Gegevensintegratie met behulp van Azure Data Factory en Azure Data Share
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Als klanten hun moderne datawarehouse- en analyseprojecten starten, hebben ze niet alleen meer gegevens nodig, maar ook meer inzicht in hun gegevens. Deze workshop gaat dieper in op hoe verbeteringen aan Azure Data Factory en Azure Data Share gegevensintegratie en -beheer in Azure vereenvoudigen.
Van het inschakelen van codevrije ETL/ELT tot het creëren van een uitgebreide weergave van uw gegevens, verbeteringen in Azure Data Factory stellen uw data engineers in staat om meer gegevens en dus meer waarde toe te voegen aan uw onderneming. Met Azure Data Share kunt u zaken doen met zakelijke delen op een beheerde manier.
In deze workshop gebruikt u Azure Data Factory (ADF) om gegevens van Azure SQL Database op te nemen in Azure Data Lake Storage Gen2 (ADLS Gen2). Zodra u de gegevens in het lake hebt opgenomen, kunt u deze transformeren via toewijzingsgegevensstroom, de systeemeigen transformatieservice van Data Dactory, en deze opvangen in Azure Synapse Analytics. Vervolgens deelt u de tabel met getransformeerde gegevens, samen met enkele aanvullende gegevens met behulp van de Azure Data Share.
De gegevens die in dit lab worden gebruikt, zijn gegevens van New York City-taxi. Als u deze wilt importeren in uw database in SQL Database, moet u het taxi-data bacpac-bestand downloaden. Selecteer de optie Onbewerkt bestand downloaden in GitHub.
Vereisten
Azure-abonnement: als u nog geen abonnement op Azure hebt, maakt u een gratis Azure-account aan voordat u begint.
Azure SQL Database: Als u geen Azure SQL Database hebt, leert u hoe u een SQL Database maakt.
Azure Data Lake Storage Gen2-opslagaccount: als u geen ADLS Gen2-opslagaccount hebt, leert u hoe u een ADLS Gen2-opslagaccount maakt.
Azure Synapse Analytics: Als u geen Azure Synapse Analytics-werkruimte hebt, leert u hoe u aan de slag gaat met Azure Synapse Analytics.
Azure Data Factory: Als u nog geen gegevensfactory hebt gemaakt, raadpleegt u hoe u een data factory maakt.
Azure Data Share: Als u nog geen gegevensshare hebt gemaakt, raadpleegt u hoe u een gegevensshare maakt.
Uw Azure Data Factory-omgeving instellen
In deze sectie leert u hoe u toegang krijgt tot de Azure Data Factory-gebruikerservaring (ADF UX) vanuit Azure Portal. Eenmaal in de ADF UX configureert u drie gekoppelde service voor elk van de gegevensarchieven die we gebruiken: Azure SQL Database, ADLS Gen2 en Azure Synapse Analytics.
Definieer in gekoppelde Azure Data Factory-services de verbindingsgegevens met externe resources. Azure Data Factory ondersteunt momenteel meer dan 85 connectors.
Open de Azure Data Factory UX
Open de Azure-portal in Microsoft Edge of Google Chrome.
Zoek met behulp van de zoekbalk boven aan de pagina naar 'Data Factory's'.
Selecteer uw data factory-resource om de resources in het linkerdeelvenster te openen.
Selecteer Azure Data Factory Studio openen. De Data Factory Studio is ook rechtstreeks toegankelijk op adf.azure.com.
U wordt omgeleid naar de startpagina van ADF in Azure Portal. Deze pagina bevat quickstarts, instructievideo's en koppelingen naar zelfstudies voor meer informatie over data factory-concepten. Als u wilt beginnen met ontwerpen, selecteert u het potloodpictogram in de linkerzijbalk.


Een gekoppelde Azure SQL Database-service maken
Als u een gekoppelde service wilt maken, selecteert u Hub beheren in de linkerzijbalk in het deelvenster Verbinding maken ions, selecteert u Gekoppelde services en selecteert u Vervolgens Nieuw om een nieuwe gekoppelde service toe te voegen.
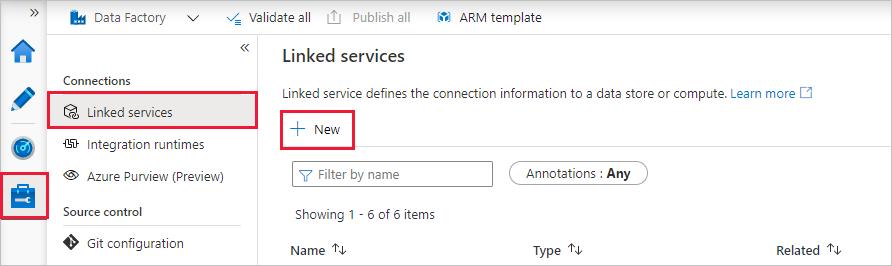
De eerste gekoppelde service die u configureert, is een Azure SQL Database. U kunt de zoekbalk gebruiken om de lijst met gegevensarchieven te filteren. Selecteer op de tegel Azure SQL Database en selecteer Doorgaan.

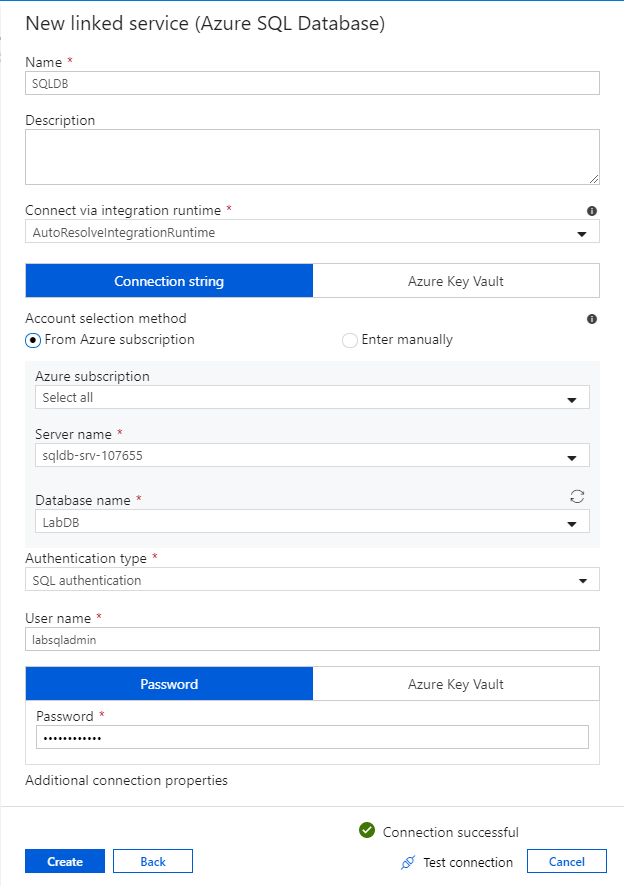
Voer in het deelvenster SQL Database-configuratie 'SQLDB' in als de naam van de gekoppelde service. Voer uw aanmeldingsgegevens in om data factory verbinding te laten maken met uw database. Als u SQL-verificatie gebruikt, voert u de servernaam, de database, uw gebruikersnaam en wachtwoord in. U kunt controleren of uw verbindingsgegevens juist zijn door De verbinding testen te selecteren. Selecteer Maken nadat dit is voltooid.

Een gekoppelde Azure Synapse Analytics-service maken
Herhaal hetzelfde proces om een gekoppelde Azure Synapse Analytics-service toe te voegen. Selecteer Nieuw op het tabblad Verbindingen. Selecteer de tegel Azure Synapse Analytics en selecteer Doorgaan.
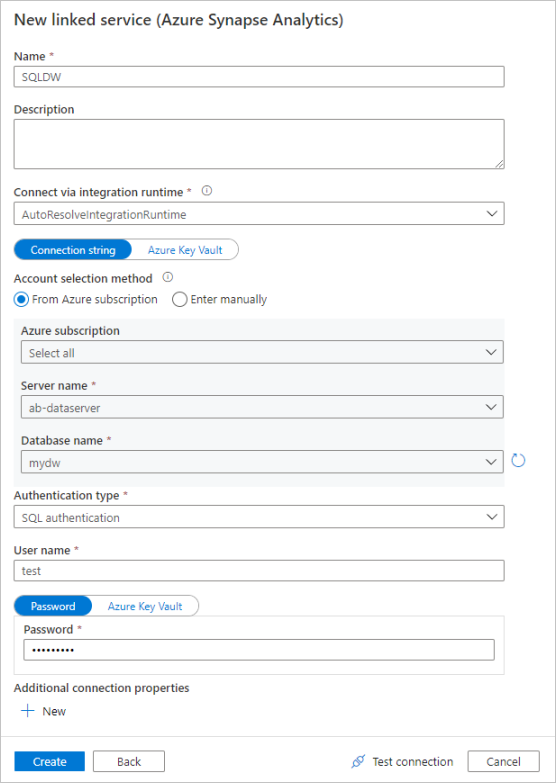
Voer in het deelvenster voor de configuratie van de gekoppelde service 'SQLDW' in als de naam van uw gekoppelde service. Voer uw aanmeldingsgegevens in om data factory verbinding te laten maken met uw database. Als u SQL-verificatie gebruikt, voert u de servernaam, de database, uw gebruikersnaam en wachtwoord in. U kunt controleren of uw verbindingsgegevens juist zijn door De verbinding testen te selecteren. Selecteer Maken nadat dit is voltooid.
Een gekoppelde Azure Data Lake Storage Gen2-service maken
De laatste gekoppelde service die nodig is voor dit lab is een Azure Data Lake Storage Gen2. Selecteer Nieuw op het tabblad Verbindingen. Selecteer de tegel Azure Data Lake Storage Gen2 en selecteer Doorgaan.
Voer in het deelvenster Configuratie van gekoppelde service 'ADLSGen2' in als de naam van de gekoppelde service. Als u accountsleutelverificatie gebruikt, selecteert u uw ADLS Gen2-opslagaccount in de vervolgkeuzelijst Opslagaccountnaam . U kunt controleren of uw verbindingsgegevens juist zijn door De verbinding testen te selecteren. Selecteer Maken nadat dit is voltooid.
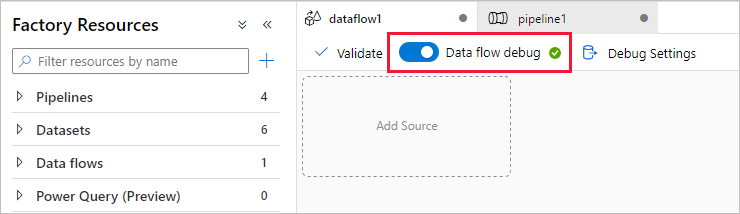
Foutopsporingsmodus voor gegevensstromen inschakelen
In de sectie Gegevens transformeren met behulp van toewijzingsgegevensstroom bouwt u toewijzingsgegevensstromen. Een best practice voordat u toewijzingsgegevensstromen bouwt, is het inschakelen van de foutopsporingsmodus, waarmee u de transformatielogica in een paar seconden kunt testen op een actief Spark-cluster.
Als u foutopsporing wilt inschakelen, selecteert u de schuifregelaar voor foutopsporing in de bovenste balk van het gegevensstroomcanvas of pijplijncanvas wanneer u gegevensstroomactiviteiten hebt. Selecteer OK wanneer het bevestigingsdialoogvenster wordt weergegeven. Het cluster wordt in ongeveer 5 tot 7 minuten gestart. Ga verder met het opnemen van gegevens uit Azure SQL Database in ADLS Gen2 met behulp van de kopieeractiviteit terwijl deze wordt geïnitialiseerd.

Gegevens opnemen met behulp van de kopieeractiviteit
In deze sectie maakt u een pijplijn met een kopieeractiviteit die één tabel uit een Azure SQL Database opneemt in een ADLS Gen2-opslagaccount. U leert hoe u een pijplijn toevoegt, een gegevensset configureert en fouten in een pijplijn opstakt via de ADF UX. Het configuratiepatroon dat wordt gebruikt in deze zelfstudie, kan worden toegepast op het kopiëren van een relationeel gegevensarchief naar een gegevensarchief op basis van bestanden.
In Azure Data Factory is een pijplijn een logische groep activiteiten die samen een taak uitvoeren. Een activiteit definieert een bewerking die op uw gegevens moet worden uitgevoerd. Een gegevensset wijst naar de gegevens die u wilt gebruiken in een gekoppelde service.
Een pijplijn met kopieeractiviteit maken
Selecteer in het deelvenster Factory-resources het pluspictogram om het nieuwe resourcemenu te openen. Selecteer Pijplijn.
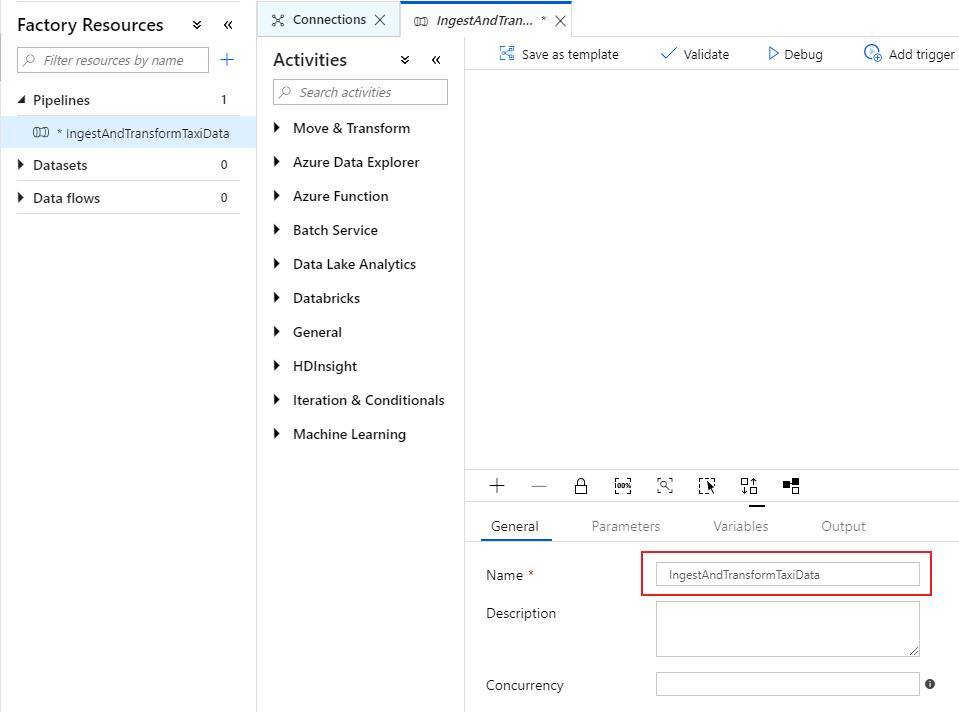
Geef op het tabblad Algemeen van het pijplijncanvas een beschrijvende naam op voor de pijplijn, zoals 'IngestAndTransformTaxiData'.
Open in het deelvenster Activiteiten van het pijplijncanvas de accordion Verplaatsen en transformeren en sleep de activiteit Gegevens kopiëren naar het canvas. Geef de kopieeractiviteit een beschrijvende naam zoals 'IngestIntoADLS'.
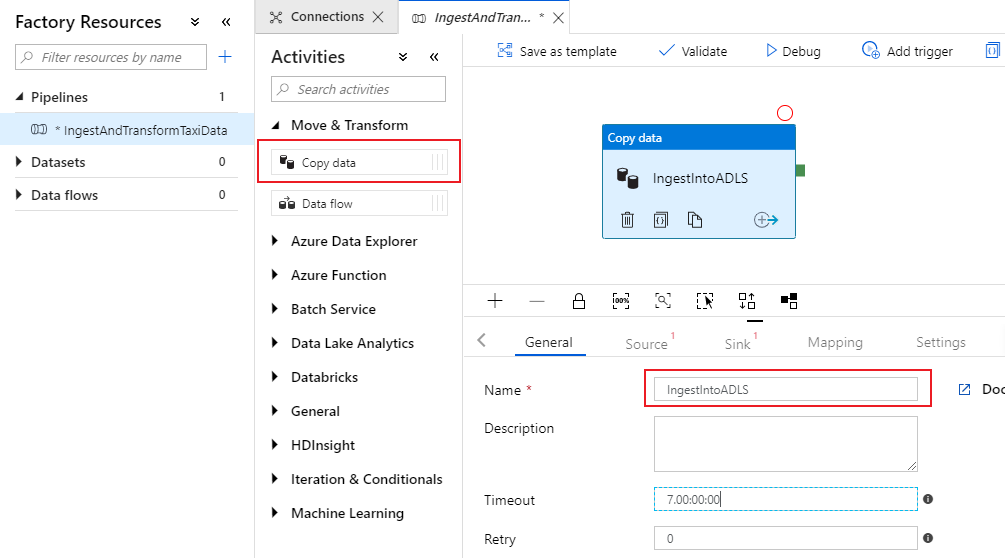


Azure SQL DB-brongegevensset configureren
Selecteer op het tabblad Bron van de kopieeractiviteit. Als u een nieuwe gegevensset wilt maken, selecteert u Nieuw. Uw bron is de tabel
dbo.TripDatain de gekoppelde service SQLDB die eerder is geconfigureerd.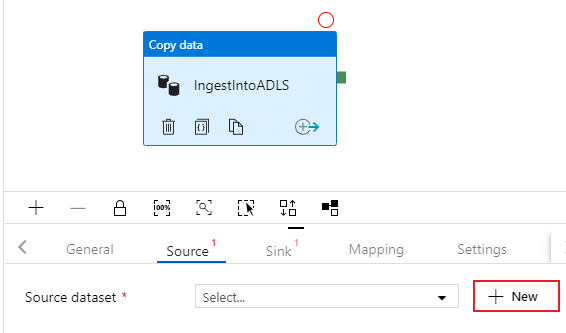
Zoek naar Azure SQL Database en selecteer Doorgaan.
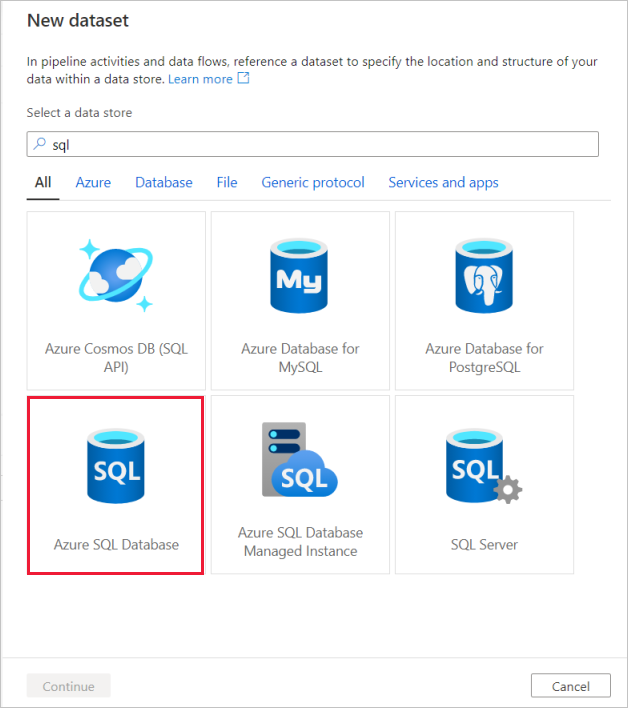
Roep de gegevensset 'TripData' aan. Selecteer 'SQLDB' als uw gekoppelde service. Selecteer de tabelnaam in de vervolgkeuzelijst tabelnaam
dbo.TripData. Importeer het schema Uit verbinding/archief. Wanneer u klaar bent, selecteert u OK.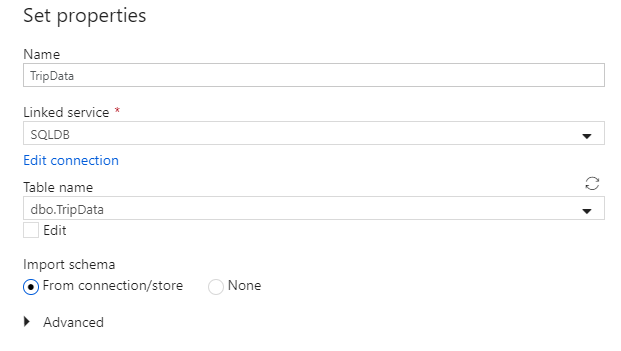
U hebt uw eerste brongegevensset gemaakt. Zorg ervoor dat in de broninstellingen de standaardwaarde Tabel is geselecteerd in het veld Query gebruiken.
ADLS Gen 2-sinkgegevensset configureren
Selecteer op het tabblad Sink van de kopieeractiviteit. Als u een nieuwe gegevensset wilt maken, selecteert u Nieuw.
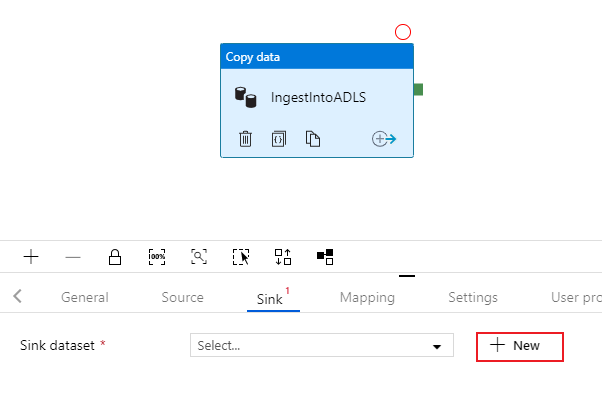
Zoek naar Azure Data Lake Storage Gen2 en selecteer Doorgaan.
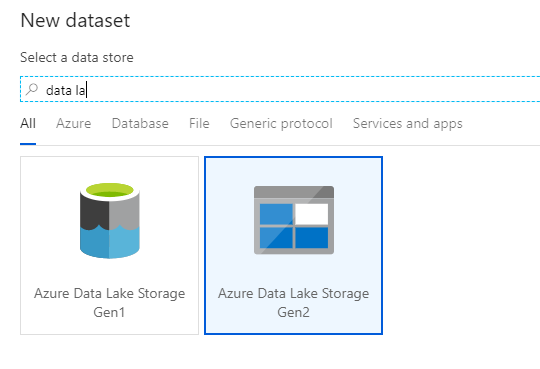
Selecteer in het deelvenster Opmaak selecteren de optie DelimitedText terwijl u naar een CSV-bestand schrijft. Selecteer Doorgaan.

Noem uw sinkgegevensset 'TripDataCSV'. Selecteer 'ADLSGen2' als uw gekoppelde service. Voer in waar u uw CSV-bestand wilt schrijven. U kunt bijvoorbeeld uw gegevens schrijven naar het bestand
trip-data.csvin containerstaging-container. Stel Eerste rij als header in op waar als u wilt dat uw uitvoergegevens headers bevatten. Omdat er nog geen bestand in de bestemming bestaat, stelt u Importschema in op Geen. Wanneer u klaar bent, selecteert u OK.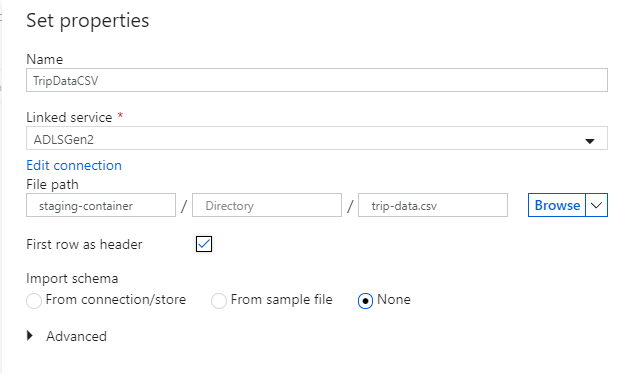
De kopieeractiviteit testen met het uitvoeren van een pijplijnfoutopsporing
Als u wilt controleren of uw kopieeractiviteit correct werkt, selecteert u Fouten opsporen boven aan het pijplijncanvas om een foutopsporingsuitvoering uit te voeren. Met een foutopsporingsuitvoering kunt u de pijplijn end-to-end testen of tot een onderbrekingspunt voordat u deze naar de data factory-service publiceert.
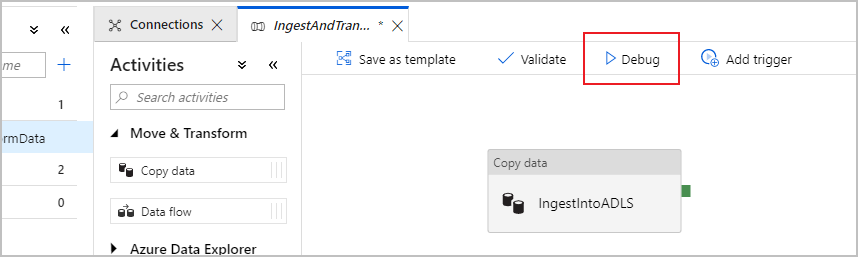
Als u de foutopsporingsuitvoering wilt controleren, gaat u naar het tabblad Uitvoer van het pijplijncanvas. Het bewakingsscherm wordt elke 20 seconden automatisch vernieuwd of wanneer u de knop Vernieuwen handmatig selecteert. De kopieeractiviteit heeft een speciale bewakingsweergave die toegankelijk is door het brilpictogram in de kolom Acties te selecteren.
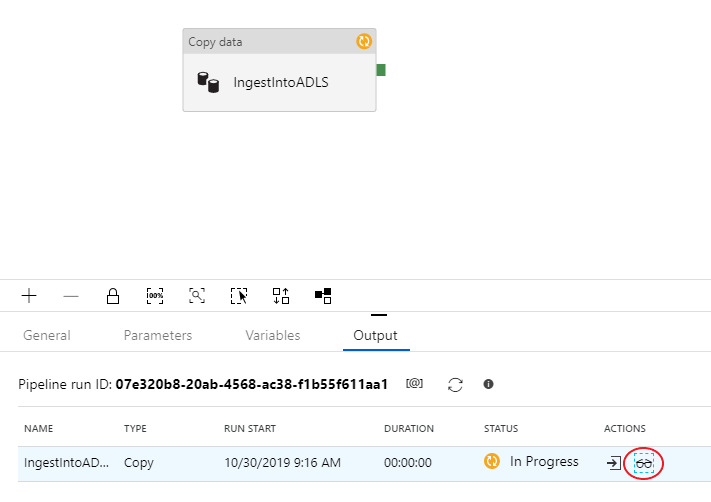
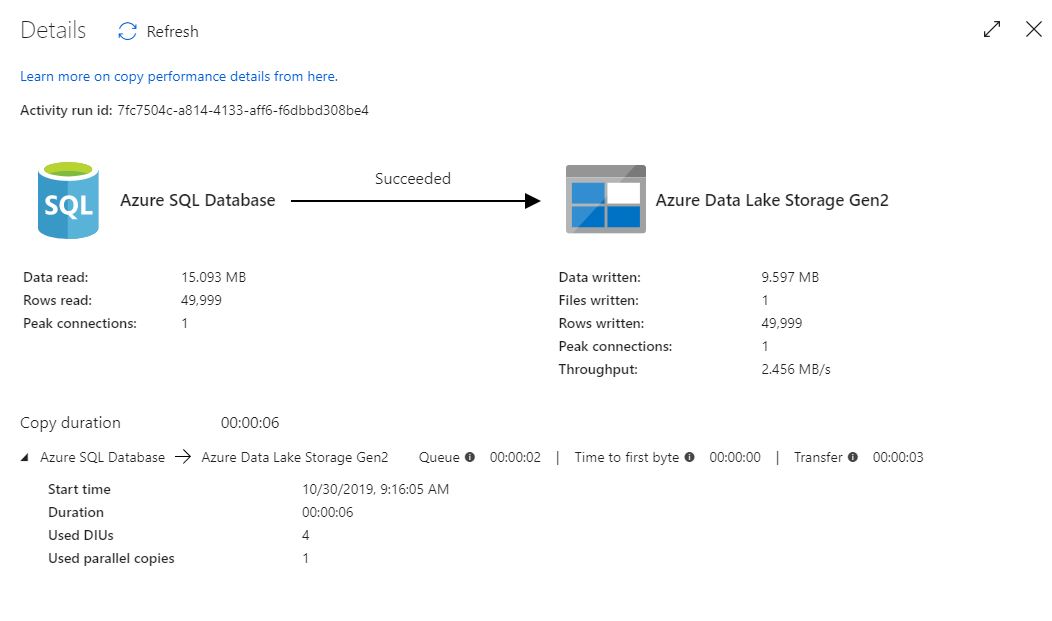
De controleweergave voor kopiëren bevat de uitvoeringsdetails en prestatiekenmerken van de activiteit. U kunt informatie bekijken zoals gelezen/geschreven gegevens, gelezen/geschreven rijen, gelezen/geschreven bestanden en doorvoer. Als u alles correct hebt geconfigureerd, ziet u 49.999 rijen die in één bestand in uw ADLS-sink zijn geschreven.
Voordat u verdergaat met de volgende sectie, wordt u aangeraden uw wijzigingen naar de data factory-service te publiceren door Alles publiceren te selecteren in de bovenste balk van de fabriek. Hoewel dit niet wordt besproken in dit lab, ondersteunt Azure Data Factory volledige git-integratie. Git-integratie biedt versiebeheer, iteratief opslaan in een opslagplaats en samenwerking op een data factory. Zie voor meer informatie broncodebeheer in Azure Data Factory.


Gegevens transformeren met toewijzingsgegevensstroom
Nu u gegevens naar Azure Data Lake Storage hebt gekopieerd, is het tijd om die gegevens samen te voegen en te aggregeren in een datawarehouse. We gebruiken de toewijzingsgegevensstroom, de visueel ontworpen transformatieservice van Azure Data Factory. Met toewijzingsgegevensstromen kunnen gebruikers transformatielogica codevrij ontwikkelen en uitvoeren op Spark-clusters die worden beheerd door de ADF-service.
De gegevensstroom die in deze stap is gemaakt, voegt de gegevensset TripDataCSV die in de vorige sectie is gemaakt samen met een tabel dbo.TripFares die is opgeslagen in SQLDB op basis van vier sleutelkolommen. Vervolgens worden de gegevens geaggregeerd op basis van kolom payment_type om het gemiddelde van bepaalde velden te berekenen en worden ze geschreven naar een Azure Synapse Analytics-tabel.
Een gegevensstroomactiviteit toevoegen aan uw pijplijn
Open in het deelvenster Activiteiten van het pijplijncanvas de accordion Verplaatsen en transformeren en sleep de activiteit Gegevensstroom naar het canvas.
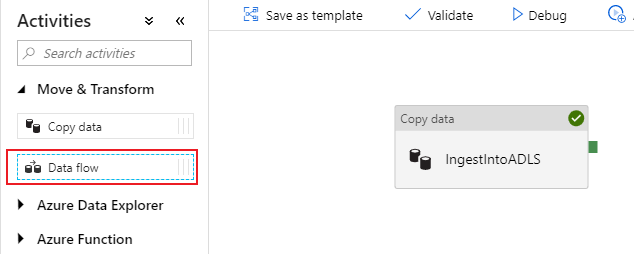
Selecteer in het zijdeelvenster dat wordt geopend Nieuwe gegevensstroom maken en kies Toewijzingsgegevensstroom. Selecteer OK.
U wordt omgeleid naar het gegevensstroomcanvas waar u uw transformatielogica gaat bouwen. Geef op het tabblad Algemeen uw gegevensstroom de naam 'JoinAndAggregateData'.


CSV-bron voor reisgegevens configureren
Het eerste wat u moet doen is uw twee brontransformaties configureren. De eerste bron verwijst naar de gegevensset 'TripDataCSV' DelimitedText. Als u een brontransformatie wilt toevoegen, selecteert u het vak Bron toevoegen op het canvas.
Geef uw bron de naam TripDataCSV en selecteer de gegevensset TripDataCSV in de vervolgkeuzelijst bron. U hebt in eerste instantie geen schema geïmporteerd bij het maken van deze gegevensset omdat er geen gegevens waren. Aangezien
trip-data.csvdit nu bestaat, selecteert u Bewerken om naar het tabblad Instellingen van de gegevensset te gaan.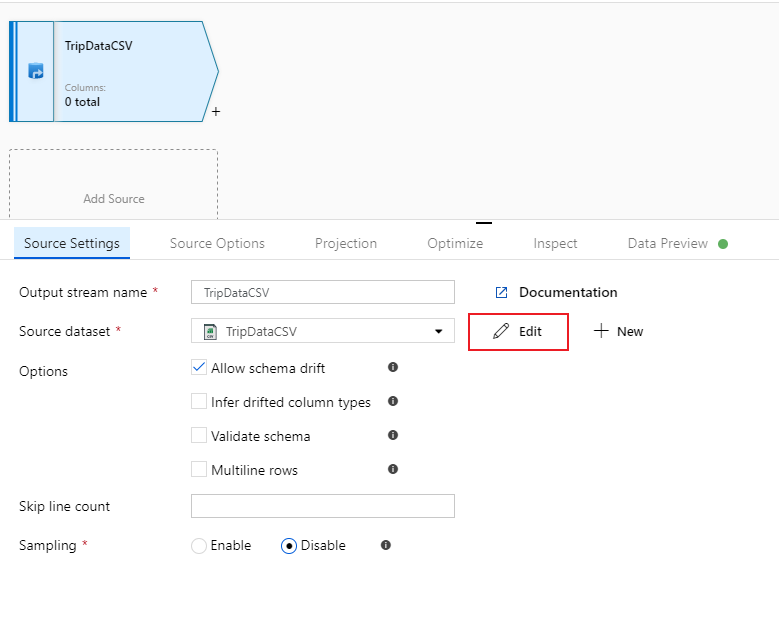
Ga naar het tabblad Schema en selecteer Schema importeren. Selecteer Uit verbinding/archief om rechtstreeks vanuit het bestandsarchief te importeren. Er moeten 14 kolommen van het type tekenreeks worden weergegeven.
Ga terug naar de gegevensstroom 'JoinAndAggregateData'. Als uw foutopsporingscluster is gestart (aangegeven met een groene cirkel naast de schuifregelaar voor foutopsporing), kunt u een momentopname van de gegevens op het tabblad Gegevensvoorbeeld ophalen. Selecteer Vernieuwen om een voorbeeld van gegevens op te halen.
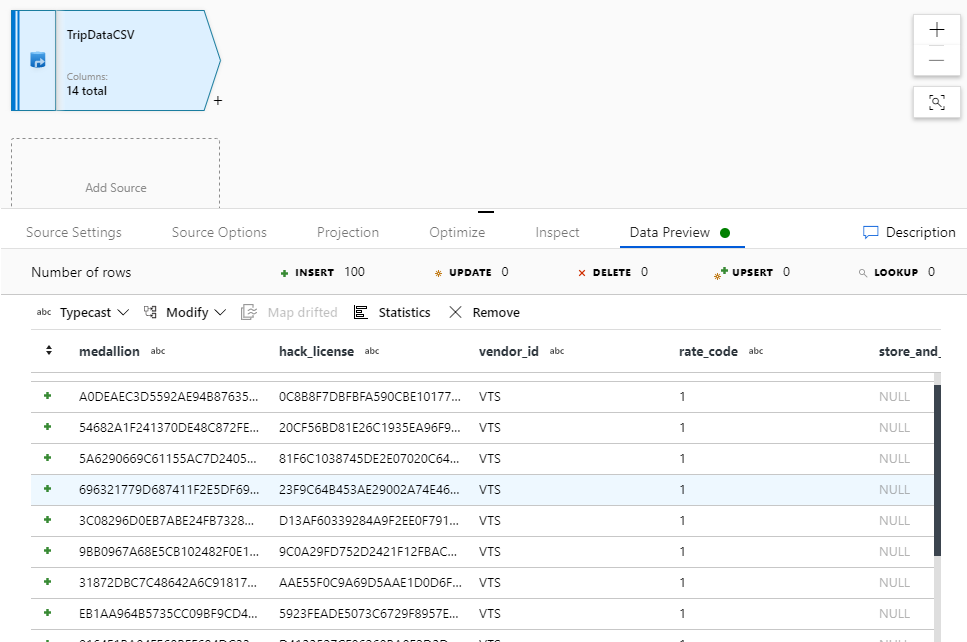


Notitie
De gegevenspreview schrijft geen gegevens.
Uw rittarieven configureren voor SQL Database-bron
De tweede bron die u toevoegt aan punten in de SQL Database-tabel
dbo.TripFares. Onder de bron 'TripDataCSV' bevindt zich nog een vak Bron toevoegen. Selecteer deze om een nieuwe brontransformatie toe te voegen.
Geef deze bron de naam 'TripFaresSQL'. Selecteer Nieuw naast het veld brongegevensset om een nieuwe SQL Database-gegevensset te maken.
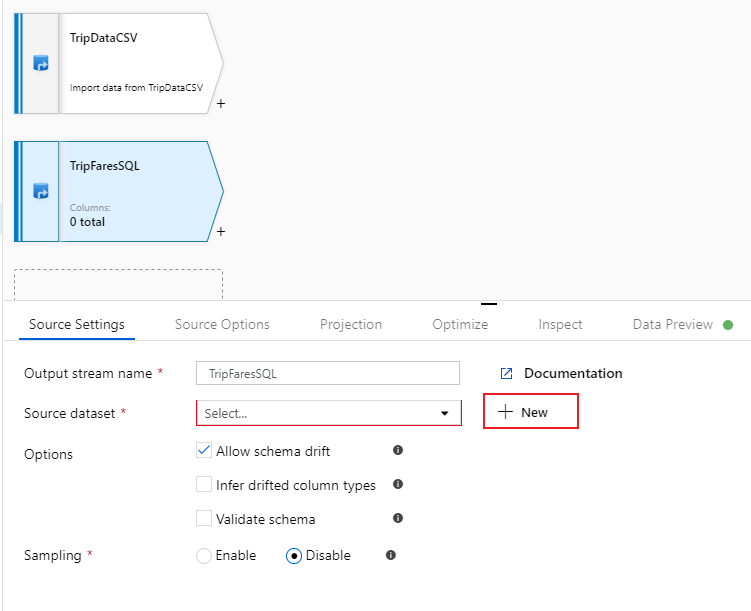
Selecteer de tegel Azure SQL Database en selecteer Doorgaan. Mogelijk ziet u dat veel van de connectors in data factory niet worden ondersteund in de toewijzingsgegevensstroom. Als u gegevens uit een van deze bronnen wilt transformeren, neemt u deze op in een ondersteunde bron met behulp van de kopieeractiviteit.

Roep de gegevensset 'TripFares' aan. Selecteer 'SQLDB' als uw gekoppelde service. Selecteer de tabelnaam in de vervolgkeuzelijst tabelnaam
dbo.TripFares. Importeer het schema Uit verbinding/archief. Wanneer u klaar bent, selecteert u OK.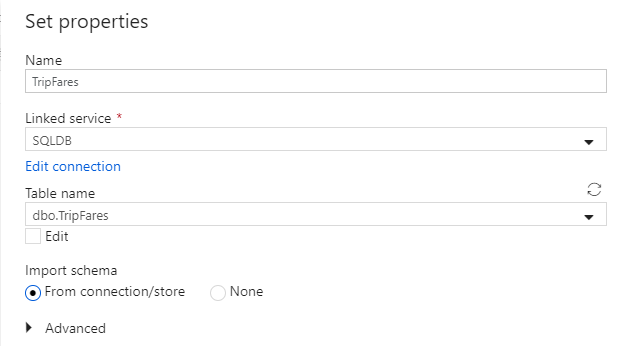
Als u uw gegevens wilt controleren, haalt u een gegevenspreview op in het tabblad Gegevenspreview.
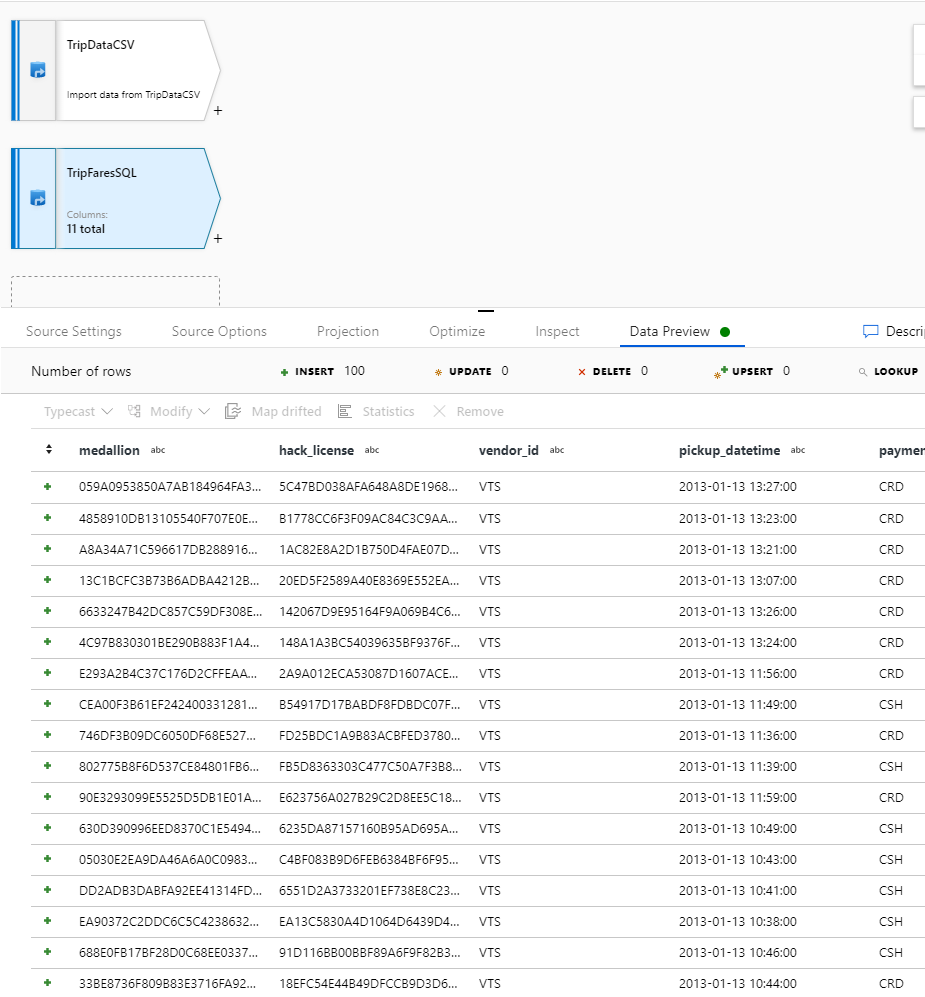

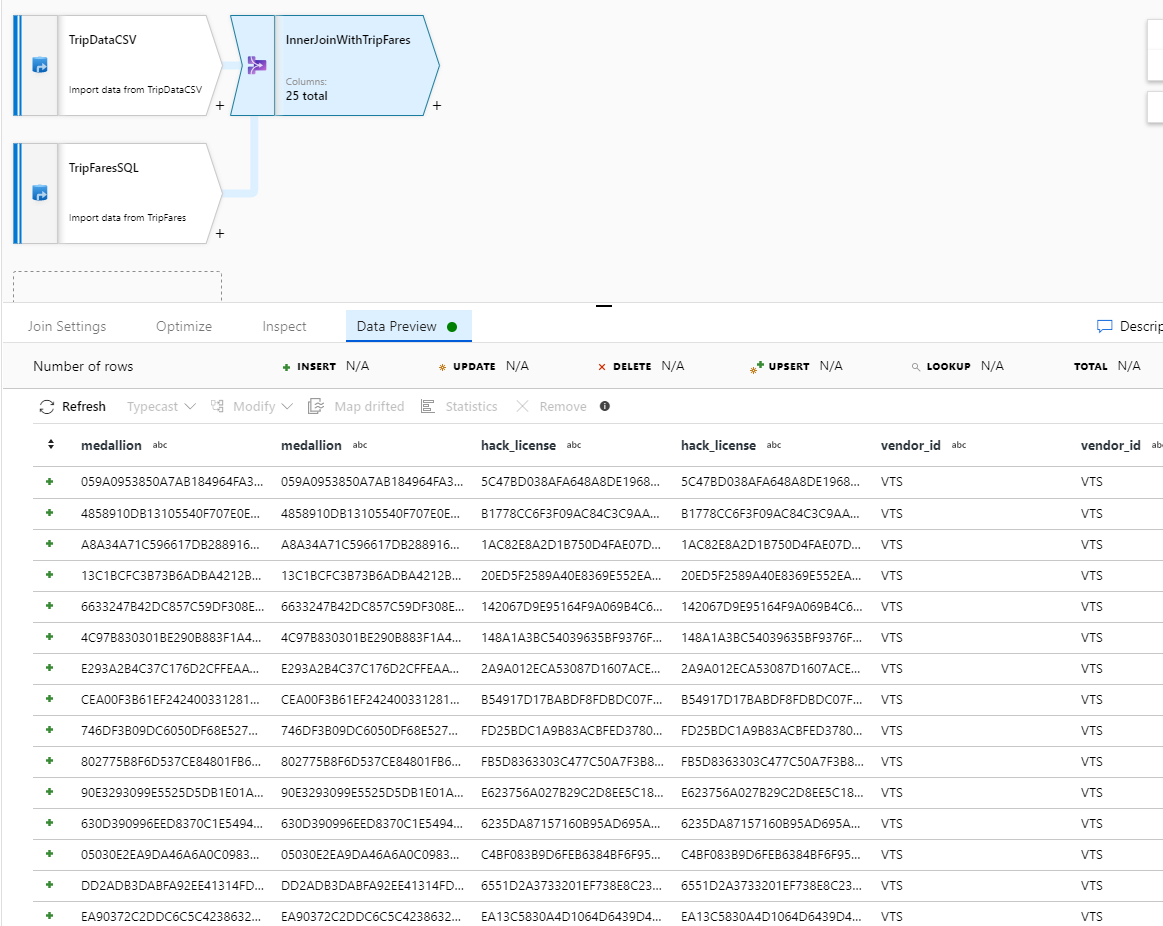
Inner join TripDataCSV en TripFaresSQL
Als u een nieuwe transformatie wilt toevoegen, selecteert u het pluspictogram in de rechterbenedenhoek van TripDataCSV. Onder Meerdere invoeren/uitvoeren selecteert u Samenvoegen.
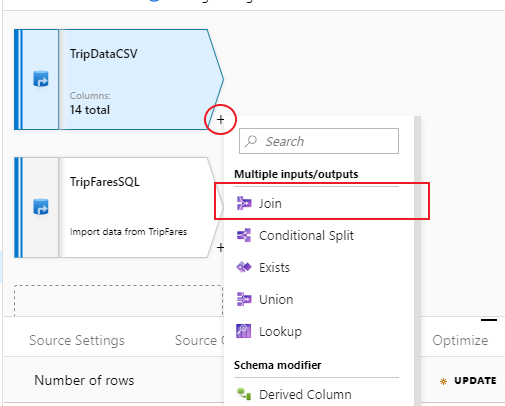
Geef uw join-transformatie de naam 'InnerJoinWithTripFares'. Selecteer TripFaresSQL in de vervolgkeuzelijst voor de juiste stroom. Selecteer Inner als join-type. Raadpleegt Join-typen voor meer informatie over de verschillende join-typen in toewijzingsgegevensstroom.
Selecteer in de vervolgkeuzelijst Joinvoorwaarden welke kolommen u wilt vergelijken vanuit elke stream. Als u een extra joinvoorwaarde wilt toevoegen, selecteert u het pluspictogram naast een bestaande voorwaarde. Standaard worden alle join-voorwaarden gecombineerd met een AND-operator, wat betekent dat aan alle voorwaarden moet worden voldaan voor een overeenkomst. In dit lab willen we overeenkomsten met kolommen
medallion,hack_license,vendor_idenpickup_datetime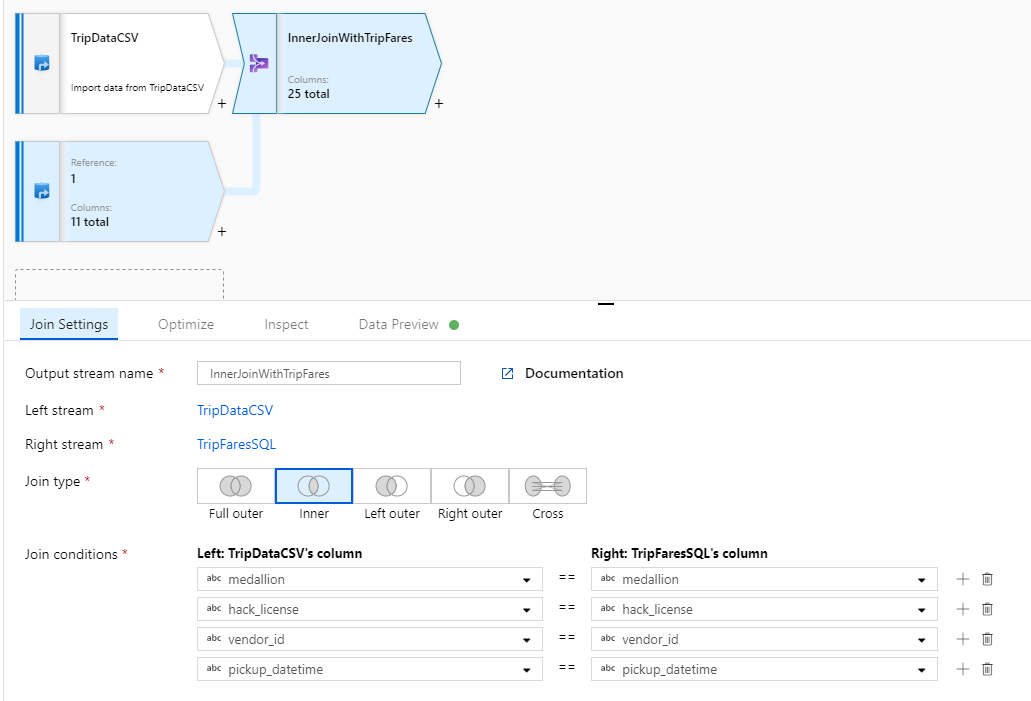
Controleer of u 25 kolommen hebt samengevoegd met een gegevenspreview.


Aggregatie per payment_type
Nadat u de jointransformatie hebt voltooid, voegt u een statistische transformatie toe door het pluspictogram naast InnerJoinWithTripFares te selecteren. Kies Aggregeren onder Schemawijzigingsfunctie.
Geef uw geaggregeerde transformatie de naam 'AggregateByPaymentType'. Selecteer
payment_typeals de kolom Groeperen op.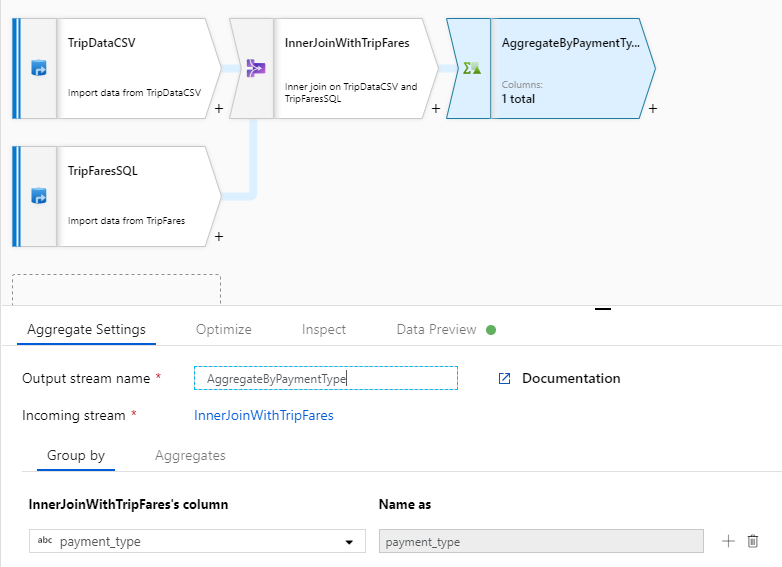
Ga naar het tabblad Aggregaties . Geef twee aggregaties op:
- De gemiddelde tarief gegroepeerd op betalingstype
- De totale reisafstand gegroepeerd op betalingstype
Eerst maakt u de expressie voor gemiddeld tarief. Voer 'average_fare' in het tekstvak Een kolom toevoegen of selecteren in.
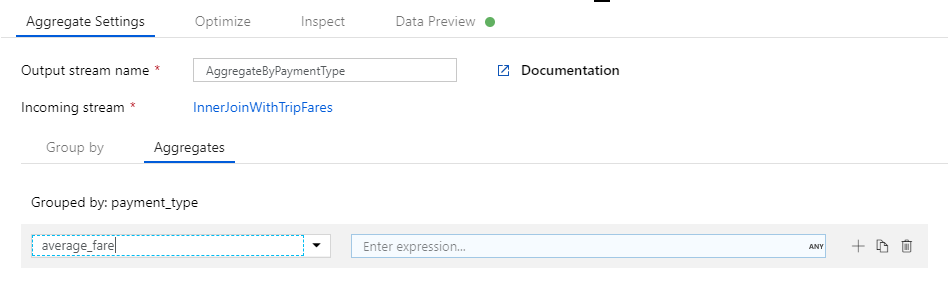
Als u een aggregatie-expressie wilt invoeren, selecteert u het blauwe vak met het label Enter-expressie, waarmee de opbouwfunctie voor gegevensstroomexpressies wordt geopend, een hulpprogramma dat wordt gebruikt om expressies voor gegevensstromen visueel te maken met behulp van invoerschema, ingebouwde functies en bewerkingen en door de gebruiker gedefinieerde parameters. Zie de Documentatie voor opbouwfunctie van expressies voor meer informatie over de mogelijkheden van de opbouwfunctie voor expressies.
Als u het gemiddelde tarief wilt ophalen, gebruikt u de
avg()aggregatiefunctie om de kolomtotal_amountte aggregeren met een geheel getal mettoInteger(). In de taal van de gegevensstroomexpressie wordt dit gedefinieerd alsavg(toInteger(total_amount)). Selecteer Opslaan en voltooien wanneer u klaar bent.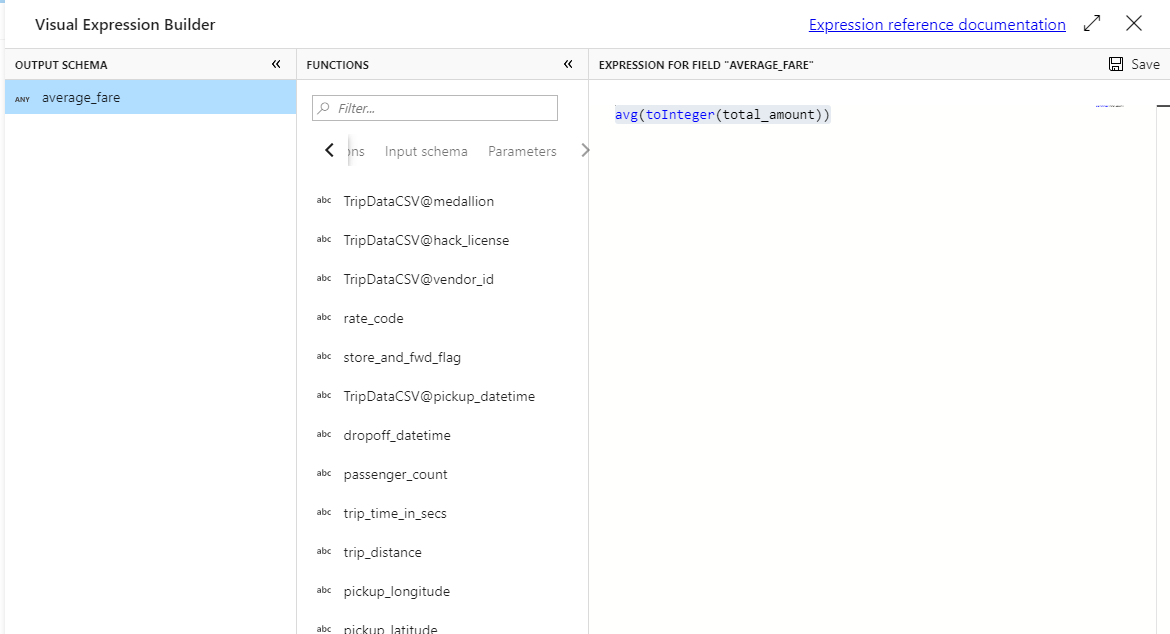
Als u een extra aggregatie-expressie wilt toevoegen, selecteert u het pluspictogram naast
average_fare. Selecteer Kolom toevoegen.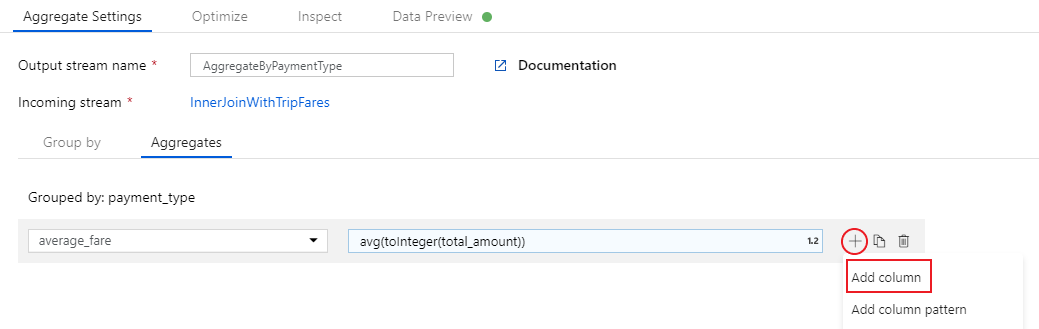
Voer 'total_trip_distance' in het tekstvak Een kolom toevoegen of selecteren in. Open zoals in de laatste stap de opbouwfunctie voor expressies om de expressie in te voeren.
Als u de totale reisafstand wilt ophalen, gebruikt u de
sum()aggregatiefunctie om de kolomtrip_distancete aggregeren met een geheel getal mettoInteger(). In de taal van de gegevensstroomexpressie wordt dit gedefinieerd alssum(toInteger(trip_distance)). Selecteer Opslaan en voltooien wanneer u klaar bent.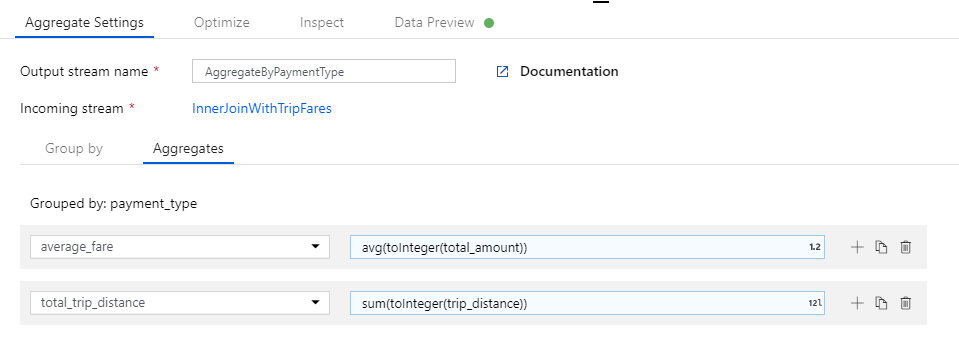
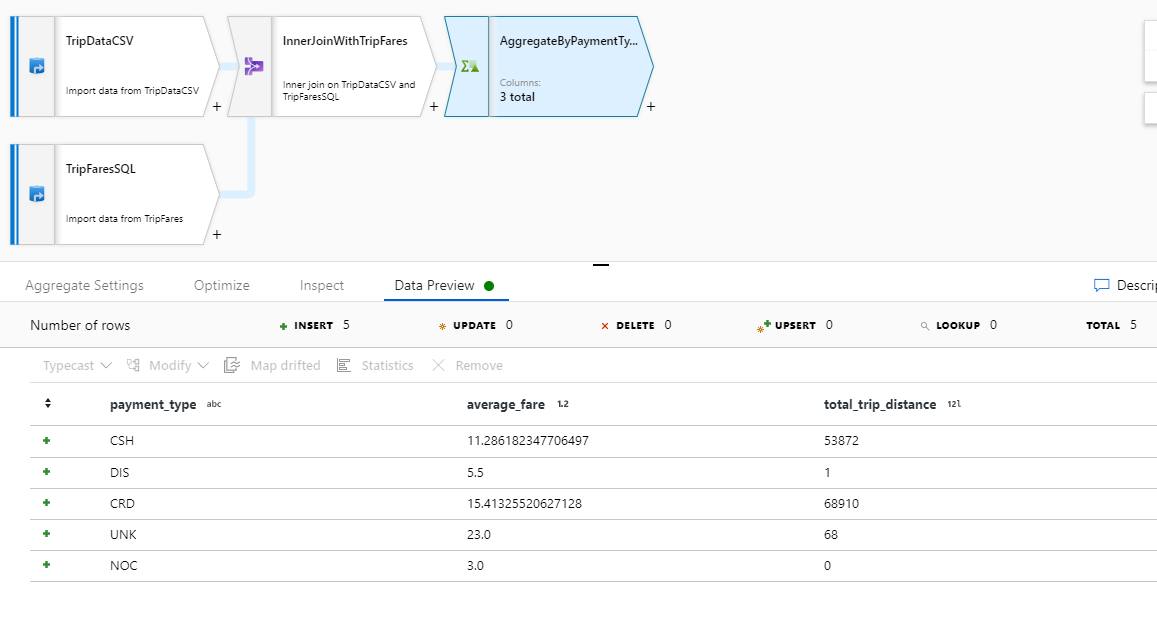
Test uw transformatielogica op het tabblad Gegevensvoorbeeld . Zoals u kunt zien, zijn er aanzienlijk minder rijen en kolommen dan eerder. Alleen de drie kolommen voor groeperen op en aggregatie die in deze transformatie zijn gedefinieerd, gaan verder. Aangezien het voorbeeld slechts vijf groepen betalingstypen bevat, worden er slechts vijf rijen gegenereerd.





Uw Azure Synapse Analytics-sink configureren
Nu we onze transformatielogica hebben voltooid, kunnen we onze gegevens in een Azure Synapse Analytics-tabel opvangen. Voeg een sink-transformatie toe in het gedeelte Bestemming.
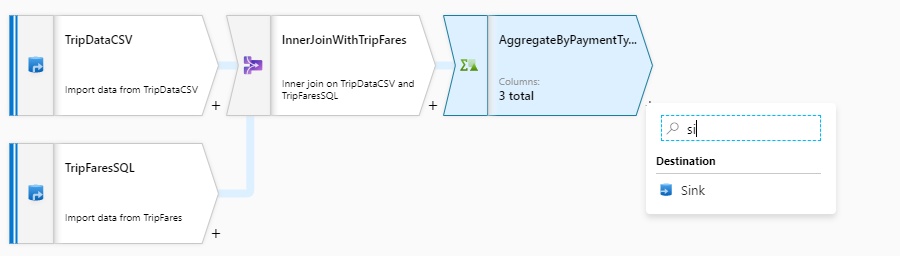
Geef uw sink de naam 'SQLDWSink'. Selecteer Nieuw naast het veld sinkgegevensset om een nieuwe Azure Synapse Analytics-gegevensset te maken.
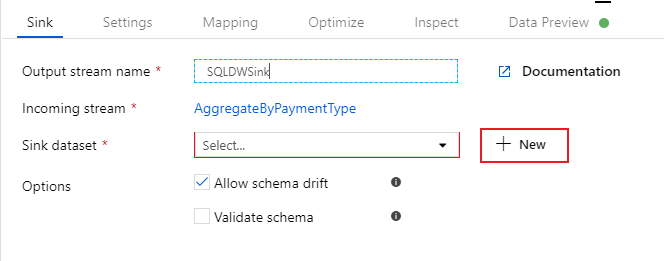
Selecteer de tegel Azure Synapse Analytics en selecteer Doorgaan.
Roep de gegevensset 'AggregatedTaxiData' aan. Selecteer 'SQLDW' als uw gekoppelde service. Selecteer Nieuwe tabel maken en geef de nieuwe tabel
dbo.AggregateTaxiDataeen naam. Wanneer u klaar bent, selecteert u OK.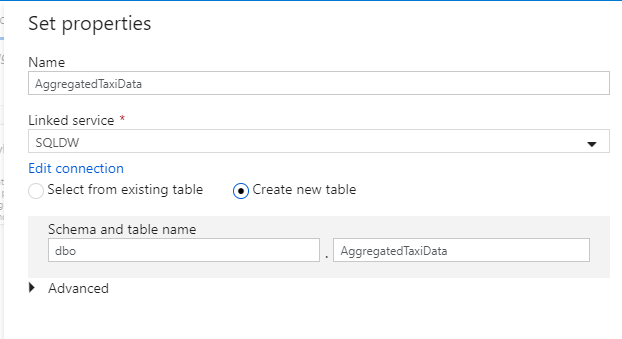
Ga naar het tabblad Instellingen van de sink. Omdat we een nieuwe tabel maken, moeten we Tabel opnieuw maken selecteren onder tabelactie. Schakel het selectievakje Fasering inschakelen uit om te schakelen tussen rij per rij of in batch invoeren.
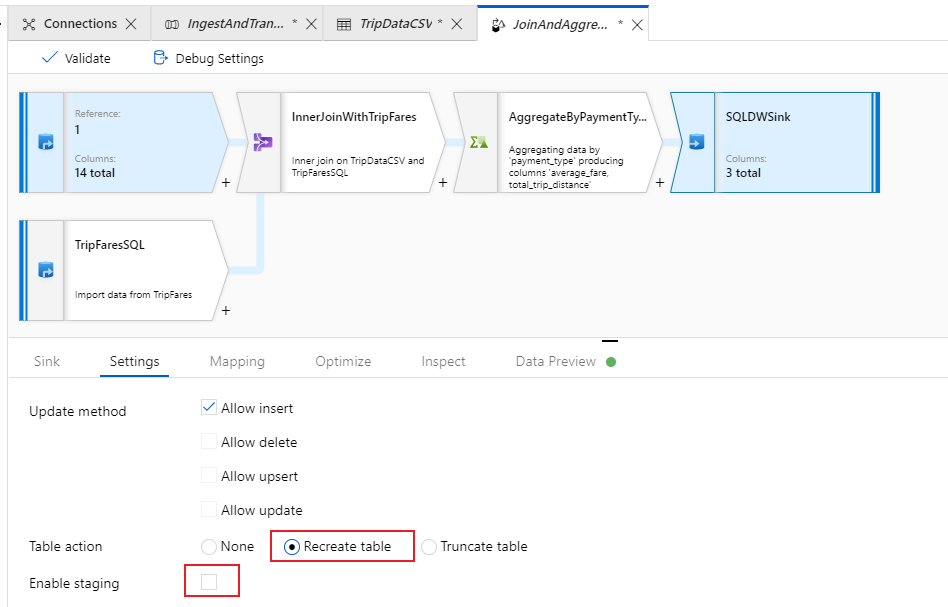


U hebt uw gegevensstroom gemaakt. Nu is het tijd om deze uit te voeren in een pijplijnactiviteit.
End-to-end-foutopsporing voor uw pijplijn
Ga terug naar het tabblad voor de pijplijn IngestAndTransformData. U ziet een groen vakje op de kopieeractiviteit 'IngestIntoADLS'. Sleep het naar de gegevensstroomactiviteit 'JoinAndAggregateData'. Hiermee maakt u een 'bij gelukt', waardoor de gegevensstroomactiviteit alleen wordt uitgevoerd als de kopie is geslaagd.
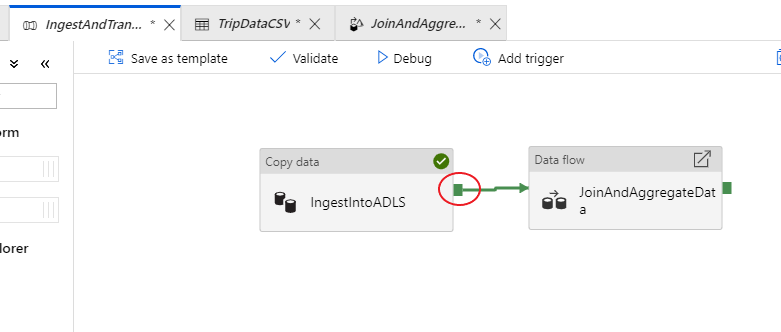
Net als voor de kopieeractiviteit selecteert u Debug om een foutopsporingsuitvoering uit te voeren. Voor foutopsporingsuitvoeringen gebruikt de gegevensstroomactiviteit het actieve foutopsporingscluster in plaats van een nieuw cluster in te stellen. Het uitvoeren van deze pijplijn duurt iets langer dan een minuut.
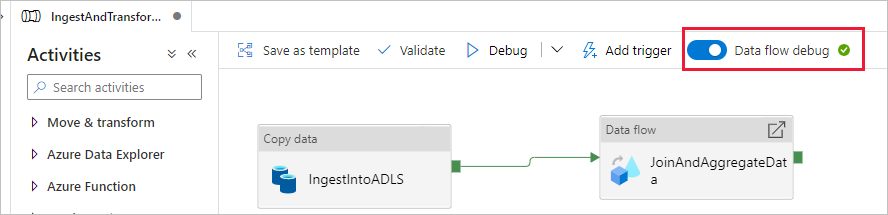
Net als bij de kopieeractiviteit heeft de gegevensstroom een speciale controleweergave die na voltooiing van de activiteit via het brilpictogram kan worden geopend.
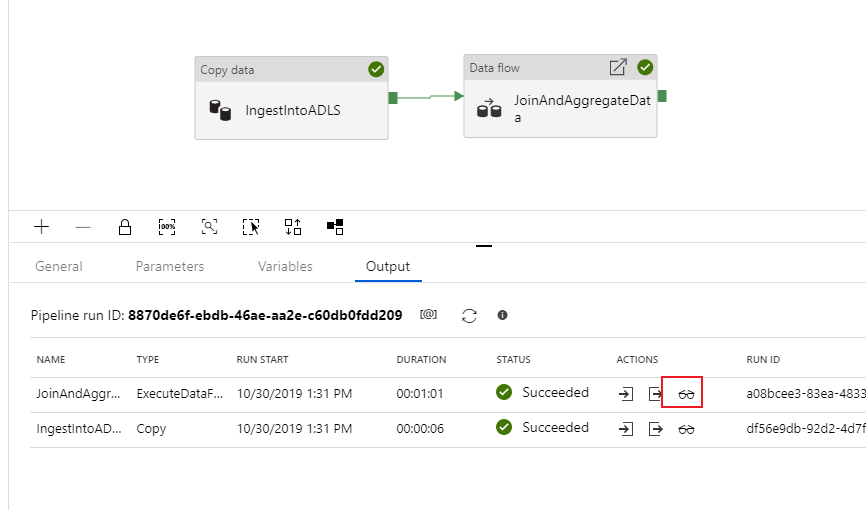
In de controleweergave kunt u een vereenvoudigde gegevensstroomgrafiek bekijken, samen met de uitvoeringstijden en rijen bij elke uitvoeringsfase. Als alles goed is uitgevoerd, hebt u 49.999 rijen samengevoegd tot vijf rijen in deze activiteit.
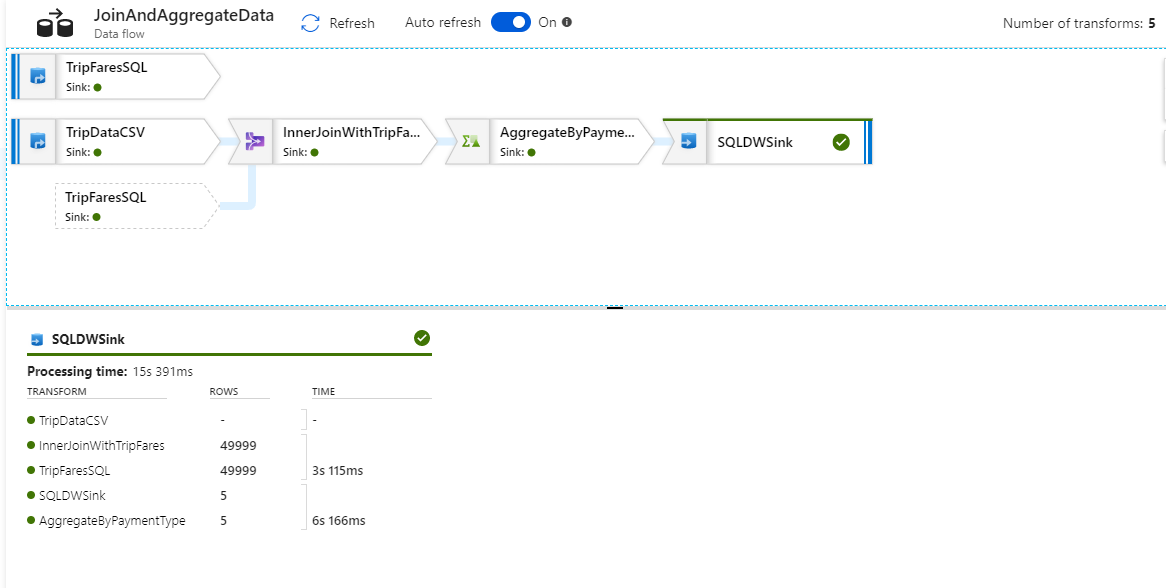
U kunt een transformatie selecteren om aanvullende informatie te krijgen over de uitvoering, zoals partitioneringsgegevens en nieuwe/bijgewerkte/verwijderde kolommen.
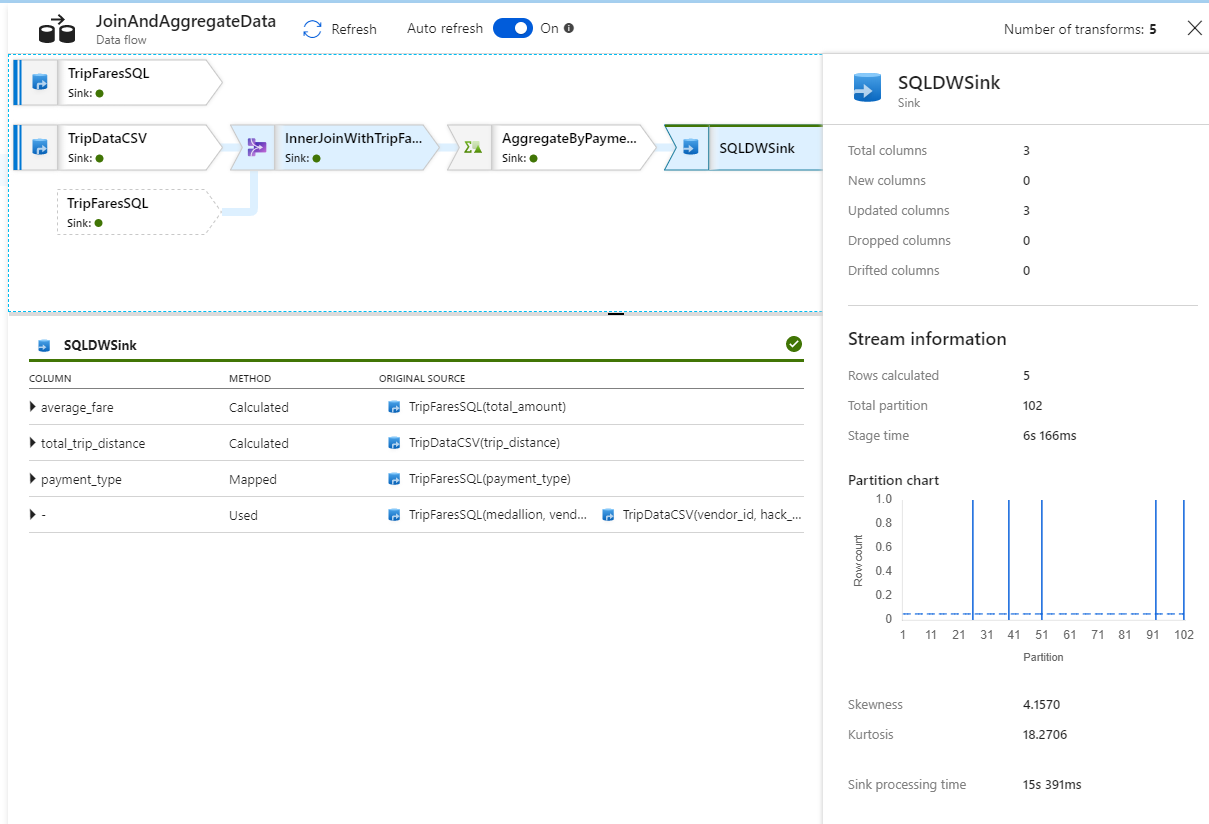




U hebt nu het gedeelte data factory van dit lab voltooid. Publiceer uw resources als u deze wilt uitvoeren met triggers. U hebt een pijplijn uitgevoerd die gegevens van Azure SQL Database heeft opgenomen naar Azure Data Lake Storage met behulp van de kopieeractiviteit en vervolgens hebt u deze gegevens samengevoegd in een Azure Synapse Analytics. U kunt controleren of de gegevens zijn geschreven door de SQL Server zelf te bekijken.
Gegevens delen met Azure Data Share
In deze sectie leert u hoe u een nieuwe gegevensshare instelt met behulp van Azure Portal. Dit omvat het maken van een nieuwe gegevensshare die gegevenssets uit Azure Data Lake Storage Gen2 en Azure Synapse Analytics bevat. Vervolgens configureert u een schema voor momentopnamen, zodat de gegevensgebruikers een optie hebben om de gegevens die met hen worden gedeeld automatisch te vernieuwen. Vervolgens nodigt u ontvangers uit voor uw gegevensshare.
Zodra u een gegevensshare hebt gemaakt, schakelt u over van rol en wordt u de gegevensgebruiker. Als gegevensgebruiker loopt u door de stroom van het accepteren van een gegevensshare-uitnodiging, het configureren van de locatie waar de gegevens moeten worden ontvangen en het toewijzen van gegevenssets aan verschillende opslaglocaties. Vervolgens activeert u een momentopname, waarmee de gegevens die met u worden gedeeld, worden gekopieerd naar de opgegeven bestemming.
Gegevens delen (gegevensproviderstroom)
Open de Azure-portal in Microsoft Edge of Google Chrome.
Zoek op Gegevensshares in de zoekbalk bovenaan de pagina
Selecteer het gegevensshare-account met 'Provider' in de naam. Bijvoorbeeld DataProvider0102.
Selecteer Beginnen met het delen van uw gegevens
Selecteer +Maken om te beginnen met het configureren van de nieuwe gegevensshare.
Geef een gewenste naam op onder Sharenaam. Dit is de sharenaam die wordt weergegeven aan uw gegevensgebruiker. Zorg er dus voor dat u een beschrijvende naam opgeeft, zoals TaxiData.
Onder Beschrijving voert u een zin in waarmee de inhoud van de gegevensshare wordt beschreven. De gegevensshare bevat wereldwijde taxiritgegevens die zijn opgeslagen in verschillende winkels, waaronder Azure Synapse Analytics en Azure Data Lake Storage.
Geef onder Gebruiksvoorwaarden een set voorwaarden op waaraan uw gegevensgebruiker moet voldoen. Enkele voorbeelden zijn 'Deze gegevens niet distribueren buiten uw organisatie' of 'Raadpleeg de juridische overeenkomst'.
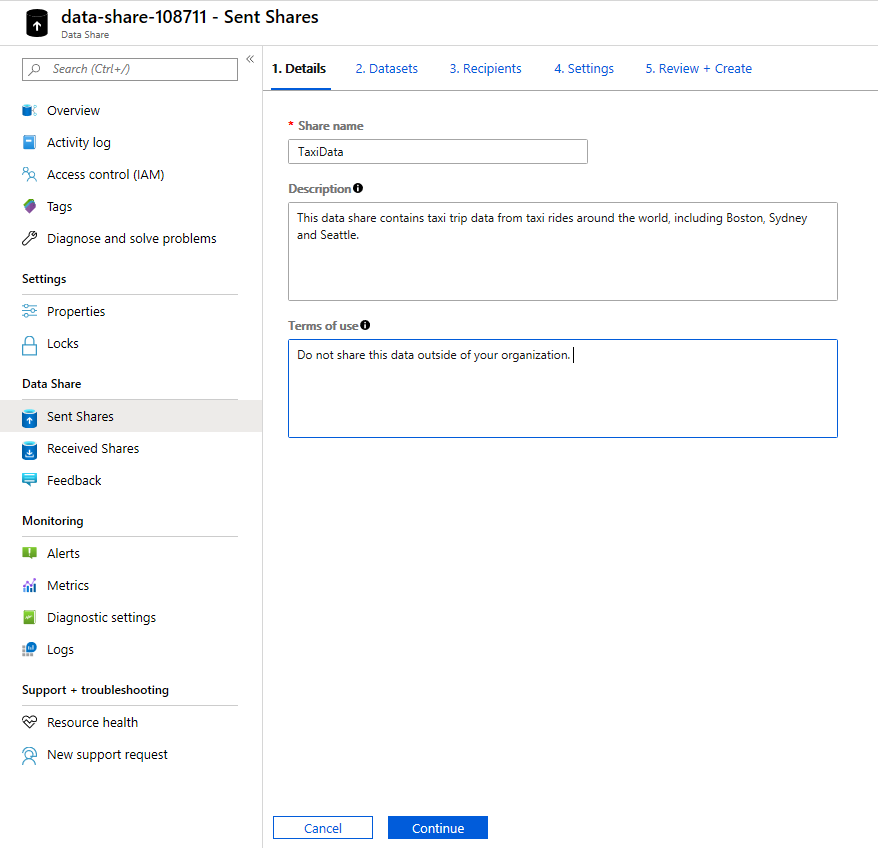
Selecteer Doorgaan.
Selecteer Gegevenssets toevoegen
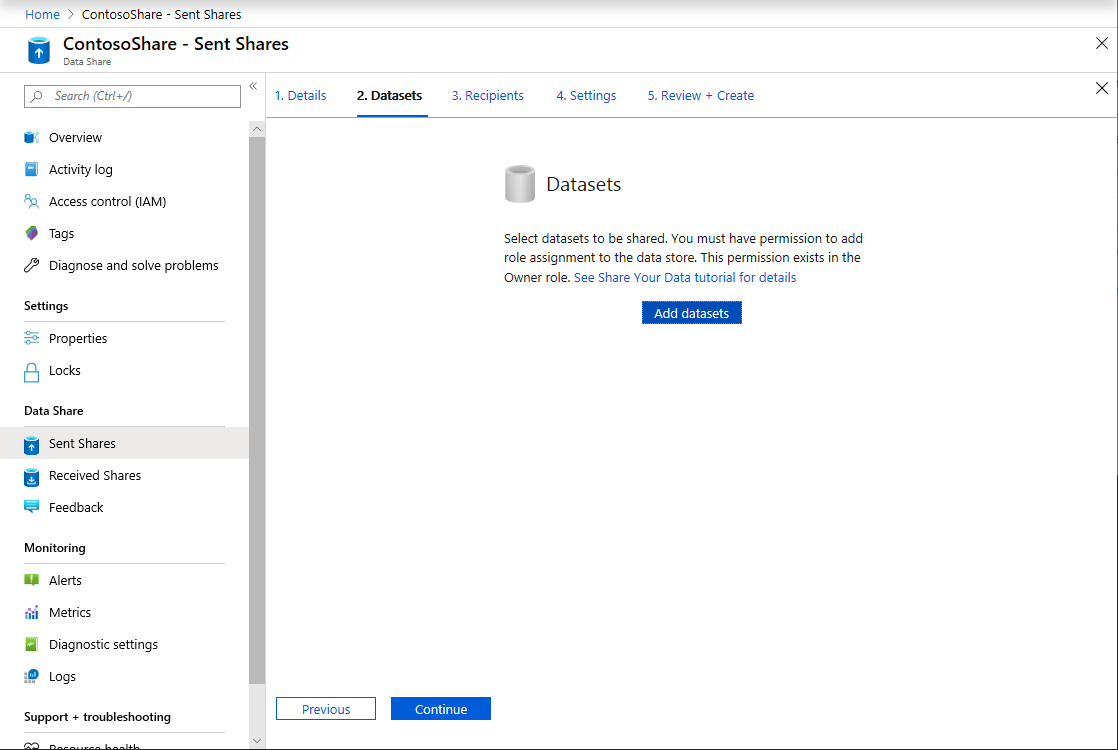
Selecteer Azure Synapse Analytics om een tabel te selecteren uit Azure Synapse Analytics waarin uw ADF-transformaties terecht zijn gekomen.
U krijgt een script dat moet worden uitgevoerd voordat u verder kunt gaan. Met het geboden script wordt een gebruiker gemaakt in de SQL-database zodat de Azure Data Share MSI kan verifiëren namens de gebruiker.
Belangrijk
Voordat u het script uitvoert, moet u uzelf instellen als de Active Directory-Beheer voor de logische SQL-server van de Azure SQL Database.
Open een nieuw tabblad en ga naar de Azure-portal. Kopieer het geleverde script om een gebruiker te maken in de database waarvan u gegevens wilt delen. Doe dit door u aan te melden bij de EDW-database met behulp van de Query-editor van Azure Portal, met behulp van Microsoft Entra-verificatie. U moet de gebruiker wijzigen in het volgende voorbeeldscript:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Ga terug naar de Azure Data Share waar u gegevenssets aan uw gegevensshare hebt toegevoegd.
Selecteer EDW en selecteer vervolgens AggregatedTaxiData voor de tabel.
Selecteer Gegevensset toevoegen
We hebben nu een SQL-tabel die deel uitmaakt van de gegevensset. Vervolgens voegen we extra gegevenssets toe vanuit Azure Data Lake Storage.
Selecteer Gegevensset toevoegen en Selecteer Azure Data Lake Storage Gen2
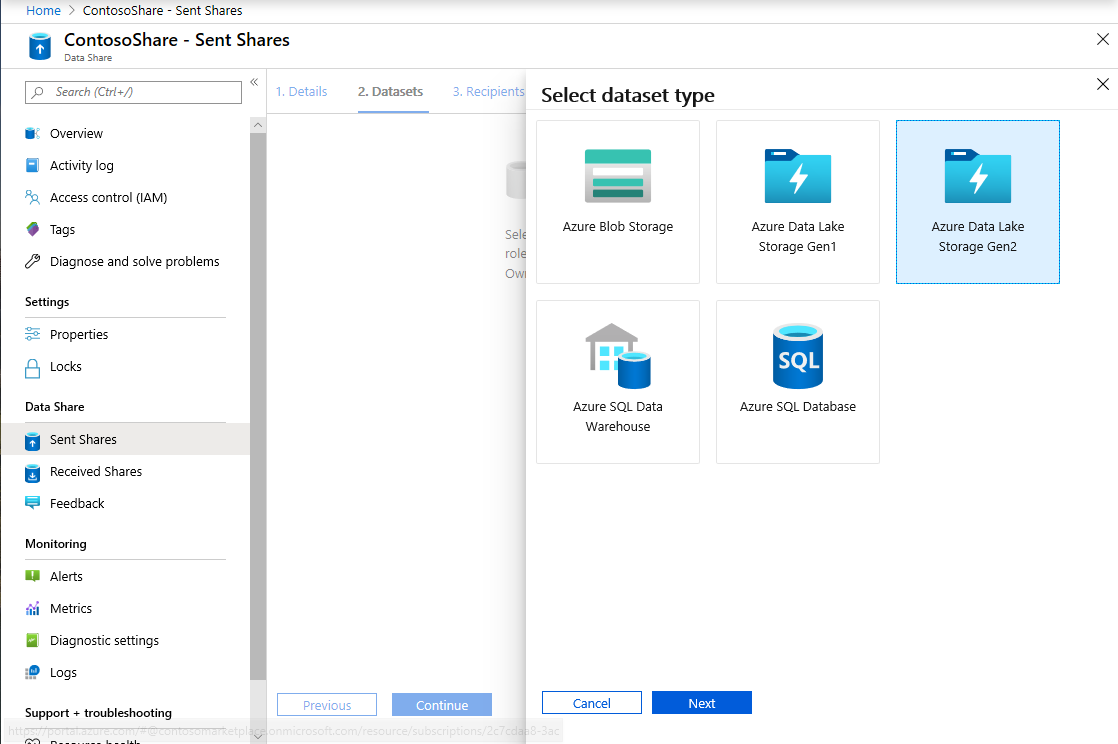
Selecteer Volgende
Vouw wwtaxidata uit. Vouw Boston-taxigegevens uit. U kunt het bestandsniveau omlaag delen.
Selecteer de map Boston-taxigegevens om de volledige map toe te voegen aan uw gegevensshare.
Selecteer Gegevenssets toevoegen
Controleer de gegevenssets die zijn toegevoegd. U moet een SQL-tabel en een ADLS Gen2-map aan uw gegevensshare hebben toegevoegd.
Selecteer Doorgaan
In dit scherm kunt u ontvangers toevoegen aan uw gegevensshare. De ontvangers die u toevoegt, ontvangen uitnodigingen voor uw gegevensshare. Voor dit lab moet u twee e-mailadressen toevoegen:
Het e-mailadres van het Azure-abonnement dat u gebruikt.
Voeg de fictieve gegevensgebruiker met de naam janedoe@fabrikam.comtoe.
In dit scherm kunt u een momentopname-instelling voor uw gegevensgebruiker configureren. Hierdoor kunnen ze regelmatig updates van uw gegevens ontvangen met een interval dat door u is gedefinieerd.
Controleer het schema voor momentopnamen en configureer een uurlijks vernieuwen van uw gegevens met behulp van de vervolgkeuzelijst Terugkeerpatroon .
Selecteer Maken.
U hebt nu een actieve gegevensshare. Hiermee kunt u zien wat u ziet als een gegevensprovider wanneer u een gegevensshare maakt.
Selecteer de gegevensshare die u hebt gemaakt met de naam DataProvider. U kunt hiernaar navigeren door Verzonden shares te selecteren in Gegevensshare.
Selecteer op schema voor momentopnamen. U kunt indien gewenst het schema voor momentopnamen uitschakelen.
Selecteer vervolgens het tabblad Gegevenssets . U kunt extra gegevenssets toevoegen aan deze gegevensshare nadat deze is gemaakt.
Selecteer het tabblad Abonnementen delen . Er zijn nog geen shareabonnementen omdat uw gegevensgebruiker uw uitnodiging nog niet heeft geaccepteerd.
Ga naar het tabblad Uitnodigingen . Hier ziet u een lijst met uitnodigingen die in behandeling zijn.
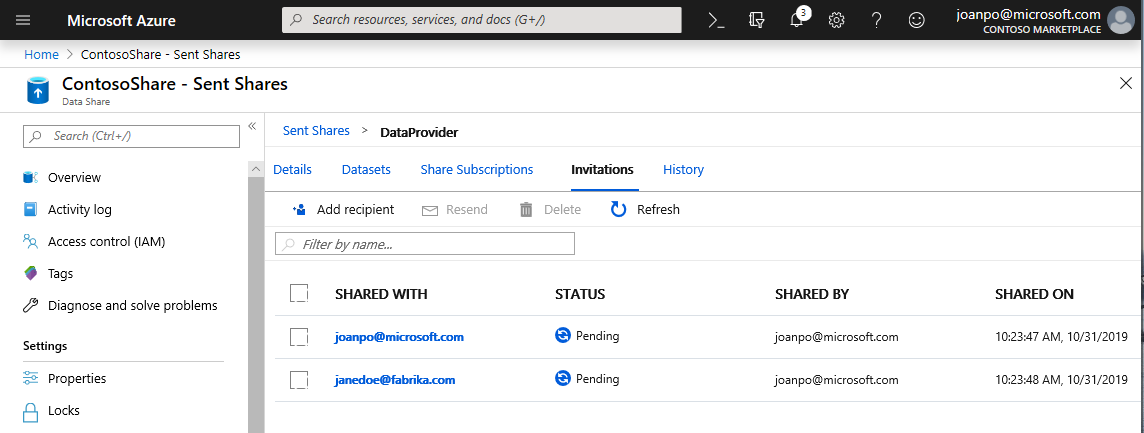
Selecteer de uitnodiging voor janedoe@fabrikam.com. Selecteer Verwijderen. Als uw ontvanger de uitnodiging nog niet heeft geaccepteerd, kan hij of zij dat ook niet meer doen.
Selecteer het tabblad Geschiedenis . Er wordt nog niets weergegeven omdat uw gegevensgebruiker uw uitnodiging nog niet heeft geaccepteerd en een momentopname heeft geactiveerd.






Gegevens ontvangen (gegevensverbruikerstroom)
Nu we onze gegevensshare hebben bekeken, zijn we klaar voor een andere context en te schakelen naar de rol van gegevensgebruiker.
U hebt nu een uitnodiging voor een Azure Data Share in uw postvak in ontvangen van Microsoft Azure. Start Outlook Web Access (outlook.com) en meld u aan met de referenties die zijn opgegeven voor uw Azure-abonnement.
Selecteer in het e-mailbericht dat u had moeten ontvangen de optie 'Uitnodiging weergeven >'. Op dit moment gaat u de ervaring van de gegevensgebruiker simuleren wanneer u een uitnodiging van gegevensprovider voor zijn of haar gegevensshare accepteert.

Mogelijk wordt u gevraagd om een abonnement te selecteren. Zorg ervoor dat u het abonnement selecteert waarmee u werkt voor dit lab.
Selecteer de uitnodiging met de titel DataProvider.
In dit uitnodigingsscherm ziet u verschillende details over de gegevensshare die u eerder hebt geconfigureerd als gegevensprovider. Bekijk de details en accepteer de gebruiksrechtsvoorwaarden indien van toepassing.
Selecteer het Abonnement en de Resourcegroep die al bestaan voor uw lab.
Voor Gegevensshare-account selecteert u DataConsumer. U kunt ook een nieuwe gegevensshare-account maken.
Naast de naam van ontvangen share ziet u dat de standaardsharenaam de naam is die is opgegeven door de gegevensprovider. Geef de share een beschrijvende naam die de gegevens beschrijft die u op het punt staat te ontvangen, bijvoorbeeld TaxiDataShare.
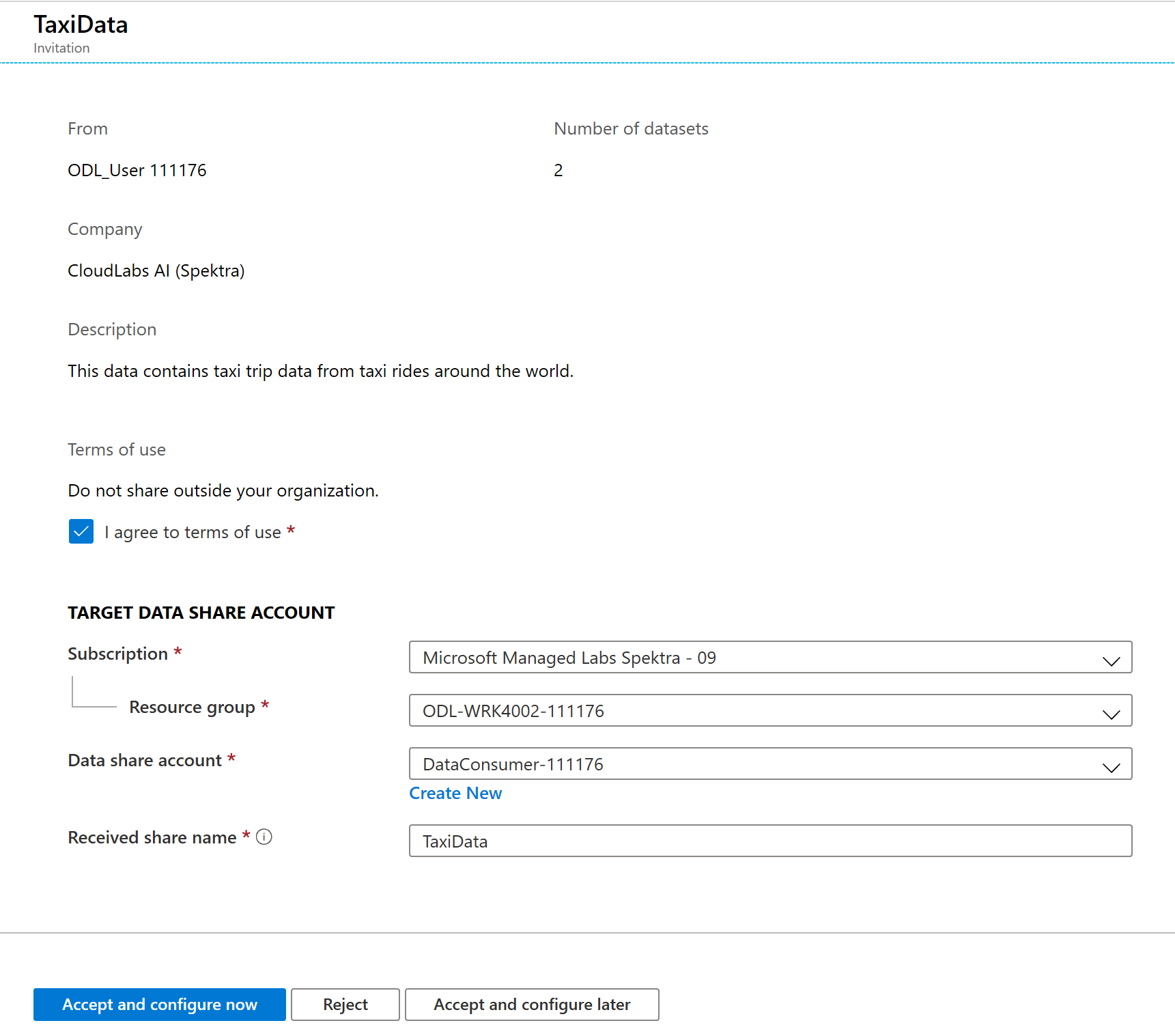
U kunt kiezen voor Nu accepteren en configureren of Later accepteren en configureren. Als u ervoor kiest om nu te accepteren en te configureren, geeft u een opslagaccount op waarin alle gegevens moeten worden gekopieerd. Als u ervoor kiest om later te accepteren en te configureren, worden de gegevenssets in de share niet toegewezen en moet u ze handmatig toewijzen. We zullen hier later voor kiezen.
Selecteer Later accepteren en configureren.
Wanneer u deze optie configureert, wordt er een shareabonnement gemaakt, maar is er nergens waar de gegevens terechtkomen omdat er geen bestemming is toegewezen.
Configureer vervolgens gegevenssettoewijzingen voor de gegevensshare.
Selecteer de Ontvangen share (de naam die u in stap 5 hebt opgegeven).
Trigger voor momentopname wordt grijs weergegeven, maar de share is actief.
Selecteer het tabblad Gegevenssets . Elke gegevensset is niet toegewezen, wat betekent dat er geen bestemming is om gegevens naar te kopiëren.
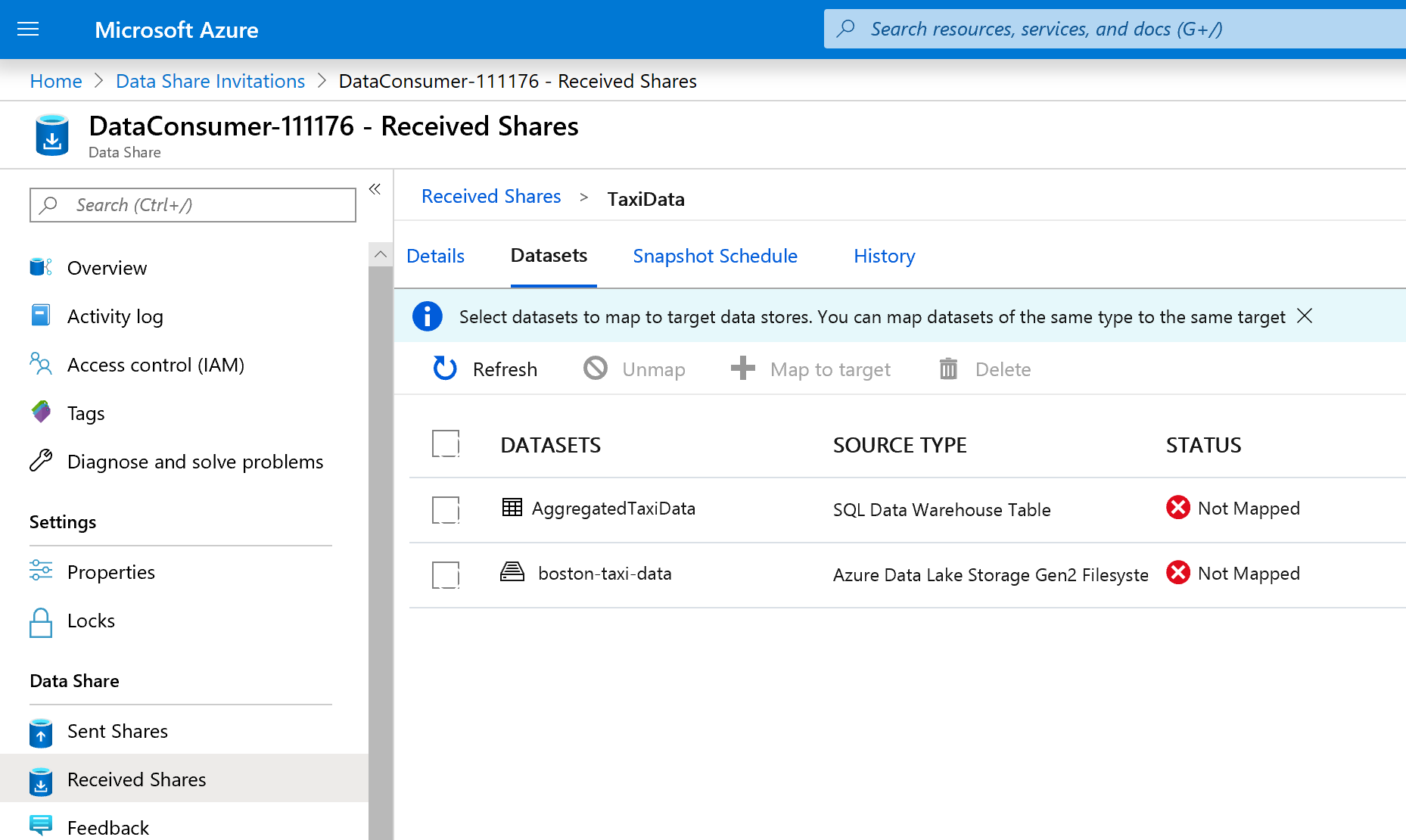
Selecteer de Azure Synapse Analytics-tabel en selecteer vervolgens +Toewijzen aan doel.
Selecteer aan de rechterkant van het scherm de vervolgkeuzelijst Doelgegevenstype .
U kunt de SQL-gegevens toewijzen aan een breed scala aan gegevensarchieven. In dit geval wijzen we toe aan een Azure SQL Database.
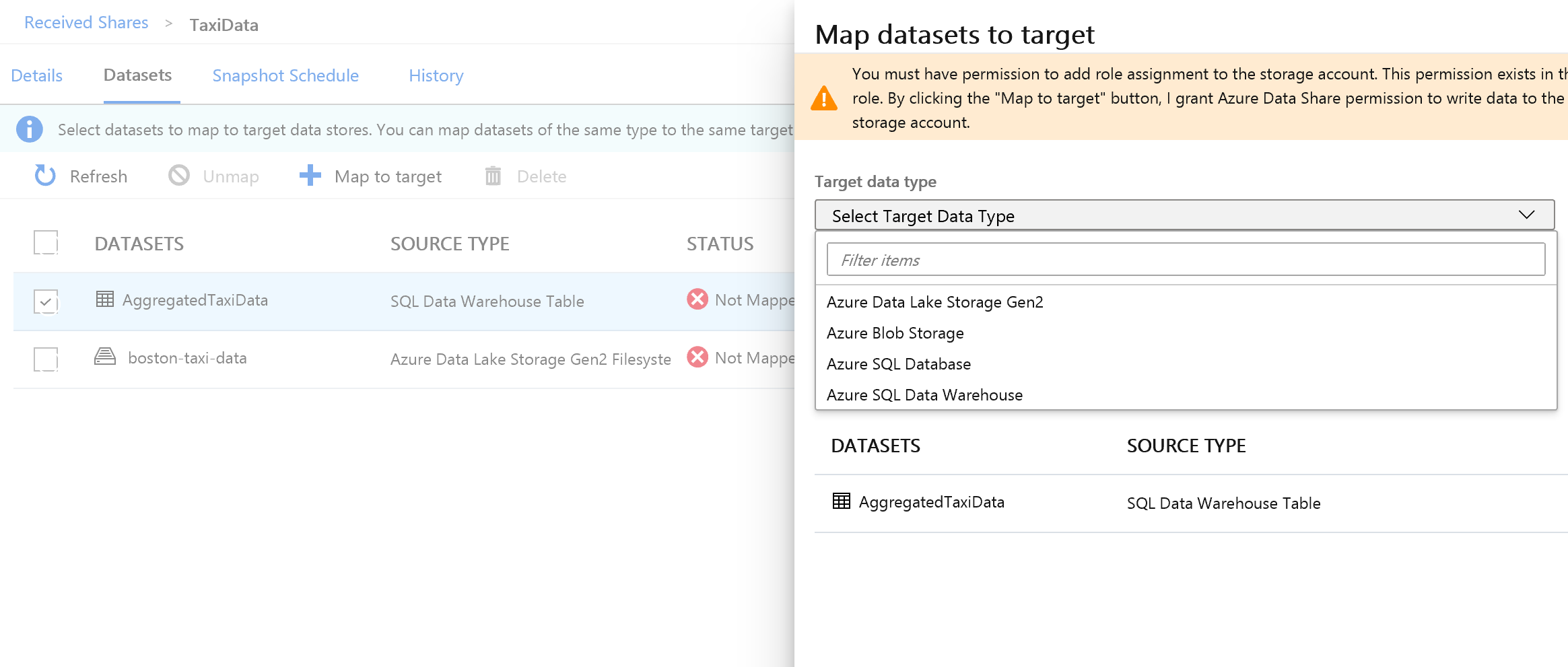
(Optioneel) Selecteer Azure Data Lake Storage Gen2 als het doelgegevenstype.
(Optioneel) Selecteer het abonnement, de resourcegroep en het opslagaccount waarin u werkt.
(Optioneel) U kunt ervoor kiezen om de gegevens in uw data lake te ontvangen in de CSV- of Parquet-indeling.
Selecteer Azure SQL Database naast Doelgegevenstype.
Selecteer het abonnement, de resourcegroep en het opslagaccount waarin u werkt.
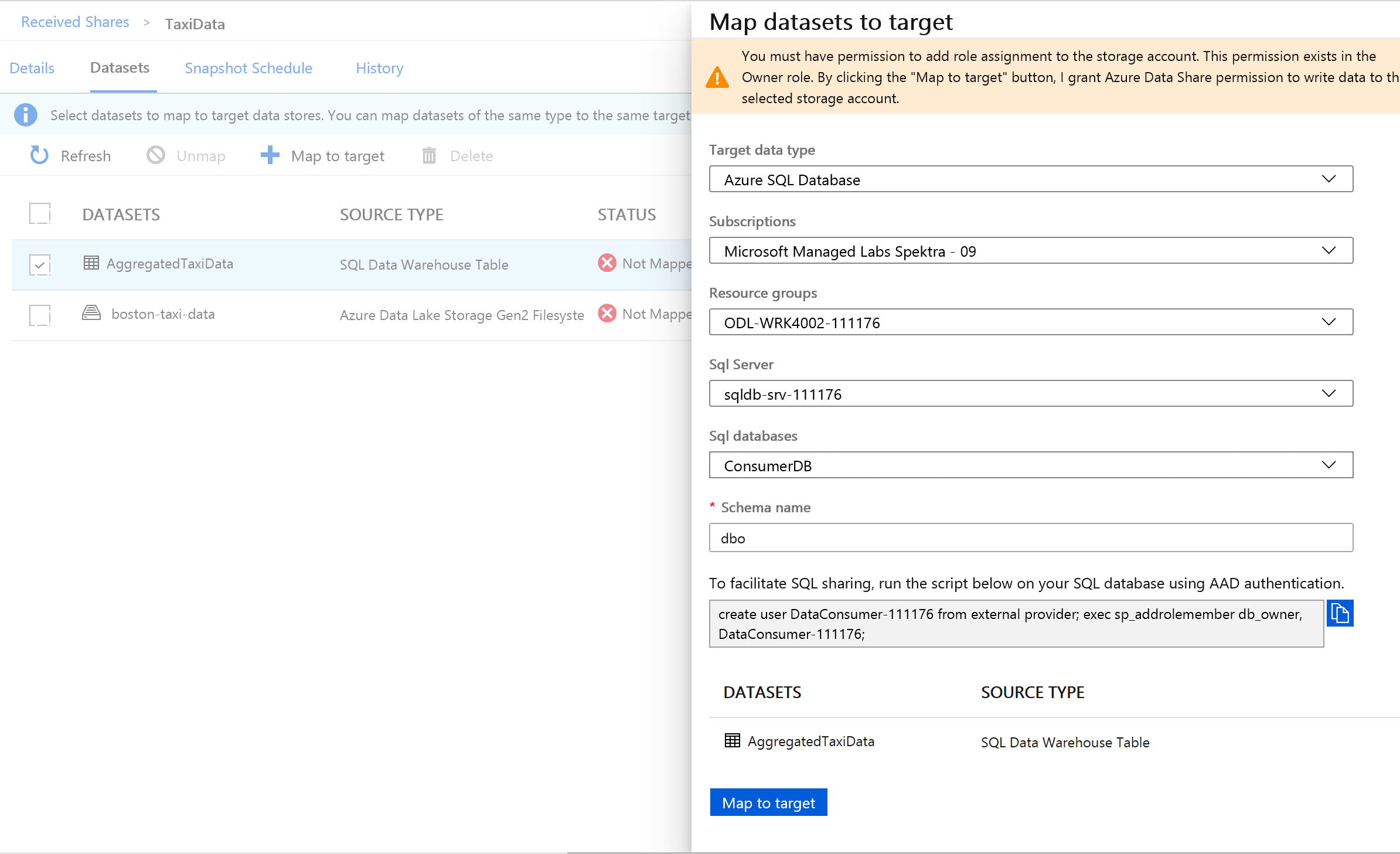
Voordat u kunt doorgaan, moet u een nieuwe gebruiker maken in de SQL Server door het geleverde script uit te voeren. Kopieer eerst het geleverde script naar het klembord.
Open een nieuw azure-portaltabblad. Sluit het bestaande tabblad niet, want u moet er even naar terugkeren.
Ga in het nieuwe tabblad dat u hebt geopend naar SQL-databases.
Selecteer de SQL-database (er mag er zich slechts één in uw abonnement bevinden). Pas op dat u de datawarehouse niet selecteert.
Selecteer Query-editor (preview)
Gebruik Microsoft Entra-verificatie om u aan te melden bij de Query-editor.
Voer de query uit die wordt geboden in de gegevensshare (gekopieerd naar het klembord in stap 14).
Met deze opdracht geeft u de Azure Data Share-service de mogelijkheid om beheerde identiteiten te gebruiken voor Azure-Services om te verifiëren of de SQL Server gegevens kan kopiëren.
Ga terug naar het oorspronkelijke tabblad en selecteer Toewijzen aan doel.
Selecteer vervolgens de Map Azure Data Lake Storage Gen2 die deel uitmaakt van de gegevensset en wijs deze toe aan een Azure Blob Storage-account.
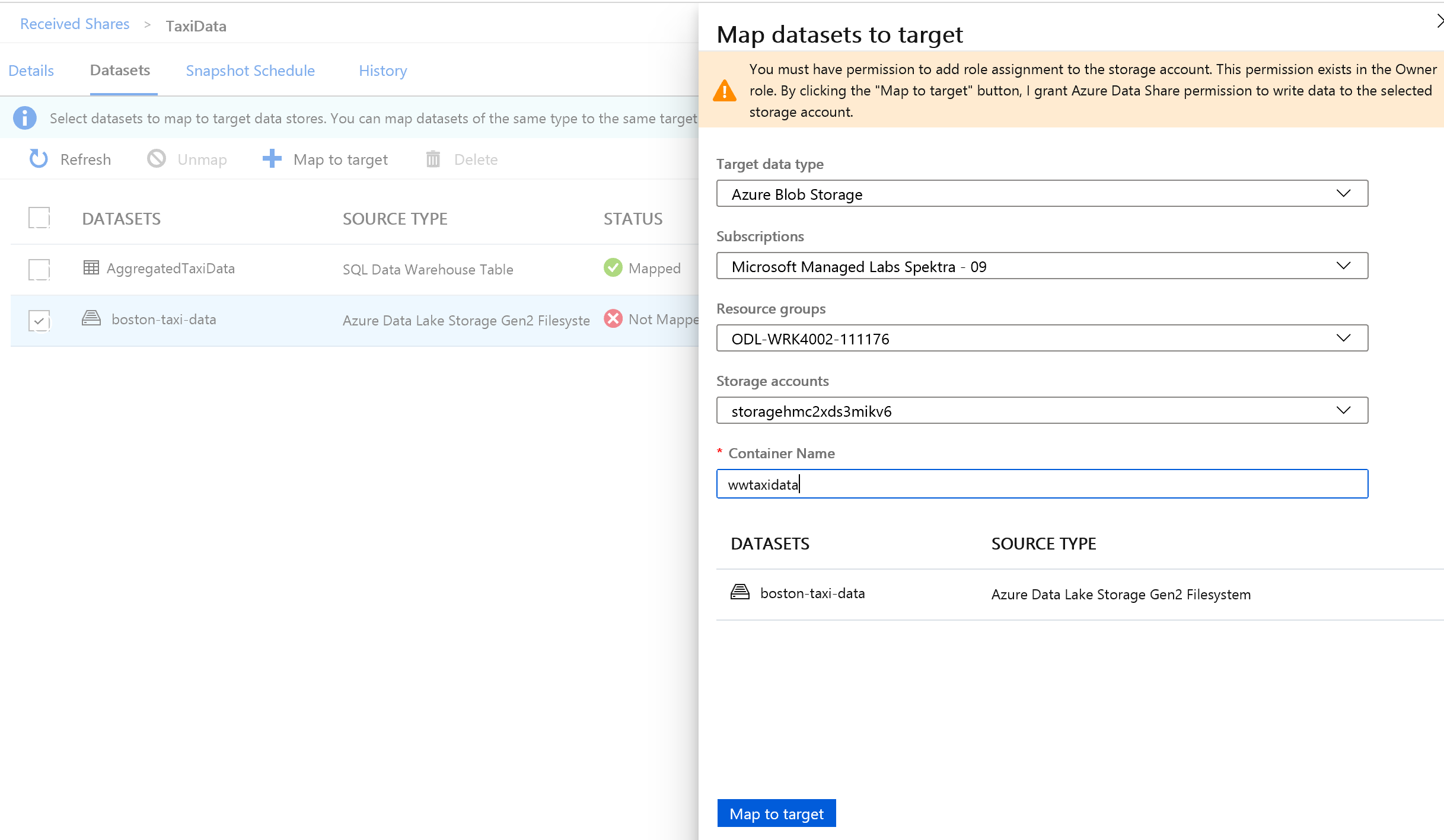
Als alle gegevenssets zijn toegewezen, bent u er klaar voor om gegevens te ontvangen van de gegevensprovider.
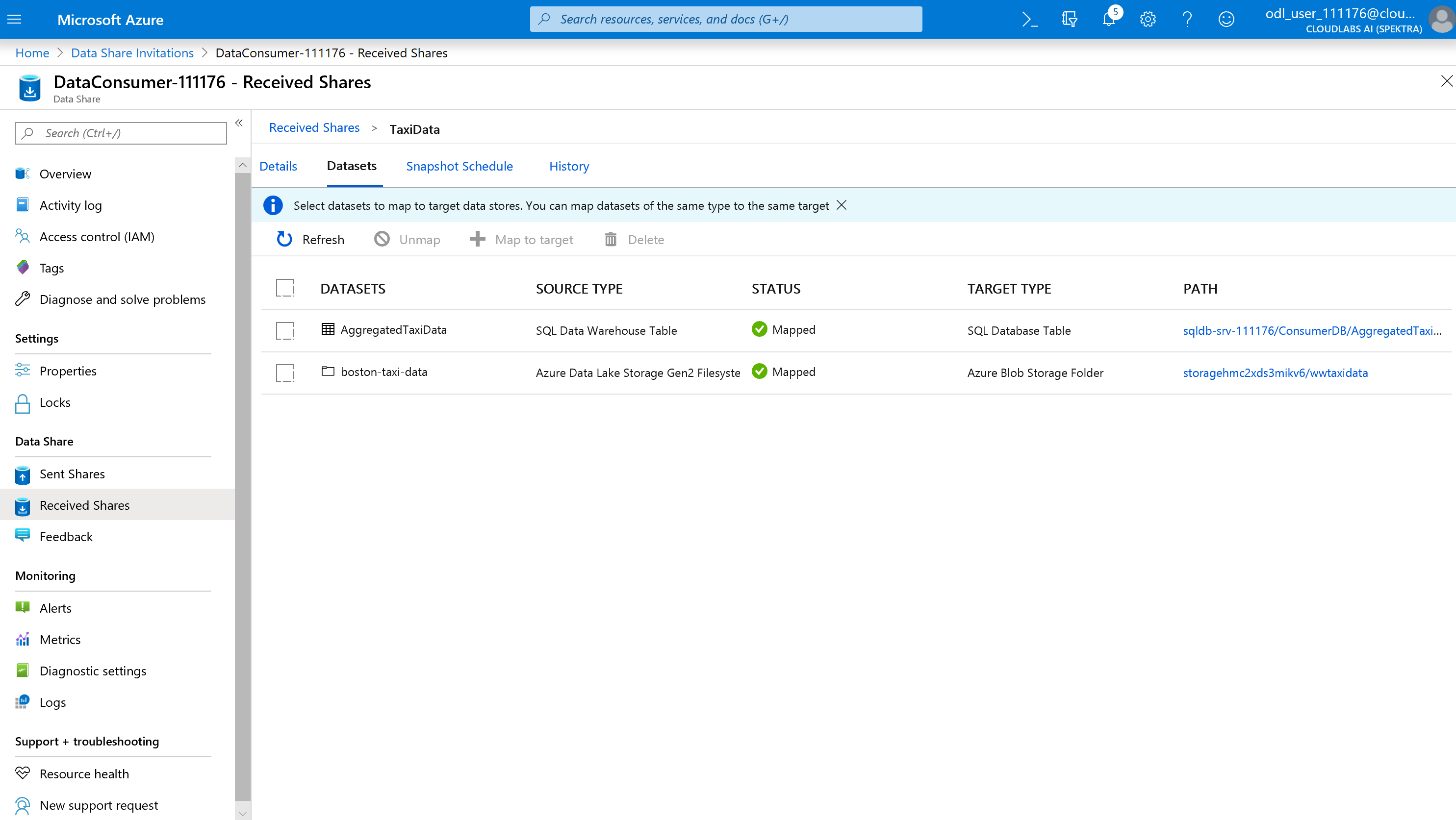
Details selecteren.
Momentopname activeren wordt niet meer grijs weergegeven, omdat de gegevensshare nu bestemmingen heeft om naar te kopiëren.
Selecteer Momentopname activeren -> Volledige kopie.
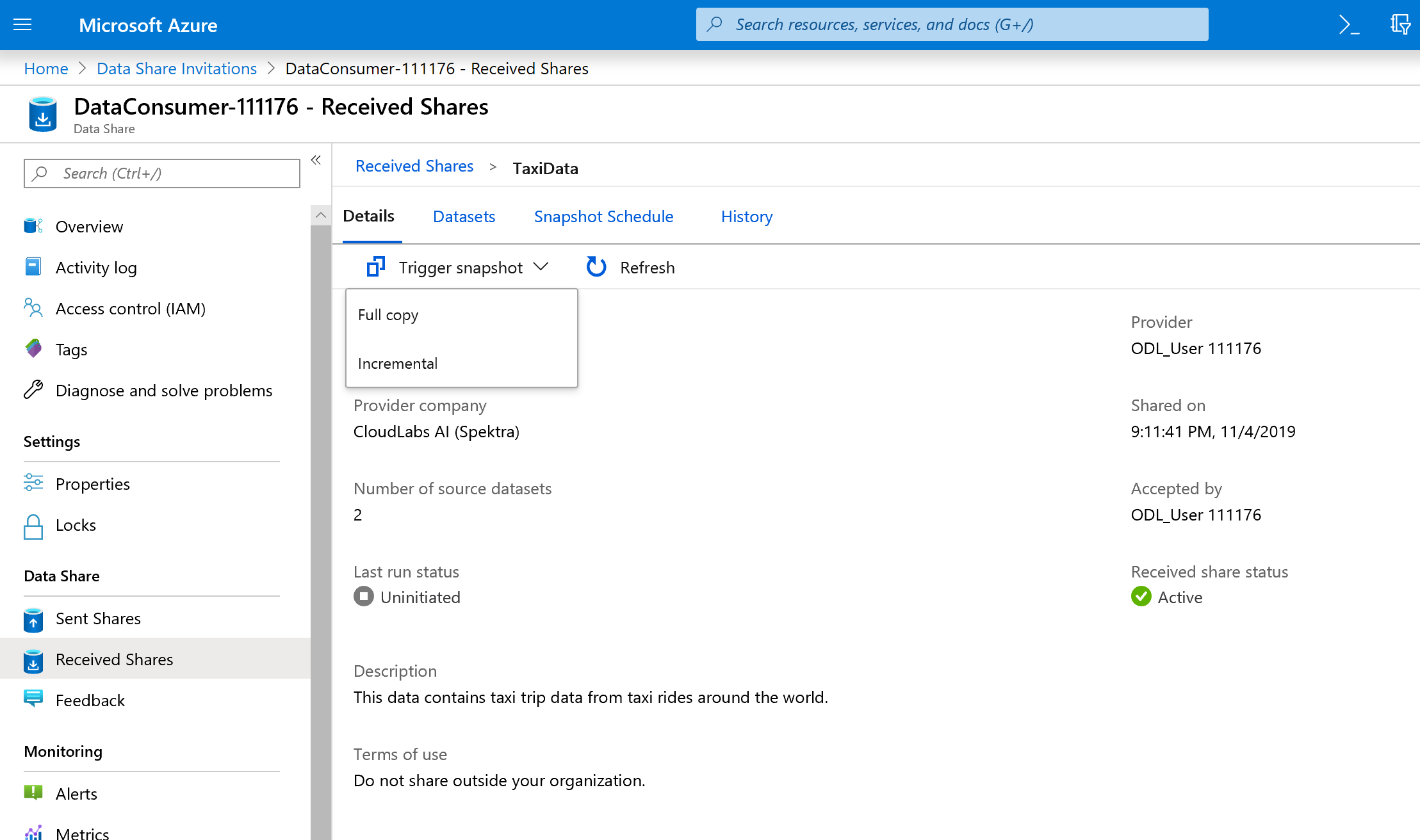
Hiermee worden gegevens gekopieerd naar uw nieuwe datashare-account. In een praktijkscenario zijn deze gegevens afkomstig van derden.
Het duurt ongeveer 3-5 minuten voordat de gegevens zijn tegengekomen. U kunt de voortgang controleren door op het tabblad Geschiedenis te selecteren.
Terwijl u wacht, gaat u naar de oorspronkelijke gegevensshare (DataProvider) en bekijkt u de status van het tabblad Abonnementen en geschiedenis delen. Er is nu een actief abonnement en als gegevensprovider kunt u ook controleren wanneer de gegevensgebruiker is begonnen met het ontvangen van de gegevens die met hen zijn gedeeld.
Ga terug naar de gegevensshare van de gegevensgebruiker. Zodra de status van de trigger is geslaagd, gaat u naar de doel-SQL-database en data lake om te zien dat de gegevens in de respectieve archieven zijn terechtgekomen.







Gefeliciteerd, u hebt het lab voltooid.