GPT-4 Turbo met Vision-concepten
GPT-4 Turbo with Vision is een groot multimodale model (LMM) ontwikkeld door OpenAI dat afbeeldingen kan analyseren en tekstuele antwoorden kan geven op vragen over deze modellen. Het bevat zowel natuurlijke taalverwerking als visueel begrip. Deze handleiding bevat informatie over de mogelijkheden en beperkingen van GPT-4 Turbo met Vision.
Als u GPT-4 Turbo met Vision wilt uitproberen, raadpleegt u de quickstart.
Chats met visie
De GPT-4 Turbo met Vision-model beantwoordt algemene vragen over wat er aanwezig is in de afbeeldingen of video's die u uploadt.
Verbeteringen
Met verbeteringen kunt u andere Azure AI-services (zoals Azure AI Vision) opnemen om nieuwe functionaliteit toe te voegen aan de chat-with-vision-ervaring.
Belangrijk
Als u Vision-uitbreiding wilt gebruiken, hebt u een Computer Vision-resource nodig. Deze moet zich in de betaalde laag (S1) en in dezelfde Azure-regio bevinden als uw GPT-4 Turbo met Vision-resource.
Belangrijk
Vision-verbeteringen worden niet ondersteund door het MODEL GPT-4 Turbo GA. Ze zijn alleen beschikbaar voor de preview-modellen.
Objectgronding: Azure AI Vision vormt een aanvulling op GPT-4 Turbo met het tekstantwoord van Vision door opvallende objecten in de invoerafbeeldingen te identificeren en te lokaliseren. Hierdoor kan het chatmodel nauwkeurigere en gedetailleerde antwoorden geven over de inhoud van de afbeelding.
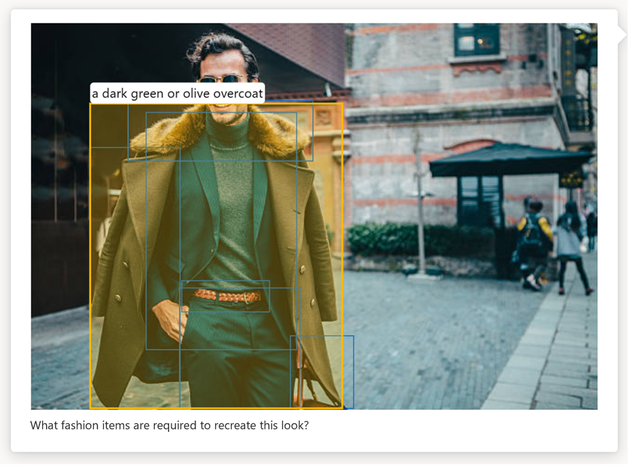

Optical Character Recognition (OCR): Azure AI Vision vormt een aanvulling op GPT-4 Turbo met Vision door OCR-resultaten van hoge kwaliteit te bieden als aanvullende informatie aan het chatmodel. Hiermee kan het model antwoorden van hogere kwaliteit produceren voor afbeeldingen met dichte tekst, getransformeerde afbeeldingen en financiële documenten met veel cijfers, en verhoogt het aantal talen dat het model in tekst kan herkennen.

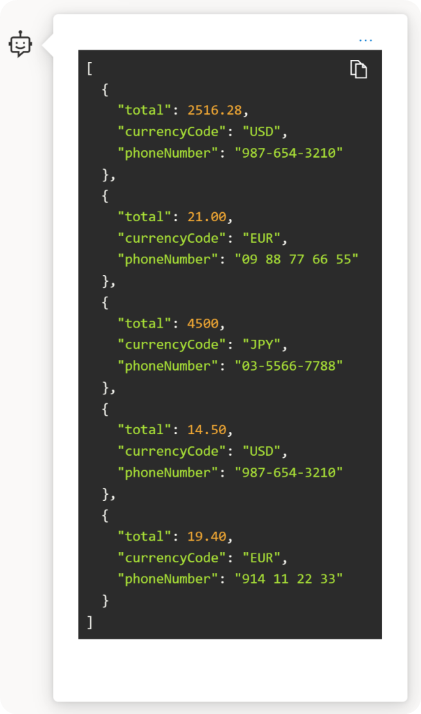
Videoprompt: Met de uitbreiding van de videoprompt kunt u videoclips gebruiken als invoer voor AI-chat, zodat het model samenvattingen en antwoorden over video-inhoud kan genereren. Azure AI Vision Video Ophalen wordt gebruikt om een set frames uit een video te samplen en een transcriptie van de spraak in de video te maken.
Speciale prijsinformatie
Belangrijk
Prijsgegevens zijn in de toekomst onderhevig aan wijzigingen.
GPT-4 Turbo met Vision brengt kosten met zich mee, zoals andere Azure OpenAI-chatmodellen. U betaalt een tarief per token voor de prompts en voltooiingen, die worden beschreven op de pagina Prijzen. De basiskosten en aanvullende functies worden hier beschreven:
Basisprijzen voor GPT-4 Turbo with Vision is:
- Invoer: $ 0,01 per 1000 tokens
- Uitvoer: $ 0,03 per 1000 tokens
Zie de sectie Tokens van het overzicht voor informatie over hoe tekst en afbeeldingen worden omgezet in tokens.
Als u Verbeteringen inschakelt, is extra gebruik van toepassing op het gebruik van GPT-4 Turbo met Vision met Azure AI Vision-functionaliteit.
| Modelleren | Prijs |
|---|---|
| + Verbeterde invoegtoepassingsfuncties voor OCR | $ 1,5 per 1000 transacties |
| + Verbeterde invoegtoepassingsfuncties voor objectdetectie | $ 1,5 per 1000 transacties |
| + Verbeterde invoegtoepassingsfunctie voor integratie 'Video ophalen' 1 | Opname: $ 0,05 per minuut video Transacties: $ 0,25 per 1000 query's van de index voor het ophalen van video's |
1 Het verwerken van video's omvat het gebruik van extra tokens om belangrijke frames voor analyse te identificeren. Het aantal extra tokens is ongeveer gelijk aan de som van de tokens in de tekstinvoer, plus 700 tokens.
Voorbeeld van afbeeldingsprijsberekening
Belangrijk
De volgende inhoud is alleen een voorbeeld en prijzen kunnen in de toekomst worden gewijzigd.
Voor een typische use-case kunt u een afbeelding maken met zowel zichtbare objecten als tekst en een invoer van 100 tokenprompts. Wanneer de service de prompt verwerkt, worden er 100 tokens aan uitvoer gegenereerd. In de afbeelding kunnen zowel tekst als objecten worden gedetecteerd. De prijs van deze transactie is:
| Artikel | Detail | Kosten |
|---|---|---|
| Tekstpromptinvoer | 100 teksttokens | $ 0,001 |
| Voorbeeldafbeeldingsinvoer (zie Afbeeldingstokens) | 170 + 85 afbeeldingstokens | $ 0,00255 |
| Verbeterde invoegtoepassingsfuncties voor OCR | $ 1,50 / 1000 transacties | $ 0,0015 |
| Verbeterde invoegtoepassingsfuncties voor objectgronding | $ 1,50 / 1000 transacties | $ 0,0015 |
| Uitvoertokens | 100 tokens (aangenomen) | $ 0,003 |
| Totaal | $ 0,00955 |
Voorbeeld van videoprijsberekening
Belangrijk
De volgende inhoud is alleen een voorbeeld en prijzen kunnen in de toekomst worden gewijzigd.
Neem voor een typische use-case een video van 3 minuten met een invoer van 100 tokenprompts. De video heeft een transcriptie van 100 tokens lang en wanneer de service de prompt verwerkt, worden er 100 tokens aan uitvoer gegenereerd. De prijzen voor deze transactie zijn:
| Artikel | Detail | Kosten |
|---|---|---|
| GPT-4 Turbo met Vision-invoertokens | 100 teksttokens | $ 0,001 |
| Extra kosten voor het identificeren van frames | 100 invoertokens + 700 tokens + 1 Video ophalen transactie | $ 0,00825 |
| Invoer van afbeeldingen en transcriptieinvoer | 20 afbeeldingen (elk 85 tokens) + 100 transcripttokens | $ 0,018 |
| Uitvoertokens | 100 tokens (aangenomen) | $ 0,003 |
| Totaal | $ 0,03025 |
Daarnaast zijn er eenmalige indexeringskosten van $ 0,15 voor het genereren van de index voor het ophalen van video's van 3 minuten. Deze index kan opnieuw worden gebruikt voor een willekeurig aantal video's ophalen en GPT-4 Turbo met Vision-API-aanroepen.
Beperkingen
In deze sectie worden de beperkingen van GPT-4 Turbo met Vision beschreven.
Ondersteuning voor installatiekopieën
- Beperking van verbeteringen van afbeeldingen per chatsessie: Verbeteringen kunnen niet worden toegepast op meerdere afbeeldingen binnen één chatgesprek.
- Maximale grootte van invoerafbeeldingen: de maximale grootte voor invoerafbeeldingen is beperkt tot 20 MB.
- Objectaarding in uitbreidings-API: Wanneer de uitbreidings-API wordt gebruikt voor objectgronding en het model duplicaten van een object detecteert, genereert het één begrenzingsvak en label voor alle duplicaten in plaats van afzonderlijke objecten voor elk object.
- Nauwkeurigheid van lage resolutie: wanneer afbeeldingen worden geanalyseerd met behulp van de instelling 'lage resolutie', kunt u sneller antwoorden krijgen en minder invoertokens gebruiken voor bepaalde gebruiksvoorbeelden. Dit kan echter van invloed zijn op de nauwkeurigheid van object- en tekstherkenning in de afbeelding.
- Beperking voor chatten van afbeeldingen: wanneer u afbeeldingen uploadt in Azure OpenAI Studio of de API, is er een limiet van 10 afbeeldingen per chatgesprek.
Video-ondersteuning
- Lage resolutie: Videoframes worden geanalyseerd met gpt-4 turbo met vision's lage resolutie instelling, die van invloed kan zijn op de nauwkeurigheid van kleine object- en tekstherkenning in de video.
- Limieten voor videobestanden: zowel MP4- als MOV-bestandstypen worden ondersteund. In Azure OpenAI Studio moeten video's minder dan 3 minuten lang zijn. Wanneer u de API gebruikt, is er geen dergelijke beperking.
- Promptlimieten: videoprompts bevatten slechts één video en geen afbeeldingen. In Azure OpenAI Studio kunt u de sessie wissen om een andere video of afbeeldingen uit te proberen.
- Beperkte frameselectie: De service selecteert 20 frames uit de hele video, die mogelijk niet alle kritieke momenten of details vastlegt. Frameselectie kan ongeveer gelijkmatig worden verdeeld over de video of gericht zijn op een specifieke query voor het ophalen van video's, afhankelijk van de prompt.
- Taalondersteuning: De service ondersteunt voornamelijk Engels voor grondgebruik met transcripties. Transcripties geven geen nauwkeurige informatie over teksten in nummers.
Volgende stappen
- Ga aan de slag met GPT-4 Turbo met Vision door de quickstart te volgen.
- Voor een uitgebreider overzicht van de API's en het gebruik van videoprompts in de chat, volgt u de instructiegids.
- Zie de API-naslaginformatie over voltooiingen en insluitingen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor