Meerdere tabellen bulksgewijs kopiëren met behulp van Azure Data Factory in de Azure-portal
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Deze zelfstudie demonstreert het kopiëren van een aantal tabellen uit Azure SQL Database naar Azure Synapse Analytics. U kunt hetzelfde patroon toepassen in andere kopieerscenario's. Bijvoorbeeld het kopiëren van tabellen van SQL Server/Oracle naar Azure SQL Database/Data Synapse Analytics/Azure Blob, verschillende paden kopiëren van Blob naar Azure SQL Database-tabellen.
Notitie
Zie Inleiding tot Azure Data Factory als u niet bekend bent met Azure Data Factory.
Op hoog niveau bevat deze zelfstudie de volgende stappen:
- Een data factory maken.
- Gekoppelde services maken voor Azure SQL Database, Azure Synapse Analytics en Azure Storage.
- Gegevenssets maken voor Azure SQL Database en Azure Synapse Analytics.
- Een pijplijn maken om de te kopiëren tabellen op te zoeken en een andere pijplijn om de kopieerbewerking daadwerkelijk uit te voeren.
- Een pijplijnuitvoering starten.
- De uitvoering van de pijplijn en van de activiteit controleren.
In deze zelfstudie wordt Azure Portal gebruikt. Zie Quickstarts (Snelstartgidsen) voor meer informatie over het gebruik van andere hulpprogramma's/SDK's voor het maken van een gegevensfactory.
End-to-end werkstroom
In dit scenario gebruikt u een aantal tabellen in Azure SQL Database die u gaat kopiëren naar Azure Synapse Analytics. Dit is de logische volgorde van de stappen in de werkstroom die in pijplijnen plaatsvindt:

- De eerste pijplijn zoekt de lijst op met tabellen die moeten worden gekopieerd naar de sinkgegevensopslag. U kunt ook een metagegevenstabel bijhouden waarin alle tabellen worden vermeld die moeten worden gekopieerd naar de sinkgegevensopslag. De pijplijn activeert vervolgens een andere pijplijn, die elke tabel in de database langsloopt en de bewerking uitvoert waarmee de gegevens worden gekopieerd.
- De tweede pijplijn voert de daadwerkelijke kopieerbewerking uit. De lijst met tabellen wordt gebruikt als parameter. Kopieer voor elke tabel in de lijst de specifieke tabel in Azure SQL Database naar de bijbehorende tabel in Azure Synapse Analytics met behulp van gefaseerd kopiëren via Blob storage en PolyBase voor de beste prestaties. In dit voorbeeld wordt de lijst met tabellen in de eerste pijplijn doorgegeven als een waarde voor de parameter.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- Azure Storage-account. Het Azure Storage-account wordt gebruikt als faseringsblobopslag in de bulksgewijze kopieerbewerking.
- Azure SQL-database. Deze database bevat de brongegevens. Maak een database in SQL Database met Adventure Works LT-testgegevens door het artikel Create a database in Azure SQL Database (Een database in Azure SQL Database maken) te volgen. In deze zelfstudie worden alle tabellen van deze voorbeelddatabase naar Azure Synapse Analytics gekopieerd.
- Azure Synapse Analytics. Dit datawarehouse bevat de uit de SQL Database gekopieerde gegevens. Als u geen Azure Synapse Analytics-werkruimte hebt, raadpleegt u het artikel Aan de slag met Azure Synapse Analytics voor de stappen om er een te maken.
Azure-services voor toegang tot SQL-server
Voor zowel SQL Database als Azure Synapse Analytics moet u Azure-services toegang verlenen tot SQL Server. Zorg ervoor dat de instelling Azure-services en -resources toegang verlenen tot deze server is ingesteld op AAN voor uw server. Met deze instelling kan de Data Factory-service gegevens lezen uit uw Azure SQL Database en schrijven naar Azure Synapse Analytics.
Als u deze instelling wilt controleren en inschakelen, gaat u naar uw serverbeveiligingsfirewalls > > en virtuele netwerken > stelt u in dat Azure-services en -resources toegang hebben tot deze server tot AAN.
Een data factory maken
Start de webbrowser Microsoft Edge of Google Chrome. Op dit moment wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Ga naar de Azure Portal.
Selecteer in het linkermenu van Azure Portal Een resource maken>Integratie>Data Factory.
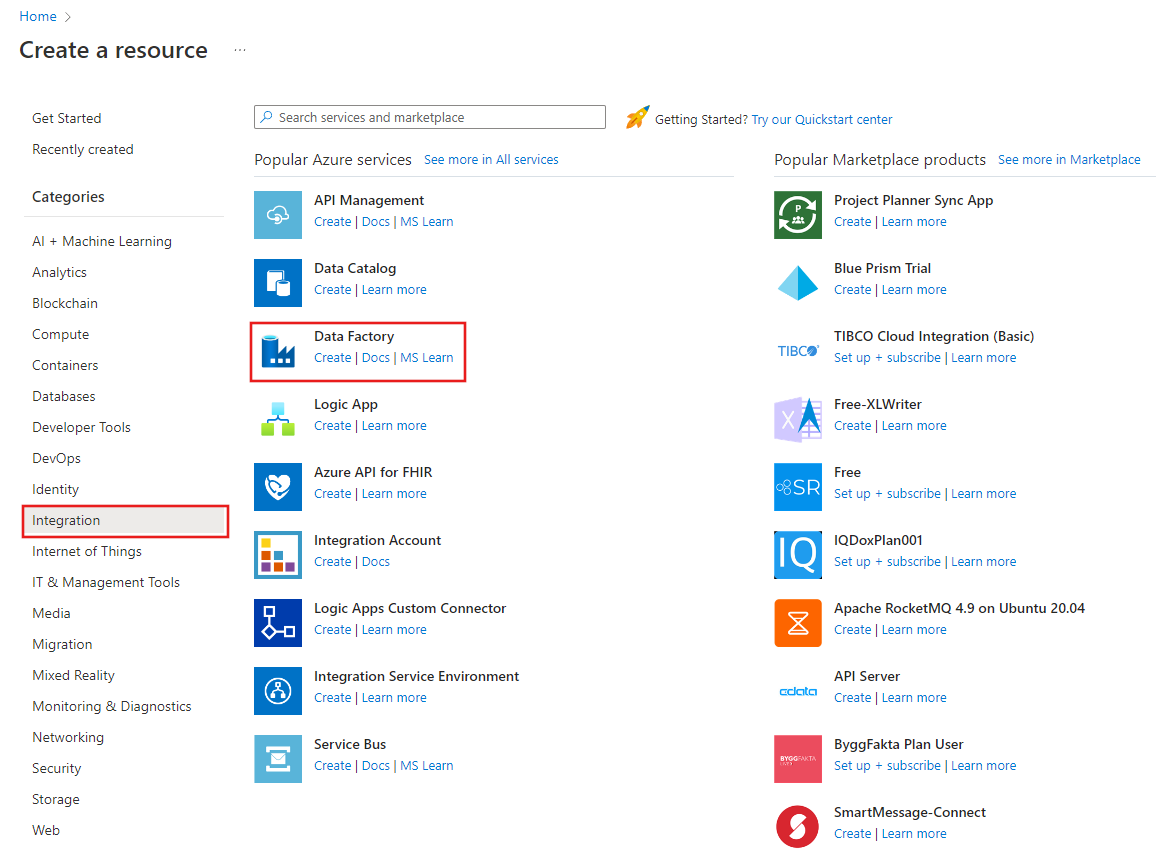
Voer op de pagina New data factoryADFTutorialBulkCopyDF in bij name.
De naam van de Azure-gegevensfactory moet wereldwijd uniek zijn. Als u het volgende foutbericht krijgt, wijzigt u de naam van de gegevensfactory (bijvoorbeeld uwnaamADFTutorialBulkCopyDF) en probeert u het opnieuw. Zie het artikel Data factory - Naamgevingsregels voor meer informatie over naamgevingsregels voor Data Factory-artefacten.
Data factory name "ADFTutorialBulkCopyDF" is not availableSelecteer het Azure-abonnement waarin u de gegevensfactory wilt maken.
Voer een van de volgende stappen uit voor de Resourcegroep:
Selecteer Bestaande gebruiken en selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
Selecteer Nieuwe maken en voer de naam van een resourcegroep in.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer V2 als de versie.
Selecteer de locatie voor de gegevensfactory. Voor een lijst met Azure-regio’s waarin Data Factory momenteel beschikbaar is, selecteert u op de volgende pagina de regio’s waarin u geïnteresseerd bent, vouwt u vervolgens Analytics uit en gaat u naar Data Factory: Beschikbare producten per regio. De gegevensopslagexemplaren (Azure Storage, Azure SQL Database, enzovoort) en berekeningen (HDInsight, enzovoort) die worden gebruikt in Data Factory, kunnen zich in andere regio's bevinden.
Klik op Create.
Nadat het maken is voltooid, selecteert u Ga naar resource om naar de pagina Data Factory te gaan.
Selecteer Openen op de tegel Azure Data Factory Studio openen om de Data Factory UI-toepassing op een afzonderlijk tabblad te starten.
Gekoppelde services maken
U maakt gekoppelde services om uw gegevensarchieven en compute-services aan een gegevensfactory te koppelen. Een gekoppelde service beschikt over de verbindingsgegevens die de Data Factory-service tijdens runtime gebruikt om een verbinding met het gegevensarchief tot stand te brengen.
In deze zelfstudie koppelt u uw gegevensarchieven van Azure SQL Database, Azure Synapse Analytics en Azure Blob Storage aan uw data factory. De Azure SQL-database fungeert als brongegevensarchief. Azure Synapse Analytics dient als de sink/bestemming van het gegevensarchief. Azure Blob Storage is bedoeld voor het vasthouden van de gegevens voordat deze worden geladen in Azure Synapse Analytics met behulp van PolyBase.
Maak de gekoppelde Azure SQL Database-bronservice
In deze stap maakt u een gekoppelde service om uw database in Azure SQL Database aan de data factory te koppelen.
Open het tabblad Beheren via het linkerdeelvenster.
Selecteer op de pagina Gekoppelde services +Nieuw om een nieuwe gekoppelde service te maken.
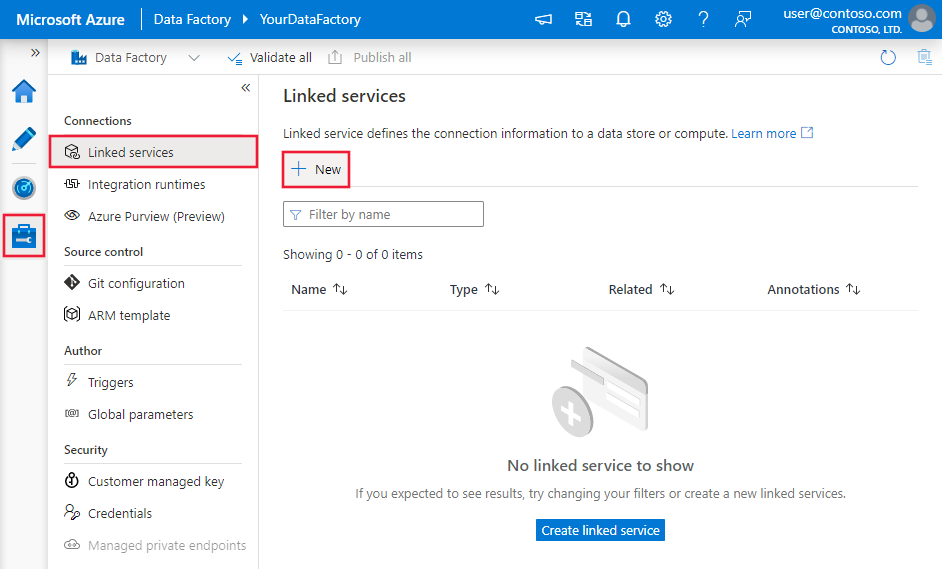
In het venster New Linked Service selecteert u Azure SQL Database en klikt u op Doorgaan.
Voer in het venster Nieuwe gekoppelde service (Azure SQL Database) de volgende stappen uit:
a. Voer AzureSqlDatabaseLinkedService in als Naam.
b. Selecteer uw server als Servernaam
c. Selecteer uw database als Databasenaam.
d. Voer naam van de gebruiker in om verbinding te maken met uw database.
e. Voer het wachtwoord voor de gebruiker in.
f. Als u de verbinding met uw database wilt testen met de opgegeven informatie, klikt u op Test connection.
g. Klik op Maken om de gekoppelde service op te slaan.
De gekoppelde service voor de sink Azure Synapse Analytics-service maken
Op het tabblad Connections klikt u nogmaals op + New op de werkbalk.
In het venster Nieuwe gekoppelde service selecteert u Azure Synapse Analytics en klikt u op Doorgaan.
Voer de volgende stappen uit in het venster Nieuwe gekoppelde service (Azure Synapse Analytics):
a. Voer AzureStorageLinkedService in bij Name.
b. Selecteer uw server als Servernaam
c. Selecteer uw database als Databasenaam.
d. Voer de Gebruikersnaam in om verbinding te maken met uw database.
e. Voer het Wachtwoord voor de gebruiker in.
f. Als u de verbinding met uw database wilt testen met de opgegeven informatie, klikt u op Test connection.
g. Klik op Create.
De gekoppelde Azure Storage-faseringsservice maken
In deze zelfstudie gebruikt u Azure Blob-opslag als een tussentijds faseringsgebied voor het inschakelen van PolyBase voor betere kopieerprestaties.
Op het tabblad Connections klikt u nogmaals op + New op de werkbalk.
In het venster New Linked Service selecteert u Azure Blob Storage en klikt u op Continue.
Voer de volgende stappen uit in het venster Nieuwe gekoppelde service (Azure Blob Storage):
a. Voer AzureStorageLinkedService in als Naam.
b. Selecteer uw Azure Storage-account bij Storage account name.c. Klik op Create.
Gegevenssets maken
In deze zelfstudie maakt u bron- en sinkgegevenssets, waarmee de locatie wordt opgegeven waar de gegevens zijn opgeslagen.
De invoergegevensset AzureSqlDatabaseDataset verwijst naar de AzureSqlDatabaseLinkedService. De gekoppelde service geeft de verbindingsreeks aan om verbinding maken met de database. De gegevensset bevat de naam van de database en de tabel met de brongegevens.
De uitvoergegevensset AzureSqlDWDataset verwijst naar de AzureSqlDWLinkedService. De gekoppelde service geeft de verbindingsreeks aan om verbinding maken met Azure Synapse Analytics. De gegevensset bevat de database en de tabel waarnaar de gegevens worden gekopieerd.
In deze zelfstudie zijn de bron- en doel-SQL-tabellen niet vastgelegd in de definities van de gegevensset. In plaats daarvan geeft de ForEach-activiteit de naam van de tabel tijdens runtime door aan de Copy-activiteit.
Een gegevensset maken voor bron SQL-Database
Selecteer het tabblad Maken in het linkerdeelvenster.
Klik in het linkerdeelvenster op + (plusteken) en selecteer Gegevensset.
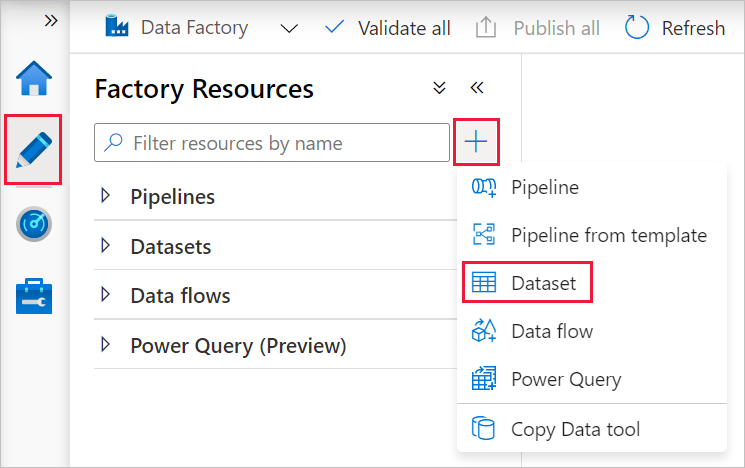
Selecteer in het venster Nieuwe gegevensset de optie Azure SQL Database en selecteer vervolgens Doorgaan.
Voer in het venster Eigenschappen instellen onder Naam AzureSqlDatabaseDataset in. Selecteer bij Gekoppelde service de optie AzureSqlDatabaseLinkedService. Klik vervolgens op OK.
Ga naar het tabblad Verbinding en selecteer een tabel bij voor Tabel. Dit is een tijdelijke tabel. U geeft een query voor de brongegevensset op tijdens het maken van een pijplijn. De query wordt gebruikt om gegevens te extraheren uit uw database. U kunt ook het selectievakje Bewerken inschakelen en dbo.dummyName invoeren als tabelnaam.
Een gegevensset maken voor de sink Azure Synapse Analytics
Klik op + (plus) in het linkervenster en klik op Dataset.
In het venster Nieuwe gegevensset selecteert u Azure Synapse Analytics en klikt u op Doorgaan.
Voer in het venster Eigenschappen instellen onder Naam AzureSqlDWDataset in. Selecteer bij Gekoppelde service de optie AzureSqlDWLinkedService. Klik vervolgens op OK.
Ga naar het tabblad Parameters, klik op + Nieuw en voer DWTableName in als de parameternaam. Klik nogmaals op + Nieuw en voer DWSchema in voor de parameternaam. Als u deze naam kopieert/plakt vanaf de pagina, moet u ervoor zorgen dat er geen spatie volgt na DWTableName en DWSchema.
Ga naar het tabblad Verbinding,
Vink de optie Bewerken aan voor Tabel. Selecteer het eerste invoervak en klik op de link Dynamische inhoud toevoegen eronder. Klik op de pagina Dynamische inhoud toevoegen op het DWSchema onder Parameters. Het expressietekstvak
@dataset().DWSchemawordt nu automatisch ingevuld. Klik vervolgens op Voltooien.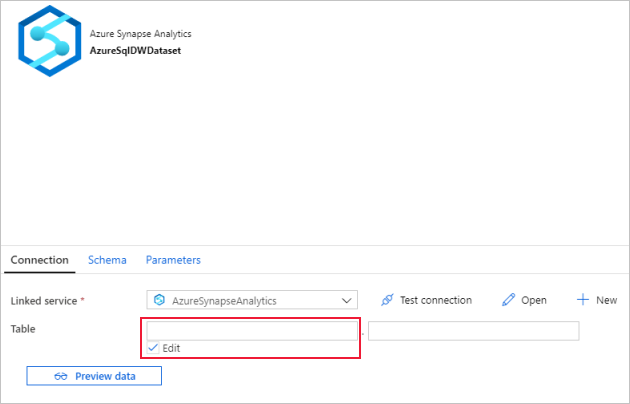
Selecteer het tweede invoervak en klik op de link Dynamische inhoud toevoegen eronder. Klik op de pagina Dynamische inhoud toevoegen op de DWTAbleName onder Parameters. Het expressietekstvak
@dataset().DWTableNamewordt nu automatisch ingevuld. Klik vervolgens op Voltooien.De tableName-eigenschap van de gegevensset is ingesteld op de waardes die worden doorgegeven als argumenten voor de DWSchema en DWTableName-parameters. De ForEach-activiteit doorloopt een lijst met tabellen en geeft deze één voor één door aan de Copy-activiteit.
Pijplijnen maken
In deze zelfstudie gaat u twee pijplijnen maken: IterateAndCopySQLTables en GetTableListAndTriggerCopyData.
De pijplijn GetTableListAndTriggerCopyData voert twee acties uit:
- Zoekt de systeemtabel van Azure SQL Database op om de lijst met te kopiëren tabellen op te halen.
- Activeert de pijplijn IterateAndCopySQLTables om het kopiëren van de gegevens daadwerkelijk uit te voeren.
De pijplijn IterateAndCopySQLTables gebruikt een lijst met tabellen als parameter. Voor elke tabel in de lijst worden gegevens uit de tabel in Azure SQL Database naar Azure Synapse Analytics gekopieerd met behulp van gefaseerd kopiëren en PolyBase.
De pijplijn IterateAndCopySQLTables maken
Klik op + (plus) in het linkervenster en klik op Pipeline.
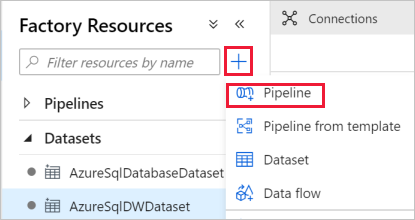
Geef op het tabblad Algemeen bij Eigenschappen IterateAndCopySQLTables op als Naam. Vouw het paneel vervolgens samen door in de rechterbovenhoek op het pictogram Eigenschappen te klikken.
Open het tabblad Parameters en voer de volgende stappen uit:
a. Klik op + Nieuw.
b. Voer tableList in als Name-parameter.
c. Selecteer Matrix bij Type.
Vouw in de werkset Activities de optie Iteration & Conditions uit en sleep de ForEach-activiteit naar het ontwerpoppervlak voor pijplijnen. U kunt ook zoeken naar activiteiten in de werkset Activiteiten.
a. Voer onderaan het tabblad AlgemeenIterateSQLTables bij Naam in.
b. Ga naar het tabblad Instellingen, klik op het invoervak voor Items en klik vervolgens op de onderstaande link Dynamische inhoud toevoegen.
c. Vouw op de pagina Dynamische inhoud toevoegen de secties Systeemvariabelen en Functies samen en klik op de tableList onder Parameters. Het expressietekstvak wordt nu automatisch ingevuld als
@pipeline().parameter.tableList. Klik vervolgens op Voltooien.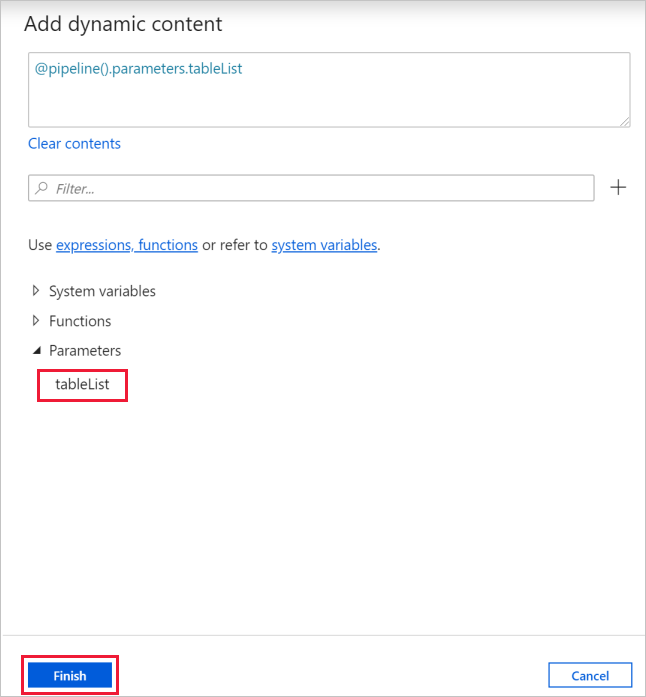
d. Ga naar het tabblad Activiteiten en klik op het potloodpictogram om een onderliggende activiteit toe te voegen aan de activiteit ForEach.
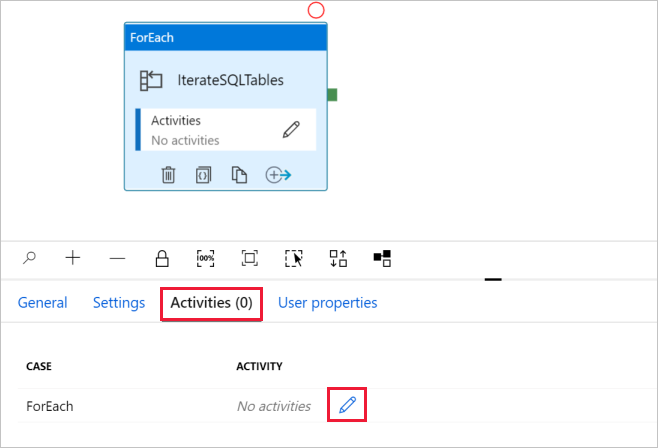
Vouw in de Activiteiten-werkset de optie Verplaatsen en overzetten uit. Gebruik vervolgens slepen-en-neerzetten om de activiteit Gegevens kopiëren te verplaatsen naar het ontwerpoppervlak voor pijplijnen. Let op het breadcrumb-menu bovenaan. IterateAndCopySQLTable is de naam van de pijplijn en IterateSQLTables is de naam van de ForEach-activiteit. Voor de ontwerpfunctie is het activiteitbereik actief. Als u vanuit de ForEach-editor wilt overschakelen naar de pijplijn-editor, klikt u op de koppeling in het koppelingenmenu.
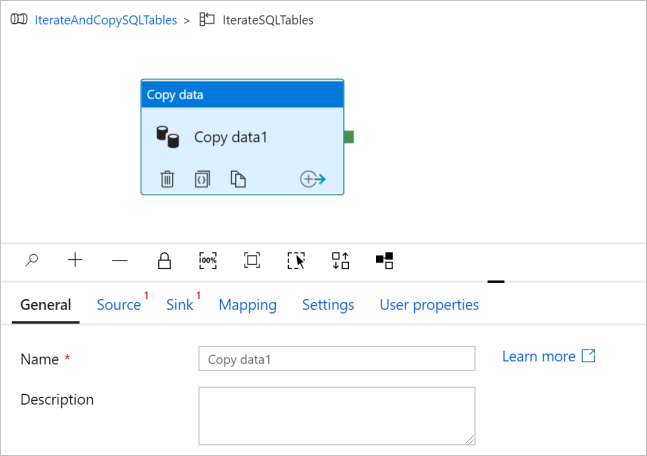
Open het tabblad Source en voer de volgende stappen uit:
Selecteer AzureSqlDatabaseDataset bij Source Dataset.
Selecteer Query bij Query gebruiken.
Klik op het invoervak Query -> selecteer de onderstaande dynamische inhoud toevoegen -> voer de volgende expressie in voor Query -> selecteer Voltooien.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Open het tabblad Sink en voer de volgende stappen uit:
Selecteer AzureSqlDWDataset bij Sink Dataset.
Klik op het invoervak voor de parameter VALUE of DWTableName -> selecteer de onderstaande dynamische inhoud toevoegen, voer
@item().TABLE_NAMEde expressie in als script.> Selecteer Voltooien.Klik op het invoervak voor de parameter VALUE of DWSchema -> selecteer de onderstaande dynamische inhoud toevoegen, voer
@item().TABLE_SCHEMAde expressie in als script.> Selecteer Voltooien.Selecteer als kopieermethode PolyBase.
Schakel de optie Standaardtype gebruiken uit.
Voor de optie Tabel is de standaardinstelling Geen. Als er geen vooraf gemaakte tabellen zijn in de sink Azure Synapse Analytics, schakelt u de optie Automatisch een tabel maken in. Met de kopieeractiviteit worden vervolgens automatisch tabellen voor u gemaakt op basis van de brongegevens. Raadpleeg Automatisch sinktabellen maken voor de details.
Klik op het invoervak Script vooraf kopiëren -> selecteer de onderstaande dynamische inhoud toevoegen -> voer de volgende expressie in als script -> selecteer Voltooien.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]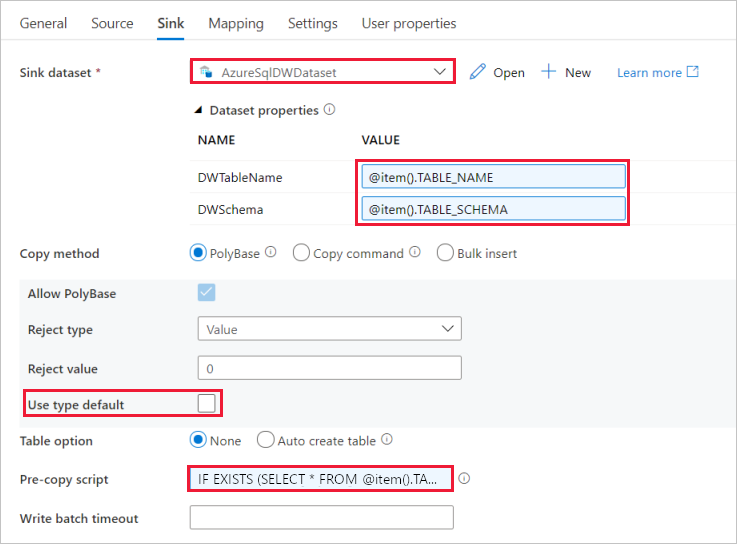
Open het tabblad Settings en voer de volgende stappen uit:
- Selecteer het selectievakje voor Fasering inschakelen.
- Selecteer AzureStorageLinkedService bij Store Account Linked Service.
Klik in de bovenste pijplijnwerkbalk op Valideren om de instellingen voor de pijplijn te valideren. Controleer of er geen validatiefouten zijn. Sluit het venster Pijplijnvalidatierapport door op de dubbele vierkante haken >> te klikken.
De pijplijn GetTableListAndTriggerCopyData maken
Deze pijplijn voert twee acties uit:
- Zoekt de systeemtabel van Azure SQL Database op om de lijst met te kopiëren tabellen op te halen.
- Activeert de pijplijn 'IterateAndCopySQLTables' om het kopiëren van de gegevens daadwerkelijk uit te voeren.
Hier volgen de stappen voor het maken van de pijplijn:
Klik op + (plus) in het linkervenster en klik op Pipeline.
In het paneel onder Eigenschappen wijzigt u de naam van de pijplijn in GetTableListAndTriggerCopyData.
Vouw in de werkset Activiteiten de optie Algemeen uit, sleep de Opzoeken-activiteit naar het ontwerpoppervlak voor pijplijnen en voer de volgende stappen uit:
- Voer LookupTableList in als Name.
- Voer De tabellijst ophalen uit de mijn database in bij Description.
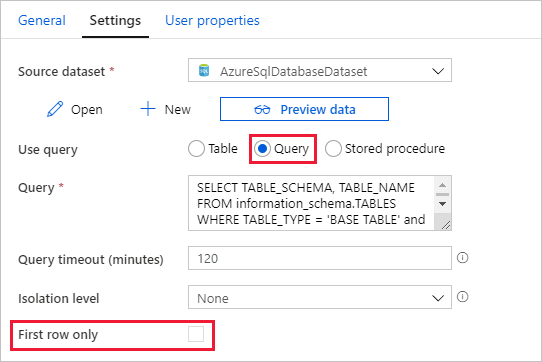
Open het tabblad Settings en voer de volgende stappen uit:
Selecteer AzureSqlDatabaseDataset bij Source Dataset.
Selecteer Query bij Query gebruiken.
Voer bij Query de volgende SQL-query in.
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Schakel het selectievakje voor het veld First row only uit.
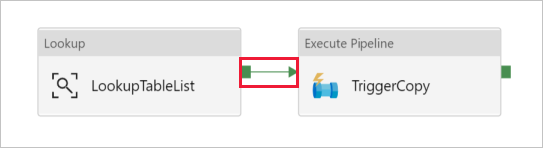
Sleep de Pijplijn uitvoeren-activiteit van de werkset Activiteiten naar het ontwerpoppervlak voor pijplijnen en stel de naam in op TriggerCopy.
Verbind de activiteit Opzoeken met de activiteit Pijplijn uitvoeren door het groene vakje dat aan de activiteit Opzoeken is gekoppeld, naar de linkerkant van de activiteit Pijplijn uitvoeren te slepen.
Ga naar het tabblad Instellingen in het tabblad van de activiteit Pijplijn uitvoeren en voer de volgende stappen uit:
Selecteer IterateAndCopySQLTables bij Invoked pipeline.
Schakel het selectievakje Wacht op voltooiing uit.
Klik in de sectie Parameters op het invoervak onder WAARDE -> selecteer de onderstaande dynamische inhoud toevoegen -> voer deze in
@activity('LookupTableList').output.valueals tabelnaamwaarde -> selecteer Voltooien. U stelt de lijst met resultaten vanuit de activiteit Opzoeken in als invoer voor de tweede pijplijn. De lijst met resultaten bevat de lijst met tabellen waarvan de gegevens naar de bestemming moeten worden gekopieerd.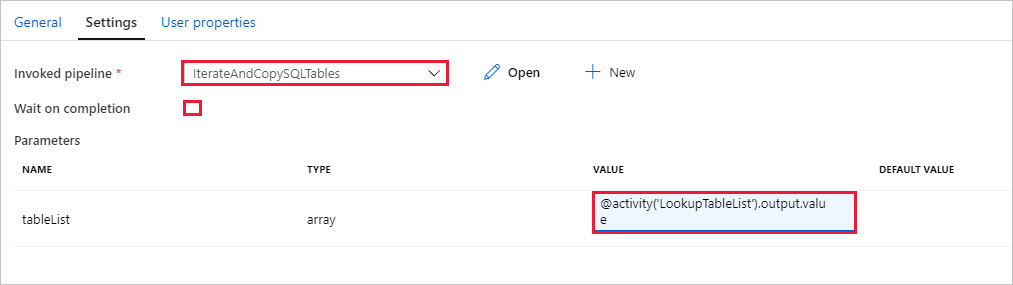
Valideer de pijplijn door te klikken op de knop Validate op de werkbalk. Controleer of er geen validatiefouten zijn. Sluit het venster Pipeline Validation Report door op >> te klikken.
Als u entiteiten (gegevenssets, pijplijnen, enzovoort) wilt publiceren naar de Data Factory-service, klikt u boven aan het venster op Alles publiceren. Wacht totdat de publicatie is uitgevoerd.
Een pijplijnuitvoering activeren
Ga naar pijplijn GetTableListAndTriggerCopyData, klik in de bovenste werkbalk van de pijplijn op Trigger toevoegen vervolgens op Nu activeren.
Bevestig de uitvoering op de pagina Pijplijn uitvoeren en selecteer Voltooien.
De pijplijnuitvoering controleren.
Ga naar het tabblad Controleren . Klik op Vernieuwen totdat u uitvoeringen ziet voor beide pijplijnen in uw oplossing. Blijf de lijst vernieuwen totdat de status Succeeded wordt weergegeven.
Als u uitvoeringen van activiteit wilt weergeven die gekoppeld zijn aan de pijplijn GetTableListAndTriggerCopyData, klikt u op de link voor de naam van die pijplijn. Er moeten twee uitvoeringen van activiteit voor deze pijplijnuitvoering te zien zijn.
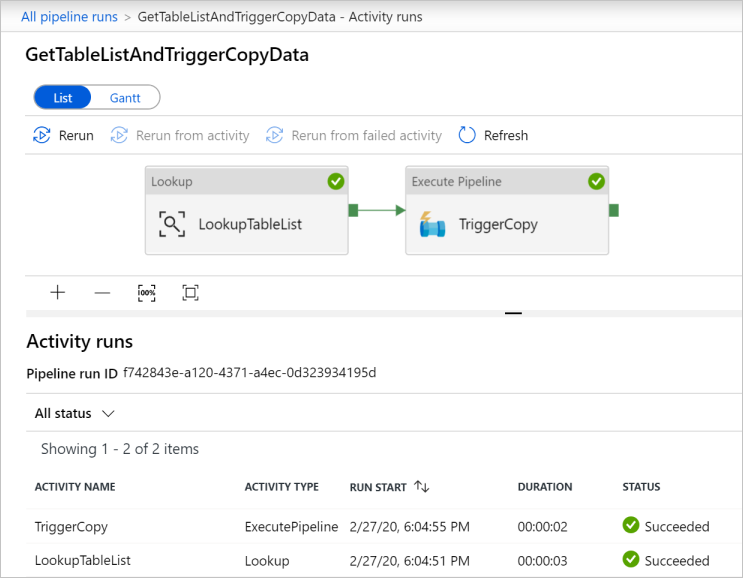
Als u de uitvoer van de activiteit Opzoeken wilt weergeven, klikt u op de link Uitvoer naast de activiteit in de kolom ACTIVITEITNAAM. U kunt het venster Output maximaliseren en herstellen. Nadat u de uitvoer hebt bekeken, klikt u op X om het venster Output te sluiten.
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Als u wilt terugkeren naar de weergave Pijplijn uitvoeren, klikt u op de link Alle uitgevoerde pijplijnen boven aan het koppelingsmenu. Klik op IterateAndCopySQLTables (onder de kolom PIJPLIJNNAAM) om de uitvoering van de pijplijnactiviteiten weer te geven. U ziet dat er één kopieeractiviteit is uitgevoerd voor elke tabel in de uitvoer van de opzoekactiviteit.
Bevestig dat de gegevens zijn gekopieerd naar het beoogde Azure Synapse Analytics dat u in deze zelfstudie hebt gebruikt.
Gerelateerde inhoud
In deze zelfstudie hebt u de volgende stappen uitgevoerd:
- Een data factory maken.
- Gekoppelde services maken voor Azure SQL Database, Azure Synapse Analytics en Azure Storage.
- Gegevenssets maken voor Azure SQL Database en Azure Synapse Analytics.
- Een pijplijn maken om de te kopiëren tabellen op te zoeken en een andere pijplijn om de kopieerbewerking daadwerkelijk uit te voeren.
- Een pijplijnuitvoering starten.
- De uitvoering van de pijplijn en van de activiteit controleren.
Ga door naar de volgende zelfstudie voor informatie over het incrementeel kopiëren van gegevens uit een bron naar een bestemming: