Delta-indeling in Azure Data Factory
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt uitgelegd hoe u gegevens kopieert naar en van een delta lake die is opgeslagen in Azure Data Lake Store Gen2 of Azure Blob Storage met behulp van de delta-indeling. Deze connector is beschikbaar als een inlinegegevensset in toewijzingsgegevensstromen als bron en sink.
Eigenschappen van toewijzingsgegevensstroom
Deze connector is beschikbaar als een inlinegegevensset in toewijzingsgegevensstromen als bron en sink.
Broneigenschappen
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een deltabron. U kunt deze eigenschappen bewerken op het tabblad Bronopties .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Notatie | Notatie moet zijn delta |
ja | delta |
indeling |
| Bestandssysteem | Het container-/bestandssysteem van de Delta Lake | ja | String | bestandssysteem |
| Folder path | De map van het deltameer | ja | String | folderPath |
| Compressietype | Het compressietype van de deltatabel | nee | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Compression level | Kies of de compressie zo snel mogelijk wordt voltooid of of het resulterende bestand optimaal moet worden gecomprimeerd. | vereist als compressedType is opgegeven. |
Optimal of Fastest |
compressionLevel |
| Tijdreizen | Kiezen of u een query wilt uitvoeren op een oudere momentopname van een deltatabel | nee | Query op tijdstempel: Tijdstempel Query uitvoeren op versie: Geheel getal |
timestampAsOf versionAsOf |
| Geen bestanden gevonden toestaan | Als waar, wordt er geen fout gegenereerd als er geen bestanden worden gevonden | nee | true of false |
ignoreNoFilesFound |
Schema importeren
Delta is alleen beschikbaar als een inlinegegevensset en heeft standaard geen gekoppeld schema. Als u kolommetagegevens wilt ophalen, klikt u op de knop Schema importeren op het tabblad Projectie . Hiermee kunt u verwijzen naar de kolomnamen en gegevenstypen die zijn opgegeven door het corpus. Als u het schema wilt importeren, moet een foutopsporingssessie voor gegevensstromen actief zijn en moet u een bestaand CDM-entiteitsdefinitiebestand hebben om naar te verwijzen.
Voorbeeld van Delta-bronscript
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Sink-eigenschappen
De onderstaande tabel bevat de eigenschappen die worden ondersteund door een delta-sink. U kunt deze eigenschappen bewerken op het tabblad Instellingen .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Notatie | Notatie moet zijn delta |
ja | delta |
indeling |
| Bestandssysteem | Het container-/bestandssysteem van de Delta Lake | ja | String | bestandssysteem |
| Folder path | De map van het deltameer | ja | String | folderPath |
| Compressietype | Het compressietype van de deltatabel | nee | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Compression level | Kies of de compressie zo snel mogelijk wordt voltooid of of het resulterende bestand optimaal moet worden gecomprimeerd. | vereist als compressedType is opgegeven. |
Optimal of Fastest |
compressionLevel |
| Vacuum | Hiermee verwijdert u bestanden die ouder zijn dan de opgegeven duur die niet langer relevant is voor de huidige tabelversie. Wanneer een waarde van 0 of minder is opgegeven, wordt de vacuümbewerking niet uitgevoerd. | ja | Geheel getal | vacuüm |
| Tabelactie | Vertelt ADF wat u moet doen met de doel-Delta-tabel in uw sink. U kunt deze als zodanig laten staan en nieuwe rijen toevoegen, de bestaande tabeldefinitie en -gegevens overschrijven met nieuwe metagegevens en gegevens, of de bestaande tabelstructuur behouden, maar eerst alle rijen afkappen en vervolgens de nieuwe rijen invoegen. | nee | Geen, Afkappen, Overschrijven | deltaTruncate, overschrijven |
| Bijwerkingsmethode | Wanneer u alleen Invoegen toestaan selecteert of wanneer u naar een nieuwe deltatabel schrijft, ontvangt het doel alle binnenkomende rijen, ongeacht de set Met beleidsregels voor rijen. Als uw gegevens rijen met andere rijbeleidsregels bevatten, moeten ze worden uitgesloten met behulp van een voorgaande filtertransformatie. Wanneer alle updatemethoden zijn geselecteerd, wordt een samenvoeging uitgevoerd, waarbij rijen worden ingevoegd/verwijderd/upserted/bijgewerkt volgens de set Rijbeleid met behulp van een voorgaande transformatie voor het wijzigen van rijen. |
ja | true of false |
invoegbaar te verwijderen upsertable kan worden bijgewerkt |
| Geoptimaliseerde schrijfbewerking | Behaalt een hogere doorvoer voor schrijfbewerkingen via het optimaliseren van interne shuffle in Spark-uitvoerders. Als gevolg hiervan ziet u mogelijk minder partities en bestanden die groter zijn | nee | true of false |
optimizedWrite: true |
| Automatisch comprimeren | Nadat een schrijfbewerking is voltooid, voert Spark automatisch de OPTIMIZE opdracht uit om de gegevens opnieuw te ordenen, wat resulteert in meer partities, indien nodig, voor betere leesprestaties in de toekomst |
nee | true of false |
autoCompact: true |
Voorbeeld van Delta-sinkscript
Het gekoppelde gegevensstroomscript is:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Delta-sink met partitiesnoeien
Met deze optie onder updatemethode hierboven (bijvoorbeeld update/upsert/delete), kunt u het aantal geïnspecteerde partities beperken. Alleen partities die aan deze voorwaarde voldoen, worden opgehaald uit het doelarchief. U kunt een vaste set waarden opgeven die een partitiekolom kan aannemen.
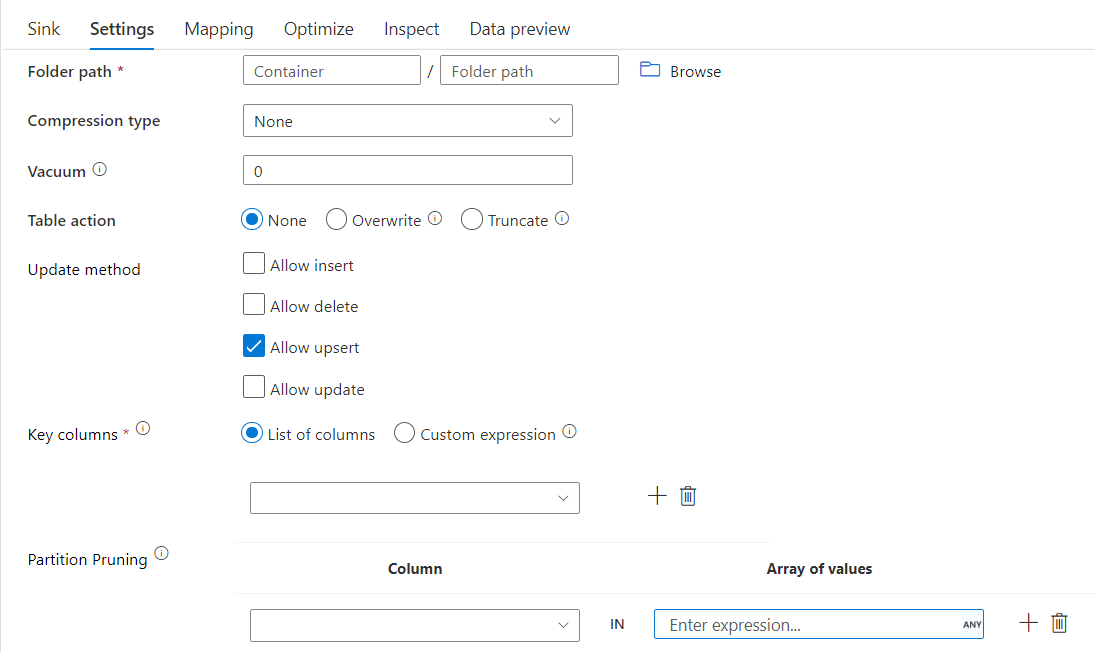
Voorbeeld van Delta-sinkscript met partitiesnoeien
Hieronder ziet u een voorbeeldscript.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta leest slechts 2 partities waarbij part_col == 5 en 8 uit het doel deltaarchief in plaats van alle partities. part_col is een kolom waarmee de doel-deltagegevens worden gepartitioneerd. Deze hoeft niet aanwezig te zijn in de brongegevens.
Optimalisatieopties voor Delta-sinks
Op het tabblad Instellingen vindt u nog drie opties voor het optimaliseren van delta-sinktransformatie.
Wanneer de optie Schema samenvoegen is ingeschakeld, wordt schemaontwikkeling mogelijk, d.w.z. kolommen die aanwezig zijn in de huidige binnenkomende stroom, maar niet in de doel-Delta-tabel, automatisch toegevoegd aan het schema. Deze optie wordt ondersteund voor alle updatemethoden.
Wanneer automatisch comprimeren is ingeschakeld, controleert transformatie na een afzonderlijke schrijfbewerking of bestanden verder kunnen worden gecomprimeerd en wordt een snelle OPTIMIZE-taak (met 128 MB-bestandsgrootten in plaats van 1 GB) uitgevoerd om bestanden verder te comprimeren voor partities met het meeste aantal kleine bestanden. Automatische compressie helpt bij het samenvoegen van een groot aantal kleine bestanden in een kleiner aantal grote bestanden. Automatisch comprimeren wordt alleen geactiveerd wanneer er ten minste 50 bestanden zijn. Zodra een compressiebewerking is uitgevoerd, wordt er een nieuwe versie van de tabel gemaakt en wordt een nieuw bestand geschreven met de gegevens van verschillende eerdere bestanden in een gecomprimeerd gecomprimeerde vorm.
Wanneer Schrijfbewerking optimaliseren is ingeschakeld, optimaliseert sinktransformatie partitiegrootten dynamisch op basis van de werkelijke gegevens door 128 MB-bestanden voor elke tabelpartitie te schrijven. Dit is een geschatte grootte en kan variëren, afhankelijk van de kenmerken van de gegevensset. Geoptimaliseerde schrijfbewerkingen verbeteren de algehele efficiëntie van de schrijfbewerkingen en volgende leesbewerkingen. Het organiseert partities zodanig dat de prestaties van volgende leesbewerkingen verbeteren.
Tip
Het geoptimaliseerde schrijfproces vertraagt de algehele ETL-taak omdat de Sink de opdracht Spark Delta Lake Optimize uitdra uw gegevens zijn verwerkt. Het wordt aanbevolen om geoptimaliseerde schrijfbewerkingen spaarzaam te gebruiken. Als u bijvoorbeeld een gegevenspijplijn per uur hebt, voert u een gegevensstroom uit met geoptimaliseerde schrijfbewerkingen per dag.
Bekende beperkingen
Wanneer u naar een delta-sink schrijft, is er een bekende beperking waarbij het aantal geschreven rijen niet wordt weergegeven in de uitvoer van de bewaking.
Gerelateerde inhoud
- Maak een brontransformatie in de toewijzingsgegevensstroom.
- Maak een sinktransformatie in de toewijzingsgegevensstroom.
- Maak een wijzigingsrijtransformatie om rijen te markeren als invoegen, bijwerken, upsert of verwijderen.