학습
인증
Microsoft Certified: Azure Cosmos DB Developer Specialty - Certifications
Microsoft Azure Cosmos DB를 사용하여 효율적인 쿼리를 작성하고, 인덱싱 정책을 만들고, SQL API 및 SDK에서 리소스를 관리 및 프로비전합니다.
적용 대상: ![]() NoSQL
NoSQL
Azure Cosmos DB와 같은 스키마 없는 데이터베이스에서는 비정형 및 반정형 데이터를 쉽게 저장하고 쿼리할 수 있지만, 성능, 스케일링 수준, 최저 비용 측면에서 서비스를 최대한 활용하려면 시간을 할애하여 데이터 모델을 신중하게 결정해야 합니다.
데이터를 어떻게 저장할 것인가? 애플리케이션에서 데이터를 검색 및 쿼리하는 방법은 무엇인가? 애플리케이션 부하가 읽기 또는 쓰기 중 어디에 집중되어 있는가?
이 문서를 읽은 다음에는 다음과 같은 질문에 답할 수 있습니다.
Azure Cosmos DB는 JSON에 문서를 저장합니다. 즉, json에 저장하기 전에 숫자를 문자열로 변환해야 하는지 여부를 신중하게 결정해야 합니다. IEEE 754 binary64에 따라 배정밀도 숫자의 경계를 벗어날 가능성이 있는 경우 모든 숫자는 이상적으로는 String으로 변환되어야 합니다. Json 사양은 상호 운용성 문제로 인해 일반적으로 이 경계 밖의 숫자를 사용하는 것이 JSON에서 좋지 않은 방법인 이유를 설명합니다. 이러한 문제는 파티션 키 열과 특히 관련이 있습니다. 파티션 키 열은 변경할 수 없고 나중에 변경하려면 데이터 마이그레이션이 필요하기 때문입니다.
Azure Cosmos DB에서 데이터 모델링을 시작할 때 엔터티를 JSON 문서로 표시되는 자체 포함 항목으로 처리해 보세요.
비교를 위해 먼저 관계형 데이터베이스에서 데이터를 모델링하는 방법을 살펴보겠습니다. 다음 예제에서는 관계형 데이터베이스에서 사용자가 저장되는 방법을 보여 줍니다.
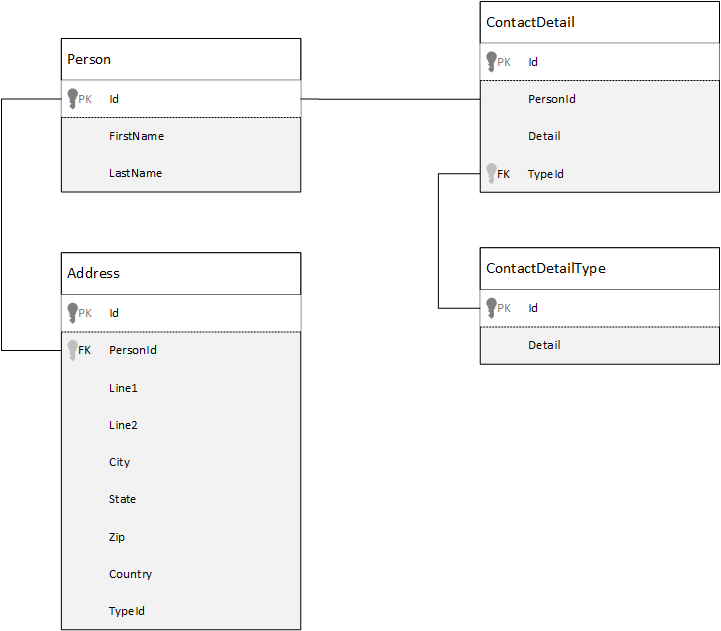
관계형 데이터베이스로 작업할 때 전략은 모든 데이터를 정규화하는 것입니다. 데이터를 정규화하려면 일반적으로 사용자 등의 엔터티를 가져와 개별 구성 요소로 분석해야 합니다. 예에서는 사용자에게 여러 연락처 세부 정보 레코드와 여러 주소 레코드가 있을 수 있습니다. 형식 등의 공통 필드를 추가로 추출하면 연락처 세부 정보를 더 세부적으로 분석할 수 있습니다. 주소의 경우도 마찬가지로, 각 레코드는 ‘집’ 또는 ‘회사’ 형식일 수 있습니다.
데이터를 정규화할 때의 원칙은 각 레코드에서 중복된 데이터 저장을 피하고 데이터를 참조하는 것입니다. 이 예제에서 모든 연락처 세부 정보와 주소를 포함하여 사용자를 읽으려면 JOINS를 사용하여 데이터를 런타임에 효율적으로 다시 작성(또는 비정규화)해야 합니다.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
한 사람의 연락처 세부 정보 및 주소를 업데이트하려면 여러 개별 테이블 간의 쓰기 작업이 필요합니다.
이제 Azure Cosmos DB에서 자체 포함 엔터티와 동일한 데이터를 모델링하는 방법을 살펴보겠습니다.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
이 방법을 사용하여 사용자와 관련된 모든 정보(예: 연락처 세부 정보 및 주소)를 단일 JSON 문서에 포함함으로써 이 사용자 레코드를 비정규화했습니다. 또한 고정된 스키마로 제한되지 않기 때문에 다른 도형의 연락처 세부 정보를 완전히 포함하는 것과 같은 유연성이 있습니다.
이제 데이터베이스에서 전체 사용자 레코드를 검색하는 작업은 단일 컨테이너와 단일 항목에 대해 단일 읽기 작업을 수행하는 것과 같습니다. 개인 레코드의 연락처 세부 정보와 주소를 업데이트하는 작업도 단일 항목에 대해 단일 쓰기 작업을 수행하는 것과 같습니다.
데이터를 비정규화하면 애플리케이션이 일반 작업 수행을 위해 실행해야 하는 쿼리 및 업데이트 수가 줄어듭니다.
일반적으로 다음과 같은 경우에 포함된 데이터 모델을 사용합니다.
참고
일반적으로 비정규화된 데이터 모델은 읽기 성능이 더 뛰어납니다.
경험상 Azure Cosmos DB에서는 모든 것을 비정규화하고 모든 데이터를 단일 항목에 포함하는 것이 좋지만, 이 경우 방지해야 하는 몇 가지 상황이 발생할 수 있습니다.
다음 JSON 코드 조각을 예로 들어 보겠습니다.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
이 코드 조각은 일반적인 블로그 또는 CMS 시스템을 모델링할 때 나타날 수 있는 포함된 주석이 있는 포스트 엔터티를 나타낼 수 있습니다. 이 예제의 문제는 주석 배열이 바인딩되지 않는 것입니다. 즉, 단일 게시물에 있을 수 있는 주석 수에 대한 제한(실질적인)이 없습니다. 항목의 크기가 무한히 커질 수 있으므로 피해야 할 디자인이므로 문제가 될 수 있습니다.
항목 크기가 증가함에 따라 유선을 통한 데이터 전송과 대규모 항목 읽기 및 업데이트 성능이 영향을 받습니다.
이 경우에는 다음과 같은 데이터 모델을 고려하는 것이 더 효율적입니다.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
이 모델에는 게시물 식별자가 포함된 속성이 있는 각 댓글에 대한 문서가 있습니다. 이렇게 하면 게시물에 댓글을 얼마든지 포함할 수 있으며 효율적으로 성장할 수 있습니다. 가장 최근 댓글보다 더 많이 보고 싶은 사용자는 댓글 컨테이너의 파티션 키가 되어야 하는 postId를 전달하여 이 컨테이너를 쿼리할 것입니다.
데이터 포함이 적합하지 않은 또 다른 경우는 포함된 데이터가 여러 항목에서 자주 사용되고 자주 변경되는 경우입니다.
다음 JSON 코드 조각을 예로 들어 보겠습니다.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
이 예제는 한 사용자의 주식 포트폴리오를 나타낼 수 있습니다. 여기서는 각 포트폴리오 문서에 주식 정보를 포함하도록 선택했습니다. 주식 거래 애플리케이션과 같이 관련 데이터가 자주 변경되는 환경에서 자주 변경되는 데이터를 포함하면 주식이 거래될 때마다 포트폴리오 문서를 계속 업데이트해야 합니다.
zbzb 주식은 하루에도 수백 번 거래될 수 있으며 수천 명의 사용자 포트폴리오에 zbzb 주식이 포함되어 있을 수 있습니다. 예시와 같은 데이터 모델에서는 매일 여러 번 수천 개의 포트폴리오 문서를 업데이트해야 하므로, 시스템의 확장성이 낮아질 수 있습니다.
데이터 포함은 많은 경우에 효과적이지만 데이터를 비정규화하면 그 가치에 비해 더 많은 문제가 발생하는 시나리오가 있습니다. 그러면 이제 무엇을 해야 할까요?
관계형 데이터베이스는 엔터티 간의 관계를 만들 수 있는 유일한 위치가 아닙니다. 문서 데이터베이스에서는 다른 문서의 데이터와 관련된 정보가 한 문서에 있을 수 있습니다. 여기서는 Azure Cosmos DB의 관계형 데이터베이스 또는 다른 문서 데이터베이스에 더 적합한 시스템을 빌드하는 것은 권장되지 않지만 간단한 관계는 괜찮으며 유용할 수 있습니다.
JSON에서도 이전 단락의 주식 포트폴리오 예제를 사용하지만, 이번에는 포함시키는 대신 포트폴리오의 주식 항목에 대해 설명하고자 합니다. 이렇게 하면 주식 항목이 하루 중 자주 변경되더라도 업데이트해야 하는 문서는 단일 주식 문서뿐입니다.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
하지만 이 방식에서 나타날 수 있는 분명한 단점은 애플리케이션이 사용자 포트폴리오를 표시할 때 저장된 각 주식에 대한 정보를 표시해야 할 경우에 나타납니다. 이 경우에는 각 주식 문서에 대한 정보를 로드하기 위해 데이터베이스를 여러 번에 걸쳐서 경유해야 합니다. 여기에서는 하루 중 자주 발생하는 쓰기 작업의 효율을 향상시키지만, 그에 따라 이 특정 시스템의 성능에 대한 영향이 덜할 수 있는 읽기 작업 성능은 희생하기로 결정했습니다.
참고
정규화된 데이터 모델은 서버에 대해 더 많은 라운드 트립이 요구될 수 있습니다.
현재 제약 조건, 외래 키 또는 기타 개념이 없으므로 문서에 있는 문서 간 관계는 사실상 "약한 링크"이며 데이터베이스 자체에서 확인되지 않습니다. 문서가 참조하는 데이터가 실제로 존재하는지 확인하려면 애플리케이션에서 또는 서버측 트리거 또는 Azure Cosmos DB의 저장 프로시저를 사용하여 이 작업을 수행해야 합니다.
일반적으로 정규화된 데이터 모델은 다음과 같은 경우에 사용합니다.
참고
일반적으로 정규화에서는 쓰기 성능이 더 뛰어납니다.
관계의 성장은 참조를 저장할 문서를 결정하는 데 도움이 됩니다.
발행자와 책을 모델링하는 JSON을 관찰하는 경우.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
발행자당 책 수가 작고 제한적으로 증가할 경우, 책 참조를 해당 발행자 문서에 저장해도 좋을 수 있습니다. 하지만 발행자당 책 수가 제한적이지 않으면, 이 데이터 모델의 경우 발행자 문서 예제와 같이 배열이 변하기 쉽고 계속 증가할 수 있습니다.
이를 조금만 변경하면 동일한 데이터를 제공하지만, 쉽게 변경되는 대규모 컬렉션을 피할 수 있는 모델을 만들 수 있습니다.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
이 예제에서는 발행자 문서에 바인딩되지 않은 컬렉션을 배치했습니다. 그리고 각 책 문서에서 발행자에 대한 참조만 두었습니다.
관계형 데이터베이스에서 다대다 관계는 다른 테이블의 레코드를 단순히 하나로 조인하는 조인 테이블을 사용해서 모델링되는 경우가 많습니다.
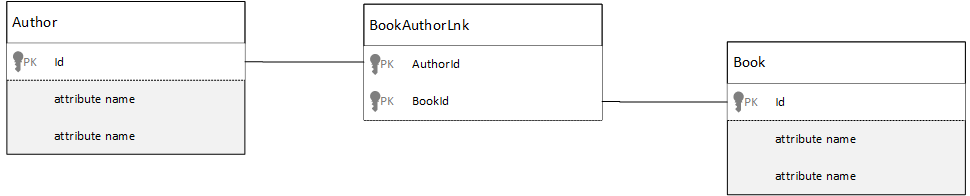
여기에서도 문서를 사용해서 동일한 방식을 따르고 다음과 비슷하게 보이는 데이터 모델을 만들고 싶을 수도 있습니다.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
이러한 모델도 작동은 가능합니다. 하지만 특정 저자와 해당 저자의 책을 로드하거나 특정 책과 해당 책의 저자를 로드하려면 항상 데이터베이스에 대해 2개 이상의 추가 쿼리를 실행해야 할 것입니다. 조인 문서에 대해 쿼리를 한 번 수행하고 조인되는 실제 문서를 인출하기 위해 또 다른 쿼리를 수행해야 합니다.
이 조인이 두 데이터 조각만 함께 붙이는 경우 완전히 삭제하지 않는 이유는 무엇일까요? 아래 예제를 고려해 보세요.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
이제 저자가 있는 경우 저자가 작성한 책을 즉시 알 수 있고, 반대로 책 문서가 로드되어 있으면 저자의 ID를 알 수 있습니다. 이렇게 하면 조인 테이블에 대한 중간 쿼리를 절약해서 애플리케이션에서 수행해야 하는 서버 라운드 트립 수를 줄일 수 있습니다.
이제 데이터 포함(또는 비정규화)과 참조(또는 정규화)에 대해 살펴보았습니다. 각 접근 방식에는 장단점 및 절충점이 있습니다.
하지만 어느 쪽이든 장단점이 있으므로 두 방식을 혼합해서 사용해도 좋습니다.
애플리케이션의 특정 사용 패턴 및 워크로드에 따라 포함 및 참조 데이터를 혼합하는 것이 적합할 수 있으며, 애플리케이션 논리를 단순화하면서 서버 라운드 트립도 줄이고, 적절한 수준으로 성능을 유지할 수 있습니다.
다음과 같은 JSON을 고려해보세요.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
여기에서는 주로 포함된 모델을 따랐으며, 다른 엔터티의 데이터가 최상위 문서에 포함되지만 다른 데이터는 참조됩니다.
책 문서를 보면 저자 배열을 볼 때 몇 가지 흥미로운 필드를 발견할 수 있습니다. 저자 문서를 다시 참조하는 데 사용하는 필드인 id 필드가 있습니다. 이는 정규화된 모델의 표준 사례이지만 name 및 thumbnailUrl도 있습니다. id만 사용하고 애플리케이션이 “link”를 통해 필요한 추가 정보를 해당 저자 문서에서 가져오도록 할 수도 있지만, 이 애플리케이션에서는 표시된 모든 책과 함께 저자 이름과 썸네일 사진을 표시하므로 저자에서 일부 데이터를 비정규화하여 목록에 있는 책당 서버 왕복을 줄일 수 있습니다.
물론, 저자 이름이 변경되거나 사진을 업데이트하려는 경우 저자가 출판한 모든 책에 대해 업데이트를 수행해야 하지만, 저자가 자신의 이름을 자주 변경하지 않는다는 가정에 따라 이 애플리케이션에서 이러한 정도는 설계상으로 허용되는 결정입니다.
위 예제에서는 읽기 작업의 고비용 처리를 줄이기 위해 사전 계산된 집계 값이 있습니다. 이 예제에서 저자의 문서에 포함된 일부 데이터는 런타임에 계산되는 데이터입니다. 새 책이 게시될 때마다, 책 문서가 생성됩니다. 그리고 countOfBooks 필드가 특정 저자에 대해 존재하는 책 문서 번호를 기준으로 계산된 값으로 설정됩니다. 이러한 최적화는 읽기를 최적화하기 위해 읽기 계산을 수행할 수 있는 읽기에 집중된 시스템에서 효과적일 수 있습니다.
모델에 사전 계산된 필드를 포함할 수 있는 기능은 Azure Cosmos DB에서 다중 문서 트랜잭션이 지원되기 때문에 가능합니다. 많은 NoSQL 저장소는 문서 간 트랜잭션을 수행할 수 없으므로 이러한 제한으로 인해 디자인상 "항상 모든 것을 포함"하도록 결정하는 것이 좋습니다. Azure Cosmos DB에서는 서버 쪽 트리거 또는 저장 프로시저를 사용해서 ACID 트랜잭션 내에서 책을 삽입하고 저자를 업데이트할 수 있습니다. 이제 데이터를 일관되게 유지하기 위해 하나의 문서에 모든 것을 포함시킬 필요가 없습니다.
일부 시나리오에서는 동일한 컬렉션에 여러 문서 형식을 포함할 수 있습니다. 일반적으로 동일한 파티션에 여러 관련 문서를 배치하려는 경우에 해당합니다. 예를 들어 동일한 컬렉션에 책과 책 리뷰를 모두 배치하고 bookId로 분할할 수 있습니다. 이 경우, 일반적으로 책과 책 리뷰를 구별하기 위해 유형을 식별하는 필드가 있는 문서에 추가하는 것이 좋습니다.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Azure Cosmos DB용 Azure Synapse Link는 클라우드 네이티브 HTAP(하이브리드 트랜잭션 및 분석 처리) 기능으로, 이를 통해 Microsoft Azure Cosmos DB의 작동 데이터에 대해 근 실시간 분석을 실행할 수 있습니다. Azure Synapse Link를 통해 Microsoft Azure Cosmos DB와 Azure Synapse Analytics가 긴밀하게 통합됩니다.
이 통합은 트랜잭션 워크로드에 영향을 주지 않고 대규모 분석을 가능하게 하는 트랜잭션 데이터의 열 형식 표현인 Azure Cosmos DB 분석 저장소를 통해 수행됩니다. 이 분석 저장소는 데이터를 복사하지 않고 트랜잭션 워크로드의 성능에 영향을 주지 않는 대규모 작동 데이터 세트에 대한 빠르고 비용 효율적인 쿼리에 적합합니다. 분석 저장소가 사용하도록 설정된 컨테이너를 만들거나 기존 컨테이너에서 분석 저장소를 사용하도록 설정하면 모든 트랜잭션 삽입, 업데이트 및 삭제가 분석 저장소와 거의 실시간으로 동기화되므로 변경 피드 또는 ETL 작업이 필요하지 않습니다.
이제 Azure Synapse Link를 사용하여 Azure Synapse Analytics에서 Azure Cosmos DB 컨테이너에 직접 연결하고 요청 단위 비용 없이 분석 저장소에 액세스할 수 있습니다. Azure Synapse Analytics는 현재 Synapse Apache Spark 및 서버리스 SQL 풀을 사용하여 Azure Synapse Link를 지원합니다. 전역적으로 분산된 Microsoft Azure Cosmos DB 계정이 있는 경우 컨테이너에 분석 저장소를 사용하도록 설정하면 해당 계정의 모든 지역에서 이 계정을 사용할 수 있습니다.
Azure Cosmos DB 트랜잭션 저장소는 행 지향 반정형 데이터로 간주되지만 분석 저장소에는 열 및 정형 형식이 있습니다. 이 변환은 고객을 위해 분석 저장소에 대한 스키마 유추 규칙을 사용하여 자동으로 수행됩니다. 변환 프로세스에는 최대 중첩 수준 수, 최대 속성 수, 지원되지 않는 데이터 형식 등의 제한이 있습니다.
참고
분석 저장소 컨텍스트에서는 다음 구조를 속성으로 간주합니다.
:으로 구분된 문자열-값 쌍”{ 및 }로 구분된 JSON 개체[ 및 ]로 구분된 JSON 배열다음 기술을 사용하면 스키마 유추 변환의 영향을 최소화하고 분석 기능을 최대화할 수 있습니다.
Azure Synapse Link를 사용하면 T-SQL 또는 Spark SQL을 사용하여 컨테이너 간에 조인할 수 있으므로 정규화는 의미가 없습니다. 정규화에 대해 예상되는 이점은 다음과 같습니다.
이러한 마지막 두 가지 요소, 즉 더 적은 속성 수와 더 적은 수준 수는 분석 쿼리의 성능에 도움이 되지만 분석 저장소에서 데이터의 일부가 표현되지 않을 가능성도 줄어듭니다. 자동 스키마 유추 규칙에 대한 문서에서 설명한 대로 분석 저장소에 표현되는 수준 및 속성 수에는 제한이 있습니다.
정규화에 대한 또 다른 중요한 요소는 Azure Synapse의 SQL 서버리스 풀에서 최대 1,000개의 열이 있는 결과 집합을 지원하고 중첩 열을 공개하는 것도 해당 제한에 포함된다는 것입니다. 즉, 분석 저장소와 Synapse SQL 서버리스 풀 모두의 속성이 1,000개로 제한됩니다.
하지만 비정규화가 Azure Cosmos DB의 중요한 데이터 모델링 기술이므로 어떻게 해야 할까요? 대답은 트랜잭션 및 분석 워크로드에 적합한 균형을 찾아야 한다는 것입니다.
Azure Cosmos DB PK(파티션 키)는 분석 저장소에서 사용되지 않습니다. 이제 원하는 PK를 사용하여 분석 저장소 복사본에 대해 분석 저장소 사용자 지정 분할을 사용할 수 있습니다. 이 격리로 인해 데이터 수집 및 데이터 요소 읽기에 중점을 두는 트랜잭션 데이터에 대한 PK를 선택할 수 있으며, Azure Synapse Link를 사용하여 파티션 간 쿼리를 수행할 수 있습니다. 한 가지 예를 살펴보겠습니다.
가상의 글로벌 IoT 시나리오에서 모든 디바이스에 비슷한 데이터 볼륨이 있고 핫 파티션 문제가 없으므로 device id는 적합한 PK입니다. 그러나 "어제의 모든 데이터" 또는 "도시당 합계"와 같이 둘 이상의 디바이스의 데이터를 분석하려는 경우 파티션 간 쿼리이므로 문제가 있을 수 있습니다. 이러한 쿼리는 요청 단위에서 처리량의 일부를 사용하여 실행하므로 트랜잭션 성능이 저하될 수 있습니다. 그러나 Azure Synapse Link를 사용하면 요청 단위 비용 없이 이러한 분석 쿼리를 실행할 수 있습니다. 분석 저장소 열 형식은 분석 쿼리에 최적화되어 있으며, Azure Synapse Link는 이 특성을 적용하여 Azure Synapse Analytics 런타임에서 뛰어난 성능을 제공합니다.
자동 스키마 유추 규칙 문서에는 지원되는 데이터 형식이 나와 있습니다. 지원되지 않는 데이터 형식은 분석 저장소의 표현을 차단하지만, 지원되는 데이터 형식은 Azure Synapse 런타임에서 다르게 처리될 수 있습니다. 예를 들어 ISO 8601 UTC 표준을 따르는 DateTime 문자열을 사용하는 경우 Azure Synapse의 Spark 풀은 이러한 열을 문자열로 표현하고, Azure Synapse의 SQL 서버리스 풀은 이러한 열을 varchar(8000)로 표현합니다.
또 다른 문제는 Azure Synapse Spark에서 모든 문자를 허용하지는 않는다는 것입니다. 공백은 허용되지만 콜론, 억음 악센트 기호 및 쉼표와 같은 문자는 허용되지 않습니다. 문서에 "이름, 성"이라는 속성이 있다고 가정해 보겠습니다. 이 속성은 분석 저장소에서 표현되며, Synapse SQL 서버리스 풀에서 문제 없이 읽을 수 있습니다. 그러나 분석 저장소에 있으므로 Azure Synapse Spark는 다른 모든 속성을 포함하여 분석 저장소에서 데이터를 읽을 수 없습니다. 결국 가장 중요한 것은 이름에 지원되지 않는 문자를 사용하는 하나의 속성이 있는 경우 Azure Synapse Spark를 사용할 수 없습니다.
Azure Cosmos DB 데이터의 루트 수준에 있는 모든 속성은 분석 저장소에서 열로 표현되고, 문서 데이터 모델의 더 깊은 수준에 있는 다른 모든 속성은 중첩 구조에서도 JSON으로 표현됩니다. 중첩 구조는 Azure Synapse 런타임에서 추가 처리를 요구하여 데이터를 정형 형식으로 평면화합니다. 이는 빅 데이터 시나리오에서 문제가 될 수 있습니다.
문서에는 분석 저장소의 두 개의 열(id 및 contactDetails)만 있습니다. 다른 모든 데이터(email 및 phone)는 개별적으로 읽기 위해 SQL 함수를 통한 추가 처리가 필요합니다.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
문서에는 분석 저장소의 세 개의 열(id, email 및 phone)이 있습니다. 모든 데이터는 열로 직접 액세스할 수 있습니다.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Azure Synapse Link를 사용하면 다음과 같은 관점에서 비용을 줄일 수 있습니다.
이는 데이터 모델이 이미 있고 변경할 수 없는 상황에 대한 훌륭한 대안입니다. 그리고 기존 데이터 모델은 중첩 수준 제한 또는 최대 속성 수와 같은 자동 스키마 유추 규칙으로 인해 분석 저장소에 잘 맞지 않습니다. 이 경우 Azure Cosmos DB 변경 피드를 사용하여 데이터를 다른 컨테이너에 복제하고 Azure Synapse Link 친화적인 데이터 모델에 필요한 변환을 적용할 수 있습니다. 한 가지 예를 살펴보겠습니다.
CustomersOrdersAndItems 컨테이너는 고객 및 항목 세부 정보(예: 청구 주소, 배달 주소, 배달 방법, 배달 상태, 품목 가격 등)를 포함한 온라인 주문을 저장하는 데 사용됩니다. 처음 1,000개의 속성만 표현되고 주요 정보는 분석 저장소에 포함되지 않아 Azure Synapse Link 사용을 차단합니다. 컨테이너에는 애플리케이션을 변경하고 데이터를 리모델링할 수 없는 PB의 레코드가 있습니다.
문제의 또 다른 관점은 빅 데이터 볼륨입니다. 수십억 개의 행이 분석 부서에서 지속적으로 사용되므로 tttl을 오래된 데이터 삭제에 사용할 수 없습니다. 분석 요구로 인해 트랜잭션 데이터베이스의 전체 데이터 기록을 유지 관리하면 요청 단위 프로비전이 지속적으로 증가하여 비용에 영향을 줍니다. 트랜잭션 및 분석 워크로드는 동시에 동일한 리소스를 얻기 위해 경쟁합니다.
그렇다면 어떻게 해야 할까요?
Customers, Orders 및 Items의 세 개의 새 컨테이너를 채우도록 결정했습니다. 변경 피드를 사용하면 데이터를 정규화하고 평면화합니다. 데이터 모델에서 불필요한 정보가 제거되고 각 컨테이너에 100개에 가까운 속성이 있으므로 자동 스키마 유추 제한으로 인한 데이터 손실을 방지할 수 있습니다.CustomersOrdersAndItems 컨테이너에 있습니다. 이에 따라 GB당 1개 이상의 요청 단위가 Azure Cosmos DB에 있으므로 다른 요청 단위 사용량을 줄일 수 있습니다. 데이터가 적으면 요청 단위도 적습니다.이 문서에서 가장 중요한 사항은 스키마가 없는 환경에서의 데이터 모델링도 이전과 같이 중요하다는 것을 이해하는 것입니다.
데이터를 화면에 표현하는 방법이 하나만 있지 않은 것처럼 데이터를 모델링하는 방법도 하나만 있는 것이 아닙니다. 애플리케이션을 이해하고 데이터를 생산, 소비 및 처리하는 방법을 이해해야 합니다. 그런 다음 여기에 제공된 일부 지침을 적용해서 애플리케이션에 즉시 필요한 사항을 처리할 수 있는 모델을 제작 방법을 설정할 수 있습니다. 애플리케이션에 변경이 필요한 경우에는 스키마가 없는 데이터베이스의 유연성을 사용해서 변경 사항을 포용하고 데이터 모델을 쉽게 발전시킬 수 있습니다.
학습
인증
Microsoft Certified: Azure Cosmos DB Developer Specialty - Certifications
Microsoft Azure Cosmos DB를 사용하여 효율적인 쿼리를 작성하고, 인덱싱 정책을 만들고, SQL API 및 SDK에서 리소스를 관리 및 프로비전합니다.