Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory-pijplijnen als Azure Synapse Analytics-pijplijnen. Dit artikel is van toepassing op het in kaart brengen van gegevensstromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Met een brontransformatie configureert u uw gegevensbron voor de gegevensstroom. Wanneer u gegevensstromen ontwerpt, is uw eerste stap altijd het configureren van een brontransformatie. Als u een bron wilt toevoegen, selecteert u het vak Bron toevoegen in het gegevensstroomcanvas.
Elke gegevensstroom vereist ten minste één brontransformatie, maar u kunt zoveel bronnen toevoegen als nodig is om uw gegevenstransformaties te voltooien. U kunt deze bronnen samenvoegen met een join, lookup of unietransformatie.
Elke brontransformatie is gekoppeld aan precies één gegevensset of gekoppelde service. De gegevensset definieert de shape en locatie van de gegevens waaruit u wilt schrijven of waaruit u wilt lezen. Als u een gegevensset op basis van bestanden gebruikt, kunt u jokertekens en bestandslijsten in uw bron gebruiken om met meer dan één bestand tegelijk te werken.
Inline gegevenssets
De eerste beslissing die u neemt wanneer u een brontransformatie maakt, is of uw brongegevens zijn gedefinieerd in een gegevenssetobject of binnen de brontransformatie. De meeste indelingen zijn slechts in één van beide beschikbaar. Zie het juiste connectordocument voor meer informatie over het gebruik van een specifieke connector.
Wanneer een indeling wordt ondersteund voor zowel inline als in een gegevenssetobject, zijn er voordelen aan beide opties. Gegevenssetobjecten zijn herbruikbare entiteiten die kunnen worden gebruikt in andere gegevensstromen en activiteiten zoals Kopiëren. Deze herbruikbare entiteiten zijn vooral handig wanneer u een beperkt schema gebruikt. Gegevenssets zijn niet gebaseerd op Spark. Soms moet u bepaalde instellingen of schemaprojectie in de brontransformatie overschrijven.
Inlinegegevenssets worden aanbevolen wanneer u flexibele schema's, eenmalige bronexemplaren of geparameteriseerde bronnen gebruikt. Als uw bron zwaar wordt geparameteriseerd, kunt u met inlinegegevenssets geen dummy-object maken. Inlinegegevenssets zijn gebaseerd op Spark en hun eigenschappen zijn onderdeel van de gegevensstroom.
Als u een inlinegegevensset wilt gebruiken, selecteert u de gewenste indeling in de brontypekiezer . In plaats van een brongegevensset te selecteren, selecteert u de gekoppelde service waarmee u verbinding wilt maken.
Schemaopties
Omdat een inlinegegevensset is gedefinieerd in de gegevensstroom, is er geen gedefinieerd schema gekoppeld aan de inlinegegevensset. Op het tabblad Projectie kunt u het brongegevensschema importeren en dat schema opslaan als bronprojectie. Op dit tabblad vindt u een knop Schemaopties waarmee u het gedrag van de schemadetectieservice van ADF kunt definiëren.
- Gebruik een geprojecteerd schema: deze optie is handig wanneer u een groot aantal bronbestanden hebt die ADF als bron scant. Het standaardgedrag van ADF is het detecteren van het schema van elk bronbestand. Maar als u al een vooraf gedefinieerde projectie hebt opgeslagen in uw brontransformatie, kunt u deze instellen op 'true' en wordt de automatische detectie van elk schema overgeslagen. Als deze optie is ingeschakeld, kan de brontransformatie alle bestanden veel sneller lezen, waarbij het vooraf gedefinieerde schema op elk bestand wordt toegepast.
- Schemadrift toestaan: schakel schemadrift in zodat uw gegevensstroom nieuwe kolommen toestaat die nog niet zijn gedefinieerd in het bronschema.
- Schema valideren: als u deze optie instelt, mislukt de gegevensstroom als een kolom en type dat in de projectie is gedefinieerd, niet overeenkomt met het gedetecteerde schema van de brongegevens.
- Afleiden van afwijkende kolomtypen: Wanneer nieuwe afwijkende kolommen worden geïdentificeerd door ADF, worden deze nieuwe kolommen gecast naar het juiste gegevensstype met behulp van de automatische type-inferentie van ADF.
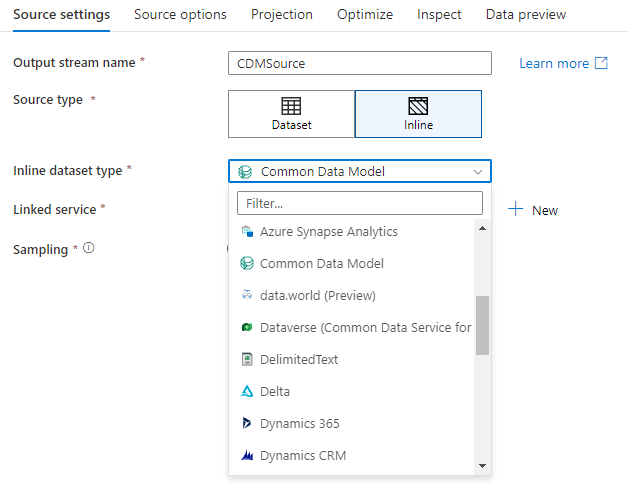
Werkruimtedatabase (alleen Synapse-werkruimten)
In Azure Synapse-werkruimten is er een extra optie aanwezig in gegevensstroombrontransformaties met de naam Workspace DB. Hiermee kunt u rechtstreeks een werkruimtedatabase van elk beschikbaar type kiezen als brongegevens zonder dat hiervoor aanvullende gekoppelde services of gegevenssets nodig zijn. De databases die zijn gemaakt via de Azure Synapse-databasesjablonen , zijn ook toegankelijk wanneer u Werkruimtedatabase selecteert.
Ondersteunde brontypen
Toewijzingsgegevensstroom volgt een ELT-benadering (EXTRAHEREN, laden en transformeren) en werkt met faseringsgegevenssets die zich allemaal in Azure bevinden. Momenteel kunnen de volgende gegevenssets worden gebruikt in een brontransformatie.
Instellingen die specifiek zijn voor deze connectors bevinden zich op het tabblad Bronopties . Voorbeelden van informatie- en gegevensstroomscripts op deze instellingen bevinden zich in de connectordocumentatie.
Azure Data Factory- en Synapse-pijplijnen hebben toegang tot meer dan 90 systeemeigen connectors. Als u gegevens uit die andere bronnen in uw gegevensstroom wilt opnemen, gebruikt u de kopieeractiviteit om die gegevens te laden in een van de ondersteunde faseringsgebieden.
Broninstellingen
Nadat u een bron hebt toegevoegd, kunt u deze configureren via het tabblad Broninstellingen. Hier kunt u de gegevensset kiezen of maken waarnaar uw bron verwijst. U kunt ook schema- en samplingopties voor uw gegevens selecteren.
Ontwikkelingswaarden voor gegevenssetparameters kunnen worden geconfigureerd in foutopsporingsinstellingen. (De foutopsporingsmodus moet zijn ingeschakeld.)
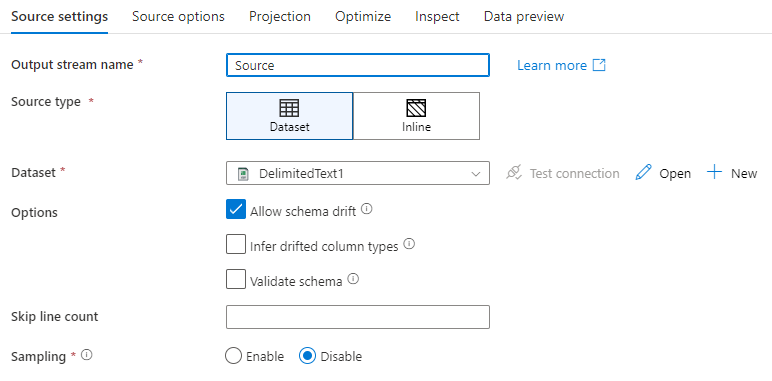
Naam van uitvoerstroom: de naam van de brontransformatie.
Brontype: Kies of u een inline gegevensset of een bestaand gegevenssetobject wilt gebruiken.
Testverbinding: test of de Spark-service van de gegevensstroom verbinding kan maken met de gekoppelde service die in uw brongegevensset wordt gebruikt. De foutopsporingsmodus moet zijn ingeschakeld voor deze functie.
Schemadrift: Schemadrift is de mogelijkheid van de service om flexibele schema's in uw gegevensstromen systeemeigen af te handelen zonder dat u expliciet kolomwijzigingen hoeft te definiëren.
Selecteer het selectievakje Schema-drift toestaan als de bronkolommen vaak veranderen. Met deze instelling kunnen alle binnenkomende bronvelden door de transformaties naar de sink stromen.
Door Afgeleid afwijkende kolomtypen te selecteren, wordt de service geïnstrueerd om gegevenstypen te detecteren en te definiëren voor elke nieuw ontdekte kolom. Als deze functie is uitgeschakeld, zijn alle gedrifte kolommen van het type tekenreeks.
Schema valideren: als het schema valideren is geselecteerd, kan de gegevensstroom niet worden uitgevoerd als de binnenkomende brongegevens niet overeenkomen met het gedefinieerde schema van de gegevensset.
Aantal regels overslaan: Het veld Regelaantal overslaan geeft aan hoeveel regels aan het begin van de gegevensset moeten worden genegeerd.
Steekproeven: Schakel steekproeven in om het aantal rijen van uw bron te beperken. Gebruik deze instelling wanneer u gegevens test of voorbeeldgegevens uit uw bron voor foutopsporingsdoeleinden. Dit is erg handig bij het uitvoeren van gegevensstromen in de foutopsporingsmodus vanuit een pijplijn.
Als u wilt controleren of uw bron correct is geconfigureerd, schakelt u de foutopsporingsmodus in en haalt u een voorbeeld van gegevens op. Zie de foutopsporingsmodus voor meer informatie.
Notitie
Wanneer de foutopsporingsmodus is ingeschakeld, overschrijft de configuratie van de rijlimiet in foutopsporingsinstellingen de sampling-instelling in de bron tijdens de voorbeeldweergave van de gegevens.
Bronopties
Het tabblad Bronopties bevat instellingen die specifiek zijn voor de gekozen connector en indeling. Zie de relevante connectordocumentatie voor meer informatie en voorbeelden. Dit omvat details zoals isolatieniveau voor gegevensbronnen die dit ondersteunen (zoals on-premises SQL-servers, Azure SQL Databases en Azure SQL Managed Instances) en andere instellingen voor gegevensbronnen.
Projectie
Net als bij schema's in gegevenssets definieert de projectie in een bron de gegevenskolommen, typen en indelingen van de brongegevens. Voor de meeste typen gegevenssets, zoals SQL en Parquet, wordt de projectie in een bron vastgezet om het schema weer te geven dat is gedefinieerd in een gegevensset, die afhankelijk is van de bron. Wanneer uw bronbestanden niet sterk zijn getypt (bijvoorbeeld platte .csv bestanden in plaats van Parquet-bestanden), kunt u de gegevenstypen definiëren voor elk veld in de brontransformatie. In de volgende afbeelding ziet u een voorbeeldprojectie:
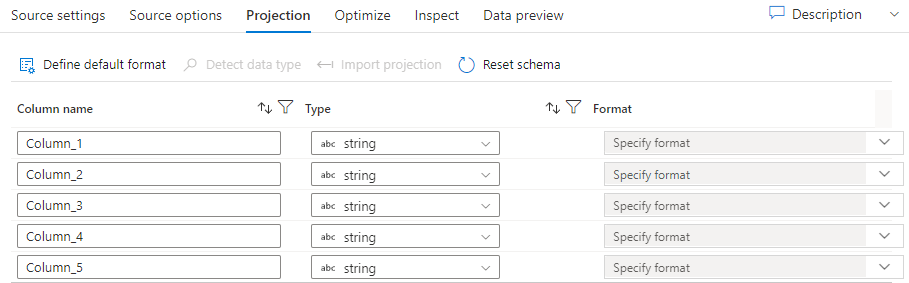
Als uw tekstbestand geen gedefinieerd schema heeft, selecteer Gegevenstype detecteren zodat de service voorbeelden neemt en de gegevenstypen afleidt. Selecteer Standaardindeling definiëren om de standaardgegevensindelingen automatisch te detecteren.
Het schema opnieuw instellen stelt de projectie opnieuw in op wat is gedefinieerd in de gegevensset waarnaar wordt verwezen.
Met het overschrijven van het schema kunt u de verwachte gegevenstypen hier wijzigen in de bron, waarbij u de door het schema gedefinieerde gegevenstypen overschrijft. U kunt de kolomgegevenstypen ook wijzigen in een downstream transformatie van afgeleide kolommen. Gebruik een selectietransformatie om de kolomnamen te wijzigen.
Schema importeren
Selecteer de knop Schema importeren op het tabblad Projectie om een actief foutopsporingscluster te gebruiken om een schemaprojectie te maken. Deze is beschikbaar in elk brontype. Als u het schema hier importeert, wordt de projectie die in de gegevensset is gedefinieerd, overschreven. Het gegevenssetobject wordt niet gewijzigd.
Het importeren van een schema is handig in gegevenssets zoals Avro en Azure Cosmos DB die ondersteuning bieden voor complexe gegevensstructuren waarvoor geen schemadefinities in de gegevensset hoeven te bestaan. Voor inline-gegevenssets is het importeren van schema de enige manier om te verwijzen naar metagegevens van kolommen zonder schemadrift.
De brontransformatie optimaliseren
Op het tabblad Optimaliseren kunt u partitiegegevens bij elke transformatiestap bewerken. In de meeste gevallen optimaliseert huidige partitionering gebruiken voor de ideale partitiestructuur van een bron.
Als u leest uit een Azure SQL Database-bron, leest aangepaste bronpartitionering waarschijnlijk de snelste gegevens. De service leest grote query's door verbindingen met uw database parallel te maken. Deze bronpartitionering kan worden uitgevoerd op een kolom of met behulp van een query.
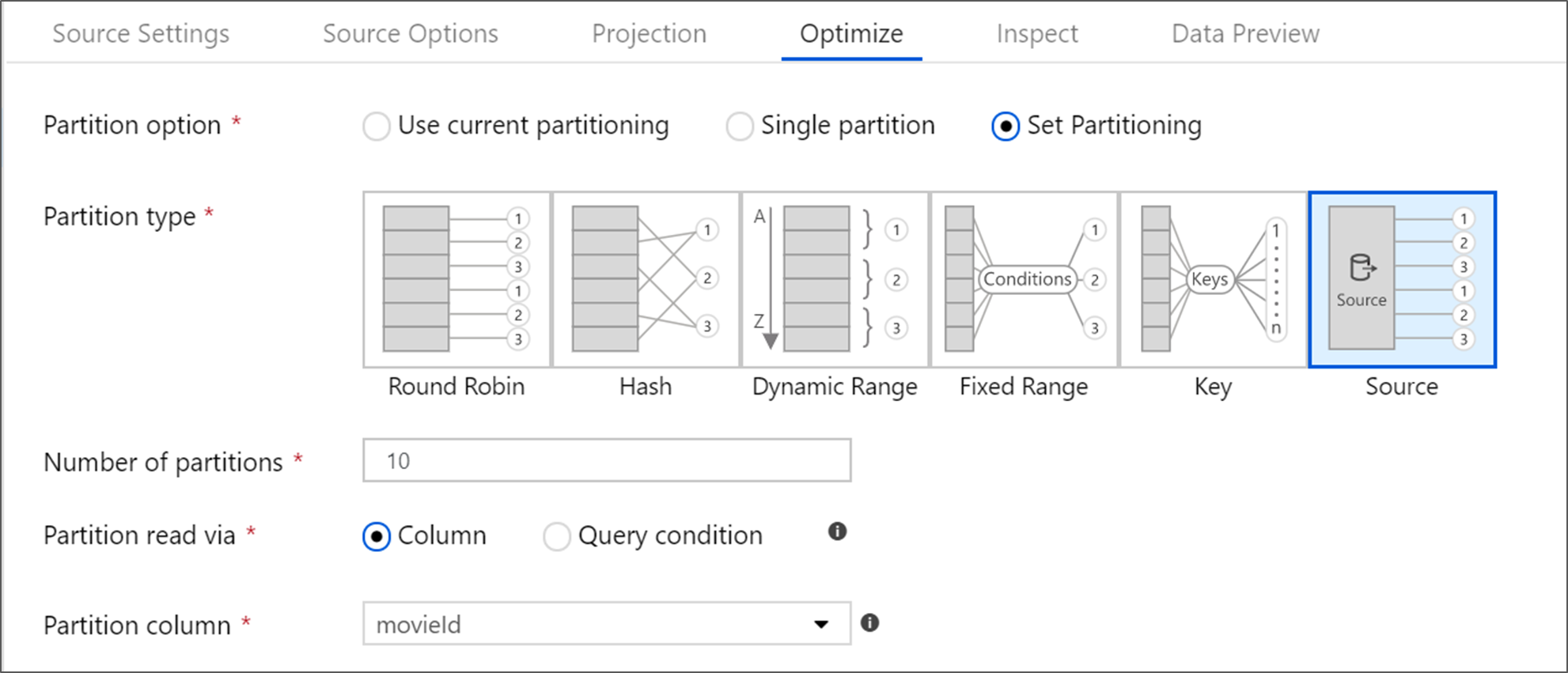
Zie het Optimaliseren-tabblad voor meer informatie over optimalisatie binnen de gegevensstroom voor mapping.
Gerelateerde inhoud
Begin met het bouwen van uw gegevensstroom met een transformatie van afgeleide kolommen en een selectietransformatie.