 도우미입니다. 사용자 질문은 영어 또는 프랑스어로 할 수 있습니다. 검색된 문서를 주의 깊게 읽고 프랑스어로 답변하세요. 모든 답변이 프랑스어로 표시되도록 문서에서 지식을 프랑스어로 번역하세요.”
중요한 동작 재확인
Azure OpenAI On Your Data는 데이터를 사용하여 사용자 쿼리에 응답하는 프롬프트 형식으로 큰 언어 모델에 지침을 전송하여 작동합니다. 애플리케이션에 중요한 특정 동작이 있는 경우 시스템 메시지에서 동작을 반복하여 정확도를 높일 수 있습니다. 예를 들어 문서에서만 답변하도록 모델을 안내하려면 다음을 추가할 수 있습니다. "정보를 사용하지 않고 검색된 문서만 사용하여 답변하세요. 답변의 모든 클레임에 대해 검색된 문서에 대한 인용을 생성하세요. 검색된 문서를 사용하여 사용자 질문에 대답할 수 없는 경우 문서가 사용자 쿼리와 관련된 이유를 설명하세요. 어떤 경우에도 자신의 지식으로 대답하지 마세요.”
프롬프트 엔지니어링 트릭
프롬프트 엔지니어링에는 출력을 개선하기 위해 시도할 수 있는 많은 트릭이 있습니다. 한 가지 예는 다음을 추가할 수 있는 생각 체인 프롬프트입니다. "사용자 쿼리에 응답하기 위해 검색된 문서의 정보에 대해 단계별로 생각해 봅시다. 문서에서 사용자 쿼리에 대한 관련 지식을 단계별로 추출하고 관련 문서에서 추출된 정보를 바탕으로, 상향식으로 답변을 작성합니다.”
참고 항목
시스템 메시지는 GPT 도우미가 검색된 문서에 따라 사용자 질문에 응답하는 방법을 수정하는 데 사용됩니다. 검색 프로세스에는 영향을 주지 않습니다. 검색 프로세스에 대한 지침을 제공하려는 경우 질문에 포함하는 것이 좋습니다. 시스템 메시지는 단지 지침일 뿐입니다. 모델은 객관성과 논란의 여지가 있는 진술을 피하는 등의 특정 동작으로 준비되어 있기 때문에 지정된 모든 지침을 준수하지 않을 수 있습니다. 시스템 메시지가 이러한 동작과 모순되는 경우 예기치 않은 동작이 발생할 수 있습니다.
최대 응답
모델 응답당 토큰 수 한도를 설정합니다. 데이터에 대한 Azure OpenAI의 상한은 1500입니다. 이는 API에서 max_tokens 매개 변수를 설정하는 것과 같습니다.
데이터에 대한 응답 제한
이 옵션은 모델이 데이터만 사용하여 응답하도록 권장하며 기본적으로 선택됩니다. 이 옵션을 선택 취소하면 모델이 내부 지식을 더 쉽게 적용하여 응답할 수 있습니다. 사용 사례와 시나리오에 따라 올바른 선택을 결정합니다.
모델과의 상호 작용
모델과 대화할 때 최상의 결과를 얻으려면 다음 방법을 따릅니다.
대화 기록
- 새 대화를 시작하거나 이전 대화와 관련이 없는 질문을 하기 전에 채팅 기록을 지웁니다.
- 대화 기록이 모델의 현재 상태를 변경하기 때문에 첫 번째 대화 차례와 후속 차례 사이에 동일한 질문에 대해 서로 다른 응답을 가져올 것으로 예상할 수 있습니다. 잘못된 답변을 받은 경우 품질 버그로 신고해 주세요.
모델 응답
특정 질문에 대한 모델 응답에 만족하지 않는 경우 질문을 보다 구체적이거나 더 일반적인 것으로 만들어 모델이 응답하는 방식을 확인하고 그에 따라 질문을 재구성해 보세요.
CoT(Chain-of-thought) 프롬프팅은 모델이 복잡한 질문/작업에 대해 원하는 결과를 생성하도록 하는 데 효과적인 것으로 나타났습니다.
질문 길이
긴 질문은 피하고 가능하면 여러 질문으로 나누세요. GPT 모델에는 허용할 수 있는 토큰 수에 제한이 있습니다. 토큰 제한은 사용자 질문, 시스템 메시지, 검색된 검색 문서(청크), 내부 프롬프트, 대화 기록(있는 경우) 및 응답에 계산됩니다. 질문이 토큰 제한을 초과하면 잘립니다.
다국어 지원
현재 Azure OpenAI On Your Data 지원 쿼리의 키워드 검색 및 의미 체계 검색은 인덱스의 데이터와 동일한 언어로 제공됩니다. 예를 들어, 데이터가 일본어로 되어 있으면 입력 쿼리도 일본어로 되어 있어야 합니다. 언어 간 문서 검색의 경우 벡터 검색을 사용하도록 설정한 인덱스를 빌드하는 것이 좋습니다.
정보 검색 및 모델 응답의 품질을 향상시키려면 영어, 프랑스어, 스페인어, 포르투갈어, 이탈리아어, 독일, 중국어(Zh), 일본어, 한국어, 러시아어, 아랍어 언어에 대한 의미 체계 검색을 사용하도록 설정하는 것이 좋습니다.
데이터가 다른 언어로 되어 있음을 모델에 알리려면 시스템 메시지를 사용하는 것이 좋습니다. 예시:
*"*사용자가 검색된 일본어 문서에서 정보를 추출할 수 있도록 디자인된 AI 도우미입니다. 응답을 작성하기 전에 일본어 문서를 주의해서 조사하세요. 사용자의 쿼리는 일본어로 되어 있으며 일본어로도 응답해야 합니다."
여러 언어로 된 문서가 있는 경우 각 언어에 대한 새 인덱스를 빌드하고 별도로 Azure OpenAI에 연결하는 것이 좋습니다.
스트리밍 데이터
stream 매개 변수를 사용하여 스트리밍 요청을 보내면 전체 API 응답을 기다리지 않고도 데이터를 점진적으로 보내고 받을 수 있습니다. 이는 특히 대규모 또는 동적 데이터의 경우 성능과 사용자 환경을 개선시킬 수 있습니다.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
더 나은 결과를 위한 대화 기록
모델과 채팅할 때 채팅 기록을 제공하면 모델이 더 높은 품질의 결과를 반환하는 데 도움이 됩니다. 더 나은 응답 품질을 위해 API 요청에 도우미 메시지의 context 속성을 포함할 필요가 없습니다.
예제는 API 참조 설명서를 참조하세요.
함수 호출
일부 Azure OpenAI 모델을 사용하면 함수 호출을 사용하도록 도구 및 tool_choice 매개 변수를 정의할 수 있습니다.
REST API/chat/completions를 통해 함수 호출을 설정할 수 있습니다.
tools및 데이터 원본이 모두 요청에 있는 경우 다음 정책이 적용됩니다.
-
tool_choice이(가)none인 경우, 도구가 무시되고 데이터 원본만 사용하여 답변을 생성합니다. - 그렇지 않으면
tool_choice지정되지 않았거나auto또는 개체로 지정되면 데이터 원본이 무시되고 응답에 선택한 함수 이름과 인수(있는 경우)가 포함됩니다. 모델이 함수를 선택하지 않는다고 결정하더라도 데이터 원본은 여전히 무시됩니다.
위의 정책이 요구 사항을 충족하지 않는 경우 프롬프트 흐름 또는 Assistants API 같은 다른 옵션을 고려하세요.
데이터의 Azure OpenAI에 대한 토큰 사용량 예측
Azure OpenAI On Your Data RAG(검색 증강 생성)는 검색 서비스(예: Azure AI 검색)와 생성(Azure OpenAI 모델)을 모두 활용하여 사용자가 제공된 데이터를 기반으로 질문에 대한 답변을 가져올 수 있도록 하는 서비스입니다.
이 RAG 파이프라인의 일부로 상위 수준에서 다음 세 단계가 있습니다.
사용자 쿼리를 검색 의도 목록으로 다시 포맷합니다. 이 작업은 지침, 사용자 질문 및 대화 기록을 포함하는 프롬프트를 사용하여 모델을 호출하여 수행됩니다. 의도 프롬프트를 호출해 보겠습니다.
각 의도에 대해 검색 서비스에서 여러 문서 청크가 검색됩니다. 사용자가 지정한 엄격한 임계값을 기준으로 관련 없는 청크를 필터링하고 내부 논리에 따라 청크를 다시 생성/집계한 후 사용자가 지정한 문서 청크 수가 선택됩니다.
이러한 문서 청크는 사용자 질문, 대화 기록, 역할 정보 및 지침과 함께 최종 모델 응답을 생성하기 위해 모델로 전송됩니다. 이를 생성 프롬프트를 호출해 보겠습니다.
모델에 대한 호출은 총 두 가지입니다.
의도 처리: 의도 프롬프트에 대한 토큰 예측에는 사용자 질문, 대화 기록 및 의도 생성을 위해 모델로 전송된 지침이 포함됩니다.
응답을 생성하기 위해: 생성 프롬프트에 대한 토큰 예측에는 사용자 질문, 대화 기록, 검색된 문서 청크 목록, 역할 정보 및 생성을 위해 전송된 지침이 포함됩니다.
모델에서 생성된 출력 토큰(의도 및 응답 모두)은 총 토큰 추정을 고려해야 합니다. 아래의 4개 열을 모두 합산하면 응답을 생성하는 데 사용되는 평균 총 토큰이 제공됩니다.
| 모델 | 생성 프롬프트 토큰 수 | 의도 프롬프트 토큰 수 | 응답 토큰 수 | 의도 토큰 수 |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
위의 숫자는 다음을 사용하는 데이터 집합에 대한 테스트를 기반으로 합니다.
- 191개 대화
- 250개 질문
- 질문당 평균 토큰 10개
- 대화당 평균 4회 대화 턴
및 다음 매개 변수.
| 설정 | 값 |
|---|---|
| 검색된 문서 수 | 5 |
| 엄격성 | 3 |
| 청크 크기 | 1024 |
| 수집된 데이터에 대한 응답을 제한하시겠습니까? | True |
이러한 예상치는 위의 매개 변수에 대해 설정된 값에 따라 달라집니다. 예를 들어 검색된 문서 수가 10으로 설정되고 엄격도가 1로 설정된 경우 토큰 수가 늘어나게 됩니다. 반환된 응답이 수집된 데이터로 제한되지 않는 경우 모델에 지정된 지침이 적고 토큰 수가 감소합니다.
추정치는 또한 질문되는 문서 및 질문의 성격에 따라 달라집니다. 예를 들어 질문이 개방형인 경우 응답이 더 길어질 수 있습니다. 마찬가지로 시스템 메시지가 길면 더 많은 토큰을 사용하는 더 긴 프롬프트가 발생하며, 대화 기록이 길면 프롬프트가 더 길어집니다.
| 모델 | 시스템 메시지에 대한 최대 토큰 |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
위의 표에서는 시스템 메시지에 사용할 수 있는 최대 토큰 수를 보여 줍니다. 모델 응답에 대한 최대 토큰 수를 보려면 모델 게시물을 참조하세요. 또한 다음 항목도 토큰을 소비합니다.
메타 프롬프트: 모델의 응답을 (API
inScope=True에서) 접지 데이터 콘텐츠로 제한하는 경우 최대 토큰 수가 더 높습니다. 그렇지 않으면(예:inScope=False인 경우) 최대값이 낮습니다. 이 숫자는 사용자 질문의 토큰 길이와 대화 내역에 따라 달라질 수 있습니다. 이 예측에는 검색을 위한 기본 프롬프트 및 쿼리 다시 쓰기 프롬프트가 포함됩니다.사용자 질문 및 기록: 변수이지만 2,000개의 토큰으로 제한됩니다.
검색된 문서(청크): 검색된 문서 청크에 사용되는 토큰의 수는 여러 요인에 따라 달라집니다. 이 값의 상한은 검색된 문서 청크의 수에 청크 크기를 곱한 값입니다. 그러나 나머지 필드를 계산한 후 사용 중인 특정 모델에 사용할 수 있는 토큰을 기준으로 잘립니다.
사용 가능한 토큰의 20%는 모델 응답을 위해 예약되어 있습니다. 나머지 80%의 사용 가능한 토큰에는 메타 프롬프트, 사용자 질문 및 대화 내역, 시스템 메시지가 포함됩니다. 남은 토큰 예산은 검색된 문서 청크에 사용됩니다.
입력에서 사용하는 토큰 수(예: 질문, 시스템 메시지/역할 정보)를 계산하려면 다음 코드 샘플을 사용합니다.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
문제 해결
실패한 작업을 해결하려면 항상 API 응답 또는 Azure AI Foundry 포털에 지정된 오류 또는 경고를 확인합니다. 다음은 몇 가지 일반적인 오류 및 경고입니다.
실패한 수집 작업
할당량 한도 문제
서비스 Y에서 X라는 이름의 인덱스만 만들 수 없습니다. 이 서비스에 대한 인덱스 할당량이 초과되었습니다. 사용하지 않는 인덱스를 먼저 삭제하거나 인덱스 생성 요청 사이에 지연 시간을 추가하거나 더 높은 한도를 위해 서비스를 업그레이드해야 합니다.
이 서비스에 대한 표준 인덱서 할당량 X를 초과했습니다. 현재 X의 표준 인덱서가 있습니다. 사용하지 않는 인덱서를 먼저 삭제하거나 인덱서 '실행 모드'를 변경하거나 서비스를 업그레이드하여 더 높은 한도를 적용해야 합니다.
해결 방법:
더 높은 가격 책정 계층으로 업그레이드하거나 사용하지 않는 자산을 삭제하세요.
전처리 시간 초과 문제
웹 API 요청이 실패했으므로 기술을 실행할 수 없습니다.
Web API 기술 응답이 옳바르지 않기 때문에 기술을 실행할 수 없습니다.
해결 방법:
입력 문서를 더 작은 문서로 분해하고 다시 시도합니다.
권한 문제
이 요청은 이 작업을 수행할 권한이 없습니다
해결 방법:
즉, 지정된 자격 증명을 사용하여 스토리지 계정에 액세스할 수 없습니다. 이 경우 API에 전달된 스토리지 계정 자격 증명을 검토하고 프라이빗 엔드포인트 뒤에 스토리지 계정이 숨겨지지 않았는지 확인합니다(프라이빗 엔드포인트가 이 리소스에 대해 구성되지 않은 경우).
Azure AI Search를 사용하여 쿼리를 보낼 때 발생하는 503 오류
각 사용자 메시지는 여러 검색 쿼리로 변환할 수 있으며, 모두 검색 리소스로 병렬로 전송됩니다. 이렇게 하면 검색 복제본 및 파티션 수가 낮을 때 제한 동작이 생성될 수 있습니다. 단일 파티션과 단일 복제본이 지원할 수 있는 초당 최대 쿼리 수는 충분하지 않을 수 있습니다. 이 경우 복제본 및 파티션을 늘리거나 애플리케이션에서 절전/재시도 논리를 추가하는 것이 좋습니다. 자세한 내용은 Azure AI Search 설명서를 참조하세요.
지역별 가용성 및 모델 지원
| 지역 | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| 오스트레일리아 동부 | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 캐나다 동부 | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 미국 동부 | ✅ | ✅ | ✅ | |||||
| 미국 동부 2 | ✅ | ✅ | ✅ | ✅ | ||||
| 프랑스 중부 | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 일본 동부 | ✅ | |||||||
| 미국 중북부 | ✅ | ✅ | ✅ | |||||
| 노르웨이 동부 | ✅ | ✅ | ||||||
| 미국 중남부 | ✅ | ✅ | ||||||
| 인도 남부 | ✅ | ✅ | ||||||
| 스웨덴 중부 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| 스위스 북부 | ✅ | ✅ | ✅ | |||||
| 영국 남부 | ✅ | ✅ | ✅ | ✅ | ||||
| 미국 서부 | ✅ | ✅ | ✅ |
**이는 텍스트 전용 구현입니다.
Azure OpenAI 리소스가 다른 지역에 있는 경우 Azure OpenAI On Your Data를 사용할 수 없습니다.