Aanbevolen procedures voor het schrijven naar bestanden naar Data Lake met gegevensstromen
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Zie Inleiding tot Azure Data Factory als u niet bekend bent met Azure Data Factory.
In deze zelfstudie leert u aanbevolen procedures die kunnen worden toegepast bij het schrijven van bestanden naar ADLS Gen2 of Azure Blob Storage met behulp van gegevensstromen. U hebt toegang nodig tot een Azure Blob Storage-account of Een Azure Data Lake Store Gen2-account voor het lezen van een Parquet-bestand en het opslaan van de resultaten in mappen.
Vereisten
- Azure-abonnement. Als u nog geen abonnement op Azure hebt, maakt u een gratis Azure-account voordat u begint.
- Azure-opslagaccount. U gebruikt ADLS-opslag als bron- en sinkgegevensopslag. Als u geen opslagaccount hebt, raadpleegt u het artikel Een opslagaccount maken om een account te maken.
Bij de stappen in deze zelfstudie wordt ervan uitgegaan dat u
Een data factory maken
In deze stap maakt u een data factory en opent u de Data Factory UX om een pijplijn in de data factory te maken.
Open Microsoft Edge of Google Chrome. Momenteel wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Selecteer een resourceintegratiegegevensfactory>>maken in het linkermenu
Voer op de pagina Nieuwe data factory, onder Naam, ADFTutorialDataFactory in
Selecteer het Azure-abonnement waarin u de data factory wilt maken.
Voer een van de volgende stappen uit voor Resourcegroep:
a. Selecteer Bestaande gebruiken en selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
b. Selecteer Nieuwe maken en voer de naam van een resourcegroep in. Zie Resourcegroepen gebruiken om uw Azure-resources te beheren voor meer informatie over resourcegroepen.
Selecteer V2 onder Versie.
Selecteer onder Locatie een locatie voor de data factory. In de vervolgkeuzelijst worden alleen ondersteunde locaties weergegeven. Gegevensarchieven (bijvoorbeeld Azure Storage en SQL Database) en berekeningen (bijvoorbeeld Azure HDInsight) die door de data factory worden gebruikt, kunnen zich in andere regio's bevinden.
Selecteer Maken.
Als het maken is voltooid, ziet u de melding in het meldingencentrum. Selecteer Naar resource gaan om naar de pagina Data factory te gaan.
Selecteer de tegel Maken en controleren om de Data Factory-gebruikersinterface te openen op een afzonderlijk tabblad.
Een pijplijn maken met een gegevensstroomactiviteit
In deze stap maakt u een pijplijn die een gegevensstroomactiviteit bevat.
Selecteer Orchestrate op de startpagina van Azure Data Factory.
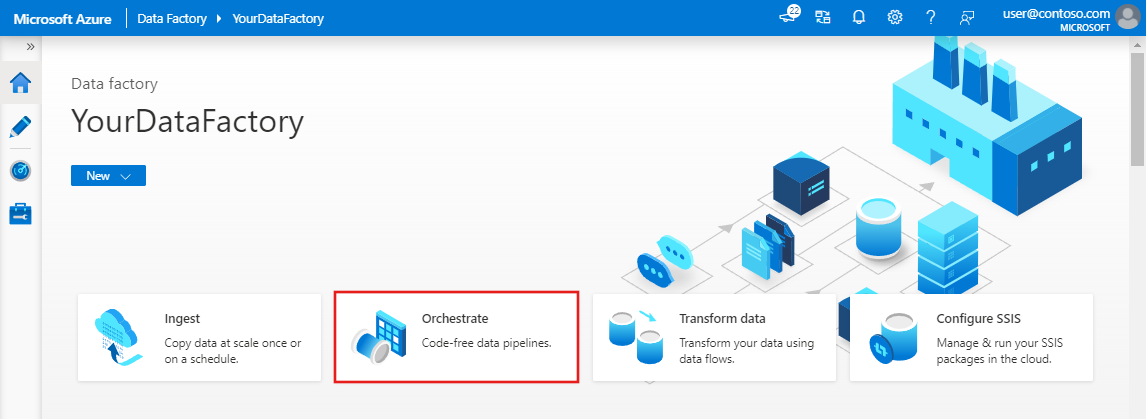
Voer op het tabblad Algemeen voor de pijplijn DeltaLake in voor de naam van de pijplijn.
Schuif in de bovenste balk van de fabriek de Gegevensstroom schuifregelaar voor foutopsporing aan. Met de foutopsporingsmodus kunt u interactieve transformatielogica testen op een live Spark-cluster. Gegevensstroom clusters 5-7 minuten duren en gebruikers worden aangeraden eerst foutopsporing in te schakelen als ze van plan zijn Gegevensstroom ontwikkeling uit te voeren. Zie De foutopsporingsmodus voor meer informatie.

Vouw in het deelvenster Activiteiten de accordeon Verplaatsen en Transformeren uit. Sleep de Gegevensstroom activiteit van het deelvenster naar het pijplijncanvas en zet deze neer.
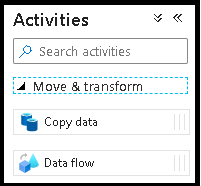
Selecteer in het pop-upvenster Toevoegen Gegevensstroom nieuwe Gegevensstroom maken en geef uw gegevensstroom een naam deltalake. Klik op Voltooien wanneer u klaar bent.
Transformatielogica bouwen in het gegevensstroomcanvas
U neemt alle brongegevens (in deze zelfstudie gebruiken we een Parquet-bestandsbron) en gebruiken we een sinktransformatie om de gegevens in Parquet-indeling te landen met behulp van de meest effectieve mechanismen voor data lake ETL.

Zelfstudiedoelstellingen
- Kies een van uw brongegevenssets in een nieuwe gegevensstroom 1. Gegevensstromen gebruiken om uw sinkgegevensset effectief te partitioneren
- Uw gepartitioneerde gegevens in ADLS Gen2 Lake-mappen plaatsen
Beginnen met een leeg gegevensstroomcanvas
Eerst gaan we de gegevensstroomomgeving instellen voor elk van de mechanismen die hieronder worden beschreven voor landingsgegevens in ADLS Gen2
- Klik op de brontransformatie.
- Klik op de nieuwe knop naast de gegevensset in het onderste deelvenster.
- Kies een gegevensset of maak een nieuwe. Voor deze demo gebruiken we een Parquet-gegevensset met de naam Gebruikersgegevens.
- Voeg een afgeleide kolomtransformatie toe. We gebruiken dit als een manier om de gewenste mapnamen dynamisch in te stellen.
- Voeg een sinktransformatie toe.
Uitvoer van hiërarchische map
Het is heel gebruikelijk om unieke waarden in uw gegevens te gebruiken om maphiërarchieën te maken om uw gegevens in de lake te partitioneren. Dit is een zeer optimale manier om gegevens in de lake en in Spark te organiseren en te verwerken (de rekenengine achter gegevensstromen). Er zijn echter kleine prestatiekosten om uw uitvoer op deze manier te organiseren. Verwacht een kleine afname van de algehele pijplijnprestaties met behulp van dit mechanisme in de sink.
- Ga terug naar de ontwerpfunctie voor gegevensstromen en bewerk de bovenstaande gegevensstroom. Klik op de sinktransformatie.
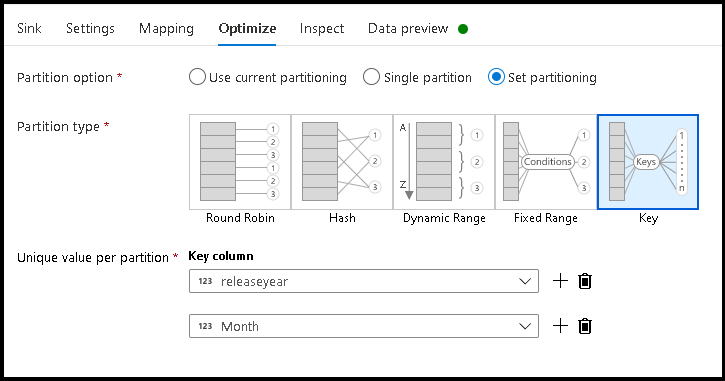
- Klik op Partitioneringssleutel instellen optimaliseren >>
- Kies de kolommen die u wilt gebruiken om de hiërarchische mapstructuur in te stellen.
- In het onderstaande voorbeeld worden jaar en maand gebruikt als de kolommen voor mapnaamgeving. De resultaten worden mappen van het formulier
releaseyear=1990/month=8. - Wanneer u de gegevenspartities in een gegevensstroombron opent, wijst u alleen de map op het hoogste niveau hierboven
releaseyearaan en gebruikt u een jokertekenpatroon voor elke volgende map, bijvoorbeeld:**/**/*.parquet - Als u de gegevenswaarden wilt bewerken of zelfs als u synthetische waarden voor mapnamen wilt genereren, gebruikt u de transformatie Afgeleide kolom om de waarden te maken die u in de mapnamen wilt gebruiken.
Map een naam opgeven als gegevenswaarden
Een iets beter presterende sinktechniek voor lake-gegevens met ADLS Gen2 die niet hetzelfde voordeel biedt als partitionering van sleutel/waarde, is Name folder as column data. Terwijl u met de sleutelpartitioneringsstijl van hiërarchische structuur gegevenssegmenten eenvoudiger kunt verwerken, is deze techniek een platgemaakte mapstructuur waarmee gegevens sneller kunnen worden geschreven.
- Ga terug naar de ontwerpfunctie voor gegevensstromen en bewerk de bovenstaande gegevensstroom. Klik op de sinktransformatie.
- Klik op Partities > instellen optimaliseren > Gebruik de huidige partitionering.
- Klik op Instellingen > map Naam als kolomgegevens.
- Kies de kolom die u wilt gebruiken voor het genereren van mapnamen.
- Als u de gegevenswaarden wilt bewerken of zelfs als u synthetische waarden voor mapnamen wilt genereren, gebruikt u de transformatie Afgeleide kolom om de waarden te maken die u in de mapnamen wilt gebruiken.
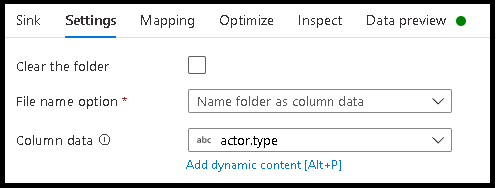
Naambestand als gegevenswaarden
De technieken die worden vermeld in de bovenstaande zelfstudies zijn goede use cases voor het maken van mapcategorieën in uw Data Lake. Het standaardschema voor naamgeving van bestanden dat door deze technieken wordt gebruikt, is het gebruik van de Spark-uitvoertaak-id. Soms wilt u mogelijk de naam van het uitvoerbestand instellen in een tekstsink voor gegevensstromen. Deze techniek wordt alleen voorgesteld voor gebruik met kleine bestanden. Het proces voor het samenvoegen van partitiebestanden in één uitvoerbestand is een langlopend proces.
- Ga terug naar de ontwerpfunctie voor gegevensstromen en bewerk de bovenstaande gegevensstroom. Klik op de sinktransformatie.
- Klik op Set partitionering met > één partitie optimaliseren>. Dit is deze vereiste voor één partitie die een knelpunt in het uitvoeringsproces creëert wanneer bestanden worden samengevoegd. Deze optie wordt alleen aanbevolen voor kleine bestanden.
- Klik op Instellingen > naambestand als kolomgegevens.
- Kies de kolom die u wilt gebruiken voor het genereren van bestandsnamen.
- Als u de gegevenswaarden wilt bewerken of zelfs als u synthetische waarden voor bestandsnamen wilt genereren, gebruikt u de transformatie Afgeleide kolom om de waarden te maken die u wilt gebruiken in uw bestandsnamen.
Gerelateerde inhoud
Meer informatie over sinks voor gegevensstromen.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor