Tips voor betere prestaties van Azure Cosmos DB Java SDK v4
VAN TOEPASSING OP: ![]() NoSQL
NoSQL
Belangrijk
De prestatietips in dit artikel zijn alleen bedoeld voor Azure Cosmos DB Java SDK v4. Bekijk de releaseopmerkingen voor De Java SDK v4 van Azure Cosmos DB, de Maven-opslagplaats en de probleemoplossingsgids voor Azure Cosmos DB Java SDK v4 voor meer informatie. Als u momenteel een oudere versie dan v4 gebruikt, raadpleegt u de gids Migreren naar Azure Cosmos DB Java SDK v4 voor hulp om te upgraden naar v4.
Azure Cosmos DB is een snelle en flexibele gedistribueerde database die naadloos wordt geschaald met gegarandeerde latentie en doorvoer. U hoeft geen belangrijke architectuurwijzigingen aan te brengen of complexe code te schrijven om uw database te schalen met Azure Cosmos DB. Omhoog en omlaag schalen is net zo eenvoudig als het maken van één API-aanroep of SDK-methode-aanroep. Omdat Azure Cosmos DB echter toegankelijk is via netwerkaanroepen, zijn er optimalisaties aan de clientzijde die u kunt uitvoeren om piekprestaties te bereiken wanneer u Azure Cosmos DB Java SDK v4 gebruikt.
Dus als u 'Hoe kan ik de prestaties van mijn database verbeteren?' vraagt, moet u rekening houden met de volgende opties:
Netwerken
Clients in dezelfde Azure-regio plaatsen voor prestaties
Plaats indien mogelijk toepassingen die Azure Cosmos DB aanroepen in dezelfde regio als de Azure Cosmos DB-database. Voor een geschatte vergelijking zijn aanroepen naar Azure Cosmos DB binnen dezelfde regio voltooid binnen 1-2 ms, maar de latentie tussen de west- en oostkust van de VS is >50 ms. Deze latentie kan waarschijnlijk variëren van aanvraag tot aanvraag, afhankelijk van de route die door de aanvraag wordt genomen, omdat deze wordt doorgegeven van de client naar de grens van het Azure-datacenter. De laagst mogelijke latentie wordt bereikt door ervoor te zorgen dat de aanroepende toepassing zich in dezelfde Azure-regio bevindt als het ingerichte Azure Cosmos DB-eindpunt. Zie Azure-regio's voor een lijst met beschikbare regio's.
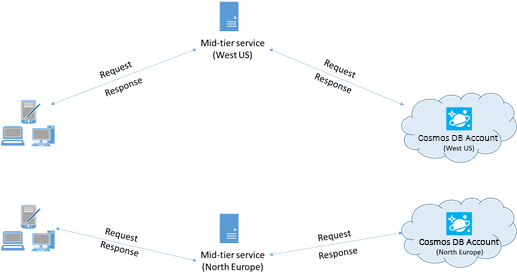
Een app die communiceert met een Azure Cosmos DB-account met meerdere regio's, moet voorkeurslocaties configureren om ervoor te zorgen dat aanvragen naar een regio met meerdere regio's gaan.
Versneld netwerken inschakelen om latentie en CPU-jitter te verminderen
We raden u ten zeerste aan de instructies te volgen om versneld netwerken in te schakelen in uw Windows (selecteer voor instructies) of Linux (selecteer voor instructies) azure-VM om de prestaties te maximaliseren door latentie en CPU-jitter te verminderen.
Zonder versneld netwerken kan IO die tussen uw Azure-VM en andere Azure-resources wordt verzonden, worden gerouteerd via een host en virtuele switch tussen de VM en de bijbehorende netwerkkaart. Als de host en virtuele switch inline in het gegevenspad worden geplaatst, neemt niet alleen de latentie en jitter in het communicatiekanaal toe, maar wordt ook de CPU-cycli van de VIRTUELE machine gestolen. Met versneld netwerken kunnen de VM-interfaces rechtstreeks met de NIC zonder tussenpersonen worden gebruikt. Alle netwerkbeleidsgegevens worden verwerkt in de hardware op de NIC, waarbij de host en virtuele switch worden overgeslagen. Over het algemeen kunt u lagere latentie en hogere doorvoer verwachten, evenals consistentere latentie en een lager CPU-gebruik wanneer u versneld netwerken inschakelt.
Beperkingen: versneld netwerken moeten worden ondersteund op het VM-besturingssysteem en kunnen alleen worden ingeschakeld wanneer de VIRTUELE machine wordt gestopt en de toewijzing ervan ongedaan wordt gemaakt. De VM kan niet worden geïmplementeerd met Azure Resource Manager. App Service heeft geen versneld netwerk ingeschakeld.
Zie de instructies voor Windows en Linux voor meer informatie.
Hoge beschikbaarheid
Zie Hoge beschikbaarheid in Azure Cosmos DB voor algemene richtlijnen voor het configureren van hoge beschikbaarheid in Azure Cosmos DB.
Naast een goede basisinstallatie in het databaseplatform zijn er specifieke technieken die kunnen worden geïmplementeerd in de Java SDK zelf, wat kan helpen bij storingsscenario's. Twee belangrijke strategieën zijn de beschikbaarheidsstrategie op basis van drempelwaarden en de circuitonderbreker op partitieniveau.
Deze technieken bieden geavanceerde mechanismen om specifieke latentie- en beschikbaarheidsuitdagingen aan te pakken, die standaard boven en buiten de mogelijkheden voor opnieuw proberen in meerdere regio's vallen die standaard zijn ingebouwd in de SDK. Door potentiële problemen op aanvraag- en partitieniveau proactief te beheren, kunnen deze strategieën de tolerantie en prestaties van uw toepassing aanzienlijk verbeteren, met name onder hoge belasting of gedegradeerde omstandigheden.
Beschikbaarheidsstrategie op basis van drempelwaarden
De beschikbaarheidsstrategie op basis van drempelwaarden kan de latentie en beschikbaarheid verbeteren door parallelle leesaanvragen naar secundaire regio's te verzenden en het snelste antwoord te accepteren. Deze aanpak kan de impact van regionale storingen of omstandigheden met hoge latentie op de prestaties van toepassingen drastisch verminderen. Daarnaast kan proactief verbindingsbeheer worden gebruikt om de prestaties verder te verbeteren door verbindingen en caches op te warmen in zowel de huidige leesregio als externe voorkeursregio's.
Voorbeeldconfiguratie:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Hoe werkt het:
Eerste aanvraag: op het moment T1 wordt een leesaanvraag gedaan naar de primaire regio (bijvoorbeeld VS - oost). De SDK wacht op een antwoord van maximaal 500 milliseconden (de
thresholdwaarde).Tweede aanvraag: Als er binnen 500 milliseconden geen reactie van de primaire regio is, wordt een parallelle aanvraag verzonden naar de volgende voorkeursregio (bijvoorbeeld VS - oost 2).
Derde aanvraag: als de primaire of secundaire regio niet binnen 600 milliseconden reageert (500 ms + 100 ms, de
thresholdStepwaarde), verzendt de SDK een andere parallelle aanvraag naar de derde voorkeursregio (bijvoorbeeld VS - west).Snelste antwoord wint: de regio die als eerste reageert, dat antwoord wordt geaccepteerd en de andere parallelle aanvragen worden genegeerd.
Proactief verbindingsbeheer helpt bij het opwarmen van verbindingen en caches voor containers in de voorkeursregio's, waardoor de latentie bij koude start voor failoverscenario's of schrijfbewerkingen in meerdere regio-instellingen wordt verminderd.
Deze strategie kan de latentie aanzienlijk verbeteren in scenario's waarbij een bepaalde regio traag of tijdelijk niet beschikbaar is, maar er kunnen meer kosten in rekening worden gebracht in termen van aanvraageenheden wanneer parallelle aanvragen voor meerdere regio's vereist zijn.
Notitie
Als de eerste voorkeursregio een niet-tijdelijke foutcode retourneert (bijvoorbeeld document niet gevonden, autorisatiefout, conflict, enzovoort), mislukt de bewerking zelf snel, omdat de beschikbaarheidsstrategie in dit scenario geen voordeel heeft.
Circuitonderbreker op partitieniveau
De circuitonderbreker op partitieniveau verbetert de latentie en schrijfbeschikbaarheid door aanvragen voor beschadigde fysieke partities bij te houden en kortsluitingsaanvragen bij te houden. Het verbetert de prestaties door bekende problematische partities te voorkomen en aanvragen om te leiden naar gezondere regio's.
Voorbeeldconfiguratie:
Circuitonderbreker op partitieniveau inschakelen:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
De achtergrondprocesfrequentie instellen voor het controleren van niet-beschikbare regio's:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
De duur instellen waarvoor een partitie niet beschikbaar kan blijven:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Hoe werkt het:
Traceringsfouten: Met de SDK worden terminalfouten (bijvoorbeeld 503's, 500s, time-outs) voor afzonderlijke partities in specifieke regio's bijgehouden.
Markeren als niet beschikbaar: als een partitie in een regio een geconfigureerde drempelwaarde voor fouten overschrijdt, wordt deze gemarkeerd als 'Niet beschikbaar'. Volgende aanvragen voor deze partitie worden kortsluiting en omgeleid naar andere gezondere regio's.
Geautomatiseerd herstel: een achtergrondthread controleert periodiek niet-beschikbare partities. Na een bepaalde duur worden deze partities voorlopig gemarkeerd als 'HealthyTentative' en worden ze onderworpen aan testaanvragen om het herstel te valideren.
Statuspromotie/degradatie: Op basis van het succes of falen van deze testaanvragen wordt de status van de partitie teruggezet naar 'In orde' of opnieuw gedegradeerd naar 'Niet beschikbaar'.
Dit mechanisme helpt bij het continu bewaken van de partitiestatus en zorgt ervoor dat aanvragen worden verwerkt met minimale latentie en maximale beschikbaarheid, zonder te worden vermomd door problematische partities.
Notitie
Circuitonderbreker is alleen van toepassing op schrijfaccounts voor meerdere regio's, zoals wanneer een partitie wordt gemarkeerd als Unavailable, worden zowel lees- als schrijfbewerkingen verplaatst naar de volgende voorkeursregio. Dit is om te voorkomen dat lees- en schrijfbewerkingen uit verschillende regio's worden geleverd vanuit hetzelfde clientexemplaren, omdat dit een antipatroon zou zijn.
Belangrijk
U moet versie 4.63.0 van de Java SDK of hoger gebruiken om circuitonderbreker op partitieniveau te activeren.
Beschikbaarheidsoptimalisaties vergelijken
Beschikbaarheidsstrategie op basis van drempelwaarden:
- Voordeel: vermindert de staartlatentie door parallelle leesaanvragen naar secundaire regio's te verzenden en verbetert de beschikbaarheid door aanvragen vooraf uit te voeren die leiden tot netwerktime-outs.
- Trade-off: er worden extra RU-kosten (aanvraageenheden) in vergelijking met circuitonderbrekers in rekening gebracht, vanwege extra parallelle aanvragen voor meerdere regio's (hoewel alleen tijdens perioden waarin drempelwaarden worden overschreden).
- Use Case: Optimaal voor leesintensieve werkbelastingen waarbij het verminderen van de latentie essentieel is en enkele extra kosten (zowel qua RU-kosten als cpu-druk van client) acceptabel zijn. Schrijfbewerkingen kunnen ook voordeel hebben als u bent aangemeld voor beleid voor niet-idempotent schrijven voor opnieuw proberen en het account schrijfbewerkingen voor meerdere regio's heeft.
Circuitonderbreker op partitieniveau:
- Voordeel: verbetert de beschikbaarheid en latentie door beschadigde partities te voorkomen, zodat aanvragen worden doorgestuurd naar gezondere regio's.
- Afruilen: er worden geen extra RU-kosten in rekening gebracht, maar er kunnen nog steeds enige initiële beschikbaarheidsverlies voor aanvragen worden toegestaan die leiden tot time-outs voor het netwerk.
- Use Case: Ideaal voor schrijfintensieve of gemengde workloads waarbij consistente prestaties essentieel zijn, met name wanneer u te maken hebt met partities die af en toe beschadigd kunnen raken.
Beide strategieën kunnen samen worden gebruikt om de beschikbaarheid van lees- en schrijfbewerkingen te verbeteren en de latentie van de staart te verminderen. Circuitonderbreker op partitieniveau kan verschillende tijdelijke foutscenario's verwerken, waaronder scenario's die kunnen leiden tot trage uitvoering van replica's, zonder dat parallelle aanvragen hoeven uit te voeren. Bovendien zal het toevoegen van een beschikbaarheidsstrategie op basis van drempelwaarden de staartlatentie verder minimaliseren en beschikbaarheidsverlies elimineren, als extra RU-kosten acceptabel zijn.
Door deze strategieën te implementeren, kunnen ontwikkelaars ervoor zorgen dat hun toepassingen tolerant blijven, hoge prestaties behouden en een betere gebruikerservaring bieden, zelfs tijdens regionale storingen of omstandigheden met hoge latentie.
Consistentie van sessiebereik in regio
Overzicht
Zie Consistentieniveaus in Azure Cosmos DB voor meer informatie over consistentie-instellingen in het algemeen. De Java SDK biedt een optimalisatie voor sessieconsistentie voor schrijfaccounts voor meerdere regio's, doordat deze binnen het bereik van de regio kan worden geplaatst. Dit verbetert de prestaties door de latentie van regionale replicatie te beperken door het minimaliseren van nieuwe pogingen aan de clientzijde. Dit wordt bereikt door sessietokens op regioniveau te beheren in plaats van wereldwijd. Als consistentie in uw toepassing kan worden beperkt tot een kleiner aantal regio's, kunt u door de consistentie van sessies binnen regiobereik te implementeren, betere prestaties en betrouwbaarheid bereiken voor lees- en schrijfbewerkingen in accounts met meerdere schrijfbewerkingen door vertragingen en nieuwe pogingen voor meerdere regio's te minimaliseren.
Vergoedingen
- Verminderde latentie: door sessietokenvalidatie te lokaliseren op regioniveau, wordt de kans op kostbare, regionale nieuwe pogingen verminderd.
- Verbeterde prestaties: minimaliseert de impact van regionale failover en replicatievertraging, waardoor de consistentie van lees-/schrijfbewerkingen hoger is en het CPU-gebruik lager is.
- Geoptimaliseerd resourcegebruik: vermindert de CPU- en netwerkoverhead voor clienttoepassingen door de noodzaak van nieuwe pogingen en regionale aanroepen te beperken, waardoor het resourcegebruik wordt geoptimaliseerd.
- Hoge beschikbaarheid: door sessietokens binnen het bereik van regio's te onderhouden, kunnen toepassingen soepel blijven werken, zelfs als bepaalde regio's een hogere latentie of tijdelijke storingen ondervinden.
- Consistentiegaranties: zorgt ervoor dat aan de garanties voor sessieconsistentie (lezen van uw schrijf- en monotone leesbewerking) betrouwbaarder wordt voldaan zonder onnodige nieuwe pogingen.
- Kostenefficiëntie: vermindert het aantal regionale aanroepen, waardoor de kosten voor gegevensoverdracht tussen regio's mogelijk worden verlaagd.
- Schaalbaarheid: Hiermee kunnen toepassingen efficiënter worden geschaald door conflicten en overhead te verminderen die gepaard gaan met het onderhouden van een globaal sessietoken, met name in setups voor meerdere regio's.
Compromissen
- Verhoogd geheugengebruik: voor het bloeifilter en de regiospecifieke sessietokenopslag is extra geheugen vereist. Dit kan een overweging zijn voor toepassingen met beperkte resources.
- Configuratiecomplexiteit: Het verwachte aantal invoegbewerkingen en het fout-positieve tarief voor het bloeifilter voegt een laag complexiteit toe aan het configuratieproces.
- Potentieel voor fout-positieven: Hoewel het bloeifilter cross-regionale nieuwe pogingen minimaliseert, is er nog steeds een kleine kans op fout-positieven die van invloed zijn op de validatie van het sessietoken, hoewel de snelheid kan worden beheerd. Een fout-positief betekent dat het globale sessietoken wordt opgelost, waardoor de kans op nieuwe pogingen in meerdere regio's wordt vergroot als de lokale regio deze globale sessie niet heeft opgepikt. Er wordt voldaan aan sessiegaranties, zelfs in aanwezigheid van fout-positieven.
- Toepasselijkheid: deze functie is het nuttigst voor toepassingen met een hoge kardinaliteit van logische partities en regelmatig opnieuw opstarten. Toepassingen met minder logische partities of onregelmatige herstarts zien mogelijk geen aanzienlijke voordelen.
Hoe het werkt
Het sessietoken instellen
- Voltooiing van aanvraag: Nadat een aanvraag is voltooid, legt de SDK het sessietoken vast en koppelt deze aan de regio en partitiesleutel.
- Opslag op regioniveau: sessietokens worden opgeslagen in een geneste
ConcurrentHashMapopslag die toewijzingen onderhoudt tussen partitiesleutelbereiken en voortgang op regioniveau. - Bloeifilter: Met een bloeifilter wordt bijgehouden welke regio's toegankelijk zijn voor elke logische partitie, waardoor sessietokenvalidatie kan worden gelokaliseerd.
Het sessietoken oplossen
- Initialisatie van aanvragen: voordat een aanvraag wordt verzonden, probeert de SDK het sessietoken voor de juiste regio op te lossen.
- Tokencontrole: het token wordt gecontroleerd op basis van de regiospecifieke gegevens om ervoor te zorgen dat de aanvraag wordt gerouteerd naar de meest recente replica.
- Logica voor opnieuw proberen: als het sessietoken niet wordt gevalideerd binnen de huidige regio, wordt de SDK opnieuw geprobeerd met andere regio's, maar gezien de gelokaliseerde opslag, is dit minder frequent.
De SDK gebruiken
U kunt de CosmosClient als volgt initialiseren met sessieconsistentie binnen het bereik van de regio:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Consistentie van sessie binnen het bereik van regio's inschakelen
Stel de volgende systeemeigenschap in om het vastleggen van regio's in te schakelen in uw toepassing:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Bloeifilter configureren
Verfijn de prestaties door de verwachte invoegingen en het fout-positieve tarief voor het bloeifilter te configureren:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Gevolgen voor geheugen
Hieronder ziet u de bewaarde grootte (grootte van het object en afhankelijk van) van de interne sessiecontainer (beheerd door de SDK) met verschillende verwachte invoegingen in het bloeifilter.
| Verwachte invoegingen | Aantal fout-positief | Behouden grootte |
|---|---|---|
| 10, 000 | 0,001 | 21 KB |
| 100, 000 | 0,001 | 183 KB |
| 1 miljoen | 0,001 | 1,8 MB |
| 10 miljoen | 0,001 | 17,9 MB |
| 100 miljoen | 0,001 | 179 MB |
| 1 miljard | 0,001 | 1,8 GB |
Belangrijk
U moet versie 4.60.0 van de Java SDK of hoger gebruiken om sessieconsistentie binnen het bereik van regio's te activeren.
Configuratie van directe en gatewayverbinding afstemmen
Zie voor het optimaliseren van verbindingsconfiguraties voor directe en gatewaymodus hoe u verbindingsconfiguraties voor Java SDK v4 kunt afstemmen.
SDK-gebruik
- De meest recente SDK installeren
De Azure Cosmos DB SDK's worden voortdurend verbeterd om de beste prestaties te bieden. Ga naar de Azure Cosmos DB SDK om de meest recente SDK-verbeteringen te bepalen.
Elk Azure Cosmos DB-clientexemplaren is thread-veilig en voert efficiënt verbindingsbeheer en adrescaching uit. Om efficiënt verbindingsbeheer en betere prestaties van de Azure Cosmos DB-client mogelijk te maken, raden we u ten zeerste aan één exemplaar van de Azure Cosmos DB-client te gebruiken voor de levensduur van de toepassing.
Wanneer u een CosmosClient maakt, is sessie de standaardconsistentie die wordt gebruikt als deze niet expliciet is ingesteld. Als sessieconsistentie niet is vereist door uw toepassingslogica, stelt u de consistentie in op Uiteindelijk. Opmerking: het wordt aanbevolen om ten minste sessieconsistentie te gebruiken in toepassingen die gebruikmaken van de Processor van de wijzigingenfeed van Azure Cosmos DB.
- Async-API gebruiken om de ingerichte doorvoer te verhogen
Azure Cosmos DB Java SDK v4 bundelt twee API's, een synchrone en een asynchrone. Grofweg implementeert de Async-API SDK-functionaliteit, terwijl de Synchronisatie-API een thin wrapper is die blokkerende aanroepen naar de Async-API maakt. Dit staat in tegenstelling tot de oudere Azure Cosmos DB Async Java SDK v2, die alleen Async-only was, en met de oudere Azure Cosmos DB Sync Java SDK v2, die alleen-synchroniseren was en een afzonderlijke implementatie had.
De keuze van de API wordt bepaald tijdens de initialisatie van de client; een CosmosAsyncClient ondersteunt Async-API, terwijl een CosmosClient ondersteuning biedt voor de Synchronisatie-API.
De Async-API implementeert niet-blokkerende IO en is de optimale keuze als u de doorvoer wilt beperken bij het uitgeven van aanvragen naar Azure Cosmos DB.
Het gebruik van de Synchronisatie-API kan de juiste keuze zijn als u een API wilt of nodig hebt, die de reactie op elke aanvraag blokkeert of als synchrone bewerking het dominante paradigma in uw toepassing is. U kunt bijvoorbeeld de synchronisatie-API gebruiken wanneer u gegevens ophoudt naar Azure Cosmos DB in een microservicestoepassing, mits de doorvoer niet kritiek is.
Let op: synchronisatie-API-doorvoer verslechtert met een toenemende reactietijd van aanvragen, terwijl de Async-API de volledige bandbreedtemogelijkheden van uw hardware kan verzadigen.
Geografische collocatie kan u hogere en consistentere doorvoer bieden bij het gebruik van de Synchronisatie-API (zie Collocate-clients in dezelfde Azure-regio voor prestaties), maar verwacht nog steeds niet dat de Asynchrone API haalbare doorvoer overschrijdt.
Sommige gebruikers zijn mogelijk ook niet bekend met Project Reactor, het Reactieve Streams-framework dat wordt gebruikt om Azure Cosmos DB Java SDK v4 Async API te implementeren. Als dit een probleem is, raden we u aan onze inleidende reactorpatroongids te lezen en vervolgens deze inleiding tot reactief programmeren te bekijken om vertrouwd te raken. Als u Azure Cosmos DB al hebt gebruikt met een Async-interface en de SDK die u hebt gebruikt azure Cosmos DB Async Java SDK v2, bent u mogelijk bekend met ReactiveX/RxJava , maar weet u niet zeker wat er is gewijzigd in Project Reactor. Bekijk in dat geval onze Reactor vs RxJava Guide om vertrouwd te raken.
De volgende codefragmenten laten zien hoe u uw Azure Cosmos DB-client initialiseert voor respectievelijk Async-API- of Synchronisatie-API-bewerking:
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Uw clientworkload uitschalen
Als u test op hoge doorvoerniveaus, kan de clienttoepassing het knelpunt worden omdat de computer het CPU- of netwerkgebruik beperkt. Als u dit punt bereikt, kunt u het Azure Cosmos DB-account verder pushen door uw clienttoepassingen uit te schalen op meerdere servers.
Een goede vuistregel is niet groter dan >50% CPU-gebruik op een bepaalde server, om latentie laag te houden.
- Geschikte Scheduler gebruiken (vermijd het stelen van Io Netty-threads voor gebeurtenislus)
De asynchrone functionaliteit van Azure Cosmos DB Java SDK is gebaseerd op netty non-blocking IO. De SDK gebruikt een vast aantal IO Netty EventLoop-threads (zoveel CPU-kernen waarover de computer beschikt) voor het uitvoeren van IO-bewerkingen. De Flux die door de API wordt geretourneerd, stuurt het resultaat naar een van de gedeelde IO Netty EventLoop-threads. Het is dus belangrijk om de gedeelde IO Netty EventLoop-threads niet te blokkeren. Het uitvoeren van CPU-intensief werk of het blokkeren van bewerkingen op de NETTY-thread van de IO-gebeurtenislus kan een impasse veroorzaken of de SDK-doorvoer aanzienlijk verminderen.
Met de volgende code wordt bijvoorbeeld een cpu-intensief werk uitgevoerd voor de IO netty-thread van de gebeurtenislus:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Nadat het resultaat is ontvangen, moet u voorkomen dat u CPU-intensief werk uitvoert aan het resultaat van de IO-netty-thread van de gebeurtenislus. U kunt in plaats daarvan uw eigen Scheduler opgeven om uw eigen thread te bieden voor het uitvoeren van uw werk, zoals hieronder wordt weergegeven (vereist import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Op basis van het type werk moet u de juiste bestaande Reactor Scheduler voor uw werk gebruiken. Lees hier Schedulers.
Raadpleeg dit blogbericht van Project Reactor voor meer informatie over het threading- en planningsmodel van project Reactor.
Voor meer informatie over Azure Cosmos DB Java SDK v4 raadpleegt u de Azure Cosmos DB-map van de Azure SDK voor Java-monorepo op GitHub.
- Logboekinstellingen in uw toepassing optimaliseren
Om verschillende redenen moet u logboekregistratie toevoegen aan een thread die een hoge aanvraagdoorvoer genereert. Als u de ingerichte doorvoer van een container volledig wilt verzadigen met aanvragen die door deze thread worden gegenereerd, kunnen optimalisaties voor logboekregistratie de prestaties aanzienlijk verbeteren.
- Een asynchrone logboekregistratie configureren
De latentie van een synchrone logboekregistratie factoren noodzakelijkerwijs in de totale latentieberekening van uw aanvraag genererende thread. Een asynchrone logboekregistratie, zoals log4j2 , wordt aanbevolen om de overhead van logboekregistratie los te koppelen van uw toepassingsthreads met hoge prestaties.
- Logboekregistratie van Netty uitschakelen
Logboekregistratie van Netty-bibliotheken is chatty en moet worden uitgeschakeld (het onderdrukken van de aanmeldingsconfiguratie is mogelijk niet voldoende) om extra CPU-kosten te voorkomen. Als u zich niet in de foutopsporingsmodus bevindt, schakelt u de logboekregistratie van Netty helemaal uit. Dus als u Log4j gebruikt om de extra CPU-kosten te verwijderen die door org.apache.log4j.Category.callAppenders() Netty worden gemaakt, voegt u de volgende regel toe aan uw codebasis:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Resourcelimiet voor openen van besturingssysteembestanden
Sommige Linux-systemen (zoals Red Hat) hebben een bovengrens voor het aantal geopende bestanden en dus het totale aantal verbindingen. Voer het volgende uit om de huidige limieten weer te geven:
ulimit -a
Het aantal geopende bestanden (nofile) moet groot genoeg zijn om voldoende ruimte te hebben voor de geconfigureerde grootte van de verbindingsgroep en andere geopende bestanden door het besturingssysteem. Het kan worden gewijzigd om een grotere verbindingsgroepgrootte toe te staan.
Open het bestand limits.conf:
vim /etc/security/limits.conf
Voeg de volgende regels toe/wijzigt:
* - nofile 100000
- Partitiesleutel opgeven in puntschrijfbewerkingen
Als u de prestaties van puntschrijfbewerkingen wilt verbeteren, geeft u de partitiesleutel voor items op in de API-aanroep voor puntschrijfbewerkingen, zoals hieronder wordt weergegeven:
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
In plaats van alleen het itemexemplaren op te geven, zoals hieronder wordt weergegeven:
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
asyncContainer.createItem(item).block();
De laatste wordt ondersteund, maar voegt latentie toe aan uw toepassing; de SDK moet het item parseren en de partitiesleutel extraheren.
Querybewerkingen
Zie de prestatietips voor querybewerkingen voor query's.
Indexeringsbeleid
- Niet-gebruikte paden uitsluiten van indexering voor snellere schrijfbewerkingen
Met het indexeringsbeleid van Azure Cosmos DB kunt u opgeven welke documentpaden moeten worden opgenomen of uitgesloten van indexering met behulp van indexeringspaden (setIncludedPaths en setExcludedPaths). Het gebruik van indexeringspaden kan betere schrijfprestaties en lagere indexopslag bieden voor scenario's waarin de querypatronen vooraf bekend zijn, omdat indexeringskosten rechtstreeks worden gecorreleerd aan het aantal unieke paden dat is geïndexeerd. In de volgende code ziet u bijvoorbeeld hoe u volledige secties van de documenten (ook wel substructuur genoemd) kunt opnemen en uitsluiten van indexering met behulp van het jokerteken *.
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Zie Het indexeringsbeleid van Azure Cosmos DB voor meer informatie.
Doorvoer
- Meten en afstemmen op lagere aanvraageenheden/tweede gebruik
Azure Cosmos DB biedt een uitgebreide set databasebewerkingen, waaronder relationele en hiërarchische query's met UDF's, opgeslagen procedures en triggers, die allemaal werken op de documenten in een databaseverzameling. De kosten die gepaard gaan met elke bewerking hangen af van de CPU, de IO en het geheugen, vereist om de bewerking uit te voeren. In plaats van aan hardwareresources te denken en te beheren, kunt u een aanvraageenheid (RU) beschouwen als één meting voor de resources die nodig zijn voor het uitvoeren van verschillende databasebewerkingen en het uitvoeren van een toepassingsaanvraag.
Doorvoer wordt ingericht op basis van het aantal aanvraageenheden dat is ingesteld voor elke container. Verbruik van aanvraageenheden wordt geëvalueerd als een tarief per seconde. Toepassingen die de ingerichte aanvraageenheidsnelheid voor hun container overschrijden, zijn beperkt totdat de snelheid lager is dan het ingerichte niveau voor de container. Als uw toepassing een hoger doorvoerniveau vereist, kunt u de doorvoer verhogen door extra aanvraageenheden in te richten.
De complexiteit van een query heeft invloed op het aantal aanvraageenheden dat wordt verbruikt voor een bewerking. Het aantal predicaten, de aard van de predicaten, het aantal UDF's en de grootte van de brongegevensset zijn allemaal van invloed op de kosten van querybewerkingen.
Als u de overhead van een bewerking wilt meten (maken, bijwerken of verwijderen), inspecteert u de header x-ms-request-charge om het aantal aanvraageenheden te meten dat door deze bewerkingen wordt verbruikt. U kunt ook de equivalente eigenschap RequestCharge bekijken in ResourceResponse<T> of FeedResponse<T>.
Java SDK V4 (Maven com.azure::azure-cosmos) Async API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
De aanvraagkosten die in deze header worden geretourneerd, zijn een fractie van uw ingerichte doorvoer. Als u bijvoorbeeld 2000 RU/s hebt ingericht en als de voorgaande query 1000 kB-documenten retourneert, zijn de kosten van de bewerking 1000. Daarom eert de server binnen één seconde slechts twee dergelijke aanvragen voordat de frequentie van volgende aanvragen wordt beperkt. Zie Aanvraageenheden en de rekenmachine voor aanvraageenheden voor meer informatie.
- Snelheidsbeperking/aanvraagsnelheid te groot verwerken
Wanneer een client de gereserveerde doorvoer voor een account probeert te overschrijden, is er geen prestatievermindering op de server en is er geen gebruik van doorvoercapaciteit buiten het gereserveerde niveau. De server beëindigt de aanvraag met RequestRateTooLarge (HTTP-statuscode 429) en retourneert de header x-ms-retry-after-ms die de hoeveelheid tijd aangeeft, in milliseconden, dat de gebruiker moet wachten voordat de aanvraag opnieuw wordt geïmplementeerd.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
De SDK's vangen dit antwoord impliciet op, respecteren de server opgegeven nieuwe poging na header en probeer de aanvraag opnieuw. Tenzij uw account gelijktijdig wordt geopend door meerdere clients, slaagt de volgende nieuwe poging.
Als u meerdere clients cumulatief boven de aanvraagsnelheid hebt, is het standaardaantal nieuwe pogingen dat momenteel is ingesteld op 9 intern door de client mogelijk niet voldoende; in dit geval genereert de client een CosmosClientException met statuscode 429 aan de toepassing. Het standaardaantal nieuwe pogingen kan worden gewijzigd met behulp van setMaxRetryAttemptsOnThrottledRequests() het ThrottlingRetryOptions exemplaar. De CosmosClientException met statuscode 429 wordt standaard geretourneerd na een cumulatieve wachttijd van 30 seconden als de aanvraag blijft werken boven de aanvraagsnelheid. Dit gebeurt zelfs wanneer het huidige aantal nieuwe pogingen kleiner is dan het maximumaantal nieuwe pogingen, of het nu de standaardwaarde is van 9 of een door de gebruiker gedefinieerde waarde.
Hoewel het geautomatiseerde gedrag voor opnieuw proberen helpt om de tolerantie en bruikbaarheid voor de meeste toepassingen te verbeteren, kan het even vreemd komen bij het uitvoeren van prestatiebenchmarks, met name bij het meten van latentie. De door de client waargenomen latentie zal pieken als het experiment de server beperkt en ervoor zorgt dat de client-SDK op de achtergrond opnieuw probeert. Als u latentiepieken tijdens prestatieexperimenten wilt voorkomen, meet u de kosten die door elke bewerking worden geretourneerd en zorgt u ervoor dat aanvragen onder de gereserveerde aanvraagsnelheid worden uitgevoerd. Zie Aanvraageenheden voor meer informatie.
- Ontwerpen voor kleinere documenten voor hogere doorvoer
De aanvraagkosten (de aanvraagverwerkingskosten) van een bepaalde bewerking worden rechtstreeks gecorreleerd aan de grootte van het document. Bewerkingen op grote documenten kosten meer dan bewerkingen voor kleine documenten. U kunt uw toepassing en werkstromen het beste ontwerpen om de grootte van uw item ongeveer 1 kB of vergelijkbare volgorde of grootte te geven. Voor latentiegevoelige toepassingen moeten grote items worden vermeden: documenten met meerdere MB vertragen uw toepassing.
Volgende stappen
Zie Partitioneren en schalen in Azure Cosmos DB voor meer informatie over het ontwerpen van uw toepassing voor schaalaanpassing en hoge prestaties.
Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB? U kunt informatie over uw bestaande databasecluster gebruiken voor capaciteitsplanning.
- Als alles wat u weet het aantal vCores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner