Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u geen gegevensintegratie hebt, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Volg dit artikel als u de JSON-bestanden wilt parseren of de gegevens naar de JSON-indeling wilt schrijven.
JSON-indeling wordt ondersteund voor de volgende connectors:
- Amazon S3
- Amazon S3-compatibele opslag,
- Azure blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Bestandssysteem
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets . Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de JSON-gegevensset.
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op Json. | Ja |
| locatie | Locatie-instellingen van de bestanden. Elke op bestanden gebaseerde connector heeft een eigen locatietype en ondersteunde eigenschappen onder location.
Zie de details in het connectorartikel -> sectie Eigenschappen van gegevensset. |
Ja |
| encodingName | Het coderingstype dat wordt gebruikt voor het lezen/schrijven van testbestanden. Toegestane waarden zijn als volgt: "UTF-8","UTF-8 zonder BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1255"2", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
Nee |
| compressie | Groep eigenschappen voor het configureren van bestandscompressie. Configureer deze sectie wanneer u compressie/decompressie wilt uitvoeren tijdens de uitvoering van de activiteit. | Nee |
| type (onder compression) |
De compressiecodec die wordt gebruikt voor het lezen/schrijven van JSON-bestanden. Toegestane waarden zijn bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy of lz4. De standaardwaarde wordt niet gecomprimeerd. Note ondersteunt momenteel Copy-activiteit geen "snappy" en "lz4" en toewijzingsgegevensstroom biedt geen ondersteuning voor "ZipDeflate", "TarGzip" en "Tar". Opmerking wanneer u kopieeractiviteit gebruikt om ZipDeflate TarGzip/en schrijven naar een of meer op bestanden gebaseerde sinkgegevensopslag. Standaard worden bestanden uitgepakt in de map:, gebruikt/ <path specified in dataset>/<folder named as source compressed file>/u bij preserveZipFileNameAsFolder om te bepalen of u de naam van de gecomprimeerde bestanden als mapstructuur wilt behouden. |
Nee |
| niveau (onder compression) |
De compressieverhouding. Toegestane waarden zijn Optimaal of Snelste. - Snelste: De compressiebewerking moet zo snel mogelijk worden voltooid, zelfs als het resulterende bestand niet optimaal is gecomprimeerd. - Optimaal: De compressiebewerking moet optimaal worden gecomprimeerd, zelfs als het langer duurt om de bewerking te voltooien. Zie het onderwerp Compressieniveau voor meer informatie. |
Nee |
Hieronder ziet u een voorbeeld van een JSON-gegevensset in Azure Blob Storage:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Copy-activiteit eigenschappen
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de JSON-bron en -sink.
Meer informatie over het extraheren van gegevens uit JSON-bestanden en het toewijzen aan sinkgegevensopslag/-indeling of omgekeerd van schematoewijzing.
JSON als bron
De volgende eigenschappen worden ondersteund in de sectie kopieeractiviteit *source* .
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op JSONSource. | Ja |
| formatSettings | Een groep eigenschappen. Raadpleeg de onderstaande tabel met leesinstellingen voor JSON. | Nee |
| storeSettings | Een groep eigenschappen over het lezen van gegevens uit een gegevensarchief. Elke op bestanden gebaseerde connector heeft zijn eigen ondersteunde leesinstellingen onder storeSettings.
Meer informatie vindt u in het connectorartikel -> Copy-activiteit properties section. |
Nee |
Ondersteunde JSON-leesinstellingen onder formatSettings:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | Het type formatSettings moet worden ingesteld op JsonReadSettings. | Ja |
| compressionProperties | Een groep eigenschappen over het decomprimeren van gegevens voor een bepaalde compressiecodec. | Nee |
| preserveZipFileNameAsFolder (onder compressionProperties->type als ZipDeflateReadSettings) |
Is van toepassing wanneer de invoergegevensset is geconfigureerd met ZipDeflate-compressie . Hiermee wordt aangegeven of de naam van het zip-bronbestand moet worden bewaard als mapstructuur tijdens het kopiëren. - Als deze is ingesteld op true (standaard), schrijft de service uitgepakte bestanden naar <path specified in dataset>/<folder named as source zip file>/.- Als deze is ingesteld op onwaar, schrijft de service uitgepakte bestanden rechtstreeks naar <path specified in dataset>. Zorg ervoor dat u geen dubbele bestandsnamen in verschillende zip-bronbestanden hebt om racen of onverwacht gedrag te voorkomen. |
Nee |
| preserveCompressionFileNameAsFolder (onder compressionProperties->type als TarGZipReadSettings of TarReadSettings) |
Is van toepassing wanneer de invoergegevensset is geconfigureerd met Tar-compressie van Tar./ Geeft aan of de gecomprimeerde bronbestandsnaam behouden moet blijven als mapstructuur tijdens het kopiëren. - Als deze is ingesteld op true (standaard), schrijft de service gedecomprimeerde bestanden naar <path specified in dataset>/<folder named as source compressed file>/. - Als deze is ingesteld op onwaar, schrijft de service gedecomprimeerde bestanden rechtstreeks naar <path specified in dataset>. Zorg ervoor dat u geen dubbele bestandsnamen in verschillende bronbestanden hebt om racen of onverwacht gedrag te voorkomen. |
Nee |
JSON als sink
De volgende eigenschappen worden ondersteund in de sectie kopieeractiviteit *sink* .
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op JSONSink. | Ja |
| formatSettings | Een groep eigenschappen. Raadpleeg de onderstaande tabel met JSON-schrijfinstellingen. | Nee |
| storeSettings | Een groep eigenschappen over het schrijven van gegevens naar een gegevensarchief. Elke op bestanden gebaseerde connector heeft zijn eigen ondersteunde schrijfinstellingen onder storeSettings.
Meer informatie vindt u in het connectorartikel -> Copy-activiteit properties section. |
Nee |
Ondersteunde JSON-schrijfinstellingen onder formatSettings:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | Het type formatSettings moet worden ingesteld op JsonWriteSettings. | Ja |
| filePattern | Hiermee geeft u het patroon aan van gegevens die zijn opgeslagen in elk JSON-bestand. Toegestane waarden zijn: setOfObjects (JSON Lines) en arrayOfObjects. De standaardwaarde is setOfObjects. Zie het gedeelte JSON-bestandpatronen voor meer informatie over deze patronen. | Nee |
JSON-bestandpatronen
Bij het kopiëren van gegevens uit JSON-bestanden kan de kopieeractiviteit automatisch de volgende patronen van JSON-bestanden detecteren en parseren. Wanneer u gegevens naar JSON-bestanden schrijft, kunt u het bestandspatroon configureren op de sink van de kopieeractiviteit.
Type I: setOfObjects
Elk bestand bevat één object, JSON-regels of samengevoegde objecten.
voorbeeld van JSON-bestand met één object
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON-lijnen (standaard voor sink)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}voorbeeld van JSON-bestand met samengevoegde objecten
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Type II: arrayOfObjects
Elk bestand bevat een matrix met objecten.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Eigenschappen van toewijzingsgegevensstroom
In mapping van gegevensstromen kunt u de JSON-indeling lezen en schrijven in de volgende gegevensarchieven: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 en SFTP en u kunt JSON-indeling lezen in Amazon S3.
Broneigenschappen
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een json-bron. U kunt deze eigenschappen bewerken op het tabblad Bronopties .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Paden met jokertekens | Alle bestanden die overeenkomen met het jokertekenpad worden verwerkt. Hiermee overschrijft u de map en het bestandspad dat is ingesteld in de gegevensset. | nee | Tekenreeks[] | jokertekenpaden |
| Hoofdpad voor partitie | Voor bestandsgegevens die zijn gepartitioneerd, kunt u een partitiehoofdpad invoeren om gepartitioneerde mappen als kolommen te lezen | nee | String | partitionRootPath |
| Lijst met bestanden | Of uw bron verwijst naar een tekstbestand waarin bestanden worden vermeld die moeten worden verwerkt | nee |
true of false |
fileList |
| Kolom voor het opslaan van de bestandsnaam | Een nieuwe kolom maken met de naam en het pad van het bronbestand | nee | String | rowUrlColumn |
| Na voltooiing | Verwijder of verplaats de bestanden na verwerking. Bestandspad begint vanuit de hoofdmap van de container | nee | Verwijderen: true of false Bewegen: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filteren op laatst gewijzigd | Kiezen om bestanden te filteren op basis van wanneer ze voor het laatst zijn gewijzigd | nee | Tijdstempel | modifiedAfter modifiedBefore |
| Eén document | Toewijzingsgegevensstromen lezen één JSON-document uit elk bestand | nee |
true of false |
singleDocument |
| Niet-aanhalingeerde kolomnamen | Als niet-aanhalingstekens voor kolomnamen zijn geselecteerd, worden in toewijzingsgegevensstromen JSON-kolommen gelezen die niet tussen aanhalingstekens staan. | nee |
true of false |
unquotedColumnNames |
| Bevat opmerkingen | Selecteer Heeft opmerkingen als de JSON-gegevens C- of C++-stijlopmerkingen bevatten | nee |
true of false |
asComments |
| Enkel aan citeren | Leest JSON-kolommen die niet tussen aanhalingstekens worden geplaatst | nee |
true of false |
singleQuoted |
| Backslash is ontsnapt | Selecteer Backslash escaped als backslashes worden gebruikt om tekens in de JSON-gegevens te escapen | nee |
true of false |
backslashEscape |
| Geen bestanden gevonden toestaan | Indien waar, wordt er geen fout gegenereerd als er geen bestanden worden gevonden | nee |
true of false |
ignoreNoFilesFound |
Inlinegegevensset
Toewijzingsgegevensstromen ondersteunen 'inlinegegevenssets' als optie voor het definiëren van uw bron en sink. Een inline JSON-gegevensset wordt rechtstreeks in uw bron- en sinktransformaties gedefinieerd en wordt niet gedeeld buiten de gedefinieerde gegevensstroom. Het is handig om gegevensseteigenschappen rechtstreeks in uw gegevensstroom te parameteriseren en kan profiteren van verbeterde prestaties ten opzichte van gedeelde ADF-gegevenssets.
Wanneer u grote aantallen bronmappen en bestanden leest, kunt u de prestaties van de detectie van gegevensbestanden verbeteren door de optie 'Door gebruiker geprojecteerd schema' in de projectie in te stellen | Dialoogvenster Schemaopties. Met deze optie wordt de automatische detectie van het standaardschema van ADF uitgeschakeld en worden de prestaties van bestandsdetectie aanzienlijk verbeterd. Voordat u deze optie instelt, moet u de JSON-projectie importeren zodat ADF een bestaand schema voor projectie heeft. Deze optie werkt niet met schemadrift.
Opties voor bronindeling
Door een JSON-gegevensset als bron in uw gegevensstroom te gebruiken, kunt u vijf extra instellingen instellen. Deze instellingen vindt u onder de accordeon JSON-instellingen op het tabblad Bronopties. Voor de instelling Documentformulier kunt u één document, document per regel en matrix van documenttypen selecteren.
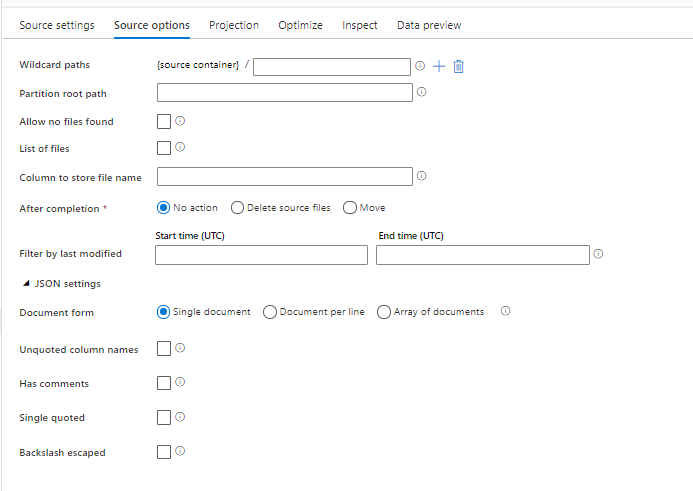
Standaardinstelling
JSON-gegevens worden standaard gelezen in de volgende indeling.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Eén document
Als één document is geselecteerd, lezen toewijzingsgegevensstromen één JSON-document uit elk bestand.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Als Document per regel is geselecteerd, lezen toewijzingsgegevensstromen één JSON-document van elke regel in een bestand.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Als matrix met documenten is geselecteerd, lezen toewijzingsgegevensstromen één matrix van het document uit een bestand.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Notitie
Als gegevensstromen een fout genereren met de melding 'corrupt_record' bij het bekijken van uw JSON-gegevens, is het waarschijnlijk dat uw gegevens één document in uw JSON-bestand bevatten. Als u één document instelt, moet deze fout worden gewist.
Niet-aanhalingeerde kolomnamen
Als niet-aanhalingstekens voor kolomnamen zijn geselecteerd, worden in toewijzingsgegevensstromen JSON-kolommen gelezen die niet tussen aanhalingstekens staan.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Bevat opmerkingen
Selecteer Heeft opmerkingen als de JSON-gegevens C- of C++-stijlopmerkingen bevatten.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Enkel aan citeren
Selecteer Enkele aanhalingstekens als de JSON-velden en -waarden enkele aanhalingstekens gebruiken in plaats van dubbele aanhalingstekens.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Backslash is ontsnapt
Selecteer Backslash escaped als backslashes worden gebruikt om tekens in de JSON-gegevens te escapen.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Eigenschappen van sink
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een json-sink. U kunt deze eigenschappen bewerken op het tabblad Instellingen .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Ga naar de map | Als de doelmap is gewist voordat u gaat schrijven | nee |
true of false |
truncate |
| Optie voor bestandsnaam | De naamgevingsindeling van de geschreven gegevens. Standaard één bestand per partitie in indeling part-#####-tid-<guid> |
nee | Patroon: Tekenreeks Per partitie: Tekenreeks[] Als gegevens in kolom: Tekenreeks Uitvoer naar één bestand: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
JSON-structuren maken in een afgeleide kolom
U kunt een complexe kolom toevoegen aan uw gegevensstroom via de opbouwfunctie voor afgeleide kolomexpressies. Voeg in de afgeleide kolomtransformatie een nieuwe kolom toe en open de opbouwfunctie voor expressies door op het blauwe vak te klikken. Als u een kolomcomplex wilt maken, kunt u de JSON-structuur handmatig invoeren of de UX gebruiken om subkolommen interactief toe te voegen.
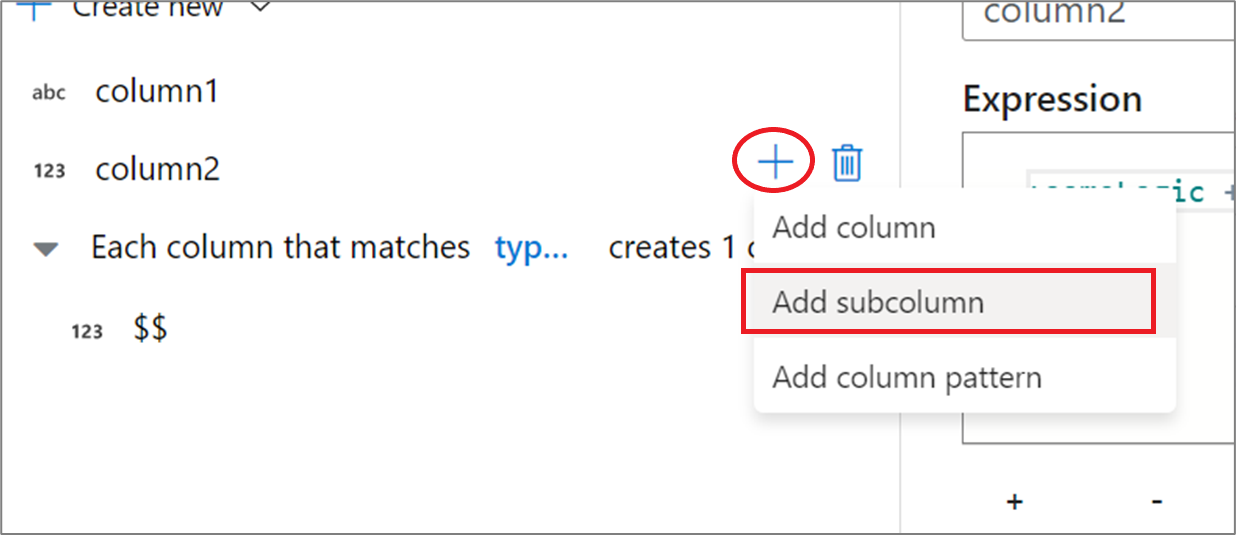
De UX van de opbouwfunctie voor expressies gebruiken
Plaats de muisaanwijzer in het zijdeelvenster van het uitvoerschema op een kolom en klik op het pluspictogram. Selecteer Subkolom toevoegen om de kolom een complex type te maken.
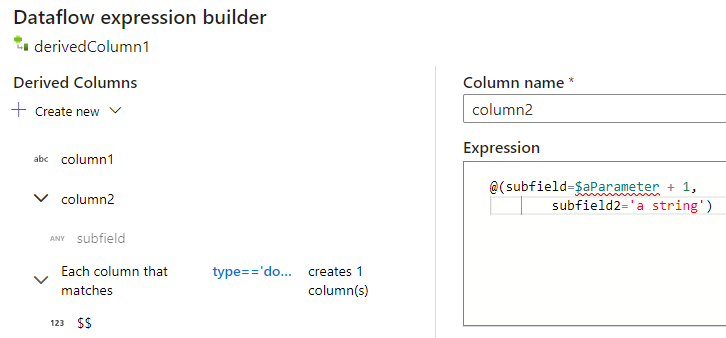
U kunt op dezelfde manier extra kolommen en subkolommen toevoegen. Voor elk niet-complex veld kan een expressie worden toegevoegd in de expressie-editor aan de rechterkant.
De JSON-structuur handmatig invoeren
Als u handmatig een JSON-structuur wilt toevoegen, voegt u een nieuwe kolom toe en voert u de expressie in de editor in. De expressie volgt de volgende algemene indeling:
@(
field1=0,
field2=@(
field1=0
)
)
Als deze expressie is ingevoerd voor een kolom met de naam complexColumn, wordt deze als de volgende JSON naar de sink geschreven:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Voorbeeld van handmatig script voor volledige hiërarchische definitie
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Gerelateerde connectors en indelingen
Hier volgen enkele algemene connectors en indelingen met betrekking tot de JSON-indeling: