Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Gegevensstromen zijn beschikbaar in Zowel Azure Data Factory als Azure Synapse Pipelines. Dit artikel is van toepassing op toewijzingsgegevensstromen. Als u geen ervaring hebt met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van een toewijzingsgegevensstroom.
Met de voorwaardelijke splitsingstransformatie worden gegevensrijen naar verschillende streams gerouteerd op basis van overeenkomende voorwaarden. De transformatie van voorwaardelijke splitsing is vergelijkbaar met een CASE-beslissingsstructuur in een programmeertaal. De transformatie evalueert expressies en stuurt op basis van de resultaten de gegevensrij naar de opgegeven stroom.
Configuratie
De instelling Splitsen op bepaalt of de rij met gegevensstromen naar de eerste overeenkomende stroom of elke stream waarmee deze overeenkomt.
Gebruik de opbouwfunctie voor gegevensstroomexpressies om een expressie voor de gesplitste voorwaarde in te voeren. Als u een nieuwe voorwaarde wilt toevoegen, klikt u op het pluspictogram in een bestaande rij. Er kan ook een standaardstream worden toegevoegd voor rijen die niet overeenkomen met een voorwaarde.
Script voor gegevensstroom
Syntaxis
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Opmerking
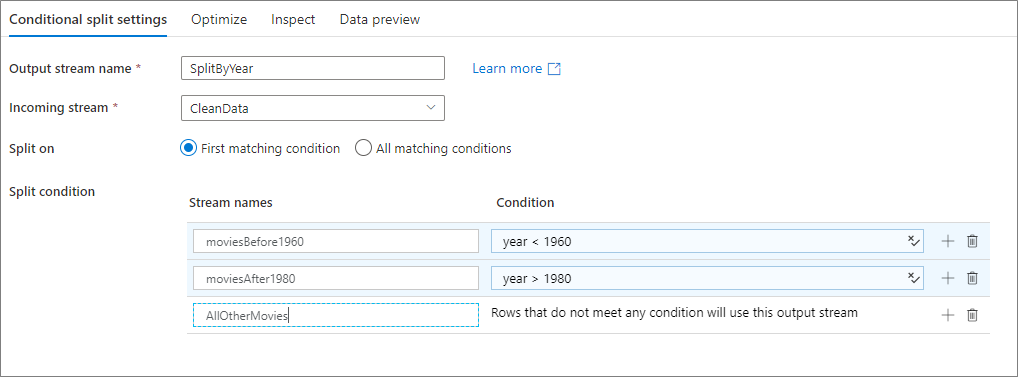
Het onderstaande voorbeeld is een voorwaardelijke splitsingstransformatie met de naam SplitByYear die binnenkomende stroom CleanDatainneemt. Deze transformatie heeft twee gesplitste voorwaarden year < 1960 en year > 1980. disjoint is onwaar omdat de gegevens naar de eerste overeenkomende voorwaarde gaan in plaats van naar alle overeenkomende voorwaarden. Elke rij die overeenkomt met de eerste voorwaarde gaat naar de uitvoerstroom moviesBefore1960. Alle resterende rijen die overeenkomen met de tweede voorwaarde, gaan naar de uitvoerstroom moviesAFter1980. Alle andere rijen stromen door de standaardstroom AllOtherMovies.
In de gebruikersinterface van de service ziet deze transformatie eruit als in de onderstaande afbeelding:
Het gegevensstroomscript voor deze transformatie bevindt zich in het onderstaande codefragment:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Gerelateerde inhoud
Veelgebruikte transformaties voor gegevensstromen die worden gebruikt met voorwaardelijke splitsing zijn de samenvoegtransformatie, opzoektransformatie en de selectietransformatie