HDInsight에서 Apache Spark를 사용하여 Application Insights 원격 분석 로그 분석
HDInsight에서 Apache Spark를 사용하여 Application Insights 원격 분석 데이터를 분석하는 방법에 대해 알아봅니다.
Visual Studio Application Insights 는 웹 애플리케이션을 모니터링하는 분석 서비스입니다. Application Insights에 의해 생성된 원격 분석 데이터를 Azure Storage로 내보낼 수 있습니다. 데이터가 Azure Storage에 있으면 HDInsight를 사용하여 분석할 수 있습니다.
필수 조건
애플리케이션에서 Application Insights를 사용하도록 구성합니다.
Linux 기반 HDInsight 클러스터를 만드는 데 익숙해야 합니다. 자세한 내용은 HDInsight에서 Apache Spark 만들기를 참조하세요.
웹 브라우저.
이 문서를 개발하고 테스트하는 데 다음 리소스를 사용했습니다.
Application Insights를 사용하도록 구성된 Node.js 웹앱를 사용하여 Application Insights 원격 분석 데이터를 생성했습니다.
HDInsight 클러스터 버전 3.5의 Linux 기반 Spark는 데이터를 분석하는 데 사용되었습니다.
아키텍처 및 계획
다음 다이어그램은 이 예제의 서비스 아키텍처를 보여 줍니다.
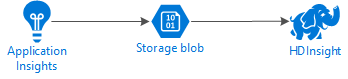
Azure Storage
Application Insights가 Blob에 원격 분석 정보를 지속적으로 내보내도록 구성될 수 있습니다. 그러면 HDInsight는 Blob에 저장된 데이터를 읽을 수 있습니다. 그러나 따라야 할 몇 가지 요구 사항이 있습니다.
위치: Storage 계정 및 HDInsight가 다른 위치에 있는 경우 대기 시간이 증가할 수 있습니다. 또한 지역 간에 이동하는 데이터에 송신 요금이 적용되면 비용이 증가합니다.
Warning
HDInsight와 다른 위치에서는 Storage 계정을 사용할 수 없습니다.
Blob 유형: HDInsight는 블록 Blob만을 지원합니다. Application Insights의 기본값은 블록 Blob을 사용하므로 기본적으로 HDInsight와 함께 사용해야 합니다.
기존 클러스터에 스토리지를 추가하는 방법에 대한 정보는 추가 스토리지 계정 추가 문서를 참조하세요.
데이터 스키마
Application Insights는 Blob으로 내보낸 원격 분석 데이터 형식에 대한 데이터 모델 내보내기 정보를 제공합니다. 이 문서의 단계에서는 Spark SQL을 데이터와 함께 사용합니다. Spark SQL은 Application Insights에 의해 기록된 JSON 데이터 구조체에 대한 스키마를 자동으로 생성할 수 있습니다.
원격 분석 데이터 내보내기
연속 내보내기 구성의 단계에 따라 Azure Storage Blob으로 원격 분석 정보를 내보내도록 Application Insights를 구성합니다.
HDInsight를 구성하여 데이터에 액세스
HDInsight 클러스터를 만드는 경우 클러스터를 만드는 동안 스토리지 계정을 추가합니다.
Azure Storage 계정을 기존 클러스터에 추가하려면 추가 스토리지 계정 추가 문서의 내용을 사용하세요.
데이터 분석: PySpark
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/jupyter로 이동합니다. 여기서 CLUSTERNAME은 클러스터의 이름입니다.Jupyter 페이지의 오른쪽 위 모퉁이에서 새로 만들기, PySpark를 차례로 선택합니다. Python 기반 Jupyter Notebook을 포함하는 새 브라우저 탭이 열립니다.
페이지의 첫 번째 필드(셀이라고 함)에 다음 텍스트를 입력합니다.
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')이 코드는 Spark가 입력 데이터에 대한 디렉터리 구조에 재귀적으로 액세스하도록 구성합니다. Application Insights 원격 분석은
/{telemetry type}/YYYY-MM-DD/{##}/과 유사한 디렉터리 구조에 기록됩니다.SHIFT+ENTER 를 사용하여 코드를 실행합니다. ‘*’가 셀의 왼쪽에 대괄호 사이에 표시되면 이 셀의 코드가 실행되고 있음을 나타냅니다. 완료되면 ‘*’는 번호로 변경되고 셀 아래에 다음 텍스트와 유사한 출력이 표시됩니다.
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...새 셀은 첫 번째 셀의 아래에 생성됩니다. 새 셀에서 다음 텍스트를 입력합니다.
CONTAINER및STORAGEACCOUNT를 Application Insights 데이터를 포함하는 Azure Storage 계정 이름 및 Blob 컨테이너 이름으로 바꿉니다.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/SHIFT+ENTER를 사용하여 이 셀을 실행합니다. 다음 텍스트와 유사한 결과가 표시됩니다.
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831반환되는 wasbs 경로는 Application Insights 원격 분석 데이터의 위치입니다. 반환되는 wasbs 경로를 사용하도록 셀의
hdfs dfs -ls줄을 변경한 다음 SHIFT+ENTER를 사용하여 셀을 다시 실행합니다. 이번 결과는 원격 분석 데이터를 포함하는 디렉터리를 표시해야 합니다.참고 항목
이 섹션의 나머지 단계에서는
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests디렉터리를 사용했습니다. 사용자의 디렉터리 구조는 다를 수 있습니다.다음 셀에서 다음 코드를 입력합니다.
WASB_PATH를 이전 단계의 경로로 바꿉니다.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)이 코드는 연속 내보내기 프로세스에서 내보낸 JSON 파일에서 데이터 프레임을 만듭니다. SHIFT+ENTER 를 사용하여 이 셀을 실행합니다.
다음 셀에서 다음을 입력하고 실행하여 Spark가 JSON 파일에 대해 만든 스키마를 봅니다.
jsonData.printSchema()각 유형의 원격 분석에 대한 스키마는 달라질 수 있습니다. 다음 예제는 웹 요청(
Requests하위 디렉터리에 저장된 데이터)에 대해 생성되는 스키마입니다.root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)다음을 사용하여 데이터 프레임을 임시 테이블로 등록하고 데이터에 대해 쿼리를 실행합니다.
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()이 쿼리는 상위 20개 레코드에 대한 도시 정보를 반환합니다. 여기서 context.location.city는 null이 아닙니다.
참고 항목
컨텍스트 구조는 Application Insights에 의해 기록된 모든 원격 분석에 표시됩니다. 도시 요소는 로그에서 채워지지 않을 수 있습니다. 스키마를 사용하여 로그에 대한 데이터를 포함하는 쿼리할 수 있는 다른 요소를 식별합니다.
이 쿼리는 다음 텍스트와 비슷한 정보를 반환합니다.
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
데이터 분석: Scala
웹 브라우저에서
https://CLUSTERNAME.azurehdinsight.net/jupyter로 이동합니다. 여기서 CLUSTERNAME은 클러스터의 이름입니다.Jupyter 페이지의 오른쪽 위 모퉁이에서 새로 만들기, Scala를 차례로 선택합니다. Scala 기반 Jupyter Notebook을 포함하는 새 브라우저 탭이 나타납니다.
페이지의 첫 번째 필드(셀이라고 함)에 다음 텍스트를 입력합니다.
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")이 코드는 Spark가 입력 데이터에 대한 디렉터리 구조에 재귀적으로 액세스하도록 구성합니다. Application Insights 원격 분석은
/{telemetry type}/YYYY-MM-DD/{##}/과 유사한 디렉터리 구조에 기록됩니다.SHIFT+ENTER 를 사용하여 코드를 실행합니다. ‘*’가 셀의 왼쪽에 대괄호 사이에 표시되면 이 셀의 코드가 실행되고 있음을 나타냅니다. 완료되면 ‘*’는 번호로 변경되고 셀 아래에 다음 텍스트와 유사한 출력이 표시됩니다.
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...새 셀은 첫 번째 셀의 아래에 생성됩니다. 새 셀에서 다음 텍스트를 입력합니다.
CONTAINER및STORAGEACCOUNT를 Application Insights 로그를 포함하는 Azure Storage 계정 이름 및 Blob 컨테이너 이름으로 바꿉니다.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/SHIFT+ENTER를 사용하여 이 셀을 실행합니다. 다음 텍스트와 유사한 결과가 표시됩니다.
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831반환되는 wasbs 경로는 Application Insights 원격 분석 데이터의 위치입니다. 반환되는 wasbs 경로를 사용하도록 셀의
hdfs dfs -ls줄을 변경한 다음 SHIFT+ENTER를 사용하여 셀을 다시 실행합니다. 이번 결과는 원격 분석 데이터를 포함하는 디렉터리를 표시해야 합니다.참고 항목
이 섹션의 나머지 단계에서는
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests디렉터리를 사용했습니다. 원격 분석 데이터가 웹앱에 대한 것이 아니면 이 디렉터리는 없을 수도 있습니다.다음 셀에서 다음 코드를 입력합니다.
WASB\_PATH를 이전 단계의 경로로 바꿉니다.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)이 코드는 연속 내보내기 프로세스에서 내보낸 JSON 파일에서 데이터 프레임을 만듭니다. SHIFT+ENTER 를 사용하여 이 셀을 실행합니다.
다음 셀에서 다음을 입력하고 실행하여 Spark가 JSON 파일에 대해 만든 스키마를 봅니다.
jsonData.printSchema각 유형의 원격 분석에 대한 스키마는 달라질 수 있습니다. 다음 예제는 웹 요청(
Requests하위 디렉터리에 저장된 데이터)에 대해 생성되는 스키마입니다.root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)다음을 사용하여 데이터 프레임을 임시 테이블로 등록하고 데이터에 대해 쿼리를 실행합니다.
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()이 쿼리는 상위 20개 레코드에 대한 도시 정보를 반환합니다. 여기서 context.location.city는 null이 아닙니다.
참고 항목
컨텍스트 구조는 Application Insights에 의해 기록된 모든 원격 분석에 표시됩니다. 도시 요소는 로그에서 채워지지 않을 수 있습니다. 스키마를 사용하여 로그에 대한 데이터를 포함하는 쿼리할 수 있는 다른 요소를 식별합니다.
이 쿼리는 다음 텍스트와 비슷한 정보를 반환합니다.
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
다음 단계
Azure의 데이터와 서비스 작업에 Apache Spark를 사용하는 더 많은 예제는 다음 문서를 참조하세요.
- BI와 Apache Spark: BI 도구와 함께 HDInsight의 Spark를 사용하여 대화형 데이터 분석 수행
- Machine Learning과 Apache Spark: HVAC 데이터를 사용하여 건물 온도를 분석하는 데 HDInsight의 Spark 사용
- Machine Learning과 Apache Spark: HDInsight의 Spark를 사용하여 식품 검사 결과 예측
- HDInsight의 Apache Spark를 사용한 웹 사이트 로그 분석
Spark 애플리케이션을 만들고 실행하는 자세한 내용은 다음 문서를 참조하세요.