Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Databasespeiling i Microsoft Fabric er en skybasert, null-ETL, SaaS-teknologi for bedrifter. Denne veiledningen hjelper deg med å opprette en speilet database fra Azure Databricks, som oppretter en skrivebeskyttet, kontinuerlig replikert kopi av Azure Databricks-dataene dine i OneLake.
Forutsetning
- Et stoffarbeidsområde.
- Aktiver ekstern datatilgang i metastore. Hvis du vil ha mer informasjon, kan du se Aktivere ekstern datatilgang i metalageret.
- Opprett eller bruk et eksisterende Azure Databricks-arbeidsområde med Unity Catalog aktivert.
- Ha
EXTERNAL USE SCHEMA-privilegiet på skjemaet i Unity Catalog som inneholder tabellene Fabric tilgang til. - Bruk Fabrics tillatelsesmodell til å angi tilgangskontroller for kataloger, skjemaer og tabeller i Fabric.
Opprett en speilet database fra Azure Databricks
Følg disse trinnene for å opprette en ny speilet database fra Azure Databricks Unity-katalogen.
Gå til arbeidsplassen din i Fabric.
Velg Nytt element>Speilet Azure Databricks katalog.

Velg en eksisterende tilkobling hvis du har en konfigurert, eller lag en ny tilkobling.
Hvis du vil opprette en tilkobling, må du være enten bruker eller administrator for Azure Databricks-arbeidsområdet. Du kan autentisere deg til ditt Azure Databricks arbeidsområde ved å bruke Organizational account eller Service principal autentisering.
Note
Autentiseringsvalget du gjør her gjelder Databricks-autentisering og Unity Catalog-autorisasjon. Hvis du trenger tilgang til Azure Data Lake Storage (ADLS) Gen2-kontoer bak en brannmur, følg trinnene for å Aktiver nettverkssikkerhetstilgang for din Azure Data Lake Storage Gen2-konto senere i denne artikkelen. Når ADLS Gen2 er bak en brannmur, kreves Fabric Workspace Identity for lagring av brannmurtilgang, uavhengig av hvilken autentiseringsmetode som er valgt for Databricks-tilkoblingen.
Etter at du kobler til et Azure Databricks arbeidsområde, på siden Velg tabeller fra en Databricks-katalog-siden, velger du katalogen, skjemaene og tabellene du vil legge til og få tilgang til fra Fabric ved å bruke inkluderings- eller eksklusjonslisten. Velg katalogen og de relaterte skjemaene og tabellene du vil legge til i Fabric-arbeidsområdet.
Du kan bare se katalogene, skjemaene og tabellene du har tilgang til. For mer informasjon, se Unity Catalog-privilegier og securable objects.
Som standard er alternativet Automatisk synkronisering av fremtidige katalogendringer for det valgte skjemaet aktivert. For mer informasjon, se Mirroring Azure Databricks > Metadata sync.
Velg Neste for å fortsette.
På siden Gjennomgå og opprett kan du gå gjennom detaljene og eventuelt endre navnet på det speilede databaseelementet, som må være unikt i arbeidsområdet ditt. Som standard er navnet på det speilede elementet navnet på katalogen.
Velg Opprett for å fortsette.
Et Databricks-katalogelement opprettes, og for hver tabell opprettes det også en tilsvarende snarvei av Databricks-typen.
Skjemaer som ikke har noen tabeller, vises ikke.
Du kan også se en forhåndsvisning av dataene når du åpner en snarvei ved å velge SQL-analyseendepunktet. Åpne SQL Analytics-endepunktelementet for å starte siden Utforsker og spørringsredigering. Du kan spørre dine speilede Azure Databricks-tabeller ved å bruke T-SQL i SQL Editor.
Opprette Lakehouse-snarveier til Databricks-katalogelementet
Du kan også opprette snarveier fra Lakehouse til Databricks-katalogelementet for å bruke Lakehouse-dataene og bruke Spark Notebooks.
- Først, lag et hytte ved innsjøen. Hvis du allerede har et innsjøhus i dette arbeidsområdet, kan du bruke et eksisterende innsjøhus.
- Velg arbeidsområdet ditt i navigasjonsmenyen.
- Velg + Nytt>innsjøhus.
- Angi et navn på innsjøen i Navn-feltet , og velg Opprett.
- I Utforsker-visningen av innsjøhuset, i Hent data i innsjøhuset-menyen , under Last inn data i innsjøhuset, velger du Ny snarveisknapp .
- Velg Microsoft OneLake. Velg en katalog. Dette er dataelementet du opprettet i de forrige trinnene. Velg deretter Neste.
- Velg tabeller i skjemaet, og velg Neste.
- Velg Opprett.
- Snarveier er nå tilgjengelige i Lakehouse for bruk med andre Lakehouse-data. Du kan også bruke notatblokker og Spark til å utføre databehandling på dataene for disse katalogtabellene som du har lagt til fra Azure Databricks-arbeidsområdet.
Opprette en semantisk modell
Du kan lage en Power BI semantisk modell basert på ditt speilede element, og manuelt legge til eller fjerne tabeller. Hvis du vil ha mer informasjon om hvordan du oppretter og administrerer semantiske modeller, kan du se Opprette en semantisk modell for Power BI.
For best mulig opplevelse, bruk Microsoft Edge-nettleseren for semantiske modelleringsoppgaver.
Administrere semantiske modellrelasjoner
Etter at du har opprettet en ny semantisk modell basert på din speilede database, konfigurer relasjonene mellom tabellene.
- Velg Modelloppsett fra utforskeren i arbeidsområdet.
- Når du velger modelloppsett, får du presentert en grafikk av tabellene som er inkludert som en del av den semantiske modellen.
- Hvis du vil opprette relasjoner mellom tabeller, drar du et kolonnenavn fra én tabell til et annet kolonnenavn i en annen tabell. En popup vises for å identifisere forholdet og kardinaliteten for tabellene.
Aktiver tilgang til nettverkssikkerhet for Azure Data Lake Storage Gen2-kontoen din
Konfigurer nettverkssikkerhet for din Azure Data Lake Storage (ADLS) Gen2-konto når du har en Azure Storage brannmur konfigurert. Denne seksjonen gjelder for ADLS Gen2-lagringskontoer bak en Azure Storage-brannmur. Azure Databricks workspace storage bak en Azure Storage-brannmur støttes ikke.
Forutsetning
Når en Azure Storage-brannmur beskytter ADLS Gen2, bruker Fabric Workspace Identity for å få tilgang til brannmuren. Selv om du velger Service Principal for ADLS-autentisering i fanen Network Security, må du tillate arbeidsplassidentiteten i Azure Storage kontobrannmur.
Workspace Identity brukes for tilgang til lagringsbrannmur. En tjenesteprincipal eller OAuth brukes for Databricks-autentisering og Unity Catalog-autorisasjon.
For å aktivere autentiseringstypen for arbeidsområdets identitet (anbefalt), knyt Fabric-arbeidsområdet til en F-kapasitet. Hvis du vil opprette en arbeidsområdeidentitet, kan du se Godkjenne med arbeidsområdeidentitet.
Du kan bare knytte en katalog til én lagringskonto.
Aktiver tilgang til nettverkssikkerhet
Når du oppretter en ny speilet Azure Databricks-katalog, velger du kategorien Nettverkssikkerhet i trinnet Velg data.
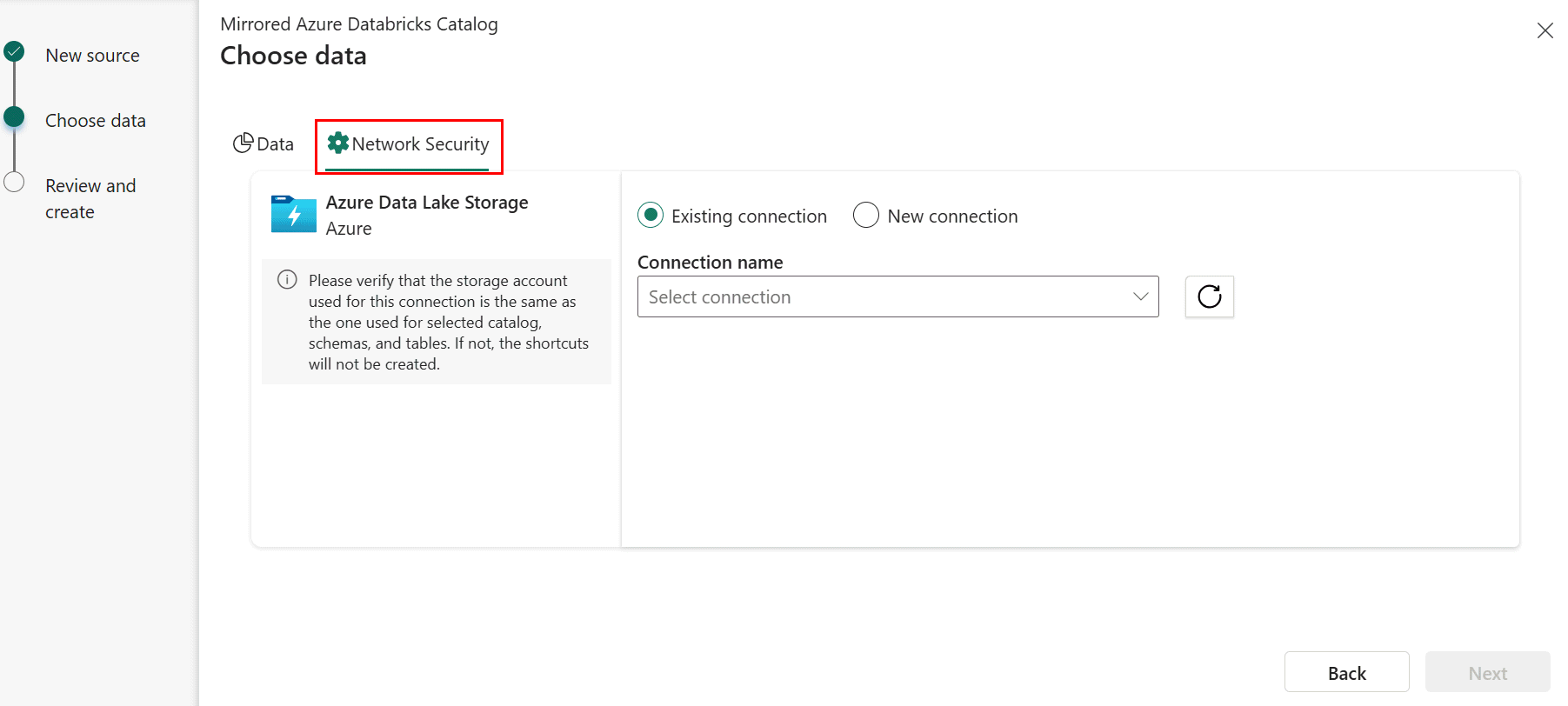
Velg en eksisterende tilkobling til lagringskontoen hvis du har konfigurert en.
- Hvis du ikke har en eksisterende ADLS-tilkobling, oppretter du en ny tilkobling.
-
URL-adressen til lagringsendepunktet er der dataene til den valgte katalogen er lagret. Endepunktet bør være den bestemte mappen der dataene er lagret, i stedet for å angi endepunktet til å være på lagringskontonivå. Gi
https://<storage account>.dfs.core.windows.net/container1/folder1for eksempel i stedet forhttps://<storage account>.dfs.core.windows.net/. - Oppgi tilkoblingslegitimasjonen. Godkjenningstypene som støttes, er organisasjonskonto, tjenestekontohaver og arbeidsområdeidentitet (anbefales).
Note
Når ADLS Gen2 er beskyttet av en Azure Storage-brannmur, bruker Fabric Workspace Identity for å gå gjennom brannmuren uavhengig av hvilken autentiseringstype som er valgt her. Autentisasjonstypen (Service Principal eller Organizational account) styrer Databricks-autentisering og Unity Catalog-autorisasjon, mens Workspace Identity kontrollerer betrodd tilgang gjennom lagringsbrannmuren. Workspace-identiteten må være tillatt i brannmuren til Azure Storage-kontoen selv om du velger en annen autentiseringstype for ADLS-tilkoblingen.
I Azure-portalen gir du tilgangsrettigheter til lagringskontoen basert på godkjenningstypen du valgte i forrige trinn. Gå til lagringskontoen i Azure-portalen. Velg Tilgangskontroll (IAM). Velg +Legg til og Legg til rolletilordning. Hvis du vil ha mer informasjon, kan du se Tilordne Azure-roller ved hjelp av Azure-portalen.
Tildel en rolle basert på omfanget av forbindelsen:
- Lagringskonto: Den valgte autentiseringsidentiteten trenger Storage Blob Data Reader-rollen på lagringskontoen.
- Container: Den valgte autentiseringsidentiteten trenger Storage Blob Data Reader-rollen på containeren.
- Mappe i en beholder (anbefalt): Den valgte autentiseringsidentiteten trenger Read (R) og Execute (E) tillatelser på mappenivå. Hvis du bruker Service Principal eller Workspace Identity som autentiseringstype, gi også den identiteten Execute-tillatelser på rotmappen i containeren og hver mappe i hierarkiet som leder til den angitte mappen.
Hvis du vil ha mer informasjon og fremgangsmåte for å gi ADLS-tilgang, kan du se ADLS-tilgangskontroll.
Aktiver Trusted Workspace Access ved å konfigurere en ressursinstansregel for ditt Fabric arbeidsområde på lagringskontoen. For detaljerte steg, se Trusted workspace access og Secure Fabric speilede databaser fra Azure Databricks.
Etter at tilkoblingen er etablert, opprettes en snarvei til Unity-katalogtabeller for tabellene hvis lagringskontonavn samsvarer med lagringskontoen spesifisert i ADLS-tilkoblingen. Snarveier lages ikke for tabeller hvis lagringskontonavn ikke stemmer overens.
Viktig!
Hvis du planlegger å bruke ADLS-tilkoblingen utenfor Mirrored Azure Databricks katalogobjekt-scenarioene, må du også tildele rollen Storage Blob Delegator på lagringskontoen.
Tips
Hvis du får en 403-autorisasjonsfeil når du bruker en Service Principal for Databricks-autentisering med en brannmurbeskyttet ADLS Gen2-konto, verifiser at arbeidsplassidentiteten er tillatt i brannmuren til Azure Storage-kontoen. Selv når en Service Principal er valgt for autentisering, bruker Fabric Workspace Identity for å gå gjennom lagringsbrannmuren.
Aktivere OneLake-sikkerhet på det speilede Databricks-elementet
Tilordne Unity Catalog (UC)-policyer til Microsoft OneLake-sikkerhet ved å følge disse trinnene:
- Synkroniser Entra-gruppen og bruk tillatelser i Unity Catalog. I Azure Databricks kan du bruke automatisk identitetsstyring for å synkronisere en Microsoft Entra ID-gruppe og gi den nødvendige Unity-katalogrettigheter (USE, BROWSE og SELECT) på den relevante katalogen og tabellene.
- Tilordne en OneLake-datatilgangsrolle. I Fabric-arbeidsområdet oppretter du en datatilgangsrolle for de nylig speilede dataene. Legg til den samme Entra-gruppen i denne rollen, og gi den lesetilgang til OneLake-snarveiene som tilsvarer Azure Databricks-tabellene. For å komme i gang med sikkerhet på tabellnivå, velg knappen Administrer OneLake sikkerhet i båndet. Sørg for at du holder tilgangskonfigurasjoner synkronisert etter hvert som katalogstrukturer og tillatelser utvikler seg. Hvis du vil ha mer informasjon, kan du se OneLake-modellen for datatilgangskontroll (forhåndsversjon).
Relatert innhold
- Secure Fabric speilede databaser fra Azure Databricks
- Blogg: Sikre speilede Azure Databricks-data i Fabric med OneLake-sikkerhet
- Begrensninger i Microsoft Fabric-speilede databaser fra Azure Databricks
- Vanlige spørsmål om speilede databaser fra Azure Databricks i Microsoft Fabric
- Speiling av Azure Databricks Unity-katalog
- Kontrollere ekstern tilgang til data i Unity Catalog