Gegevens kopiëren en transformeren in Azure Synapse Analytics met behulp van Azure Data Factory- of Synapse-pijplijnen
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt in Azure Data Factory- of Synapse-pijplijnen om gegevens van en naar Azure Synapse Analytics te kopiëren en Gegevensstroom te gebruiken om gegevens te transformeren in Azure Data Lake Storage Gen2. Lees het inleidende artikel voor meer informatie over Azure Data Factory.
Ondersteunde mogelijkheden
Deze Azure Synapse Analytics-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR | Beheerd privé-eindpunt |
|---|---|---|
| Copy-activiteit (bron/sink) | (1) (2) | ✓ |
| Toewijzingsgegevensstroom (bron/sink) | (1) | ✓ |
| Activiteit Lookup | (1) (2) | ✓ |
| GetMetadata-activiteit | (1) (2) | ✓ |
| Scriptactiviteit | (1) (2) | ✓ |
| Opgeslagen procedureactiviteit | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Voor Copy-activiteit ondersteunt deze Azure Synapse Analytics-connector deze functies:
- Kopieer gegevens met behulp van SQL-verificatie en Microsoft Entra Application-tokenverificatie met een service-principal of beheerde identiteiten voor Azure-resources.
- Als bron kunt u gegevens ophalen met behulp van een SQL-query of opgeslagen procedure. U kunt er ook voor kiezen om parallel te kopiëren vanuit een Azure Synapse Analytics-bron. Zie de sectie Parallel kopiëren uit Azure Synapse Analytics voor meer informatie.
- Laad gegevens als sink met behulp van de COPY-instructie of PolyBase of bulksgewijs invoegen. We raden de COPY-instructie of PolyBase aan voor betere kopieerprestaties. De connector biedt ook ondersteuning voor het automatisch maken van de doeltabel met DISTRIBUTION = ROUND_ROBIN als deze niet bestaat op basis van het bronschema.
Belangrijk
Als u gegevens kopieert met behulp van een Azure Integration Runtime, configureert u een firewallregel op serverniveau zodat Azure-services toegang hebben tot de logische SQL-server. Als u gegevens kopieert met behulp van een zelf-hostende Integration Runtime, configureert u de firewall om het juiste IP-bereik toe te staan. Dit bereik omvat het IP-adres van de machine dat wordt gebruikt om verbinding te maken met Azure Synapse Analytics.
Aan de slag
Tip
Gebruik de PolyBase- of COPY-instructie om gegevens in Azure Synapse Analytics te laden om de beste prestaties te behalen. PolyBase gebruiken om gegevens te laden in Azure Synapse Analytics en de instructie COPY gebruiken om gegevens in Azure Synapse Analytics-secties te laden, bevatten details. Zie 1 TB in Azure Synapse Analytics laden in minder dan 15 minuten met Azure Data Factory voor een overzicht van een use-case.
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde Azure Synapse Analytics-service maken met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde Azure Synapse Analytics-service te maken in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Synapse en selecteer de Azure Synapse Analytics-connector.
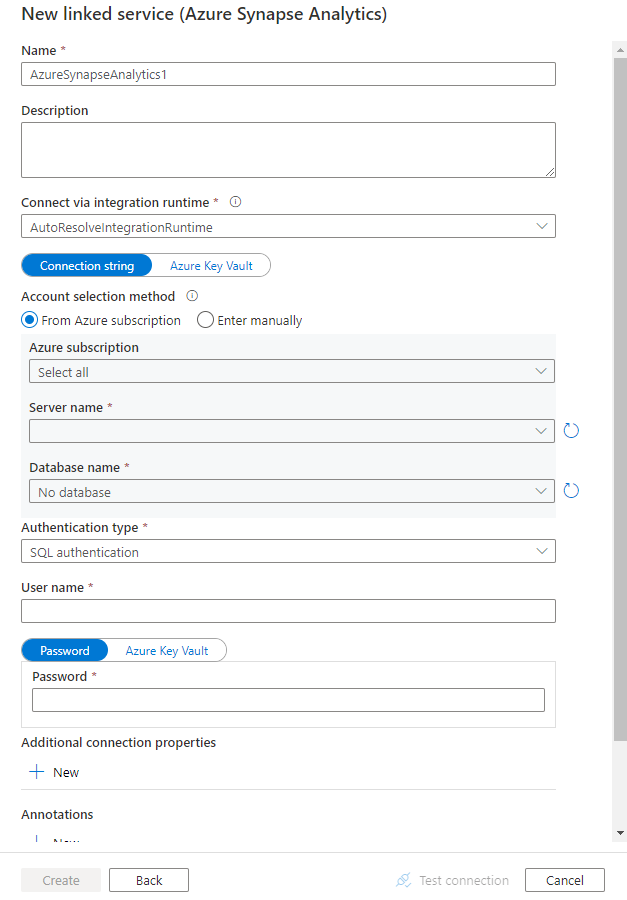
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen waarmee Data Factory- en Synapse-pijplijnentiteiten worden gedefinieerd die specifiek zijn voor een Azure Synapse Analytics-connector.
Eigenschappen van gekoppelde service
De aanbevolen versie van de Azure Synapse Analytics-connector ondersteunt TLS 1.3. Raadpleeg deze sectie om de versie van uw Azure Synapse Analytics-connector te upgraden van verouderde versie. Zie de bijbehorende secties voor de details van de eigenschap.
Tip
Wanneer u een gekoppelde service maakt voor een serverloze SQL-pool in Azure Synapse vanuit Azure Portal:
- Kies Handmatig invoeren voor accountselectiemethode.
- Plak de volledig gekwalificeerde domeinnaam van het serverloze eindpunt. U vindt dit op de overzichtspagina van Azure Portal voor uw Synapse-werkruimte in de eigenschappen onder Serverloze SQL-eindpunt. Bijvoorbeeld:
myserver-ondemand.sql-azuresynapse.net. - Geef voor databasenaam de databasenaam op in de serverloze SQL-pool.
Tip
Als u een fout krijgt met de foutcode UserErrorFailedToConnectToSqlServer en het bericht 'De sessielimiet voor de database is XXX en is bereikt', voegt u het toe Pooling=false aan uw verbindingsreeks en probeert u het opnieuw.
Aanbevolen versie
Deze algemene eigenschappen worden ondersteund voor een gekoppelde Azure Synapse Analytics-service wanneer u de aanbevolen versie toepast:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureSqlDW. | Ja |
| server | De naam of het netwerkadres van het SQL Server-exemplaar waarmee u verbinding wilt maken. | Ja |
| database | De naam van de database. | Ja |
| authenticationType | Het type dat wordt gebruikt voor verificatie. Toegestane waarden zijn SQL (standaard), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Ga naar de relevante verificatiesectie over specifieke eigenschappen en vereisten. | Ja |
| encryptie | Geef aan of TLS-versleuteling is vereist voor alle gegevens die worden verzonden tussen de client en de server. Opties: verplicht (voor waar, standaard)/optioneel (voor onwaar)/strikt. | Nee |
| trustServerCertificate | Geef aan of het kanaal wordt versleuteld tijdens het omzeilen van de certificaatketen om de vertrouwensrelatie te valideren. | Nee |
| hostNameInCertificate | De hostnaam die moet worden gebruikt bij het valideren van het servercertificaat voor de verbinding. Wanneer deze niet is opgegeven, wordt de servernaam gebruikt voor certificaatvalidatie. | Nee |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een particulier netwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Zie de onderstaande tabel voor aanvullende verbindingseigenschappen:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| applicationIntent | Het workloadtype van de toepassing bij het maken van verbinding met een server. Toegestane waarden zijn ReadOnly en ReadWrite. |
Nee |
| connectTimeout | De tijdsduur (in seconden) om te wachten op een verbinding met de server voordat de poging wordt beëindigd en er een fout wordt gegenereerd. | Nee |
| connectRetryCount | Het aantal nieuwe verbindingen dat is geprobeerd na het identificeren van een niet-actieve verbindingsfout. De waarde moet een geheel getal tussen 0 en 255 zijn. | Nee |
| connectRetryInterval | De hoeveelheid tijd (in seconden) tussen elke poging om opnieuw verbinding te maken na het identificeren van een niet-actieve verbindingsfout. De waarde moet een geheel getal tussen 1 en 60 zijn. | Nee |
| loadBalanceTimeout | De minimale tijd (in seconden) voordat de verbinding live in de verbindingsgroep wordt uitgevoerd voordat de verbinding wordt vernietigd. | Nee |
| commandTimeout | De standaardwachttijd (in seconden) voordat de poging om een opdracht uit te voeren eindigt en een fout genereert. | Nee |
| integratedSecurity | De toegestane waarden zijn true of false. Geef bij het opgeven falseaan of gebruikersnaam en wachtwoord zijn opgegeven in de verbinding. Wanneer u opgeeft true, geeft u aan of de referenties van het huidige Windows-account worden gebruikt voor verificatie. |
Nee |
| failoverPartner | De naam of het adres van de partnerserver waarmee verbinding moet worden gemaakt als de primaire server niet beschikbaar is. | Nee |
| maxPoolSize | Het maximum aantal verbindingen dat is toegestaan in de verbindingsgroep voor de specifieke verbinding. | Nee |
| minPoolSize | Het minimale aantal verbindingen dat is toegestaan in de verbindingsgroep voor de specifieke verbinding. | Nee |
| multipleActiveResultSets | De toegestane waarden zijn true of false. Wanneer u opgeeft true, kan een toepassing meerdere actieve resultatensets (MARS) onderhouden. Wanneer u opgeeft false, moet een toepassing alle resultatensets van de ene batch verwerken of annuleren voordat deze andere batches op die verbinding kan uitvoeren. |
Nee |
| multiSubnetFailover | De toegestane waarden zijn true of false. Als uw toepassing verbinding maakt met een AlwaysOn-beschikbaarheidsgroep (AG) op verschillende subnetten, stelt u deze eigenschap in om true sneller te detecteren en verbinding te maken met de momenteel actieve server. |
Nee |
| packetSize | De grootte in bytes van de netwerkpakketten die worden gebruikt om te communiceren met een exemplaar van de server. | Nee |
| Bundeling | De toegestane waarden zijn true of false. Wanneer u opgeeft true, wordt de verbinding gegroepeerd. Wanneer u opgeeft false, wordt de verbinding expliciet geopend telkens wanneer de verbinding wordt aangevraagd. |
Nee |
SQL-verificatie
Als u SQL-verificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| gebruikersnaam | De gebruikersnaam die wordt gebruikt om verbinding te maken met de server. | Ja |
| password | Het wachtwoord voor de gebruikersnaam. Markeer dit veld als SecureString om het veilig op te slaan. U kunt ook verwijzen naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
Voorbeeld: SQL-verificatie gebruiken
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: wachtwoord in Azure Key Vault
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verificatie van service-principal
Als u service-principalverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| servicePrincipalId | Geef de client-id van de toepassing op. | Ja |
| servicePrincipalCredential | De referenties van de service-principal. Geef de sleutel van de toepassing op. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| AD-tenant | Geef de tenantgegevens (domeinnaam of tenant-id) op waaronder uw toepassing zich bevindt. U kunt deze ophalen door de muisaanwijzer in de rechterbovenhoek van Azure Portal te plaatsen. | Ja |
| azureCloudType | Geef voor service-principalverificatie het type Azure-cloudomgeving op waarnaar uw Microsoft Entra-toepassing is geregistreerd. Toegestane waarden zijn AzurePublic, AzureChina, en AzureGermanyAzureUsGovernment. Standaard wordt de cloudomgeving van de data factory of Synapse-pijplijn gebruikt. |
Nee |
U moet ook de onderstaande stappen volgen:
Maak een Microsoft Entra-toepassing vanuit Azure Portal. Noteer de naam van de toepassing en de volgende waarden die de gekoppelde service definiëren:
- Toepassings-id
- Toepassingssleutel
- Tenant-id
Richt een Microsoft Entra-beheerder in voor uw server in Azure Portal als u dit nog niet hebt gedaan. De Microsoft Entra-beheerder kan een Microsoft Entra-gebruiker of Microsoft Entra-groep zijn. Als u de groep met een beheerde identiteit een beheerdersrol verleent, slaat u stap 3 en 4 over. De beheerder heeft volledige toegang tot de database.
Maak ingesloten databasegebruikers voor de service-principal. Maak verbinding met het datawarehouse van of waarmee u gegevens wilt kopiëren met behulp van hulpprogramma's zoals SSMS, met een Microsoft Entra-identiteit met ten minste ALTER ANY USER-machtigingen. Voer de volgende T-SQL uit:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;Verdeel de benodigde machtigingen voor de service-principal zoals u normaal gesproken doet voor SQL-gebruikers of anderen. Voer de volgende code uit of raadpleeg hier meer opties. Als u PolyBase wilt gebruiken om de gegevens te laden, leert u de vereiste databasemachtiging.
EXEC sp_addrolemember db_owner, [your application name];Configureer een gekoppelde Azure Synapse Analytics-service in een Azure Data Factory- of Synapse-werkruimte.
Voorbeeld van een gekoppelde service die gebruikmaakt van verificatie van de service-principal
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door het systeem toegewezen beheerde identiteiten voor Verificatie van Azure-resources
Een data factory of Synapse-werkruimte kan worden gekoppeld aan een door het systeem toegewezen beheerde identiteit voor Azure-resources die de resource vertegenwoordigen. U kunt deze beheerde identiteit gebruiken voor Azure Synapse Analytics-verificatie. De aangewezen resource heeft toegang tot en kopieer gegevens van of naar uw datawarehouse met behulp van deze identiteit.
Als u door het systeem toegewezen beheerde identiteitverificatie wilt gebruiken, geeft u de algemene eigenschappen op die in de vorige sectie worden beschreven en volgt u deze stappen.
Richt een Microsoft Entra-beheerder in voor uw server in Azure Portal als u dit nog niet hebt gedaan. De Microsoft Entra-beheerder kan een Microsoft Entra-gebruiker of Microsoft Entra-groep zijn. Als u de groep met een door het systeem toegewezen beheerde identiteit een beheerdersrol verleent, slaat u stap 3 en 4 over. De beheerder heeft volledige toegang tot de database.
Maak ingesloten databasegebruikers voor de door het systeem toegewezen beheerde identiteit. Maak verbinding met het datawarehouse van of waarmee u gegevens wilt kopiëren met behulp van hulpprogramma's zoals SSMS, met een Microsoft Entra-identiteit met ten minste ALTER ANY USER-machtigingen. Voer de volgende T-SQL uit.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Verdeel de door het systeem toegewezen beheerde identiteit machtigingen zoals u normaal gesproken doet voor SQL-gebruikers en anderen. Voer de volgende code uit of raadpleeg hier meer opties. Als u PolyBase wilt gebruiken om de gegevens te laden, leert u de vereiste databasemachtiging.
EXEC sp_addrolemember db_owner, [your_resource_name];Configureer een gekoppelde Azure Synapse Analytics-service.
Voorbeeld:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door de gebruiker toegewezen beheerde identiteitverificatie
Een data factory of Synapse-werkruimte kan worden gekoppeld aan een door de gebruiker toegewezen beheerde identiteiten die de resource vertegenwoordigen. U kunt deze beheerde identiteit gebruiken voor Azure Synapse Analytics-verificatie. De aangewezen resource heeft toegang tot en kopieer gegevens van of naar uw datawarehouse met behulp van deze identiteit.
Als u door de gebruiker toegewezen beheerde identiteitverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| aanmeldingsgegevens | Geef de door de gebruiker toegewezen beheerde identiteit op als referentieobject. | Ja |
U moet ook de onderstaande stappen volgen:
Richt een Microsoft Entra-beheerder in voor uw server in Azure Portal als u dit nog niet hebt gedaan. De Microsoft Entra-beheerder kan een Microsoft Entra-gebruiker of Microsoft Entra-groep zijn. Als u de groep met een door de gebruiker toegewezen beheerde identiteit een beheerdersrol verleent, slaat u stap 3 over. De beheerder heeft volledige toegang tot de database.
Maak ingesloten databasegebruikers voor de door de gebruiker toegewezen beheerde identiteit. Maak verbinding met het datawarehouse van of waarmee u gegevens wilt kopiëren met behulp van hulpprogramma's zoals SSMS, met een Microsoft Entra-identiteit met ten minste ALTER ANY USER-machtigingen. Voer de volgende T-SQL uit.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Maak een of meerdere door de gebruiker toegewezen beheerde identiteiten en ververleent de door de gebruiker toegewezen beheerde identiteit machtigingen zoals u normaal gesproken doet voor SQL-gebruikers en anderen. Voer de volgende code uit of raadpleeg hier meer opties. Als u PolyBase wilt gebruiken om de gegevens te laden, leert u de vereiste databasemachtiging.
EXEC sp_addrolemember db_owner, [your_resource_name];Wijs een of meerdere door de gebruiker toegewezen beheerde identiteiten toe aan uw data factory en maak referenties voor elke door de gebruiker toegewezen beheerde identiteit.
Configureer een gekoppelde Azure Synapse Analytics-service.
Voorbeeld
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verouderde versie
Deze algemene eigenschappen worden ondersteund voor een gekoppelde Azure Synapse Analytics-service wanneer u een verouderde versie toepast:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AzureSqlDW. | Ja |
| connectionString | Geef de informatie op die nodig is om verbinding te maken met het Azure Synapse Analytics-exemplaar voor de eigenschap connectionString . Markeer dit veld als securestring om het veilig op te slaan. U kunt ook de sleutel voor wachtwoord-/service-principals in Azure Key Vault plaatsen en als het SQL-verificatie is, haalt u de password configuratie uit de verbindingsreeks. Zie het artikel Store-referenties in Azure Key Vault met meer informatie. |
Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken (als uw gegevensarchief zich in een particulier netwerk bevindt). Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Raadpleeg voor verschillende verificatietypen respectievelijk de volgende secties over specifieke eigenschappen en vereisten:
- SQL-verificatie voor de verouderde versie
- Verificatie van de service-principal voor de verouderde versie
- Door het systeem toegewezen beheerde identiteitverificatie voor de verouderde versie
- Door de gebruiker toegewezen beheerde identiteitverificatie voor de verouderde versie
SQL-verificatie voor de verouderde versie
Als u SQL-verificatie wilt gebruiken, geeft u de algemene eigenschappen op die in de vorige sectie worden beschreven.
Verificatie van de service-principal voor de verouderde versie
Als u service-principalverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| servicePrincipalId | Geef de client-id van de toepassing op. | Ja |
| servicePrincipalKey | Geef de sleutel van de toepassing op. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| AD-tenant | Geef de tenantgegevens op, zoals de domeinnaam of tenant-id, waaronder uw toepassing zich bevindt. Haal deze op door de muis in de rechterbovenhoek van Azure Portal te bewegen. | Ja |
| azureCloudType | Geef voor service-principalverificatie het type Azure-cloudomgeving op waarnaar uw Microsoft Entra-toepassing is geregistreerd. Toegestane waarden zijn AzurePublic, AzureChina, AzureUsGovernment en AzureGermany. Standaard wordt de cloudomgeving van de data factory of Synapse-pijplijn gebruikt. |
Nee |
U moet ook de stappen in service-principalverificatie volgen om de bijbehorende machtiging te verlenen.
Door het systeem toegewezen beheerde identiteitverificatie voor de verouderde versie
Als u door het systeem toegewezen beheerde identiteitverificatie wilt gebruiken, volgt u dezelfde stap voor de aanbevolen versie in door het systeem toegewezen beheerde identiteitverificatie.
Door de gebruiker toegewezen beheerde identiteitverificatie voor verouderde versie
Als u door de gebruiker toegewezen beheerde identiteitverificatie wilt gebruiken, volgt u dezelfde stap voor de aanbevolen versie in door de gebruiker toegewezen beheerde identiteitverificatie.
Eigenschappen van gegevensset
Zie het artikel Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets .
De volgende eigenschappen worden ondersteund voor de Azure Synapse Analytics-gegevensset:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AzureSqlDWTable. | Ja |
| schema | Naam van het schema. | Nee voor bron, Ja voor sink |
| table | Naam van de tabel/weergave. | Nee voor bron, Ja voor sink |
| tableName | Naam van de tabel/weergave met schema. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Voor nieuwe workload gebruikt schema u en table. |
Nee voor bron, Ja voor sink |
Voorbeeld van gegevensseteigenschappen
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschappen van kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Azure Synapse Analytics-bron en -sink.
Azure Synapse Analytics als bron
Tip
Als u gegevens efficiënt wilt laden vanuit Azure Synapse Analytics met behulp van gegevenspartitionering, vindt u meer informatie over parallel kopiëren vanuit Azure Synapse Analytics.
Als u gegevens uit Azure Synapse Analytics wilt kopiëren, stelt u de typeeigenschap in de bron Kopieeractiviteit in op SqlDWSource. De volgende eigenschappen worden ondersteund in de sectie Bron van kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op SqlDWSource. | Ja |
| sqlReaderQuery | Gebruik de aangepaste SQL-query om gegevens te lezen. Voorbeeld: select * from MyTable. |
Nee |
| sqlReaderStoredProcedureName | De naam van de opgeslagen procedure waarmee gegevens uit de brontabel worden gelezen. De laatste SQL-instructie moet een SELECT-instructie zijn in de opgeslagen procedure. | Nee |
| storedProcedureParameters | Parameters voor de opgeslagen procedure. Toegestane waarden zijn naam- of waardeparen. Namen en hoofdletters van parameters moeten overeenkomen met de namen en hoofdletters van de opgeslagen procedureparameters. |
Nee |
| isolationLevel | Hiermee geeft u het gedrag voor transactievergrendeling voor de SQL-bron op. De toegestane waarden zijn: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Als dit niet is opgegeven, wordt het standaardisolatieniveau van de database gebruikt. Zie system.data.isolationlevel voor meer informatie. | Nee |
| partitionOptions | Hiermee geeft u de opties voor gegevenspartitionering op die worden gebruikt voor het laden van gegevens uit Azure Synapse Analytics. Toegestane waarden zijn: Geen (standaard), PhysicalPartitionsOfTable en DynamicRange. Wanneer een partitieoptie is ingeschakeld (dat wil niet None), wordt de mate van parallelle uitvoering om gegevens van een Azure Synapse Analytics gelijktijdig te laden, bepaald door de parallelCopies instelling voor de kopieeractiviteit. |
Nee |
| partitionSettings | Geef de groep van de instellingen voor gegevenspartitionering op. Toepassen wanneer de partitieoptie niet Noneis. |
Nee |
Onder partitionSettings: |
||
| partitionColumnName | Geef de naam op van de bronkolom in geheel getal of datum/datum/tijd -type (int, smallint, bigintdate, smalldatetime, , datetimeof datetime2datetimeoffset) dat wordt gebruikt door bereikpartitionering voor parallelle kopie. Als deze niet is opgegeven, wordt de index of de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als de partitiekolom.Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?DfDynamicRangePartitionCondition aan de WHERE-component. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
| partitionUpperBound | De maximumwaarde van de partitiekolom voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Toepassen wanneer de partitieoptie is DynamicRange. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
| partitionLowerBound | De minimale waarde van de partitiekolom voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Toepassen wanneer de partitieoptie is DynamicRange. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
Let op het volgende punt:
- Wanneer u opgeslagen procedure in de bron gebruikt om gegevens op te halen, moet u er rekening mee houden dat uw opgeslagen procedure is ontworpen als het retourneren van een ander schema wanneer een andere parameterwaarde wordt doorgegeven, mogelijk een fout optreedt of onverwacht resultaat ziet bij het importeren van het schema uit de gebruikersinterface of bij het kopiëren van gegevens naar sql-database met automatisch maken van tabellen.
Voorbeeld: SQL-query gebruiken
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Voorbeeld: opgeslagen procedure gebruiken
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Voorbeeld van opgeslagen procedure:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics als sink
Azure Data Factory- en Synapse-pijplijnen ondersteunen drie manieren om gegevens in Azure Synapse Analytics te laden.
- COPY-instructie gebruiken
- PolyBase gebruiken
- Bulksgewijs invoegen gebruiken
De snelste en meest schaalbare manier om gegevens te laden, is via de COPY-instructie of de PolyBase.
Als u gegevens wilt kopiëren naar Azure Synapse Analytics, stelt u het sinktype in kopieeractiviteit in op SqlDWSink. De volgende eigenschappen worden ondersteund in de sectie Sink voor kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de sink voor kopieeractiviteit moet worden ingesteld op SqlDWSink. | Ja |
| allowPolyBase | Hiermee wordt aangegeven of PolyBase moet worden gebruikt om gegevens te laden in Azure Synapse Analytics. allowCopyCommand en allowPolyBase kan niet beide waar zijn. Zie PolyBase gebruiken om gegevens te laden in de sectie Azure Synapse Analytics voor beperkingen en details. Toegestane waarden zijn Waar en Onwaar (standaard). |
Nee Toepassen bij het gebruik van PolyBase. |
| polyBaseSettings | Een groep eigenschappen die kan worden opgegeven wanneer de allowPolybase eigenschap is ingesteld op true. |
Nee Toepassen bij het gebruik van PolyBase. |
| allowCopyCommand | Hiermee wordt aangegeven of u de COPY-instructie gebruikt om gegevens te laden in Azure Synapse Analytics. allowCopyCommand en allowPolyBase kan niet beide waar zijn. Zie de instructie COPY gebruiken om gegevens te laden in de sectie Azure Synapse Analytics voor beperkingen en details. Toegestane waarden zijn Waar en Onwaar (standaard). |
Nee Toepassen wanneer u COPY gebruikt. |
| copyCommandSettings | Een groep eigenschappen die kan worden opgegeven wanneer allowCopyCommand de eigenschap is ingesteld op TRUE. |
Nee Toepassen wanneer u COPY gebruikt. |
| writeBatchSize | Aantal rijen dat moet worden ingevoegd in de SQL-tabel per batch. De toegestane waarde is een geheel getal (aantal rijen). Standaard bepaalt de service dynamisch de juiste batchgrootte op basis van de rijgrootte. |
Nee Toepassen wanneer u bulksgewijs invoegen gebruikt. |
| writeBatchTimeout | De wachttijd voor de invoegbewerking, upsert en opgeslagen procedure die moet worden voltooid voordat er een time-out optreedt. Toegestane waarden zijn voor de periode. Een voorbeeld is '00:30:00' gedurende 30 minuten. Als er geen waarde is opgegeven, wordt de time-out standaard ingesteld op '00:30:00'. |
Nee Toepassen wanneer u bulksgewijs invoegen gebruikt. |
| preCopyScript | Geef in elke uitvoering een SQL-query op voor kopieeractiviteit die moet worden uitgevoerd voordat u gegevens naar Azure Synapse Analytics schrijft. Gebruik deze eigenschap om de vooraf geladen gegevens op te schonen. | Nee |
| tableOption | Hiermee geeft u op of de sinktabel automatisch moet worden gemaakt, als deze niet bestaat, op basis van het bronschema. Toegestane waarden zijn: none (standaard), autoCreate. |
Nee |
| disableMetricsCollection | De service verzamelt metrische gegevens, zoals Azure Synapse Analytics DWU's voor optimalisatie van kopieerprestaties en aanbevelingen, waardoor extra master DB-toegang wordt geïntroduceerd. Als u zich zorgen maakt over dit gedrag, geeft u true op om dit uit te schakelen. |
Nee (standaard is false) |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
| WriteBehavior | Geef het schrijfgedrag op voor kopieeractiviteit om gegevens te laden in Azure Synapse Analytics. De toegestane waarde is Invoegen en Upsert. De service maakt standaard gebruik van Insert om gegevens te laden. |
Nee |
| upsertSettings | Geef de groep van de instellingen voor schrijfgedrag op. Toepassen wanneer de optie WriteBehavior is Upsert. |
Nee |
Onder upsertSettings: |
||
| keys | Geef de kolomnamen op voor unieke rijidentificatie. U kunt één sleutel of een reeks sleutels gebruiken. Als deze niet is opgegeven, wordt de primaire sleutel gebruikt. | Nee |
| interimSchemaName | Geef het tussentijdse schema op voor het maken van een tussentijdse tabel. Opmerking: de gebruiker moet over de machtiging beschikken voor het maken en verwijderen van een tabel. De tussentijdse tabel deelt standaard hetzelfde schema als de sinktabel. | Nee |
Voorbeeld 1: Azure Synapse Analytics-sink
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Voorbeeld 2: Upsert-gegevens
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Parallel kopiëren vanuit Azure Synapse Analytics
De Azure Synapse Analytics-connector in kopieeractiviteit biedt ingebouwde gegevenspartitionering om gegevens parallel te kopiëren. U vindt opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.
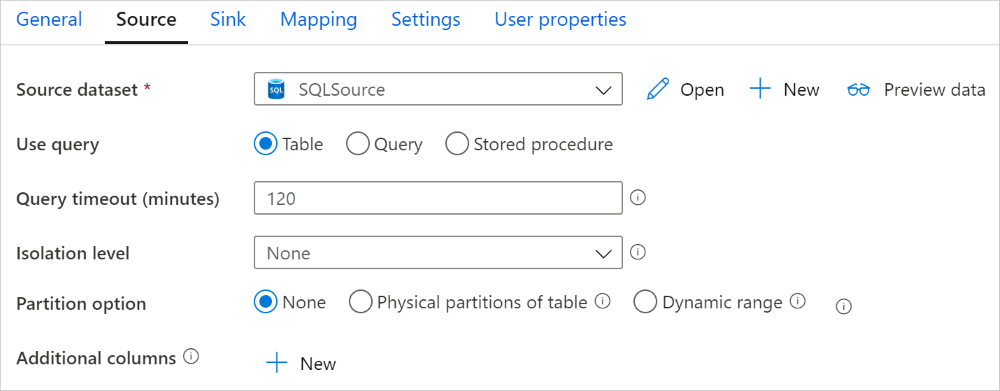
Wanneer u gepartitioneerde kopie inschakelt, voert de kopieeractiviteit parallelle query's uit op uw Azure Synapse Analytics-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de parallelCopies instelling voor de kopieeractiviteit. Als u bijvoorbeeld instelt op parallelCopies vier, genereert de service gelijktijdig vier query's op basis van de opgegeven partitieoptie en -instellingen en haalt elke query een deel van de gegevens op uit uw Azure Synapse Analytics.
U wordt aangeraden parallelle kopieën met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens uit Azure Synapse Analytics laadt. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, is het raadzaam om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige belasting van grote tabellen, met fysieke partities. | Partitieoptie: fysieke partities van de tabel. Tijdens de uitvoering detecteert de service automatisch de fysieke partities en kopieert de gegevens per partitie. Als u wilt controleren of uw tabel een fysieke partitie heeft of niet, kunt u naar deze query verwijzen. |
| Volledige belasting van grote tabellen, zonder fysieke partities, terwijl met een geheel getal of datum/tijd-kolom voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Partitiekolom (optioneel): Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Als deze niet is opgegeven, wordt de index- of primaire-sleutelkolom gebruikt. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in de tabel worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, worden de waarden automatisch gedetecteerd door de kopieeractiviteit. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, met parallelle kopie als 4, haalt de service gegevens op met 4 partities - id's in bereik <=20, [21, 50], [51, 80] en >=81. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, zonder fysieke partities, terwijl u een geheel getal of een datum/datum/tijd-kolom gebruikt voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, waarbij de parallelle kopie als 4 is, haalt de service gegevens op met 4 partities- id's in het bereik <=20, [21, 50], [51, 80] en >=81. Hier volgen meer voorbeeldquery's voor verschillende scenario's: 1. Voer een query uit op de hele tabel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Query's uitvoeren uit een tabel met kolomselectie en aanvullende where-componentfilters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query uitvoeren met subquery's: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query uitvoeren met partitie in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Aanbevolen procedures voor het laden van gegevens met partitieoptie:
- Kies een onderscheidende kolom als partitiekolom (zoals primaire sleutel of unieke sleutel) om scheeftrekken van gegevens te voorkomen.
- Als de tabel een ingebouwde partitie heeft, gebruikt u de partitieoptie Fysieke partities van de tabel om betere prestaties te krijgen.
- Als u Azure Integration Runtime gebruikt om gegevens te kopiëren, kunt u grotere 'Data-Integratie eenheden (DIU)' (>4) instellen om meer rekenresources te gebruiken. Controleer de toepasselijke scenario's daar.
- "Mate van kopieerparallellisme" bepaalt de partitienummers, stelt dit getal een beetje te groot voor de prestaties, raadt u aan dit getal in te stellen als (DIU of het aantal zelf-hostende IR-knooppunten) * (2 tot 4).
- Houd er rekening mee dat Azure Synapse Analytics maximaal 32 query's tegelijk kan uitvoeren. Als u 'Mate van kopieerparallelisme' instelt, kan dit leiden tot een probleem met synapse-beperking.
Voorbeeld: volledige belasting van grote tabellen met fysieke partities
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Voorbeeld: query met partitie dynamisch bereik
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Voorbeeldquery om fysieke partitie te controleren
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Als de tabel een fysieke partitie heeft, ziet u HasPartition als Ja.
Copy-instructie gebruiken om gegevens te laden in Azure Synapse Analytics
Het gebruik van de COPY-instructie is een eenvoudige en flexibele manier om gegevens te laden in Azure Synapse Analytics met hoge doorvoer. Voor meer informatie, controleert u gegevens bulksgewijs laden met behulp van de COPY-instructie
- Als uw brongegevens zich in Azure Blob of Azure Data Lake Storage Gen2 bevinden en de indeling compatibel is met de COPY-instructie, kunt u de kopieeractiviteit gebruiken om de COPY-instructie rechtstreeks aan te roepen om Azure Synapse Analytics de gegevens uit de bron te laten ophalen. Zie Direct copy met behulp van de COPY-instructie voor meer informatie.
- Als uw brongegevensarchief en -indeling niet oorspronkelijk wordt ondersteund door de COPY-instructie, gebruikt u in plaats daarvan de functie Gefaseerde kopie met behulp van de functie COPY-instructie. De functie voor gefaseerde kopie biedt u ook betere doorvoer. De gegevens worden automatisch geconverteerd naar de indeling die compatibel is met de COPY-instructie, slaat de gegevens op in Azure Blob Storage en roept vervolgens de COPY-instructie aan om gegevens te laden in Azure Synapse Analytics.
Tip
Wanneer u de COPY-instructie gebruikt met Azure Integration Runtime, is effectieve Data-Integratie eenheden (DIU) altijd 2. Het afstemmen van de DIU heeft geen invloed op de prestaties, omdat het laden van gegevens uit de opslag wordt mogelijk gemaakt door de Azure Synapse-engine.
Directe kopie met behulp van copy-instructie
De copy-instructie van Azure Synapse Analytics ondersteunt rechtstreeks Azure Blob en Azure Data Lake Storage Gen2. Als uw brongegevens voldoen aan de criteria die in deze sectie worden beschreven, gebruikt u de COPY-instructie om rechtstreeks vanuit het brongegevensarchief naar Azure Synapse Analytics te kopiëren. Gebruik anders gefaseerde kopie met behulp van de COPY-instructie. De service controleert de instellingen en mislukt de uitvoering van de kopieeractiviteit als niet aan de criteria wordt voldaan.
De gekoppelde bronservice en -indeling zijn met de volgende typen en verificatiemethoden:
Ondersteund type brongegevensarchief Ondersteunde indeling Ondersteund type bronverificatie Azure Blob Tekst met scheidingstekens Verificatie van accountsleutels, shared access signature authentication, service principal authentication (using ServicePrincipalKey), door het systeem toegewezen beheerde identiteitverificatie Parquet Verificatie van accountsleutels, shared access signature-verificatie ORK Verificatie van accountsleutels, shared access signature-verificatie Azure Data Lake Storage Gen2 Tekst met scheidingstekens
Parquet
ORKVerificatie van accountsleutels, verificatie van de service-principal (met servicePrincipalKey), verificatie van gedeelde toegangshandtekening, door het systeem toegewezen beheerde identiteitverificatie Belangrijk
- Wanneer u verificatie van beheerde identiteiten gebruikt voor uw gekoppelde opslagservice, leert u de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2 .
- Als uw Azure Storage is geconfigureerd met een VNet-service-eindpunt, moet u verificatie voor beheerde identiteiten gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg de impact van het gebruik van VNet-service-eindpunten met Azure Storage.
De indelingsinstellingen zijn met de volgende:
- Voor Parquet:
compressionkan geen compressie, Snappy ofGZip. - Voor ORC:
compressionkan geen compressie,zlibof Snappy zijn. - Voor tekst met scheidingstekens:
rowDelimiterwordt expliciet ingesteld als één teken of '\r\n', de standaardwaarde wordt niet ondersteund.nullValueis ingesteld op een lege tekenreeks ("").encodingNameis ingesteld op utf-8 of utf-16.escapeCharmoet hetzelfde zijn alsquoteCharen is niet leeg.skipLineCountis standaard ingesteld of ingesteld op 0.compressionkan geen compressie ofGZip.
- Voor Parquet:
Als uw bron een map is,
recursivemoet in de kopieeractiviteit worden ingesteld op waar enwildcardFilenamemoet dit zijn*of*.*.wildcardFolderPath,wildcardFilename(anders dan*of*.*),modifiedDateTimeStart, ,modifiedDateTimeEndenenablePartitionDiscoveryprefixadditionalColumnszijn niet opgegeven.
De volgende instellingen voor de COPY-instructie worden ondersteund onder allowCopyCommand kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| defaultValues | Hiermee geeft u de standaardwaarden voor elke doelkolom in Azure Synapse Analytics op. De standaardwaarden in de eigenschap overschrijven de standaardbeperking die is ingesteld in het datawarehouse en de identiteitskolom mag geen standaardwaarde hebben. | Nee |
| additionalOptions | Aanvullende opties die worden doorgegeven aan een Azure Synapse Analytics COPY-instructie, rechtstreeks in de component 'With' in de COPY-instructie. Citeer de waarde indien nodig om te voldoen aan de vereisten voor de COPY-instructie. | Nee |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Gefaseerde kopie met de instructie COPY
Wanneer uw brongegevens niet systeemeigen compatibel zijn met de COPY-instructie, schakelt u het kopiëren van gegevens in via een tussentijdse fasering van Azure Blob of Azure Data Lake Storage Gen2 (dit kan geen Azure Premium Storage zijn). In dit geval converteert de service de gegevens automatisch om te voldoen aan de vereisten voor de gegevensindeling van de COPY-instructie. Vervolgens wordt de COPY-instructie aangeroepen om gegevens in Azure Synapse Analytics te laden. Ten slotte worden uw tijdelijke gegevens uit de opslag opgeschoond. Zie Gefaseerde kopie voor meer informatie over het kopiëren van gegevens via een fasering.
Als u deze functie wilt gebruiken, maakt u een gekoppelde Azure Blob Storage-service of een gekoppelde Azure Data Lake Storage Gen2-service met accountsleutel of door het systeem beheerde identiteitsverificatie die verwijst naar het Azure-opslagaccount als tussentijdse opslag.
Belangrijk
- Wanneer u verificatie van beheerde identiteiten gebruikt voor uw gekoppelde faseringsservice, leert u de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2 . U moet ook machtigingen verlenen aan uw beheerde identiteit van uw Azure Synapse Analytics-werkruimte in uw faserings-Azure Blob Storage- of Azure Data Lake Storage Gen2-account. Zie Machtigingen verlenen aan beheerde identiteiten voor werkruimten voor meer informatie over het verlenen van deze machtiging.
- Als uw faserings-Azure Storage is geconfigureerd met VNet-service-eindpunt, moet u verificatie voor beheerde identiteit gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg Impact van het gebruik van VNet-service-eindpunten met Azure Storage.
Belangrijk
Als uw faserings-Azure Storage is geconfigureerd met een beheerd privé-eindpunt en de firewall voor opslag is ingeschakeld, moet u verificatie van beheerde identiteiten gebruiken en machtigingen voor Opslagblobgegevenslezer verlenen aan de Synapse SQL Server om ervoor te zorgen dat deze toegang heeft tot de gefaseerde bestanden tijdens het laden van de COPY-instructie.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
PolyBase gebruiken om gegevens te laden in Azure Synapse Analytics
Het gebruik van PolyBase is een efficiënte manier om een grote hoeveelheid gegevens te laden in Azure Synapse Analytics met hoge doorvoer. U ziet een grote toename in de doorvoer met behulp van PolyBase in plaats van het standaard BULKINSERT-mechanisme.
- Als uw brongegevens zich in Azure Blob of Azure Data Lake Storage Gen2 bevinden en de indeling compatibel is met PolyBase, kunt u kopieeractiviteit gebruiken om PolyBase rechtstreeks aan te roepen om Azure Synapse Analytics de gegevens uit de bron te laten halen. Zie Direct kopiëren met PolyBase voor meer informatie.
- Als uw brongegevensarchief en -indeling niet oorspronkelijk door PolyBase worden ondersteund, gebruikt u in plaats daarvan de gefaseerde kopie met behulp van de functie PolyBase . De functie voor gefaseerde kopie biedt u ook betere doorvoer. De gegevens worden automatisch geconverteerd naar een indeling die compatibel is met PolyBase, slaat de gegevens op in Azure Blob Storage en roept PolyBase vervolgens aan om gegevens te laden in Azure Synapse Analytics.
Tip
Meer informatie over aanbevolen procedures voor het gebruik van PolyBase. Wanneer u PolyBase gebruikt met Azure Integration Runtime, is effectieve Data-Integratie eenheden (DIU) voor directe of gefaseerde opslag-naar-Synapse altijd 2. Het afstemmen van de DIU heeft geen invloed op de prestaties, omdat het laden van gegevens uit de opslag wordt mogelijk gemaakt door de Synapse-engine.
De volgende PolyBase-instellingen worden ondersteund onder polyBaseSettings kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| rejectValue | Hiermee geeft u het aantal of percentage rijen op dat kan worden geweigerd voordat de query mislukt. Meer informatie over de weigeringsopties van PolyBase in de sectie Argumenten van CREATE EXTERNAL TABLE (Transact-SQL). Toegestane waarden zijn 0 (standaard), 1, 2, enzovoort. |
Nee |
| rejectType | Hiermee geeft u op of de optie rejectValue een letterlijke waarde of een percentage is. Toegestane waarden zijn Waarde (standaard) en Percentage. |
Nee |
| rejectSampleValue | Bepaalt het aantal rijen dat moet worden opgehaald voordat PolyBase het percentage geweigerde rijen opnieuw berekent. Toegestane waarden zijn 1, 2, enzovoort. |
Ja, als het rejectType percentage is. |
| useTypeDefault | Hiermee geeft u op hoe ontbrekende waarden in tekstbestanden met scheidingstekens moeten worden verwerkt wanneer PolyBase gegevens ophaalt uit het tekstbestand. Meer informatie over deze eigenschap vindt u in de sectie Argumenten in CREATE EXTERNAL FILE FORMAT (Transact-SQL). Toegestane waarden zijn Waar en Onwaar (standaard). |
Nee |
Directe kopie met behulp van PolyBase
Azure Synapse Analytics PolyBase ondersteunt rechtstreeks Azure Blob en Azure Data Lake Storage Gen2. Als uw brongegevens voldoen aan de criteria die in deze sectie worden beschreven, gebruikt u PolyBase om rechtstreeks vanuit het brongegevensarchief naar Azure Synapse Analytics te kopiëren. Gebruik anders gefaseerde kopie met behulp van PolyBase.
Tip
Als u gegevens efficiënt naar Azure Synapse Analytics wilt kopiëren, kunt u met Azure Data Factory nog eenvoudiger en handiger inzichten uit gegevens ontdekken wanneer u Data Lake Store gebruikt met Azure Synapse Analytics.
Als niet aan de vereisten wordt voldaan, controleert de service de instellingen en wordt automatisch teruggezet naar het BULKINSERT-mechanisme voor de gegevensverplaatsing.
De gekoppelde bronservice heeft de volgende typen en verificatiemethoden:
Ondersteund type brongegevensarchief Ondersteund type bronverificatie Azure Blob Verificatie van accountsleutels, door het systeem toegewezen beheerde identiteitverificatie Azure Data Lake Storage Gen2 Verificatie van accountsleutels, door het systeem toegewezen beheerde identiteitverificatie Belangrijk
- Wanneer u verificatie van beheerde identiteiten gebruikt voor uw gekoppelde opslagservice, leert u de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2 .
- Als uw Azure Storage is geconfigureerd met een VNet-service-eindpunt, moet u verificatie voor beheerde identiteiten gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg de impact van het gebruik van VNet-service-eindpunten met Azure Storage.
De brongegevensindeling is van Parquet-, ORC- of gescheiden tekst, met de volgende configuraties:
- Mappad bevat geen jokertekenfilter.
- De bestandsnaam is leeg of verwijst naar één bestand. Als u de bestandsnaam met jokertekens opgeeft in de kopieeractiviteit, kan dit alleen
*of*.*. rowDelimiteris standaard, \n, \r\n of \r.nullValueis ingesteld op een lege tekenreeks (') entreatEmptyAsNullwordt ingesteld als standaard of ingesteld op true.encodingNameis standaard ingesteld of ingesteld op utf-8.quoteChar,escapeCharenskipLineCountzijn niet opgegeven. PolyBase biedt ondersteuning voor het overslaan van veldnamenrij, die kan worden geconfigureerd alsfirstRowAsHeader.compressionkan geen compressie,GZipof deflate zijn.
Als uw bron een map is,
recursivemoet in kopieeractiviteit worden ingesteld op waar.wildcardFolderPath, ,wildcardFilenamemodifiedDateTimeStart,modifiedDateTimeEnd, ,prefixenenablePartitionDiscoveryadditionalColumnszijn niet opgegeven.
Notitie
Als uw bron een map is, ziet u dat PolyBase bestanden ophaalt uit de map en alle bijbehorende submappen, en er worden geen gegevens opgehaald uit bestanden waarvoor de bestandsnaam begint met een onderstreping (_) of een punt (.), zoals hier wordt beschreven - LOCATION-argument.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
Gefaseerde kopie met behulp van PolyBase
Wanneer uw brongegevens niet systeemeigen compatibel zijn met PolyBase, schakelt u het kopiëren van gegevens in via een tussentijdse fasering van Azure Blob of Azure Data Lake Storage Gen2 (dit kan geen Azure Premium Storage zijn). In dit geval converteert de service de gegevens automatisch om te voldoen aan de vereisten voor gegevensindeling van PolyBase. Vervolgens wordt PolyBase aangeroepen om gegevens te laden in Azure Synapse Analytics. Ten slotte worden uw tijdelijke gegevens uit de opslag opgeschoond. Zie Gefaseerde kopie voor meer informatie over het kopiëren van gegevens via een fasering.
Als u deze functie wilt gebruiken, maakt u een gekoppelde Azure Blob Storage-service of een gekoppelde Azure Data Lake Storage Gen2-service met accountsleutel of beheerde identiteitsverificatie die verwijst naar het Azure-opslagaccount als tussentijdse opslag.
Belangrijk
- Wanneer u verificatie van beheerde identiteiten gebruikt voor uw gekoppelde faseringsservice, leert u de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2 . U moet ook machtigingen verlenen aan uw beheerde identiteit van uw Azure Synapse Analytics-werkruimte in uw faserings-Azure Blob Storage- of Azure Data Lake Storage Gen2-account. Zie Machtigingen verlenen aan beheerde identiteiten voor werkruimten voor meer informatie over het verlenen van deze machtiging.
- Als uw faserings-Azure Storage is geconfigureerd met VNet-service-eindpunt, moet u verificatie voor beheerde identiteit gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg Impact van het gebruik van VNet-service-eindpunten met Azure Storage.
Belangrijk
Als uw faserings-Azure Storage is geconfigureerd met een beheerd privé-eindpunt en de firewall voor opslag is ingeschakeld, moet u verificatie van beheerde identiteiten gebruiken en machtigingen voor Opslagblobgegevenslezer verlenen aan de Synapse SQL Server om ervoor te zorgen dat deze toegang heeft tot de gefaseerde bestanden tijdens het laden van PolyBase.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Aanbevolen procedures voor het gebruik van PolyBase
De volgende secties bevatten naast de aanbevolen procedures die worden genoemd in Best practices voor Azure Synapse Analytics.
Vereiste databasemachtiging
Als u PolyBase wilt gebruiken, moet de gebruiker die gegevens laadt in Azure Synapse Analytics de machtiging CONTROL hebben voor de doeldatabase. Een manier om dat te bereiken is door de gebruiker toe te voegen als lid van de db_owner rol. Meer informatie over hoe u dit doet in het overzicht van Azure Synapse Analytics.
Limieten voor rijgrootte en gegevenstype
PolyBase-belastingen zijn beperkt tot rijen die kleiner zijn dan 1 MB. Het kan niet worden gebruikt om te laden in VARCHR(MAX), NVARCHAR(MAX) of VARBINARY(MAX). Zie De capaciteitslimieten van de Azure Synapse Analytics-service voor meer informatie.
Wanneer uw brongegevens rijen van meer dan 1 MB bevatten, wilt u de brontabellen mogelijk verticaal splitsen in verschillende kleine tabellen. Zorg ervoor dat de grootste grootte van elke rij niet groter is dan de limiet. De kleinere tabellen kunnen vervolgens worden geladen met behulp van PolyBase en samengevoegd in Azure Synapse Analytics.
Voor gegevens met dergelijke brede kolommen kunt u ook niet-PolyBase gebruiken om de gegevens te laden door de instelling PolyBase toestaan uit te schakelen.
Resourceklasse van Azure Synapse Analytics
Als u de best mogelijke doorvoer wilt bereiken, wijst u een grotere resourceklasse toe aan de gebruiker die gegevens laadt in Azure Synapse Analytics via PolyBase.
Problemen met PolyBase oplossen
Laden naar de kolom Decimaal
Als uw brongegevens een tekstindeling hebben of andere niet-PolyBase-compatibele winkels (met gefaseerde kopie en PolyBase) en deze lege waarde bevat die moet worden geladen in de decimale kolom van Azure Synapse Analytics, krijgt u mogelijk de volgende fout:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
De oplossing bestaat uit het opheffen van de optie Use type default (as false) in de sink voor kopieeractiviteit -> PolyBase-instellingen. 'USE_TYPE_DEFAULT' is een systeemeigen PolyBase-configuratie, die aangeeft hoe ontbrekende waarden in tekstbestanden met scheidingstekens moeten worden verwerkt wanneer PolyBase gegevens ophaalt uit het tekstbestand.
Controleer de eigenschap tableName in Azure Synapse Analytics
De volgende tabel bevat voorbeelden van het opgeven van de eigenschap tableName in de JSON-gegevensset. Er worden verschillende combinaties van schema- en tabelnamen weergegeven.
| DB-schema | Tabelnaam | eigenschap tableName JSON |
|---|---|---|
| dbo | MyTable | MyTable of dbo. MyTable of [dbo]. [MyTable] |
| dbo1 | MyTable | dbo1. MyTable of [dbo1]. [MyTable] |
| dbo | My.Table | [Mijn.Tabel] of [dbo]. [Mijn.Tabel] |
| dbo1 | My.Table | [dbo1]. [Mijn.Tabel] |
Als u de volgende fout ziet, kan het probleem de waarde zijn die u hebt opgegeven voor de eigenschap tableName . Zie de voorgaande tabel voor de juiste manier om waarden op te geven voor de eigenschap tableName JSON.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
Kolommen met standaardwaarden
Op dit moment accepteert de functie PolyBase alleen hetzelfde aantal kolommen als in de doeltabel. Een voorbeeld is een tabel met vier kolommen waarin een van deze kolommen is gedefinieerd met een standaardwaarde. De invoergegevens moeten nog steeds vier kolommen bevatten. Een invoergegevensset met drie kolommen levert een fout op die vergelijkbaar is met het volgende bericht:
All columns of the table must be specified in the INSERT BULK statement.
De NULL-waarde is een speciale vorm van de standaardwaarde. Als de kolom nullable is, zijn de invoergegevens in de blob voor die kolom mogelijk leeg. Maar deze kan niet ontbreken in de invoergegevensset. PolyBase voegt NULL in voor ontbrekende waarden in Azure Synapse Analytics.
Toegang tot extern bestand is mislukt
Als u de volgende fout krijgt, moet u ervoor zorgen dat u gebruikmaakt van verificatie van beheerde identiteiten en machtigingen voor Opslagblobgegevenslezer hebt verleend aan de beheerde identiteit van de Azure Synapse-werkruimte.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
Zie Machtigingen verlenen aan beheerde identiteit na het maken van de werkruimte voor meer informatie.
Eigenschappen van toewijzingsgegevensstroom
Wanneer u gegevens transformeert in de toewijzingsgegevensstroom, kunt u tabellen lezen en schrijven vanuit Azure Synapse Analytics. Zie de brontransformatie en sinktransformatie in toewijzingsgegevensstromen voor meer informatie.
Brontransformatie
Instellingen die specifiek zijn voor Azure Synapse Analytics zijn beschikbaar op het tabblad Bronopties van de brontransformatie.
Invoer Selecteren of u de bron naar een tabel (equivalent van Select * from <table-name>) verwijst of een aangepaste SQL-query invoert.
Fasering inschakelen. Het wordt ten zeerste aanbevolen deze optie te gebruiken in productieworkloads met Azure Synapse Analytics-bronnen. Wanneer u een gegevensstroomactiviteit uitvoert met Azure Synapse Analytics-bronnen uit een pijplijn, wordt u gevraagd om een opslagaccount voor een faseringslocatie en wordt dit gebruikt voor het laden van gefaseerde gegevens. Het is het snelste mechanisme om gegevens uit Azure Synapse Analytics te laden.
- Wanneer u verificatie van beheerde identiteiten gebruikt voor uw gekoppelde opslagservice, leert u de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2 .
- Als uw Azure Storage is geconfigureerd met een VNet-service-eindpunt, moet u verificatie voor beheerde identiteiten gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg de impact van het gebruik van VNet-service-eindpunten met Azure Storage.
- Wanneer u een serverloze SQL-pool van Azure Synapse als bron gebruikt, wordt fasering niet ondersteund.
Query: Als u Query selecteert in het invoerveld, voert u een SQL-query voor uw bron in. Met deze instelling wordt elke tabel overschreven die u in de gegevensset hebt gekozen. Order By-componenten worden hier niet ondersteund, maar u kunt een volledige SELECT FROM-instructie instellen. U kunt ook door de gebruiker gedefinieerde tabelfuncties gebruiken. select * from udfGetData() is een UDF in SQL die een tabel retourneert. Met deze query wordt een brontabel geproduceerd die u in uw gegevensstroom kunt gebruiken. Het gebruik van query's is ook een uitstekende manier om rijen te verminderen voor testen of opzoekacties.
SQL-voorbeeld: Select * from MyTable where customerId > 1000 and customerId < 2000
Batchgrootte: Voer een batchgrootte in om grote gegevens te segmenteren in leesbewerkingen. In gegevensstromen wordt deze instelling gebruikt om caching van Spark-kolommen in te stellen. Dit is een optieveld, dat standaardinstellingen van Spark gebruikt als deze leeg blijft.
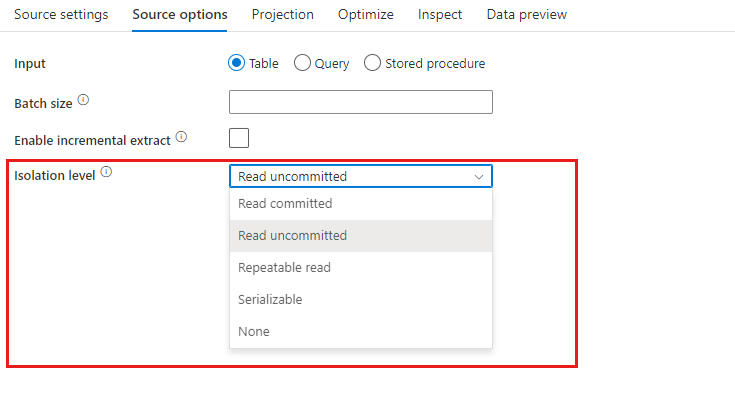
Isolatieniveau: de standaardinstelling voor SQL-bronnen in de toewijzingsgegevensstroom wordt niet-verzonden. U kunt hier het isolatieniveau wijzigen in een van deze waarden:
- Vastgelegd lezen
- Niet-verzonden lezen
- Herhaalbare leesbewerking
- Serialiseerbaar
- Geen (isolatieniveau negeren)
Sinktransformatie
Instellingen die specifiek zijn voor Azure Synapse Analytics zijn beschikbaar op het tabblad Instellingen van de sinktransformatie.
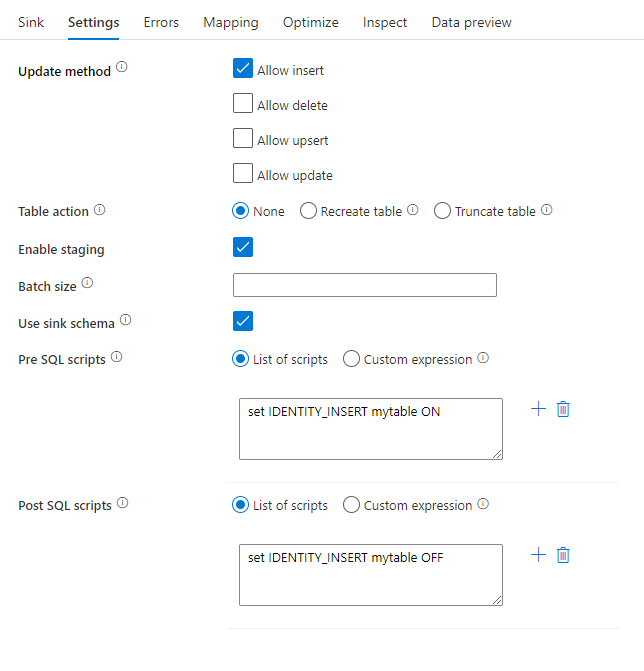
Updatemethode: bepaalt welke bewerkingen zijn toegestaan op uw databasebestemming. De standaardinstelling is om alleen invoegingen toe te staan. Als u rijen wilt bijwerken, upsert of verwijderen, is een transformatie met alter-row vereist om rijen voor deze acties te taggen. Voor updates, upserts en verwijderingen moet een sleutelkolom of -kolommen worden ingesteld om te bepalen welke rij moet worden gewijzigd.
Tabelactie: bepaalt of alle rijen opnieuw moeten worden gemaakt of verwijderd uit de doeltabel voordat u gaat schrijven.
- Geen: Er wordt geen actie uitgevoerd voor de tabel.
- Opnieuw maken: de tabel wordt verwijderd en opnieuw gemaakt. Vereist als u dynamisch een nieuwe tabel maakt.
- Afkappen: alle rijen uit de doeltabel worden verwijderd.
Fasering inschakelen: Hiermee kunt u laden in Azure Synapse Analytics SQL-pools met behulp van de kopieeropdracht en wordt aanbevolen voor de meeste Synapse-sinks. De faseringsopslag is geconfigureerd in de activiteit Execute Gegevensstroom.
- Wanneer u verificatie van beheerde identiteiten gebruikt voor uw gekoppelde opslagservice, leert u de benodigde configuraties voor respectievelijk Azure Blob en Azure Data Lake Storage Gen2 .
- Als uw Azure Storage is geconfigureerd met een VNet-service-eindpunt, moet u verificatie voor beheerde identiteiten gebruiken met 'Vertrouwde Microsoft-service toestaan' ingeschakeld voor het opslagaccount. Raadpleeg de impact van het gebruik van VNet-service-eindpunten met Azure Storage.
Batchgrootte: bepaalt hoeveel rijen er in elke bucket worden geschreven. Grotere batchgrootten verbeteren compressie en geheugenoptimalisatie, maar risico op geheugenuitzonderingen bij het opslaan van gegevens in de cache.
Sinkschema gebruiken: standaard wordt er een tijdelijke tabel gemaakt onder het sinkschema als fasering. U kunt ook de optie Sink-schema gebruiken uitschakelen en in plaats daarvan een schemanaam opgeven waaronder Data Factory een faseringstabel maakt om upstreamgegevens te laden en deze automatisch op te schonen na voltooiing. Zorg ervoor dat u een tabelmachtiging hebt gemaakt in de database en dat u de machtiging voor het schema wijzigt.

Pre- en post-SQL-scripts: voer SQL-scripts met meerdere regels in die worden uitgevoerd vóór (voorverwerking) en na (naverwerking) gegevens naar uw Sink-database worden geschreven
Tip
- Het is raadzaam om scripts met één batch met meerdere opdrachten in meerdere batches te splitsen.
- Alleen DDL-instructies (Data Definition Language) en DML-instructies (Data Definition Language) die een eenvoudig aantal updates retourneren, kunnen worden uitgevoerd als onderdeel van een batch. Meer informatie over het uitvoeren van batchbewerkingen
Verwerking van foutrijen
Bij het schrijven naar Azure Synapse Analytics kunnen bepaalde rijen met gegevens mislukken vanwege beperkingen die zijn ingesteld door de bestemming. Enkele veelvoorkomende fouten zijn:
- Tekenreeks- of binaire gegevens worden afgekapt in tabel
- Kan de waarde NULL niet invoegen in kolom
- Conversie is mislukt bij het converteren van de waarde naar het gegevenstype
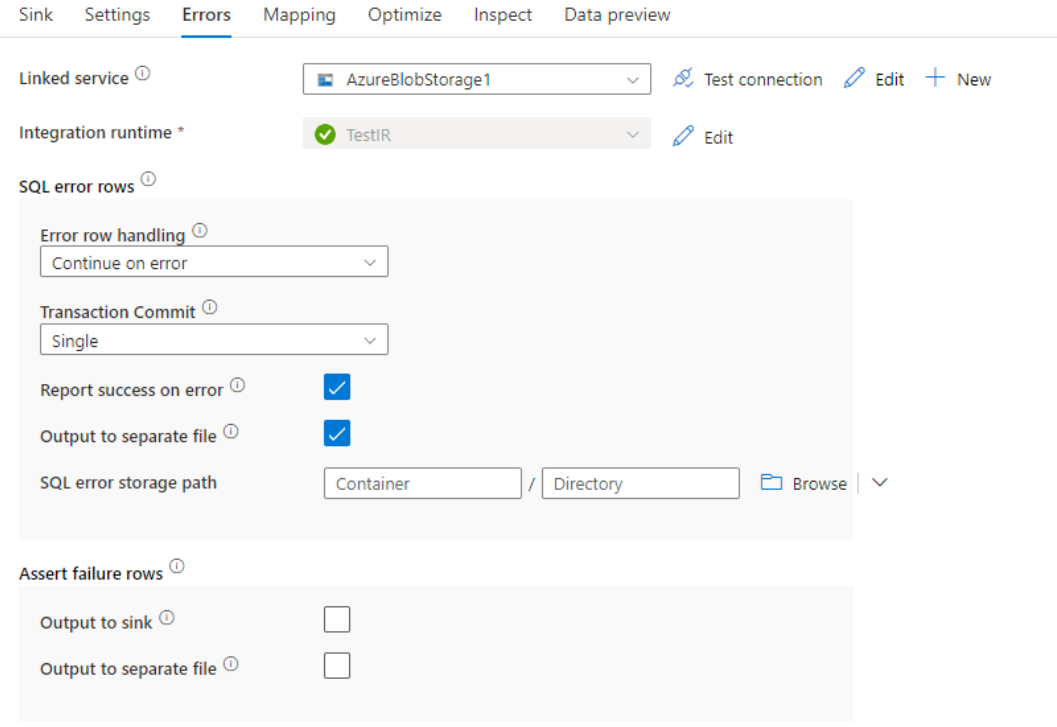
Standaard mislukt een uitvoering van een gegevensstroom bij de eerste fout die deze krijgt. U kunt ervoor kiezen om door te gaan op een fout waarmee uw gegevensstroom kan worden voltooid, zelfs als afzonderlijke rijen fouten hebben. De service biedt verschillende opties voor het afhandelen van deze foutrijen.
Transactiedoorvoering: kies of uw gegevens worden geschreven in één transactie of in batches. Eén transactie biedt betere prestaties en er zijn geen gegevens zichtbaar voor anderen totdat de transactie is voltooid. Batch-transacties hebben slechtere prestaties, maar kunnen werken voor grote gegevenssets.
Geweigerde uitvoergegevens: als deze optie is ingeschakeld, kunt u de foutrijen uitvoeren in een CSV-bestand in Azure Blob Storage of een Azure Data Lake Storage Gen2-account van uw keuze. Hiermee worden de foutrijen met drie extra kolommen geschreven: de SQL-bewerking zoals INSERT of UPDATE, de foutcode van de gegevensstroom en het foutbericht in de rij.
Geslaagd melden bij fout: als deze optie is ingeschakeld, wordt de gegevensstroom gemarkeerd als geslaagd, zelfs als er foutrijen worden gevonden.
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Eigenschappen van GetMetadata-activiteit
Als u meer wilt weten over de eigenschappen, controleert u de Activiteit GetMetadata
Toewijzing van gegevenstypen voor Azure Synapse Analytics
Wanneer u gegevens kopieert van of naar Azure Synapse Analytics, worden de volgende toewijzingen gebruikt van Azure Synapse Analytics-gegevenstypen naar tussentijdse gegevenstypen van Azure Data Factory. Deze toewijzingen worden ook gebruikt bij het kopiëren van gegevens van of naar Azure Synapse Analytics met behulp van Synapse-pijplijnen, omdat pijplijnen ook Azure Data Factory in Azure Synapse implementeren. Zie schema- en gegevenstypetoewijzingen voor meer informatie over hoe kopieeractiviteit het bronschema en het gegevenstype toewijst aan de sink.
Tip
Raadpleeg het artikel Tabelgegevenstypen in Azure Synapse Analytics in ondersteunde gegevenstypen van Azure Synapse Analytics en de tijdelijke oplossingen voor niet-ondersteunde gegevenstypen.
| Azure Synapse Analytics-gegevenstype | Tussentijds gegevenstype Data Factory |
|---|---|
| bigint | Int64 |
| binair | Byte[] |
| bit | Booleaanse waarde |
| char | Tekenreeks, Teken[] |
| datum | Datum en tijd |
| Datum/tijd | DateTime |
| datetime2 | Datum en tijd |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM-kenmerk (varbinary(max)) | Byte[] |
| Float | Dubbel |
| image | Byte[] |
| int | Int32 |
| money | Decimal |
| nchar | Tekenreeks, Teken[] |
| numeriek | Decimal |
| nvarchar | Tekenreeks, Teken[] |
| werkelijk | Eén |
| rowversion | Byte[] |
| smalldatetime | Datum en tijd |
| smallint | Int16 |
| smallmoney | Decimal |
| tijd | TimeSpan |
| tinyint | Byte |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | Tekenreeks, Teken[] |
De Versie van Azure Synapse Analytics upgraden
Als u de Versie van Azure Synapse Analytics wilt upgraden, selecteert u Aanbevolen onder Versie op de pagina Gekoppelde service bewerken en configureert u de gekoppelde service door te verwijzen naar de eigenschappen van de gekoppelde service voor de aanbevolen versie.
Verschillen tussen de aanbevolen en de verouderde versie
In de onderstaande tabel ziet u de verschillen tussen Azure Synapse Analytics met behulp van de aanbevolen en de verouderde versie.
| Aanbevolen versie | Verouderde versie |
|---|---|
Ondersteuning voor TLS 1.3 via encrypt as strict. |
TLS 1.3 wordt niet ondersteund. |
Gerelateerde inhoud
Zie ondersteunde gegevensarchieven en -indelingen voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door Kopieeractiviteit.