Incrementeel laden van gegevens vanuit Azure SQL Managed Instance naar Azure Storage met behulp van change data capture (CDC)
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie maakt u een Azure data factory met een pijplijn die gewijzigde gegevens laadt op basis van informatie over change data capture (CDC) in de Azure SQL Managed Instance-brondatabase naar Azure Blob Storage.
In deze zelfstudie voert u de volgende stappen uit:
- Voorbereiden van de bron-gegevensopslag
- Een data factory maken.
- Maak gekoppelde services.
- Maak bron- en sinkgegevenssets.
- De pijplijn maken, fouten erin opsporen en uitvoeren om te controleren op gewijzigde gegevens
- Gegevens in de brontabel wijzigen
- De volledige pijplijn voor incrementeel kopiëren voltooien, uitvoeren en bewaken
Overzicht
De change data capture-technologie die wordt ondersteund door gegevensarchieven zoals Azure SQL Managed Instance en SQL Server kunnen worden gebruikt voor het identificeren van gewijzigde gegevens. In deze zelfstudie wordt beschreven hoe u met Azure Data Factory kunt gebruikmaken van SQL change data capture-technologie voor het incrementeel laden van wijzigingsgegevens uit Azure SQL Managed Instance naar Azure Blob Storage. Zie Change Data Capture in SQL Server voor meer concrete informatie over SQL change data capture-technologie.
End-to-end werkstroom
Hier zijn de gangbare end-to-end werkstroomstappen voor het incrementeel laden van gegevens met behulp van change data capture-technologie.
Notitie
Zowel Azure SQL MI als SQL Server ondersteunen de change data capture-technologie. In deze zelfstudie wordt Azure SQL Managed Instance gebruikt als de gegevensopslagbron. U kunt ook een lokale SQL Server gebruiken.
Oplossingen op hoog niveau
In deze zelfstudie maakt u een pijplijn waarmee de volgende bewerkingen worden uitgevoerd:
- Maak een opzoekactiviteit om het aantal gewijzigde records in de SQL Database CDC-tabel te tellen en door te geven aan een IF Condition-activiteit.
- Maak een If Condition om te controleren of er gewijzigde records zijn. Als dat zo is, roept u de kopieeractiviteit op.
- Maak een Kopieeractiviteit om de ingevoegde/bijgewerkte/verwijderde gegevens te kopiëren van de CDC-tabel naar Azure Blob Storage.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- Azure SQL Managed Instance. U gebruikt de database als de brongegevensopslag. Als u geen beheerd exemplaar van Azure SQL hebt, raadpleegt u het artikel Een beheerd exemplaar voor Azure SQL Database maken voor stappen om er een te maken.
- Azure Storage-account. U gebruikt de Blob-opslag als de sinkgegevensopslag. Als u geen Azure-opslagaccount hebt, raadpleegt u het artikel Een opslagaccount maken om een account te maken. Maak een container met de naam raw.
Een gegevensbrontabel maken in Azure SQL Database
Start SQL Server Management Studio en maak verbinding met uw Azure SQL Managed Instance-server.
Klik in Server Explorer met de rechtermuisknop op de database en kies de Nieuwe query.
Voer de volgende SQL-opdracht uit voor de Azure SQL Managed Instance-database om een tabel met de naam
customerste maken als gegevensbronopslag.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Schakel Change data capture in uw database en de brontabel (customers) in door de volgende SQL-query uit te voeren:
Notitie
- Vervang <de naam van het bronschema> door het schema van Azure SQL MI met de tabel 'customers'.
- Change data capture doet niets als onderdeel van de transacties die de getraceerde tabel wijzigen. In plaats daarvan worden de invoeg-, update- en verwijderbewerkingen naar het transactielogboek geschreven. Gegevens die in wijzigingstabellen worden neergezet, worden onbeheerbaar als u de gegevens niet regelmatig verwijdert. Zie voor meer informatie Enable Change Data Capture for a database (Change data capture voor een database inschakelen)
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Voeg gegevens in de tabel 'customers' in door de volgende opdracht uit te voeren:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Notitie
Er worden geen historische wijzigingen van de tabel vastgelegd voordat change data capture wordt ingeschakeld.
Een data factory maken
Volg de stappen in de quickstart van het artikel : Een gegevensfactory maken met behulp van Azure Portal om een data factory te maken als u er nog geen hebt om mee te werken.
Gekoppelde services maken
U maakt gekoppelde services in een gegevensfactory om uw gegevensarchieven en compute-services aan de gegevensfactory te koppelen. In deze sectie maakt u gekoppelde services in het Azure Storage-account en de Azure SQL MI.
Maak een gekoppelde Azure Storage-service.
Tijdens deze stap koppelt u uw Azure Storage-account aan de data factory.
Klik op Connections en klik op + New.
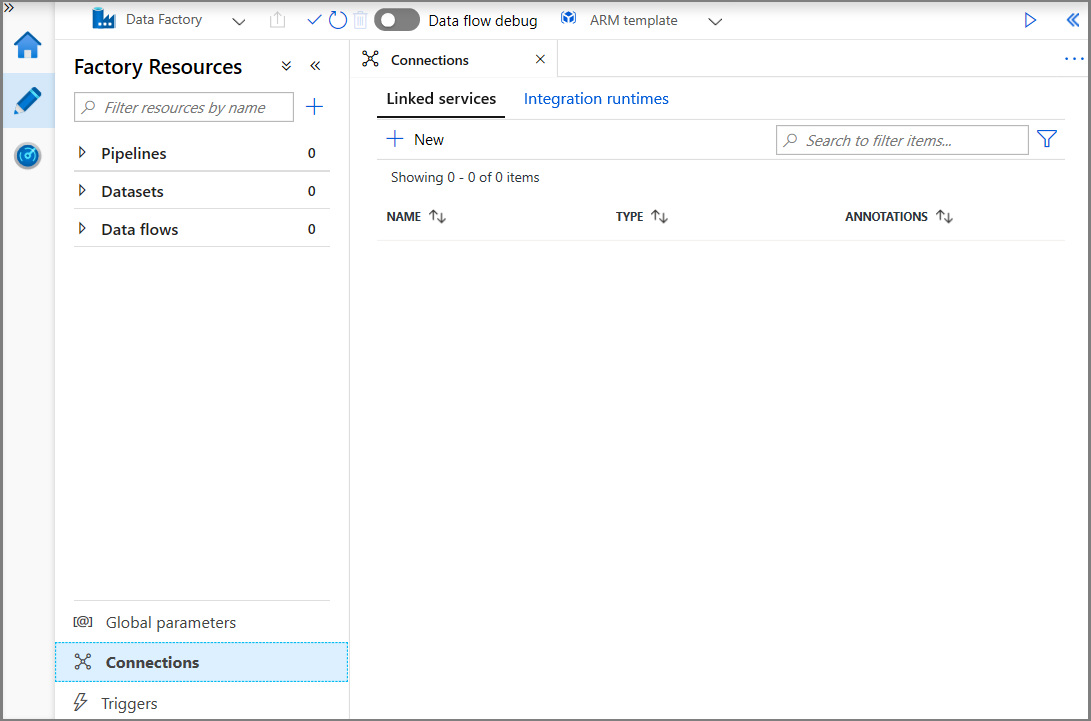
In het venster New Linked Service selecteert u Azure Blob Storage en klikt u op Continue.
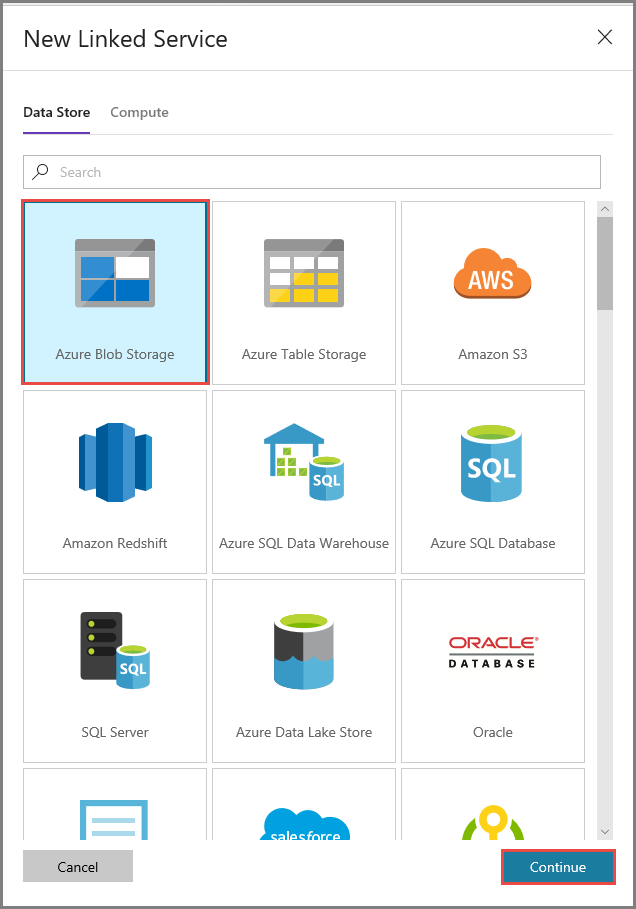
Voer in het venster New Linked Service de volgende stappen uit:
- Voer AzureStorageLinkedService in als Naam.
- Selecteer uw Azure Storage-account bij Storage account name.
- Klik op Opslaan.
Maak een gekoppelde Azure SQL MI-databaseservice.
In deze stap koppelt u uw Azure SQL MI-database aan de data factory.
Notitie
Hier vindt u informatie over toegang via openbare en privé-eindpunten voor SQL MI-gebruikers. Als u een privé-eindpunt gebruikt, moet u deze pijplijn uitvoeren met een zelf-hostende Information Runtime. Hetzelfde geldt voor degenen die SQL Server on-premises gebruiken, in een VM- of VNet-scenario.
Klik op Connections en klik op + New.
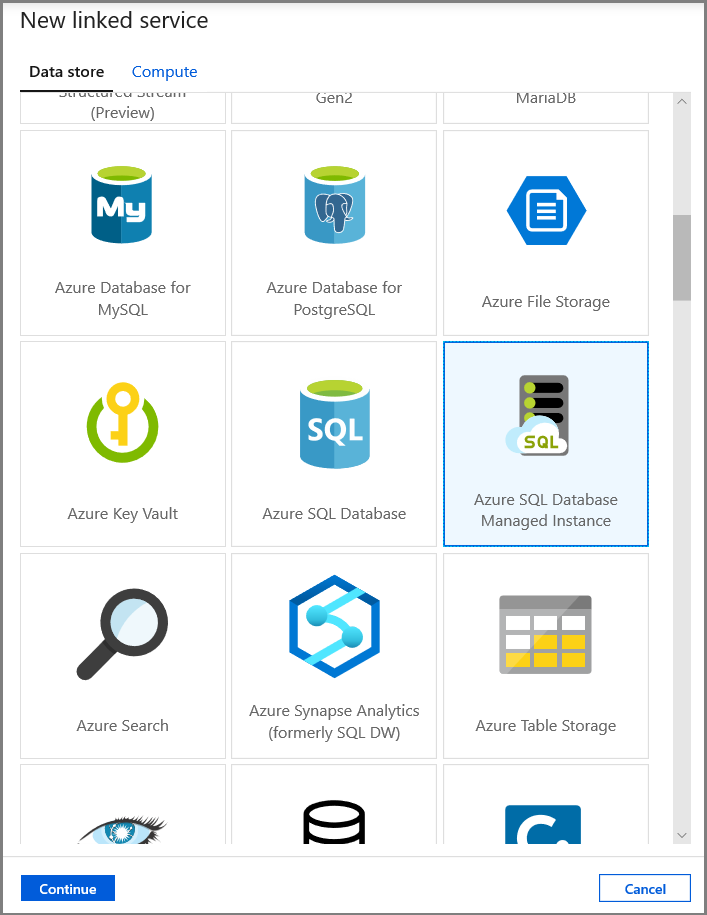
In het venster Nieuwe gekoppelde service selecteert u Azure SQL Database Managed Instance en klikt u op Doorgaan.
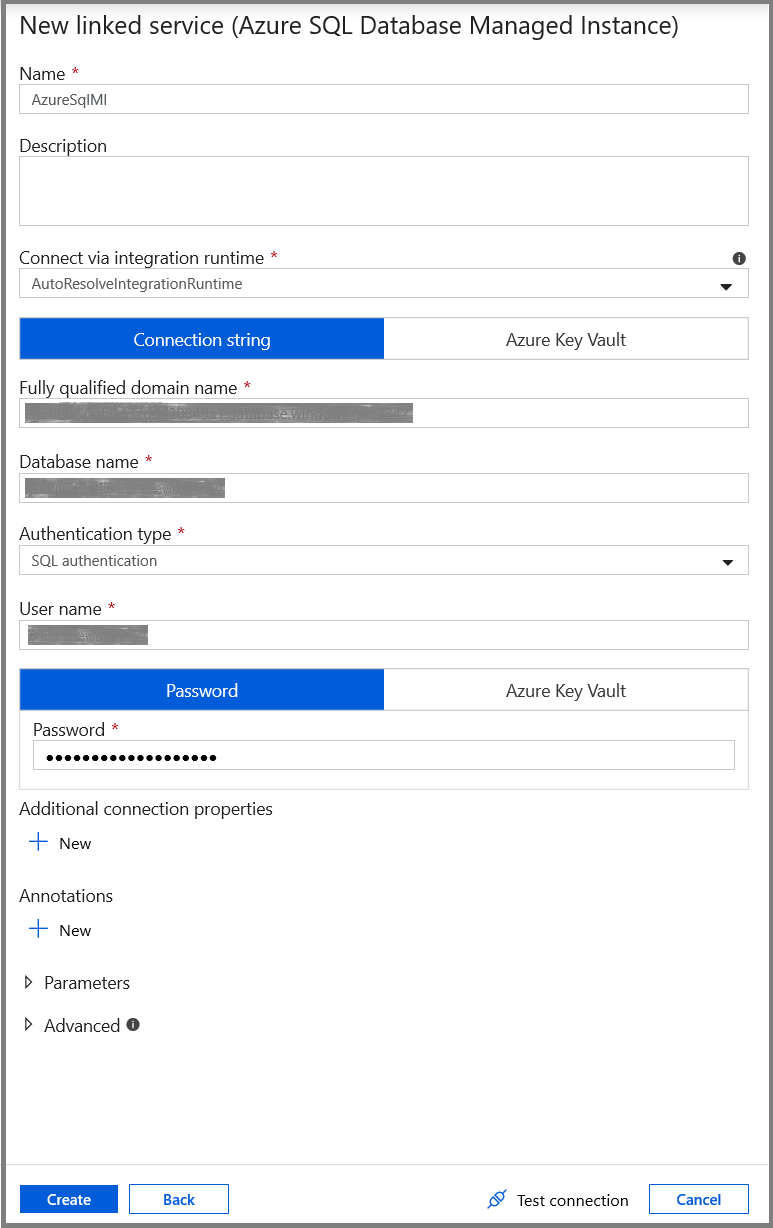
Voer in het venster New Linked Service de volgende stappen uit:
- Voer AzureSqlMI1 in het veld Naam in.
- Selecteer uw SQL-server in het veld Servernaam.
- Selecteer uw SQL-database in het veld Databasenaam.
- Voer de gebruikersnaam in bij Gebruikersnaam.
- Voer het wachtwoord voor de gebruiker in bij Wachtwoord.
- Als u de verbinding wilt testen, klikt u op Verbinding testen.
- Klik op Save om de gekoppelde service op te slaan.
Gegevenssets maken
In deze stap maakt u gegevenssets die voor de gegevensbron en -bestemming staan.
Een gegevensset maken om brongegevens weer te geven
In deze stap maakt u een gegevensset die de brongegevens vertegenwoordigt.
Klik in de structuurweergave op + (plus) en klik op Dataset.
Selecteer Azure SQL Database Managed Instance en klik op Doorgaan.
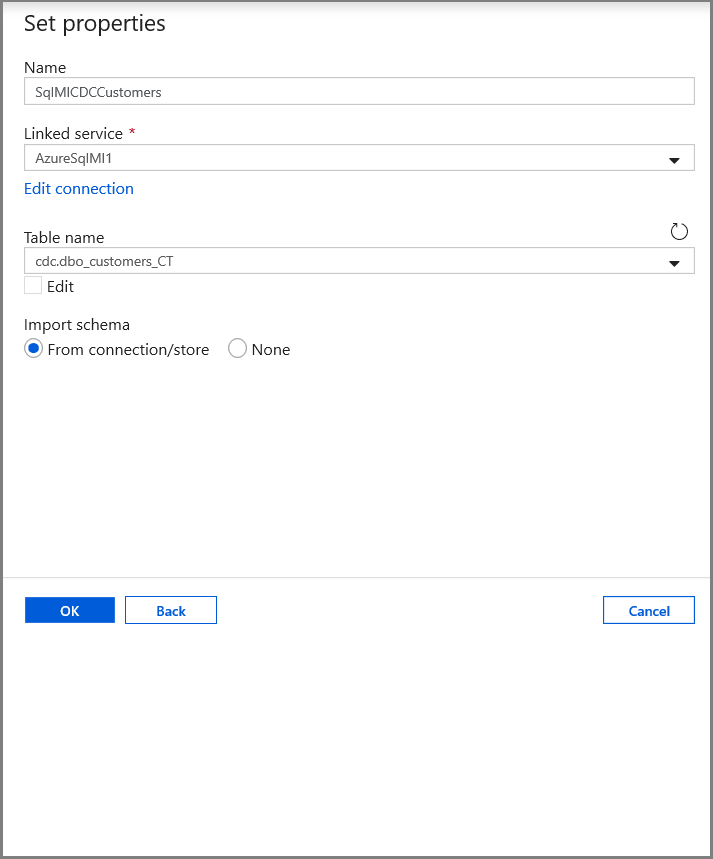
Stel op het tabblad Eigenschappen instellen de naam van de gegevensset en de verbindingsgegevens in:
- Selecteer AzureSqlMI1 bij Gekoppelde service.
- Selecteer [dbo].[dbo_customers_CT] bij Tabelnaam. Opmerking: deze tabel is automatisch gemaakt toen CDC werd ingeschakeld voor de tabel 'customers'. Gewijzigde gegevens worden nooit rechtstreeks vanuit deze tabel opgevraagd, maar worden in plaats daarvan geëxtraheerd via de CDC-functies.
Maak een gegevensset om gegevens weer te geven die zijn gekopieerd naar het sink-gegevensarchief.
In deze stap maakt u een gegevensset die de gegevens voorstelt die worden gekopieerd uit de gegevensopslag van de bron. U hebt de data lake-container gemaakt in uw Azure-blobopslag als onderdeel van de vereisten. Maak de container als deze bestaat niet (of) stel deze in op de naam van een bestaande container. In deze zelfstudie wordt de naam van het uitvoerbestand dynamisch gegenereerd met behulp van de triggertijd, die later wordt geconfigureerd.
Klik in de structuurweergave op + (plus) en klik op Dataset.
Selecteer Azure Blob Storage en klik op Doorgaan.
Selecteer DelimitedText en klik op Doorgaan.

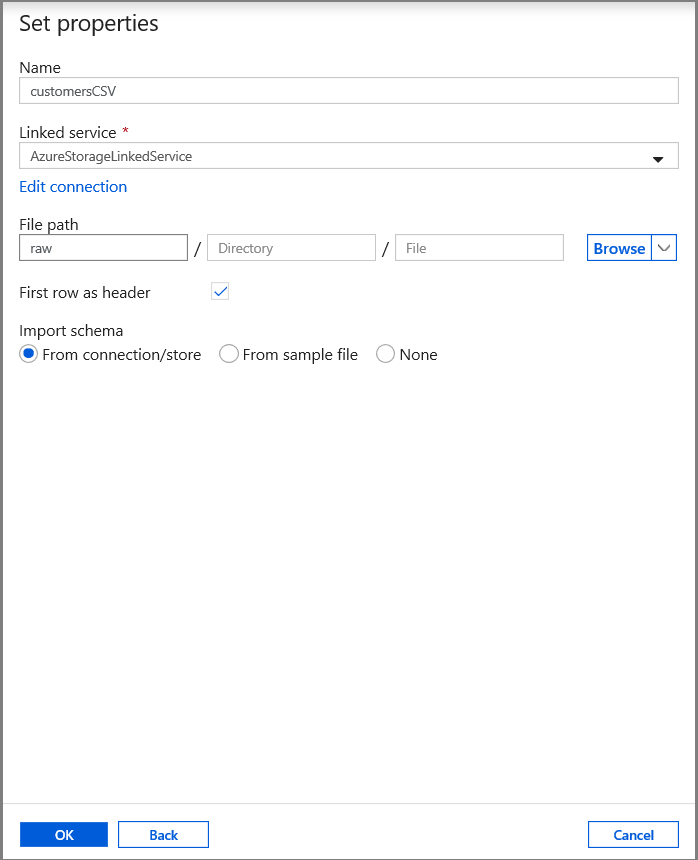
Stel op het tabblad Eigenschappen instellen de naam van de gegevensset en de verbindingsgegevens in:
- Selecteer AzureStorageLinkedService bij Linked service.
- Voer raw in voor de tegel container van het filePath.
- Schakel Eerste rij als koptekst in
- Klik op OK.
Een pijplijn maken om de gewijzigde gegevens te kopiëren
In deze stap maakt u een pijplijn, waarmee eerst het aantal gewijzigde records in de wijzigingstabel wordt gecontroleerd met behulp van een opzoekactiviteit. Een If Condition-activiteit controleert of het aantal gewijzigde records groter is dan nul en voert een kopieeractiviteit uit om de ingevoegde/bijgewerkte/verwijderde gegevens te kopiëren van Azure SQL Database naar Azure Blob Storage. Ten slotte wordt er een tumblingvenstertrigger geconfigureerd en worden de begin- en eindtijden doorgegeven aan de activiteiten als de begin- en eindparameters.
Ga in de gebruikersinterface van Data Factory naar het tabblad Bewerken . Klik op + (plus) in het linkerdeelvenster en klik op Pijplijn.

Er wordt een nieuw tabblad weergegeven voor het configureren van de pijplijn. U ziet ook de pijplijn in de structuurweergave. In het venster Properties wijzigt u de naam van de pijplijn in IncrementalCopyPipeline.
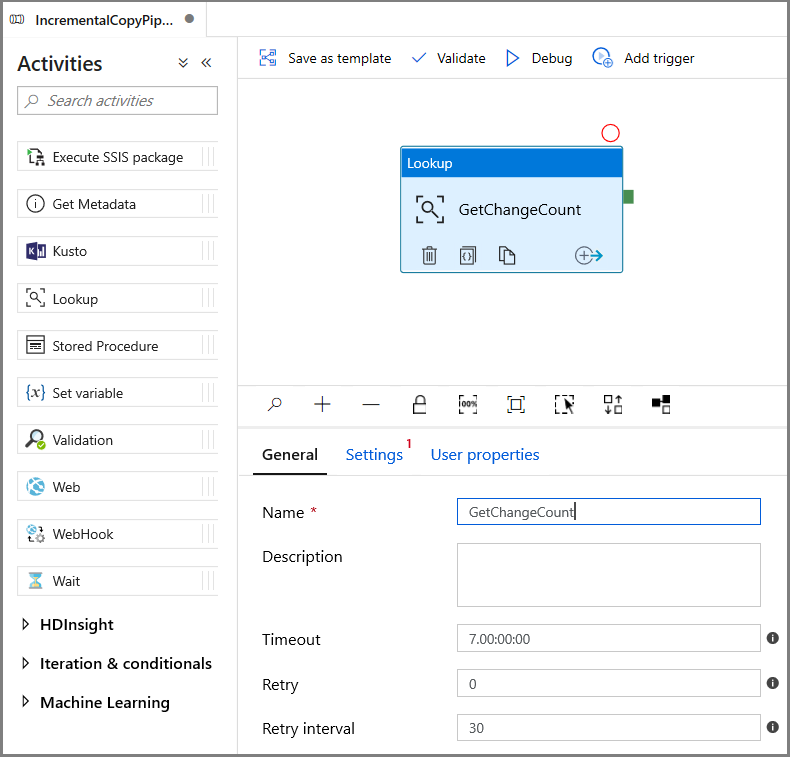
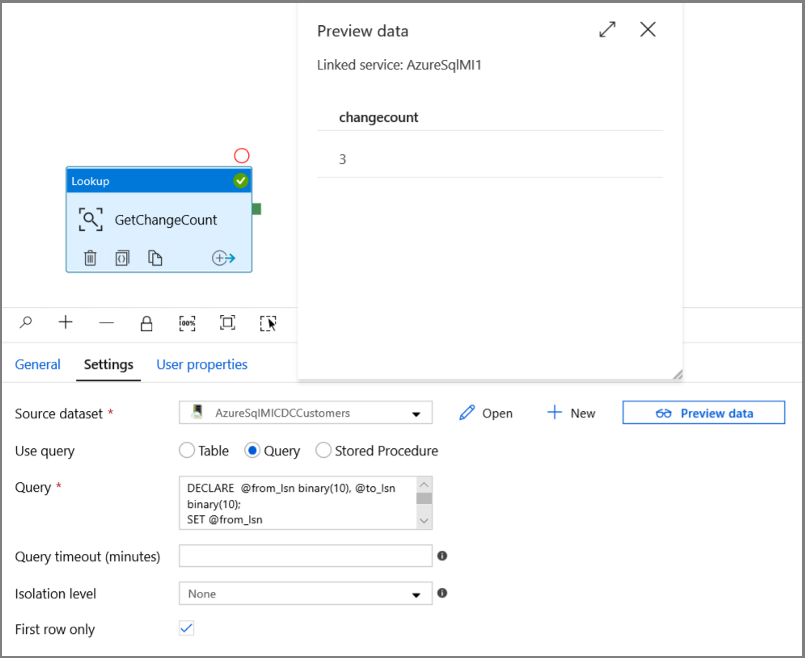
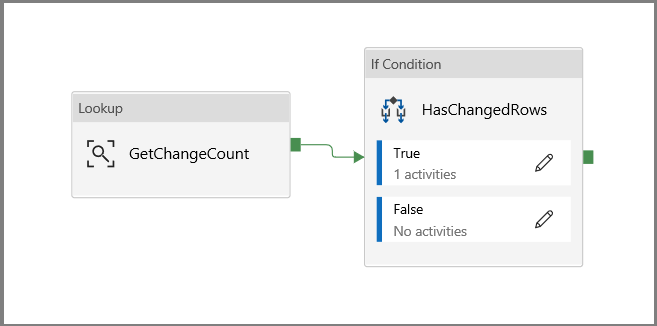
Vouw in de Activiteiten-werkset de optie Algemeen uit. Gebruik vervolgens slepen-en-neerzetten om de opzoekactiviteit te verplaatsen naar het ontwerpoppervlak voor pijplijnen. Stel de naam van de activiteit in op GetChangeCount. Met deze activiteit wordt het aantal records in de wijzigingstabel voor een bepaald tijdvenster opgehaald.
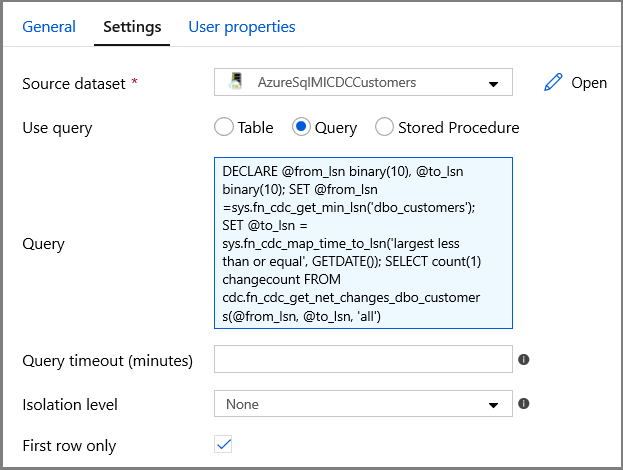
Ga naar het tabblad Instellingen in het venster Eigenschappen:
Geef de naam op van de SQL MI-gegevensset voor het veld Brongegevensset.
Selecteer de optie Query en voer het volgende in het queryvak in:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Schakel Alleen eerste rij in
Klik op de knop Preview-gegevens om te controleren of er een geldige uitvoer wordt verkregen door de opzoekactiviteit
Vouw in de werkset Activiteiten de optie Iteratie en voorwaarden uit en sleep de If Condition-activiteit naar het ontwerpoppervlak voor pijplijnen. Stel de naam van de activiteit in op HasChangedRows.
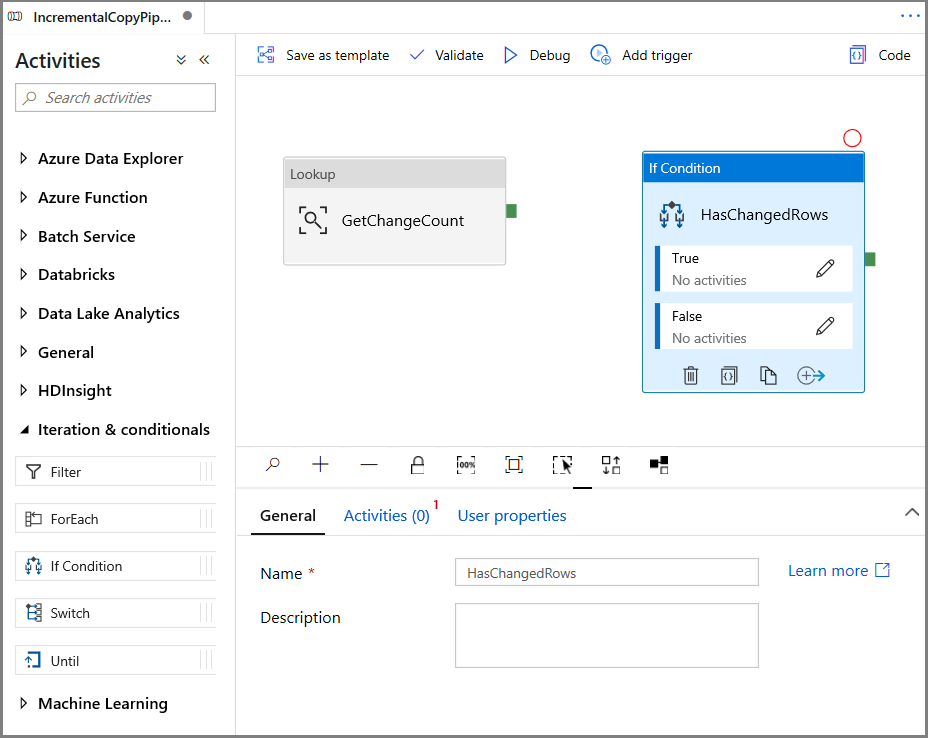
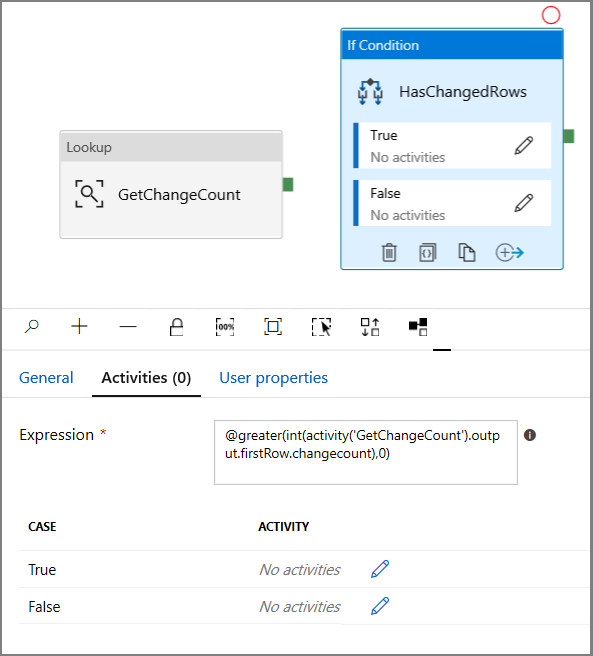
Ga in het venster Eigenschappen naar Activiteiten:
- Voer de volgende Expressie in
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Klik op het potloodpictogram om de True-voorwaarde te bewerken.
- Vouw Algemeen uit in de werkset Activiteiten. Sleep vervolgens een activiteit Wachten naar het ontwerpoppervlak voor pijplijnen. Dit is een tijdelijke activiteit voor het opsporen van fouten in de If Condition en wordt later in de zelfstudie gewijzigd.
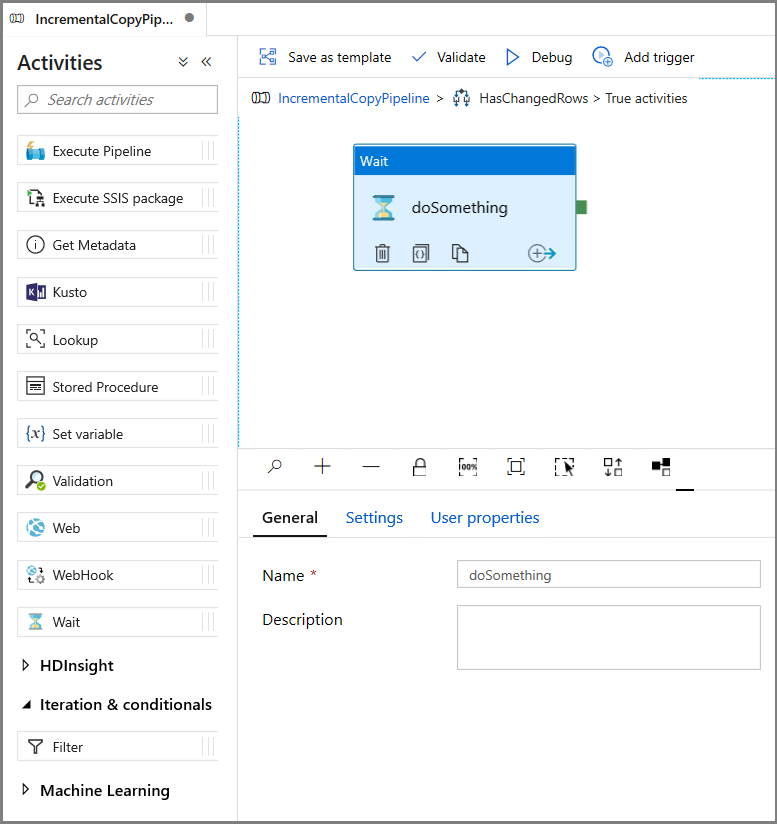
- Klik op de breadcrumb IncrementalCopyPipeline om terug te keren naar de hoofdpijplijn.
Voer de pijplijn uit in de modus Foutopsporing om te controleren of de pijplijn wordt uitgevoerd.
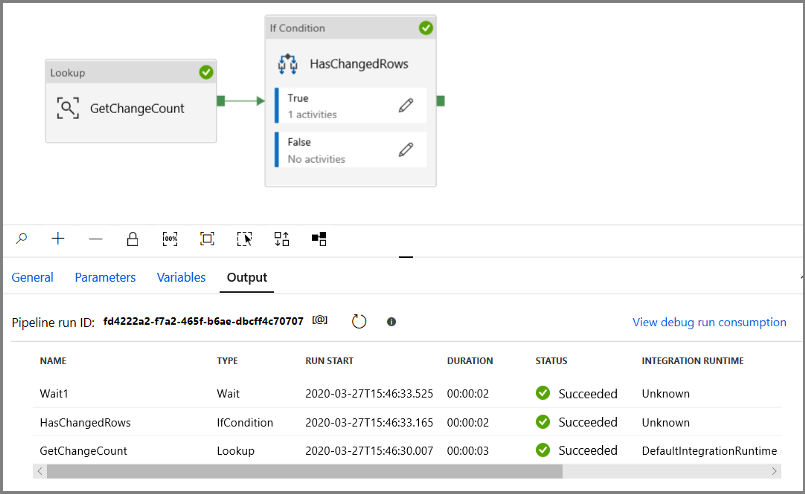
Ga vervolgens terug naar de stap met de True-voorwaarde en verwijder de activiteit Wachten. Vouw in de werkset Activiteiten de optie Verplaatsen en transformeren uit. Sleep vervolgens de Kopieeractiviteit naar het ontwerpoppervlak voor pijplijnen. Stel de naam van de activiteit in op IncrementalCopyActivity.
Ga naar Source in het venster Properties en voer de volgende stappen uit:
Geef de naam op van de SQL MI-gegevensset voor het veld Brongegevensset.
Selecteer Query bij Use Query.
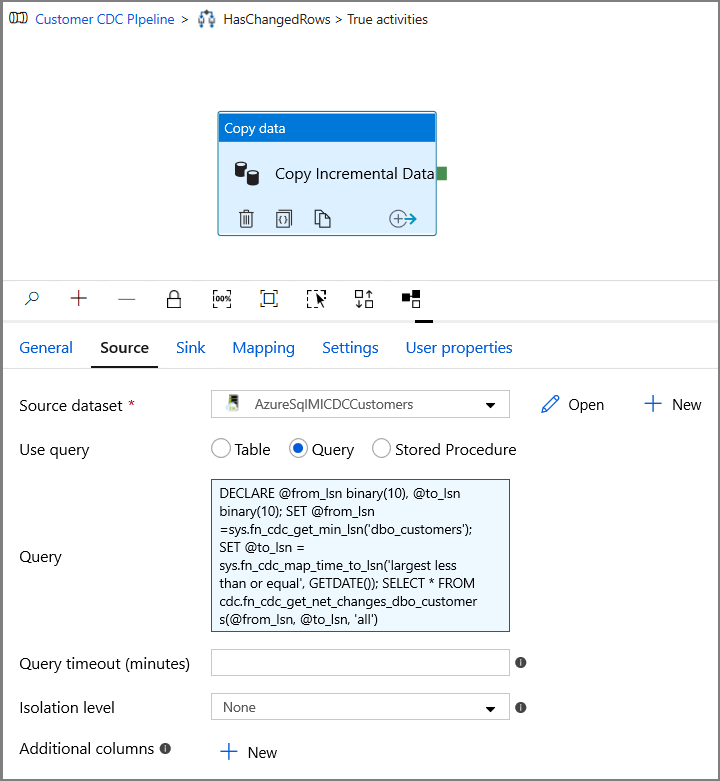
Voer het volgende in voor Query.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
Klik op preview om te controleren of de query de gewijzigde rijen correct retourneert.
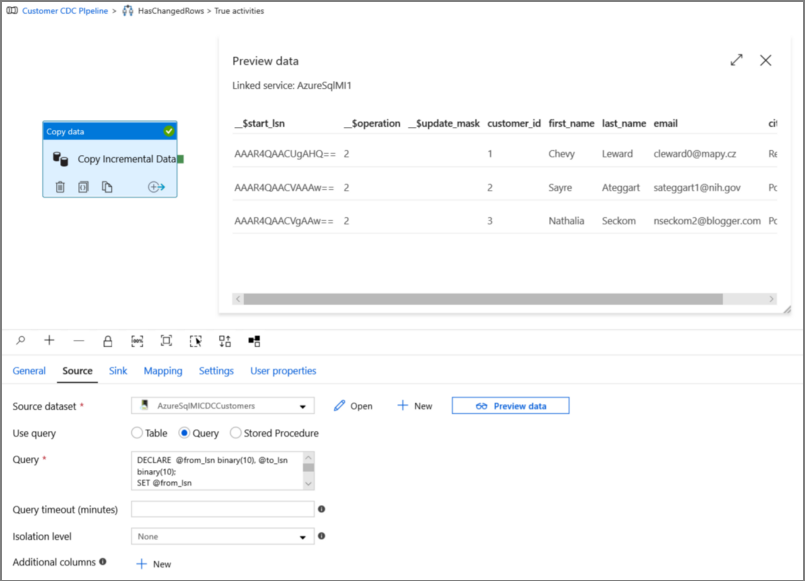
Ga naar het tabblad Sink en geef de Azure Storage-gegevensset op voor het veld Sinkgegevensset.

Klik om terug te gaan naar het canvas van de hoofdpijplijn en verbind één voor één de activiteit Opzoeken met de activiteit If Condition. Sleep de groene knop die is gekoppeld aan de activiteit Opzoeken naar de activiteit If Condition.
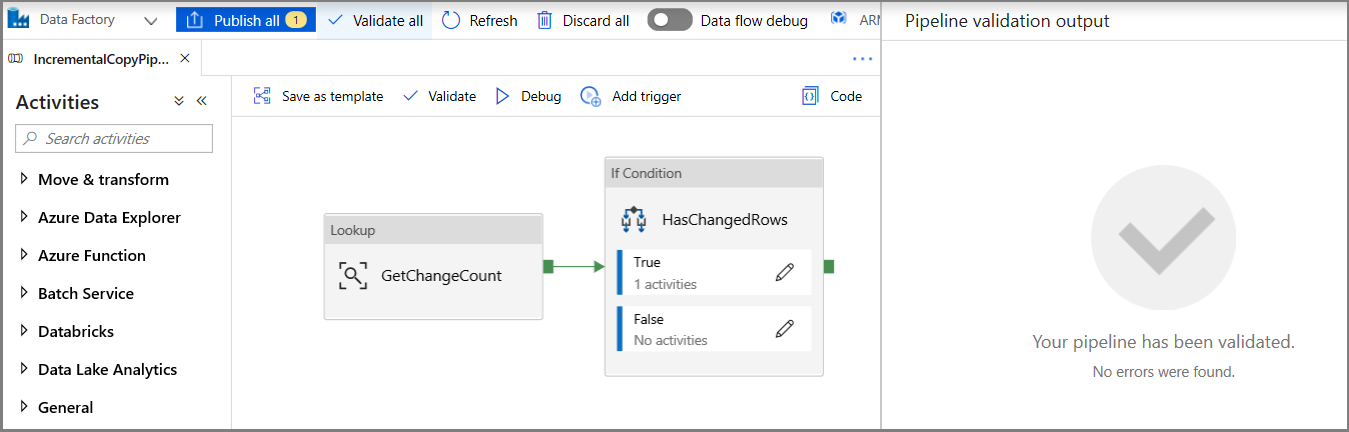
Klik op Validate op de werkbalk. Controleer of er geen validatiefouten zijn. Sluit het venster Pipeline Validation Report door op >> te klikken.
Klik op Foutopsporing om de pijplijn te testen en te controleren of er een bestand is gegenereerd op de opslaglocatie.
Publiceer entiteiten (gekoppelde services, gegevenssets en pijplijnen) naar de Data Factory-service door te klikken op de knop Alles publiceren. Wacht tot u het bericht Publishing succeeded ziet.
De tumblingvenstertrigger en de parameters van het CDC-venster configureren
In deze stap maakt u een tumblingvenstertrigger om de taak volgens een frequent schema uit te voeren. U gebruikt de systeemvariabelen WindowStart en WindowEnd van de tumblingvenstertrigger en geeft ze door als parameters aan de pijplijn die u wilt gebruiken in de CDC-query.
Ga naar het tabblad Parameters van de pijplijn IncrementalCopyPipeline en gebruik de knop + Nieuw om twee parameters (triggerStartTime en triggerEndTime) toe te voegen aan de pijplijn. Dit zijn de begin- en eindtijd van het tumblingvenster. Voor foutopsporing voegt u standaardwaarden toe in de indeling JJJJ-MM-DD HH24: MI: SS. FFF. Zorg ervoor dat de triggerStartTime niet eerder is dan wanneer CDC op de tabel is ingeschakeld, anders treedt er een fout op.
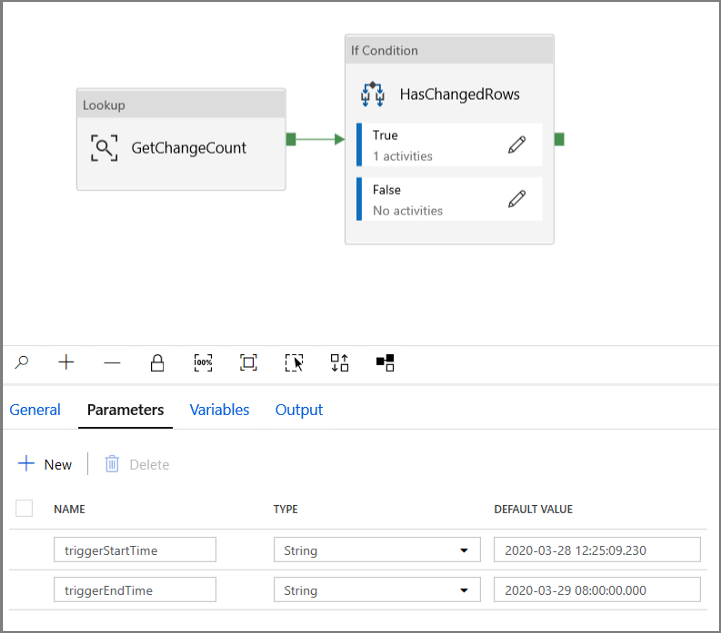
Klik op het tabblad Instellingen van de activiteit Opzoeken en configureer de query om de begin- en eindparameters te gebruiken. Kopieer het volgende naar de query:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Navigeer naar de kopieeractiviteit in het true-geval van de If Condition-activiteit en klik op het tabblad Bron . Kopieer het volgende naar de query:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Klik op het tabblad Sink van de activiteit Kopiëren en klik op Openen om de eigenschappen van de gegevensset te bewerken. Klik op het tabblad Parameters en voeg een nieuwe parameter toe met de naam triggerStart
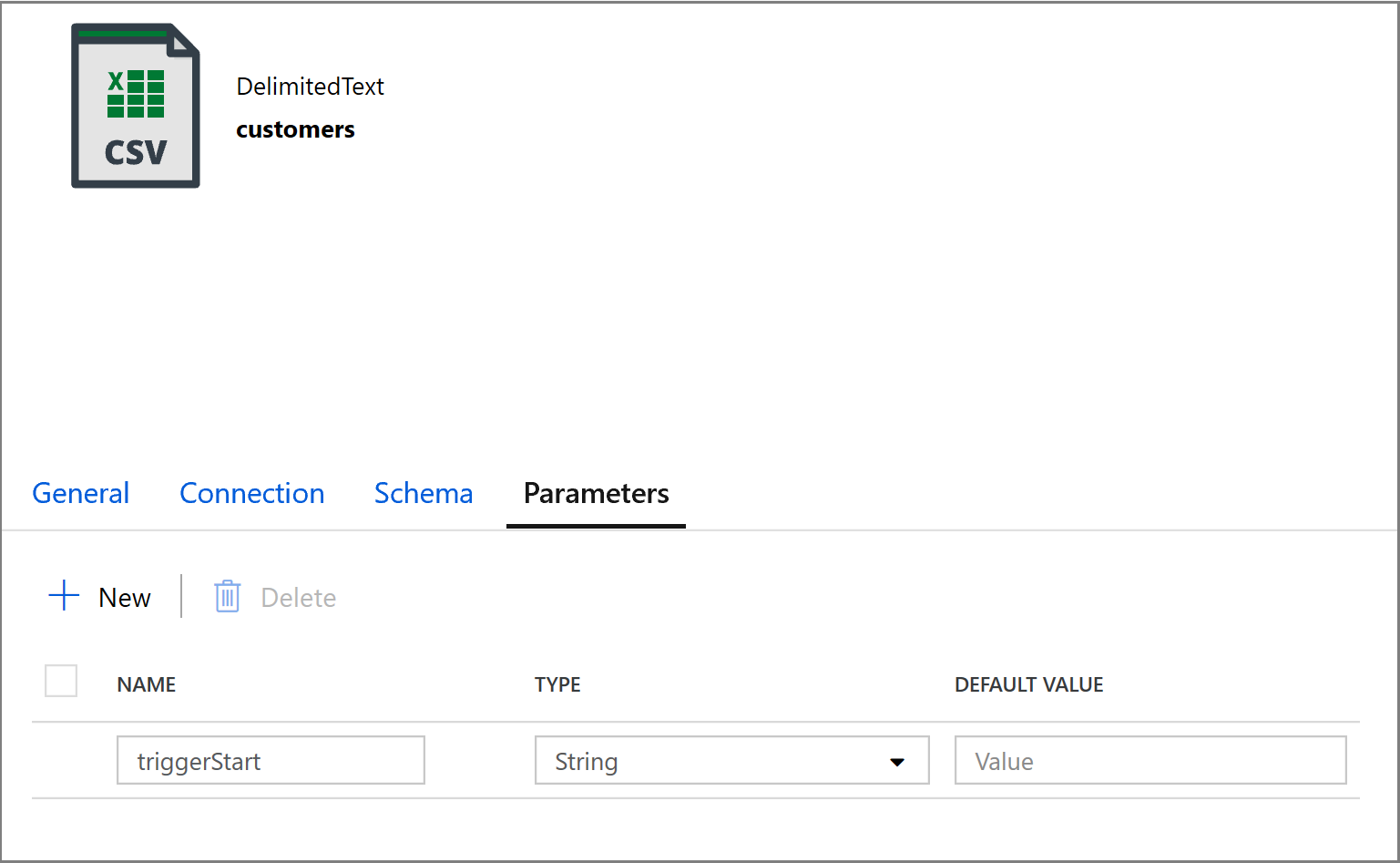
Configureer vervolgens de eigenschappen van de gegevensset om de gegevens op te slaan in een submap customers/incremental met op datums gebaseerde partities.
Klik op het tabblad Verbinding van de eigenschappen van de gegevensset en voeg dynamische inhoud toe voor de secties Map en Bestand.
Voer de volgende expressie in de sectie Map in door te klikken op de link voor dynamische inhoud onder het tekstvak:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Voer de volgende expressie in het gedeelte Bestand in. Hiermee worden bestandsnamen gemaakt op basis van de begindatum en -tijd van de trigger, en krijgen ze een achtervoegsel met de cvs-extensie:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')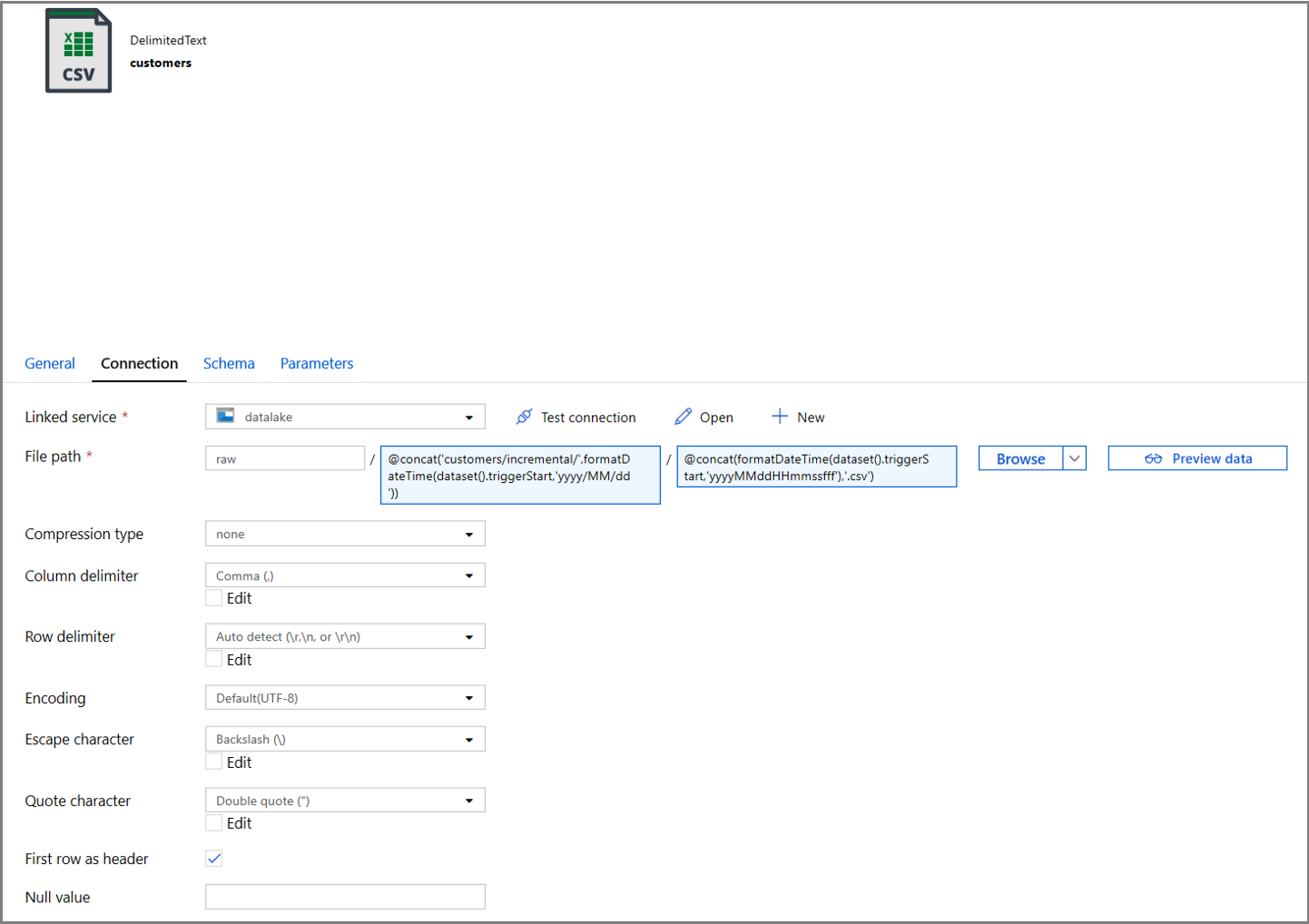
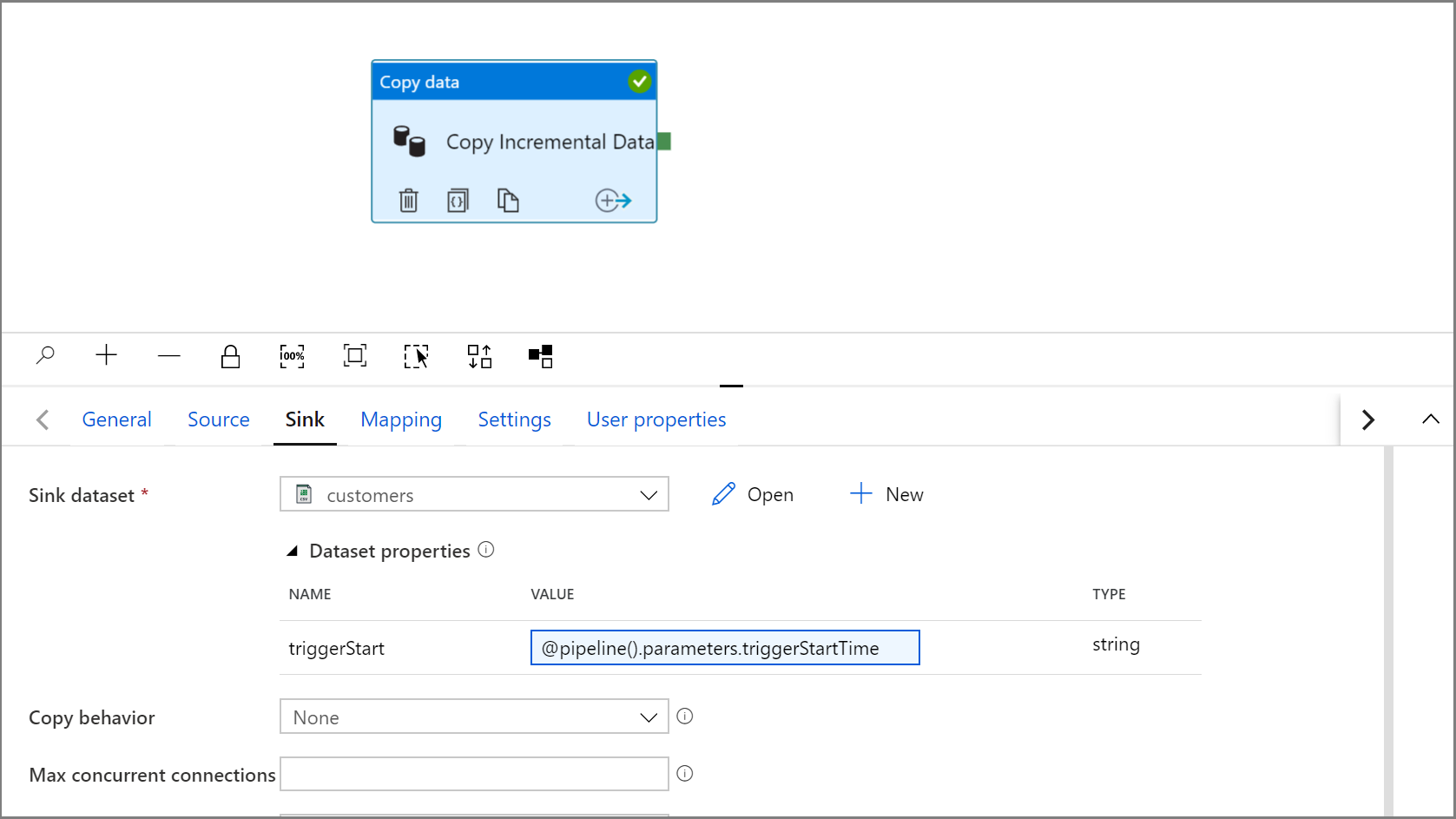
Ga terug naar de instellingen voor Sink in de activiteit Kopiëren door te klikken op het tabblad IncrementalCopyPipeline.
Vouw de eigenschappen van de gegevensset uit en voer dynamische inhoud in de parameterwaarde triggerStart in met de volgende expressie:
@pipeline().parameters.triggerStartTime
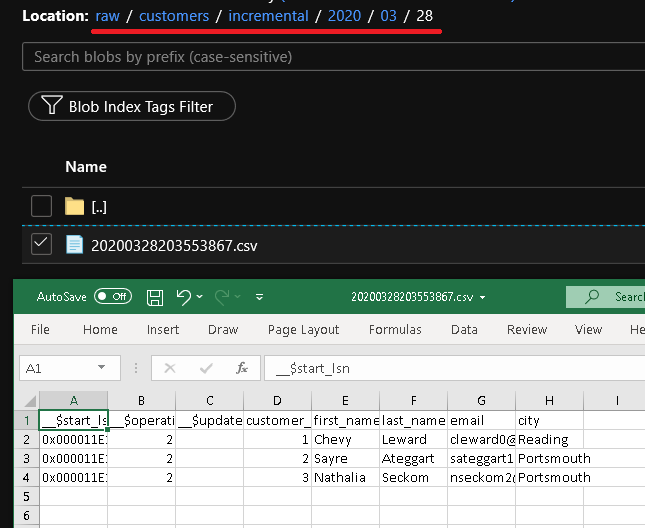
Klik op Foutopsporing om de pijplijn te testen en ervoor te zorgen dat de mapstructuur en het uitvoerbestand naar verwachting worden gegenereerd. Download en open het bestand om de inhoud te controleren.
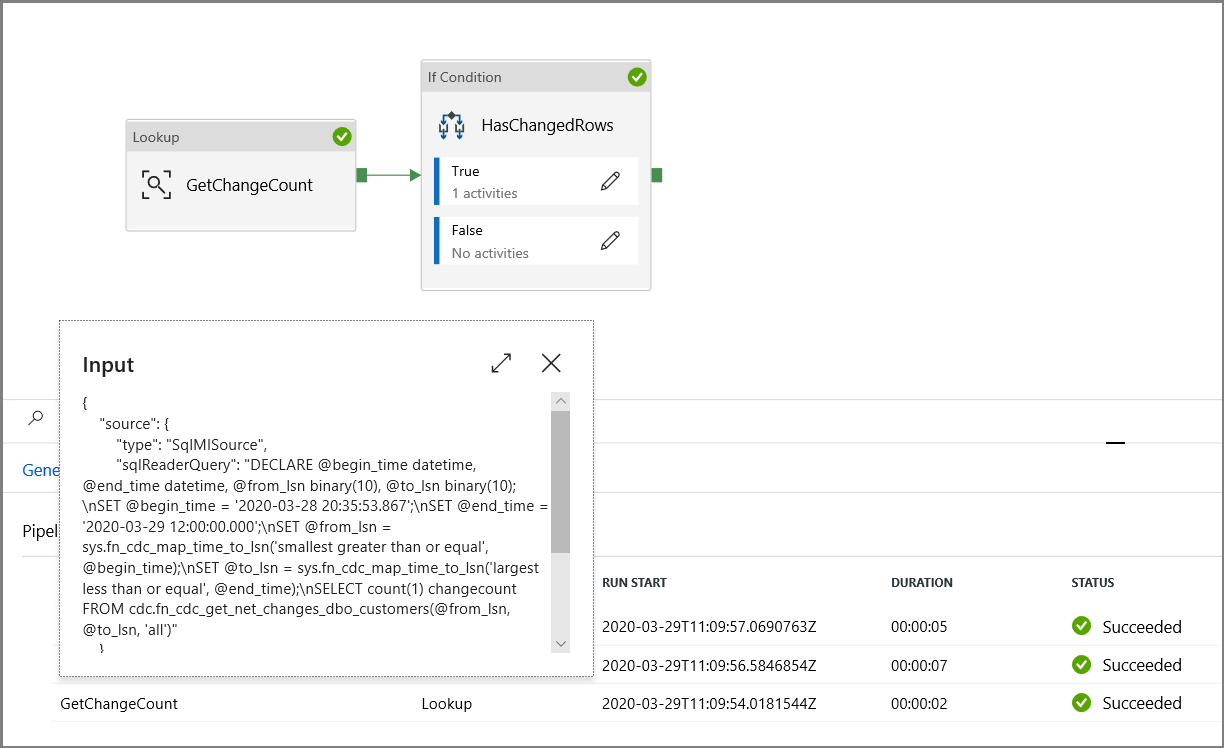
Controleer of de parameters in de query worden geïnjecteerd door de invoerparameters van de pijplijnuitvoering te bekijken.
Publiceer entiteiten (gekoppelde services, gegevenssets en pijplijnen) naar de Data Factory-service door te klikken op de knop Alles publiceren. Wacht tot u het bericht Publishing succeeded ziet.
Configureer tot slot een tumblingvenstertrigger om de pijplijn met een regelmatig interval uit te voeren en de begin- en eindparameters in te stellen.
- Klik op de knop Trigger toevoegen en selecteer Nieuw/bewerken
- Voer een naam voor de trigger in en geef een begintijd op, die gelijk is aan de eindtijd van het bovenstaande venster Foutopsporing.
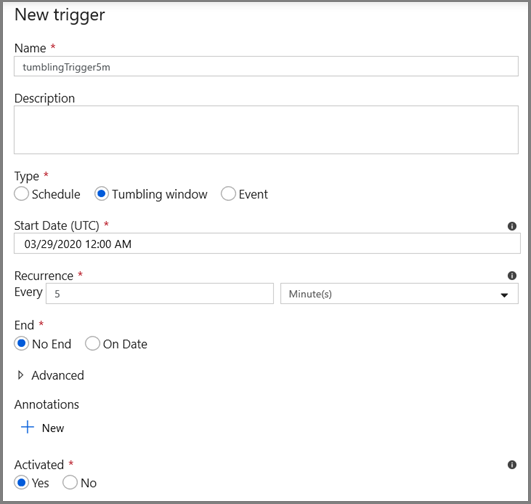
Geef in het volgende scherm respectievelijk de volgende waarden voor de begin- en eindparameters op.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')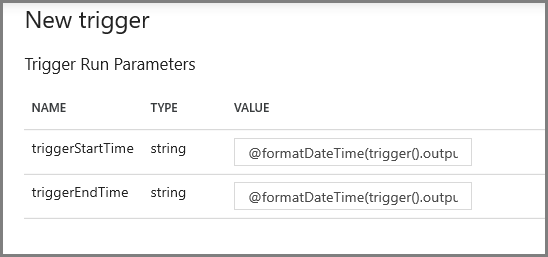
Notitie
De trigger wordt alleen uitgevoerd zodra deze is gepubliceerd. Daarnaast is het verwachte gedrag van het tumblingvenster het uitvoeren van alle historische intervallen vanaf de begindatum tot nu. Meer informatie over de tumblingvenstertriggers vindt u hier.
U kunt met behulp van SQL Server Management Studio aanvullende wijzigingen aanbrengen in de klantentabel door de volgende SQL-versie uit te voeren:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Klik op de knop Alles publiceren. Wacht tot u het bericht Publishing succeeded ziet.
Na een paar minuten wordt de pijplijn geactiveerd en wordt er een nieuw bestand geladen in Azure Storage
De pijplijn incrementele kopie bewaken
Klik op het tabblad Monitor aan de linkerkant. U ziet de pijplijnuitvoering in de lijst en de status ervan. Als u de lijst wilt vernieuwen, klikt u op Refresh. Beweeg de muisaanwijzer over de naam van de pijplijn om het actie- en verbruiksrapport opnieuw uit te voeren.
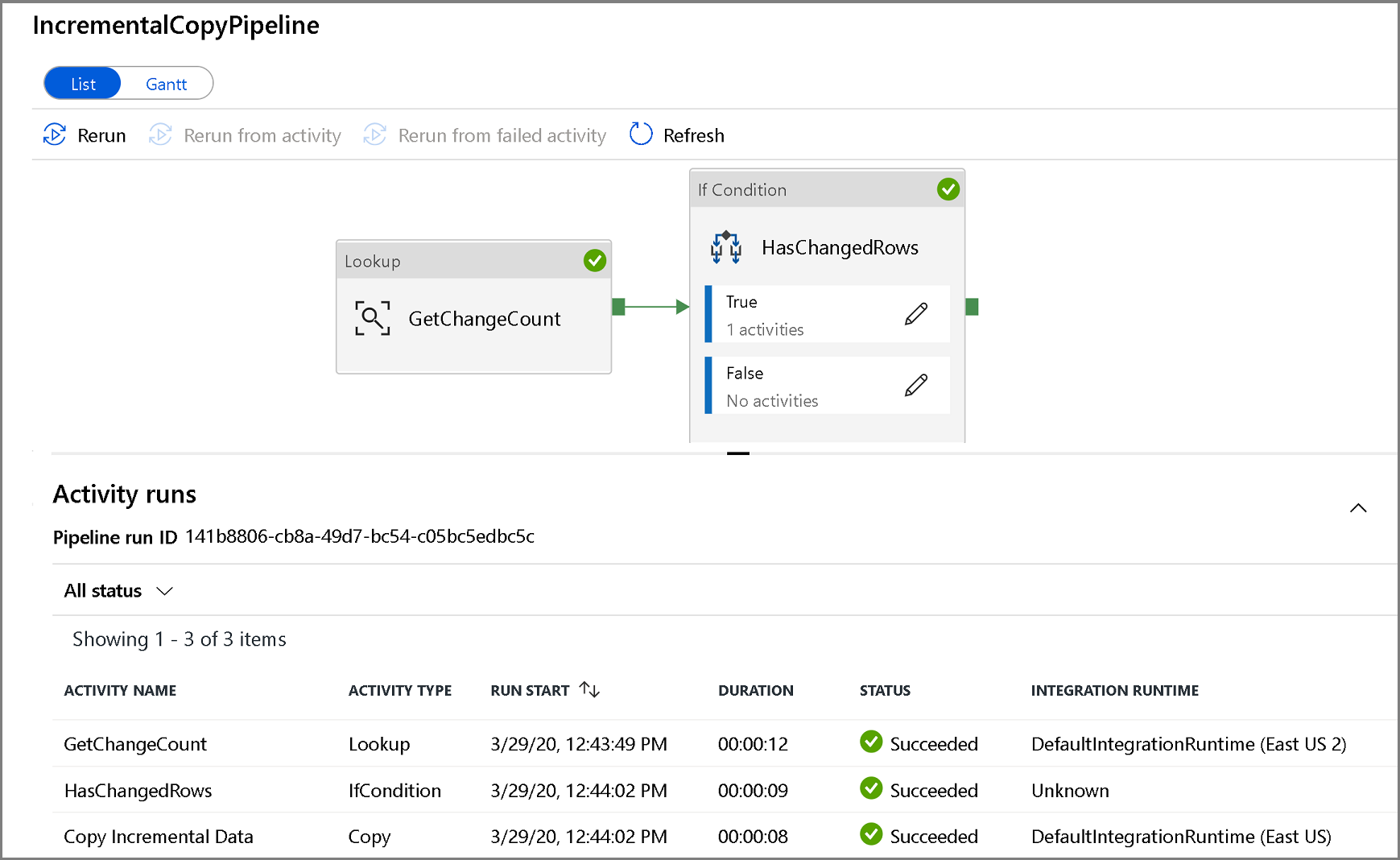
Als u de uitvoeringen van activiteiten die zijn gekoppeld aan de pijplijnuitvoering wilt weergeven, klikt u op de naam van de pijplijn. Als er gewijzigde gegevens zijn gedetecteerd, worden er drie activiteiten, waaronder de activiteit Kopiëren, weergegeven, anders worden er maar twee weergegeven. Als u wilt terugkeren naar de weergave met pijplijnuitvoeringen, klikt u op de koppeling Alle pijplijnen bovenaan.
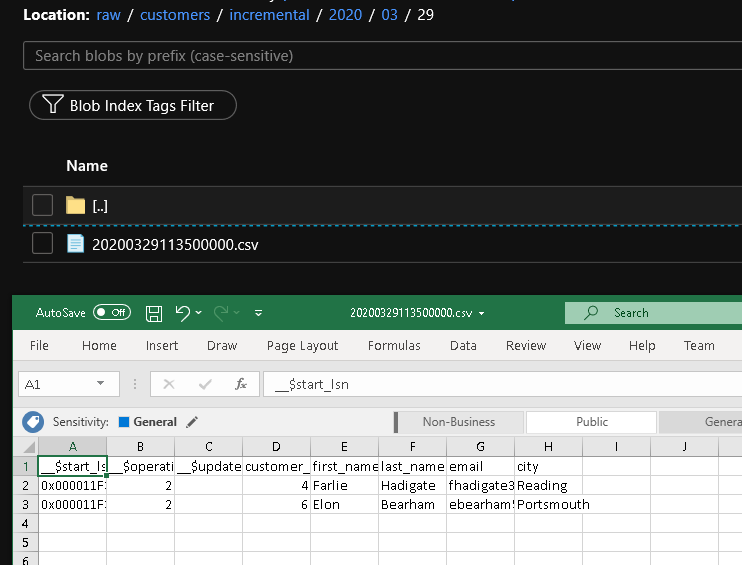
De resultaten bekijken
U ziet u het tweede bestand in de customers/incremental/YYYY/MM/DD map van de raw container.
Gerelateerde inhoud
Ga naar de volgende zelfstudie voor meer informatie over het kopiëren van nieuwe en gewijzigde bestanden alleen op basis van hun LastModifiedDate:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor