이 문서에서는 검색 증강 생성을 통해 LLM이 학습하지 않고도 데이터 원본을 지식으로 처리할 수 있는 방법을 설명합니다.
LLM은 학습을 통해 광범위한 기술 자료를 갖추고 있습니다. 대부분의 시나리오에서는 요구 사항에 맞게 설계된 LLM을 선택할 수 있지만 해당 LLM은 특정 데이터를 이해하기 위한 추가 교육이 여전히 필요합니다. 검색 증강 생성을 사용하면 먼저 데이터를 학습하지 않고도 LLM에서 데이터를 사용할 수 있습니다.
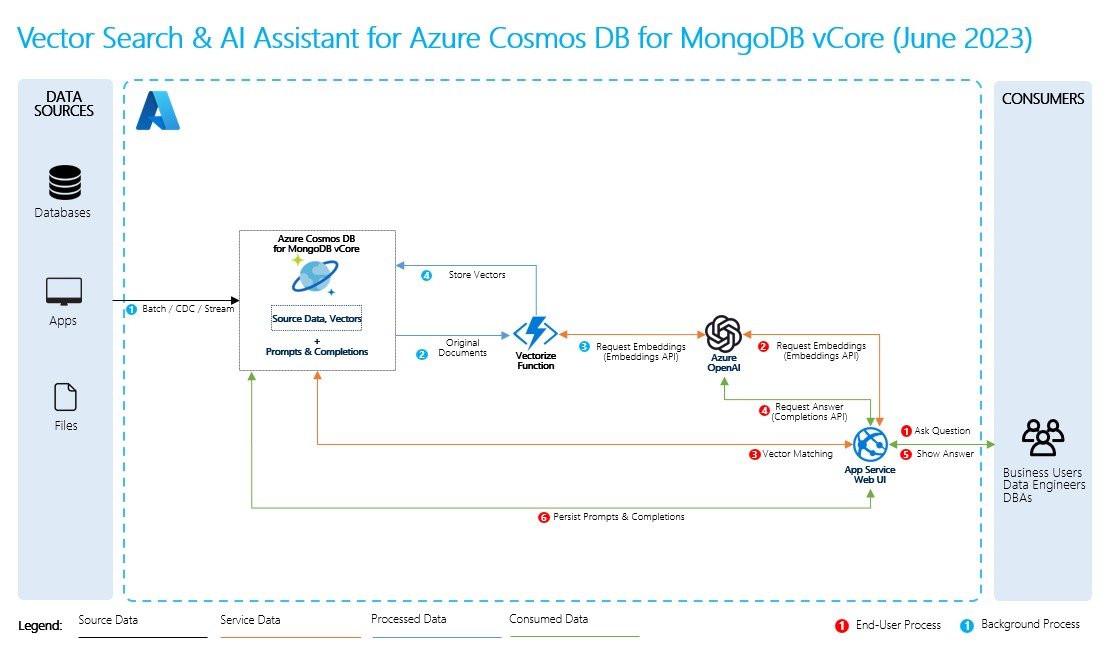
RAG의 작동 방식
검색 증강 생성을 수행하기 위해 데이터와 데이터에 관한 일반적인 질문들을 위한 임베딩을 만듭니다. 즉석에서 이 작업을 수행할 수도 있고, 벡터 데이터베이스 솔루션을 사용하여 포함을 만들고 저장할 수도 있습니다.
사용자가 질문하면 LLM은 임베딩을 사용하여 사용자의 질문을 데이터와 비교하고 가장 관련성이 높은 맥락을 찾습니다. 이 컨텍스트와 사용자의 질문은 프롬프트에서 LLM으로 이동하고 LLM은 데이터를 기반으로 응답을 제공합니다.
기본 RAG 프로세스
RAG를 수행하려면 검색에 사용할 각 데이터 원본을 처리해야 합니다. 기본 프로세스는 다음과 같습니다.
- 대용량 데이터를 관리 가능한 조각으로 청크합니다.
- 청크를 검색 가능한 형식으로 변환합니다.
- 변환된 데이터를 효율적인 액세스를 허용하는 위치에 저장합니다. 또한 LLM이 응답을 제공할 때 인용 또는 참조에 대한 관련 메타데이터를 저장하는 것이 중요합니다.
- 프롬프트에서 변환된 데이터를 LLM에 공급하세요.
- 원본 데이터: 데이터가 있는 위치입니다. 이는 컴퓨터의 파일/폴더, 클라우드 리포지토리의 파일, Azure Machine Learning 데이터 자산, Git 리포지토리 또는 SQL 데이터베이스일 수 있습니다.
- 데이터 청크: 원본의 데이터를 일반 텍스트로 변환해야 합니다. 예를 들어, 워드 문서나 PDF를 크랙하여 열고 텍스트로 변환해야 합니다. 그러면 텍스트가 더 작은 조각으로 나누어집니다.
- 텍스트를 벡터로 변환: 임베딩입니다. 벡터는 개념을 숫자 시퀀스로 변환한 숫자 표현으로, 컴퓨터가 해당 개념 간의 관계를 쉽게 이해할 수 있도록 해줍니다.
- 원본 데이터와 포함 간의 링크: 이 정보는 사용자가 만든 청크에 메타데이터로 저장되며, LLM이 응답을 생성하는 동안 인용을 생성하는 데 사용됩니다.
참고하십시오
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET