Incrementeel gegevens kopiëren van Azure SQL Database naar Blob Storage met behulp van wijzigingen bijhouden in Azure Portal
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In een oplossing voor gegevensintegratie is incrementeel (of delta) laden van gegevens na een eerste volledige laadhandeling een veelgebruikt scenario. De gewijzigde gegevens binnen een periode in uw brongegevensarchief kunnen eenvoudig worden gesegmenteerd (bijvoorbeeld LastModifyTime, CreationTime). Maar in sommige gevallen is er geen expliciete manier om de deltagegevens te identificeren van de laatste keer dat u de gegevens hebt verwerkt. U kunt de technologie voor het bijhouden van wijzigingen gebruiken die wordt ondersteund door gegevensarchieven zoals Azure SQL Database en SQL Server om de deltagegevens te identificeren.
In deze zelfstudie wordt beschreven hoe u Azure Data Factory gebruikt met wijzigingen bijhouden om deltagegevens van Azure SQL Database incrementeel te laden in Azure Blob Storage. Zie Wijzigingen bijhouden in SQL Server voor meer informatie over het bijhouden van wijzigingen.
In deze zelfstudie voert u de volgende stappen uit:
- Bereid het brongegevensarchief voor.
- Een data factory maken.
- Maak gekoppelde services.
- Maken van bron-, sink- en wijzigingsgegevenssets.
- Maak, voer deze uit en bewaak de volledige kopieerpijplijn.
- Gegevens toevoegen of bijwerken in de brontabel.
- De incrementele kopieerpijplijn maken, uitvoeren en bewaken.
Oplossingen op hoog niveau
In deze zelfstudie maakt u twee pijplijnen die de volgende bewerkingen uitvoeren.
Notitie
In deze zelfstudie wordt Azure SQL Database gebruikt als de bron-gegevensopslag. U kunt ook SQL Server gebruiken.
Eerste laadbewerking van historische gegevens: u maakt een pijplijn met een kopieeractiviteit waarmee de volledige gegevens uit het brongegevensarchief (Azure SQL Database) worden gekopieerd naar het doelgegevensarchief (Azure Blob Storage):
- Schakel technologie voor het bijhouden van wijzigingen in de brondatabase in Azure SQL Database in.
- Haal de initiële waarde van
SYS_CHANGE_VERSIONde database op als basislijn om gewijzigde gegevens vast te leggen. - Laad volledige gegevens uit de brondatabase in Azure Blob Storage.

Incrementeel laden van deltagegevens volgens een schema: U maakt een pijplijn met de volgende activiteiten en voert deze periodiek uit:
Maak twee opzoekactiviteiten om de oude en nieuwe
SYS_CHANGE_VERSIONwaarden op te halen uit Azure SQL Database.Maak één kopieeractiviteit om de ingevoegde, bijgewerkte of verwijderde gegevens (de deltagegevens) tussen de twee
SYS_CHANGE_VERSIONwaarden van Azure SQL Database naar Azure Blob Storage te kopiëren.U laadt de deltagegevens door de primaire sleutels van gewijzigde rijen (tussen twee
SYS_CHANGE_VERSIONwaarden)sys.change_tracking_tableste koppelen aan gegevens in de brontabel en vervolgens de deltagegevens naar het doel te verplaatsen.Maak één opgeslagen procedureactiviteit om de waarde voor
SYS_CHANGE_VERSIONde volgende pijplijnuitvoering bij te werken.

Vereisten
- Azure-abonnement. Als u nog geen abonnement hebt, maakt u een gratis account voordat u begint.
- Azure SQL-database. U gebruikt een database in Azure SQL Database als brongegevensarchief. Als u er nog geen hebt, raadpleegt u Een database maken in Azure SQL Database voor stappen om deze te maken.
- Azure-opslagaccount. U gebruikt Blob Storage als de sinkgegevensopslag . Als u geen Azure-opslagaccount hebt, raadpleegt u Een opslagaccount maken voor stappen om er een te maken. Maak een container met de naam adftutorial.
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Een gegevensbrontabel maken in Azure SQL Database
Open SQL Server Management Studio en maak verbinding met SQL Database.
Klik in Server Explorer met de rechtermuisknop op uw database en selecteer vervolgens Nieuwe query.
Voer de volgende SQL-opdracht uit voor uw database om een tabel te maken met de naam
data_source_tablebrongegevensopslag:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Schakel wijzigingen bijhouden in uw database en de brontabel (
data_source_table) in door de volgende SQL-query uit te voeren.Notitie
- Vervang door
<your database name>de naam van de database in Azure SQL Database metdata_source_table. - De gewijzigde gegevens worden in het huidige voorbeeld twee dagen bewaard. Als u de gewijzigde gegevens elke drie dagen of meer laadt, zal sommige informatie niet worden meegenomen. U moet de waarde van een groter getal wijzigen of ervoor zorgen dat de periode voor het laden van
CHANGE_RETENTIONde gewijzigde gegevens binnen twee dagen valt. Zie Wijzigingen bijhouden inschakelen voor een database voor meer informatie.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Vervang door
Maak een nieuwe tabel en sla
ChangeTracking_versiondeze op met een standaardwaarde door de volgende query uit te voeren:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Notitie
Als de gegevens niet worden gewijzigd nadat u wijzigingen bijhouden voor SQL Database hebt ingeschakeld, is
0de waarde van de versie voor het bijhouden van wijzigingen.Voer de volgende query uit om een opgeslagen procedure in uw database te maken. De pijplijn roept deze opgeslagen procedure aan om de versie voor het bijhouden van wijzigingen bij te werken in de tabel die u in de vorige stap hebt gemaakt.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Een data factory maken
Open de webbrowser Microsoft Edge of Google Chrome. Momenteel ondersteunen alleen deze browsers de Gebruikersinterface (UI) van Data Factory.
Selecteer een resource maken in azure Portal in het linkermenu.
Selecteer Integration>Data Factory.
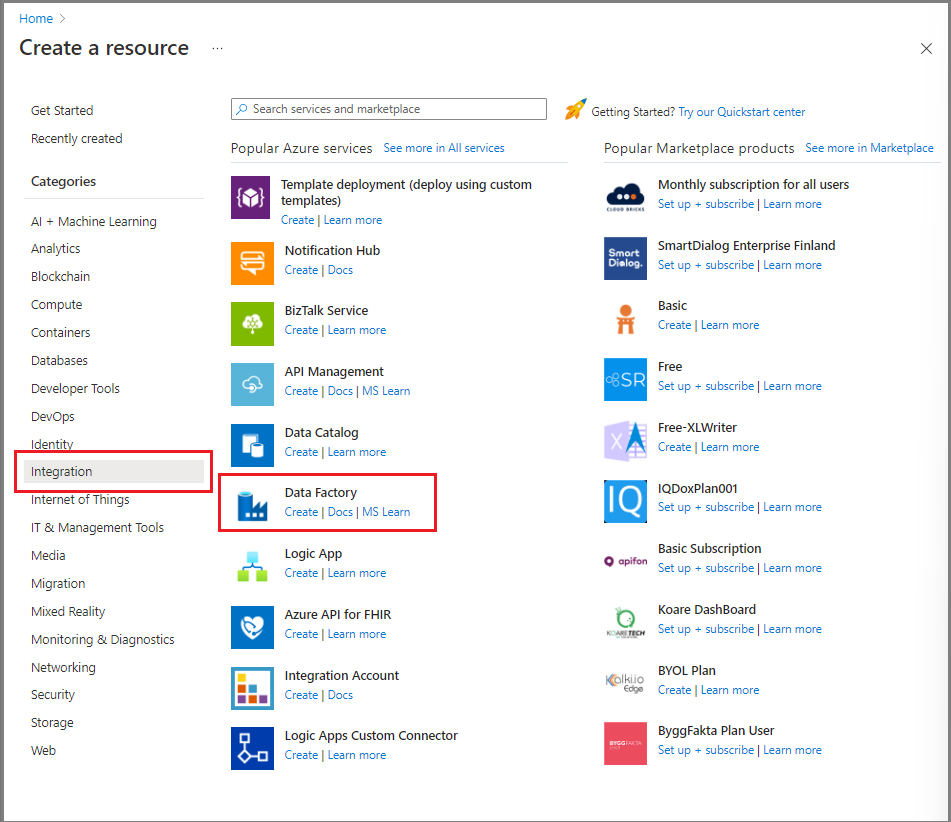
Voer op de pagina Nieuwe data factory ADFTutorialDataFactory in als naam.
De naam van de data factory moet wereldwijd uniek zijn. Als er een foutbericht wordt weergegeven dat de naam die u hebt gekozen niet beschikbaar is, wijzigt u de naam (bijvoorbeeld in uwnaamADFTutorialDataFactory) en probeert u de data factory opnieuw te maken. Zie Naamgevingsregels voor Azure Data Factory voor meer informatie.
Selecteer het Azure-abonnement waarin u de data factory wilt maken.
Voer een van de volgende stappen uit voor Resourcegroep:
- Selecteer Bestaande gebruiken en selecteer vervolgens een bestaande resourcegroep in de vervolgkeuzelijst.
- Selecteer Nieuwe maken en voer vervolgens de naam van een resourcegroep in.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer V2 als Versie.
Selecteer voor Regio de regio voor de gegevensfactory.
In de vervolgkeuzelijst worden alleen locaties weergegeven die worden ondersteund. De gegevensarchieven (bijvoorbeeld Azure Storage en Azure SQL Database) en berekeningen (bijvoorbeeld Azure HDInsight) die een data factory gebruikt, kunnen zich in andere regio's bevinden.
Selecteer Volgende: Git-configuratie. Stel de opslagplaats in door de instructies in configuratiemethode 4 te volgen: tijdens het maken van de fabriek of schakel het selectievakje Git later configureren in.
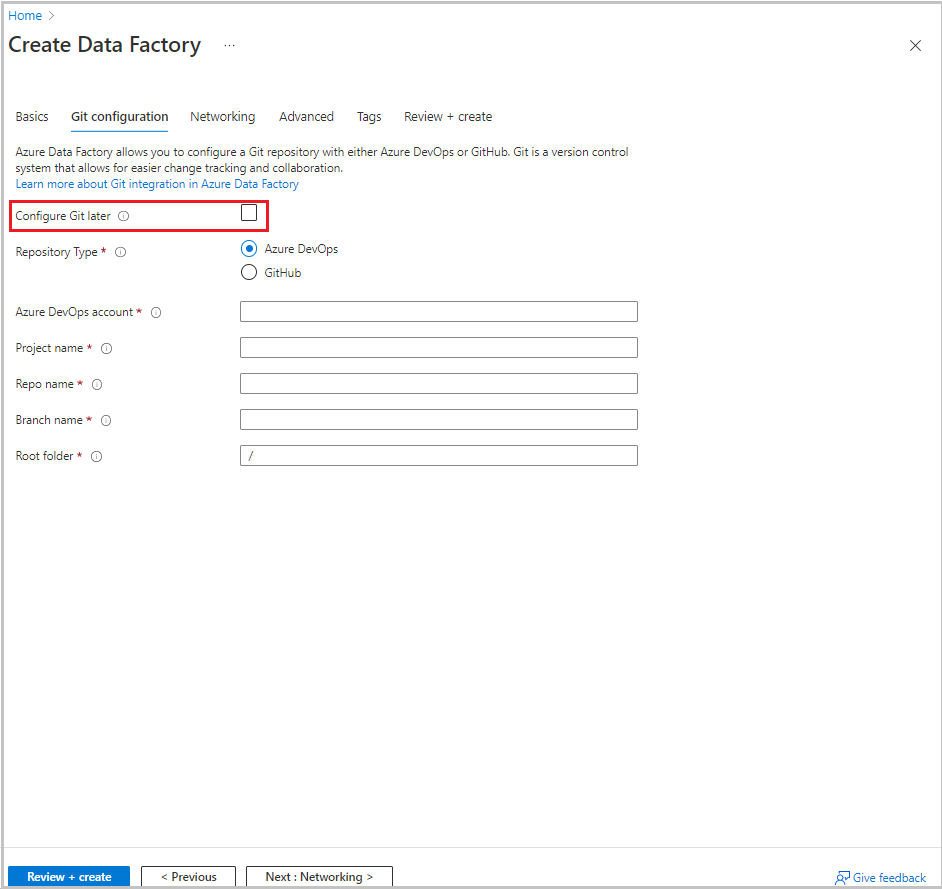
Selecteer Controleren + maken.
Selecteer Maken.
Op het dashboard wordt op de tegel Deploying Data Factory de status weergegeven.

Nadat het maken is voltooid, wordt de data factory-pagina weergegeven. Selecteer de tegel Start studio om de Gebruikersinterface van Azure Data Factory te openen op een afzonderlijk tabblad.
Gekoppelde services maken
U maakt gekoppelde services in een gegevensfactory om uw gegevensarchieven en compute-services aan de gegevensfactory te koppelen. In deze sectie maakt u gekoppelde services aan uw Azure-opslagaccount en uw database in Azure SQL Database.
Een gekoppelde Azure Storage-service maken
Uw opslagaccount koppelen aan de data factory:
- Selecteer gekoppelde services in de gebruikersinterface van Data Factory op het tabblad Beheren onder Verbinding maken ions. Selecteer vervolgens + Nieuw of de knop Gekoppelde service maken.
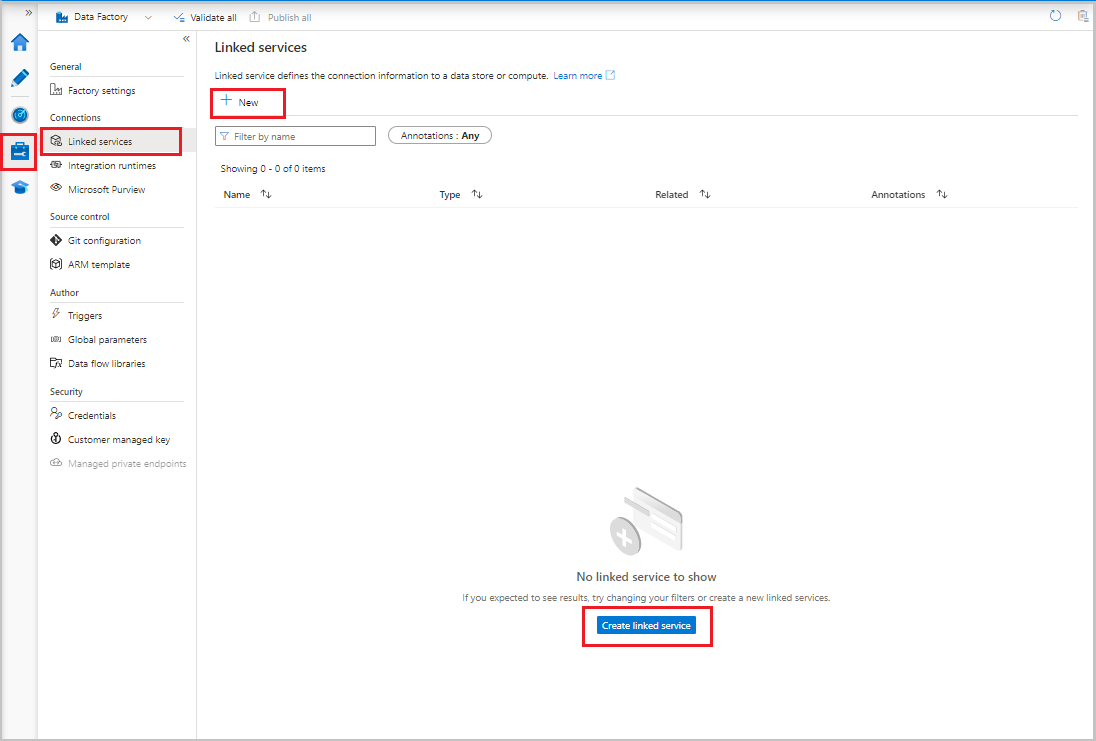
- Selecteer Azure Blob Storage in het venster Nieuwe gekoppelde service en selecteer Vervolgens Doorgaan.
- Voer de volgende gegevens in:
- Voer bij NaamAzureStorageLinkedService in.
- Selecteer de Integration Runtime voor Verbinding maken via Integration Runtime.
- Selecteer een verificatiemethode voor verificatietype.
- Selecteer uw Azure Storage-account voor de naam van het opslagaccount.
- Selecteer Maken.
Een gekoppelde Azure SQL Database-service maken
Uw database koppelen aan de data factory:
Selecteer gekoppelde services in de gebruikersinterface van Data Factory op het tabblad Beheren onder Verbinding maken ions. Selecteer vervolgens + Nieuw.
Selecteer Azure SQL Database in het venster Nieuwe gekoppelde service en selecteer Vervolgens Doorgaan.
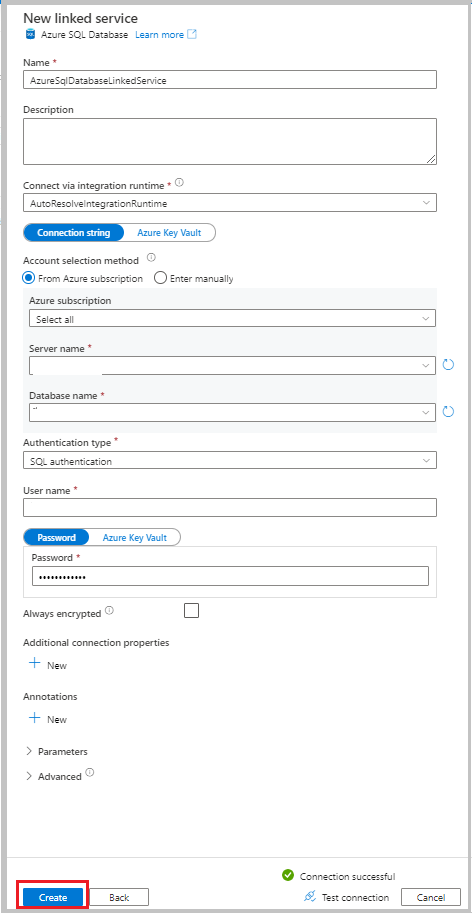
Voer de volgende informatie in:
- Voer bij Name AzureSqlDatabaseLinkedService in.
- Selecteer uw server als servernaam.
- Selecteer uw database als databasenaam.
- Selecteer een verificatiemethode voor verificatietype. In deze zelfstudie wordt SQL-verificatie gebruikt voor demonstratie.
- Voer bij Gebruikersnaam de naam van de gebruiker in.
- Voer voor Wachtwoord een wachtwoord in voor de gebruiker. U kunt ook de informatie opgeven voor de gekoppelde Azure Key Vault- AKV-service, de geheime naam en de geheime versie.
Als u de verbinding wilt testen, selecteert u Verbinding testen.
Selecteer Maken om de gekoppelde service te maken.
Gegevenssets maken
In deze sectie maakt u gegevenssets die de gegevensbron en het gegevensdoel vertegenwoordigen, samen met de plaats waar de SYS_CHANGE_VERSION waarden moeten worden opgeslagen.
Een gegevensset maken om brongegevens weer te geven
Selecteer in de gebruikersinterface van Data Factory op het tabblad Auteur het plusteken (+). Selecteer vervolgens Gegevensset of selecteer het beletselteken voor gegevenssetacties.
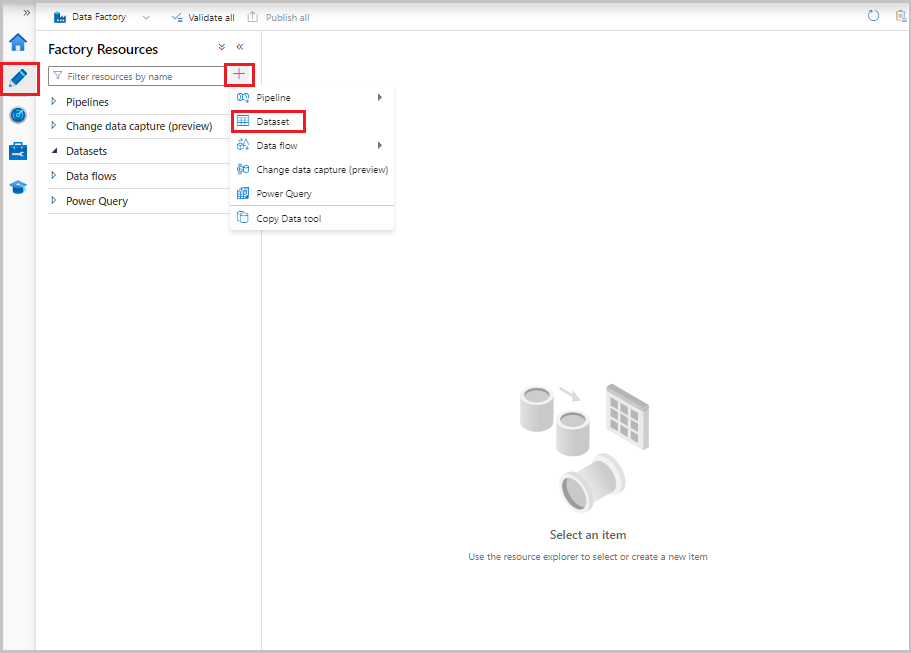
Selecteer Azure SQL Database en vervolgens Doorgaan.
Voer in het venster Eigenschappen instellen de volgende stappen uit:
- Voer voor Naam SourceDataset in.
- Selecteer AzureSqlDatabaseLinkedService voor de gekoppelde service.
- Selecteer dbo.data_source_table voor tabelnaam.
- Selecteer voor importschema de optie Uit verbinding/archief .
- Selecteer OK.

Een gegevensset maken die gegevens vertegenwoordigt die naar het sink-gegevensarchief zijn gekopieerd
In de volgende procedure maakt u een gegevensset die de gegevens vertegenwoordigt die zijn gekopieerd uit het brongegevensarchief. U hebt de adftutorial-container in Azure Blob Storage gemaakt als onderdeel van de vereisten. Maak de container als deze bestaat niet of stel deze in op de naam van een bestaande container. In deze zelfstudie wordt de naam van het uitvoerbestand dynamisch gegenereerd op basis van de expressie @CONCAT('Incremental-', pipeline().RunId, '.txt').
Selecteer +in de gebruikersinterface van Data Factory op het tabblad Auteur. Selecteer vervolgens Gegevensset of selecteer het beletselteken voor gegevenssetacties.
Selecteer Azure Blob Storage en selecteer vervolgens Doorgaan.
Selecteer de indeling van het gegevenstype als DelimitedText en selecteer vervolgens Doorgaan.
Voer in het venster Eigenschappen instellen de volgende stappen uit:
- Voer voor Naam SinkDataset in.
- Selecteer AzureBlobStorageLinkedService voor gekoppelde service.
- Voer voor bestandspad adftutorial/incchgtracking in.
- Selecteer OK.
Nadat de gegevensset in de structuurweergave wordt weergegeven, gaat u naar het tabblad Verbinding maken ion en selecteert u het tekstvak Bestandsnaam. Wanneer de optie Dynamische inhoud toevoegen wordt weergegeven, selecteert u deze.
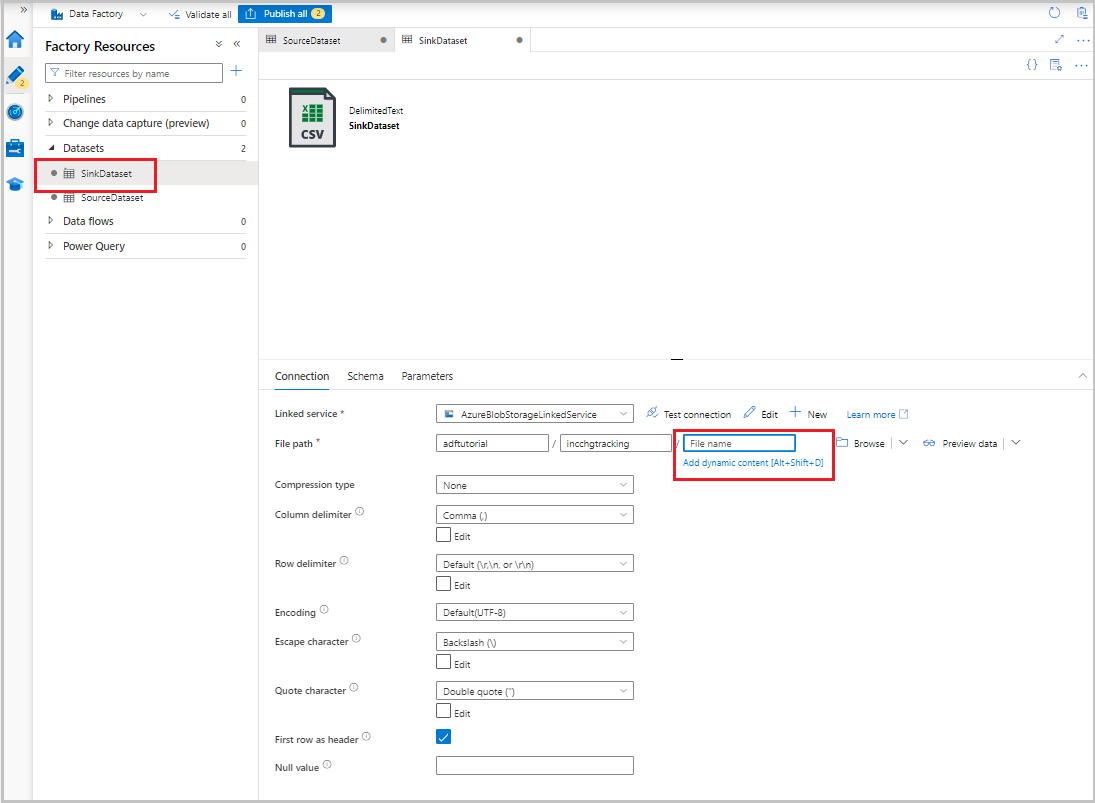
Het venster Opbouwfunctie voor pijplijnexpressies wordt weergegeven. Plak
@concat('Incremental-',pipeline().RunId,'.csv')het tekstvak.Selecteer OK.
Een gegevensset maken voor het weergeven van de bovengrenswaarde
In de volgende procedure maakt u een gegevensset voor het opslaan van de versie voor het bijhouden van wijzigingen. U hebt de table_store_ChangeTracking_version tabel gemaakt als onderdeel van de vereisten.
- Selecteer in de gebruikersinterface van Data Factory op het tabblad Auteur de optie +En selecteer vervolgens Gegevensset.
- Selecteer Azure SQL Database en vervolgens Doorgaan.
- Voer in het venster Eigenschappen instellen de volgende stappen uit:
- Voer voor Name ChangeTrackingDataset in.
- Selecteer AzureSqlDatabaseLinkedService voor de gekoppelde service.
- Selecteer dbo.table_store_ChangeTracking_version bij Tabelnaam.
- Selecteer voor importschema de optie Uit verbinding/archief .
- Selecteer OK.
Een pijplijn maken voor de volledige kopie
In de volgende procedure maakt u een pijplijn met een kopieeractiviteit waarmee de volledige gegevens uit het brongegevensarchief (Azure SQL Database) worden gekopieerd naar het doelgegevensarchief (Azure Blob Storage):
Selecteer in de gebruikersinterface van Data Factory op het tabblad Auteur de optie Pijplijn en selecteer vervolgens Pijplijn>.+
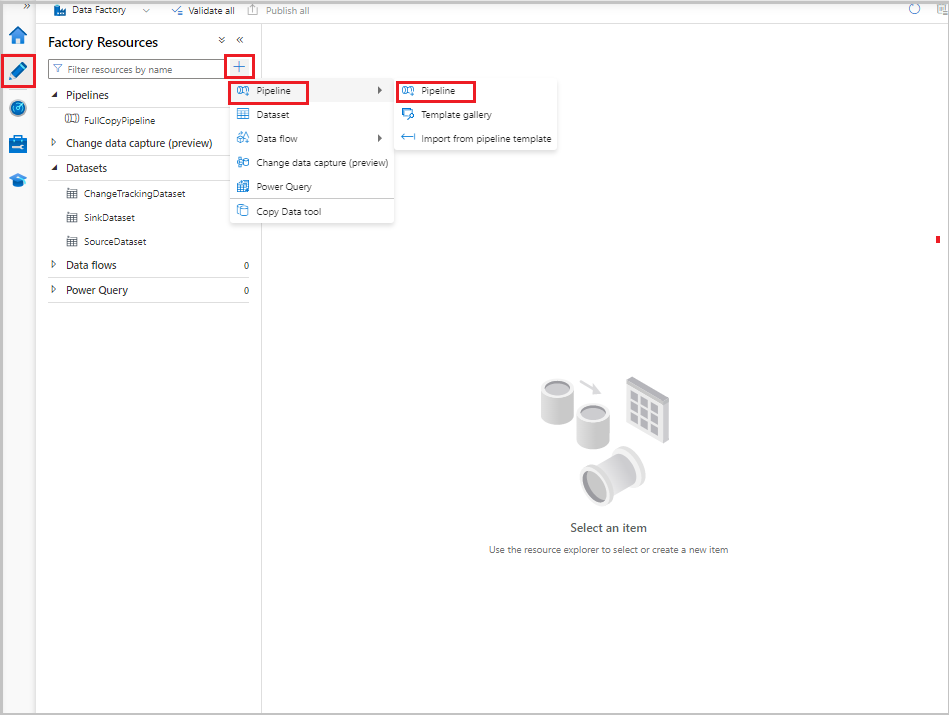
Er wordt een nieuw tabblad weergegeven voor het configureren van de pijplijn. De pijplijn wordt ook weergegeven in de structuurweergave. In het venster Properties wijzigt u de naam van de pijplijn in FullCopyPipeline.
Vouw in de werkset Activiteiten Move & transform uit. Voer een van de volgende stappen uit:
- Sleep de kopieeractiviteit naar het ontwerpoppervlak voor pijplijnen.
- Zoek in de zoekbalk onder Activiteiten naar de kopieergegevensactiviteit en stel de naam in op FullCopyActivity.
Schakel over naar het tabblad Bron. Selecteer SourceDataset voor brongegevensset.
Ga naar het tabblad Sink . Voor Sink-gegevensset selecteert u SinkDataset.
Als u de pijplijndefinitie wilt valideren, selecteert u Valideren op de werkbalk. Controleer of er geen validatiefouten zijn. Sluit de uitvoer van de pijplijnvalidatie.
Als u entiteiten (gekoppelde services, gegevenssets en pijplijnen) wilt publiceren, selecteert u Alles publiceren. Wacht totdat het bericht Successfully published wordt weergegeven.
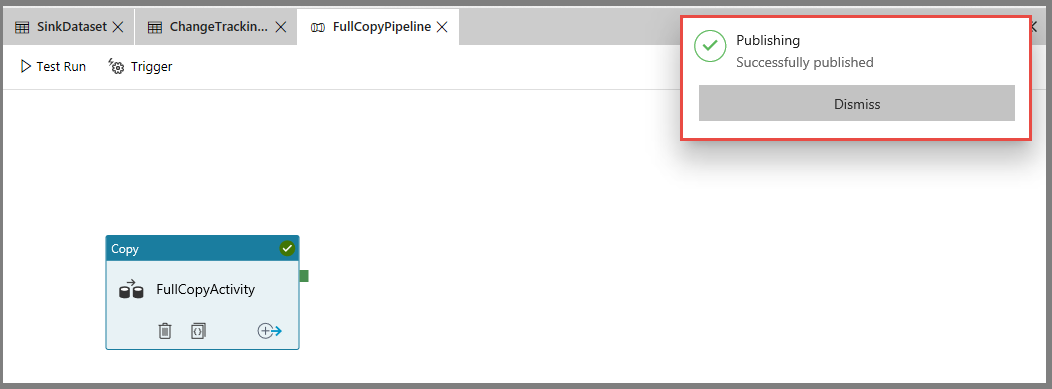
Als u meldingen wilt zien, selecteert u de knop Meldingen weergeven.
Voer de volledige kopie-pijplijn uit
Selecteer in de data factory-gebruikersinterface op de werkbalk voor de pijplijn de optie Trigger toevoegen en selecteer Nu activeren.
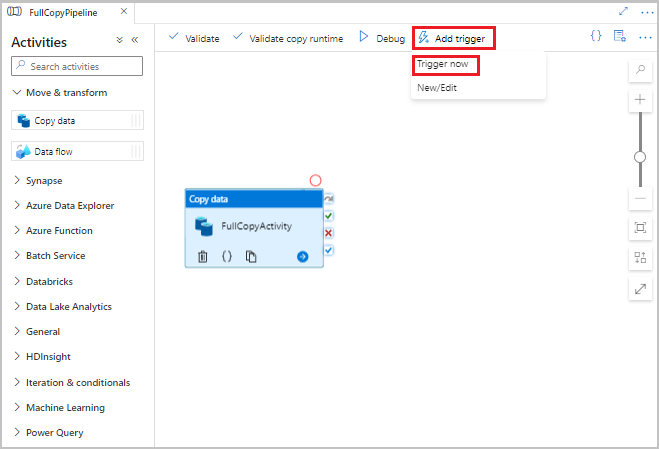
Selecteer OK in het venster Pijplijnuitvoering.

De volledige kopieerpijplijn bewaken
Selecteer in de gebruikersinterface van Data Factory het tabblad Monitor . De pijplijnuitvoering en de status ervan worden weergegeven in de lijst. Als u de lijst wilt vernieuwen, selecteert u Vernieuwen. Beweeg de muisaanwijzer over de pijplijnuitvoering om de optie Opnieuw uitvoeren of Verbruik op te halen.
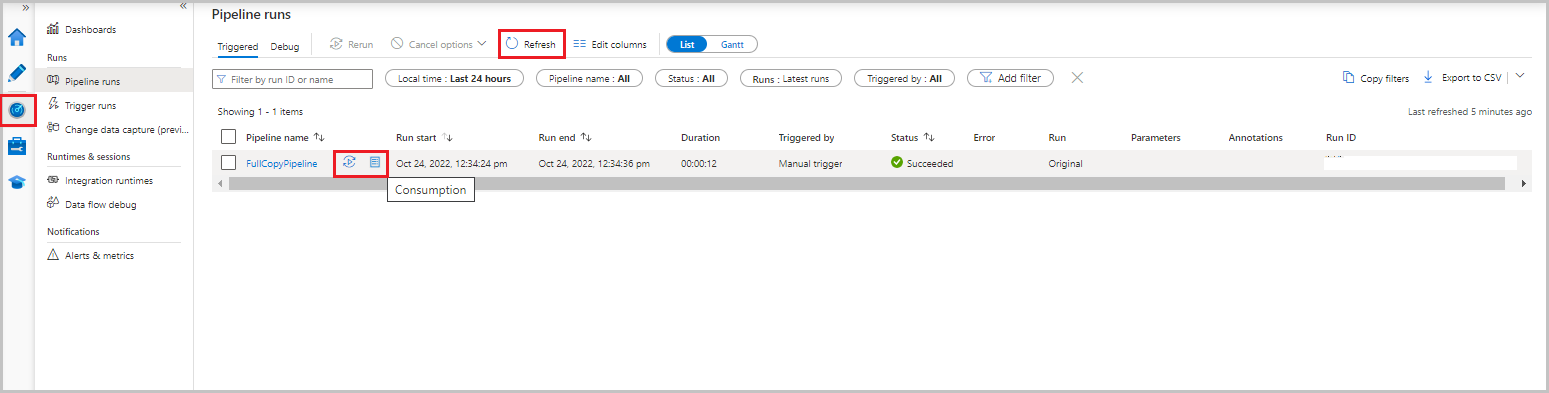
Als u activiteitsuitvoeringen wilt weergeven die zijn gekoppeld aan de pijplijnuitvoering, selecteert u de naam van de pijplijn in de kolom Pijplijnnaam . Er is slechts één activiteit in de pijplijn, dus er is slechts één vermelding in de lijst. Als u wilt teruggaan naar de weergave van pijplijnuitvoeringen, selecteert u de koppeling Alle pijplijnuitvoeringen bovenaan.
De resultaten bekijken
De incchgtracking-map van de adftutorial-container bevat een bestand met de naam incremental-<GUID>.csv.
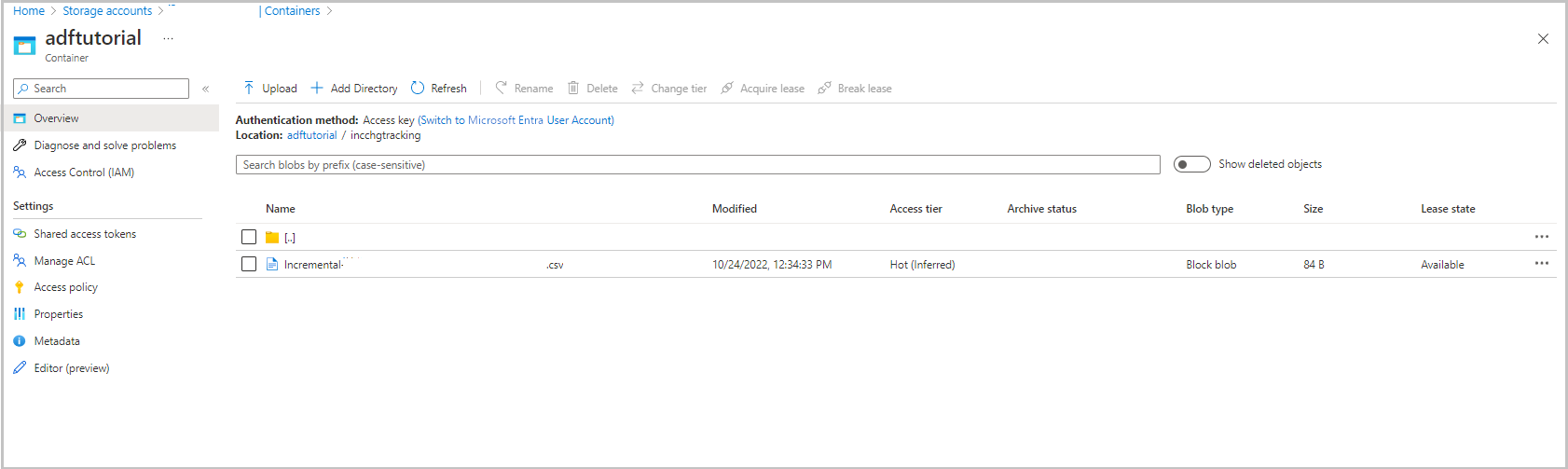
Het bestand moet de gegevens van uw database bevatten:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Meer gegevens toevoegen aan de brontabellen
Voer de volgende query uit op uw database om een rij toe te voegen en een rij bij te werken:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Een pijplijn voor de delta-kopie maken
In de volgende procedure maakt u een pijplijn met activiteiten en voert u deze periodiek uit. Wanneer u de pijplijn uitvoert:
- De opzoekactiviteiten krijgen de oude en nieuwe
SYS_CHANGE_VERSIONwaarden van Azure SQL Database en geven deze door aan de kopieeractiviteit. - De kopieeractiviteit kopieert de ingevoegde, bijgewerkte of verwijderde gegevens tussen de twee
SYS_CHANGE_VERSIONwaarden van Azure SQL Database naar Azure Blob Storage. - Met de opgeslagen procedureactiviteit wordt de waarde voor
SYS_CHANGE_VERSIONde volgende pijplijnuitvoering bijgewerkt.
Ga in de data factory-gebruikersinterface naar het tabblad Auteur. Selecteer +en selecteer vervolgens Pijplijn>.
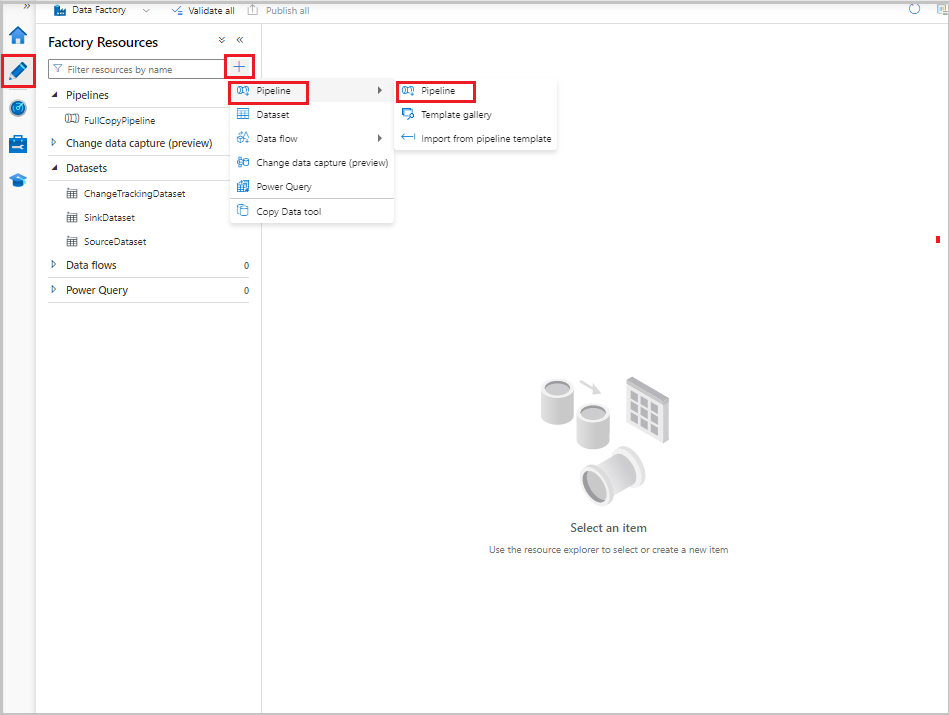
Er wordt een nieuw tabblad weergegeven voor het configureren van de pijplijn. De pijplijn wordt ook weergegeven in de structuurweergave. In het venster Properties wijzigt u de naam van de pijplijn in IncrementalCopyPipeline.
Vouw Algemeen uit in de werkset Activiteiten . Sleep de opzoekactiviteit naar het ontwerpoppervlak voor pijplijnen of zoek in het vak Zoekactiviteiten . Stel de naam van de activiteit in op LookupLastChangeTrackingVersionActivity. Met deze activiteit wordt de versie voor het bijhouden van wijzigingen opgehaald die wordt gebruikt in de laatste kopieerbewerking die is opgeslagen in de
table_store_ChangeTracking_versiontabel.Ga naar het tabblad Instellingen in het venster Eigenschappen. Selecteer ChangeTrackingDataset voor brongegevensset.
Sleep de opzoekactiviteit van de werkset Activities naar het ontwerpoppervlak voor pijplijnen. Stel de naam van de activiteit in op LookupCurrentChangeTrackingVersionActivity. Deze activiteit haalt de huidige versie voor bijhouden van wijzigingen op.
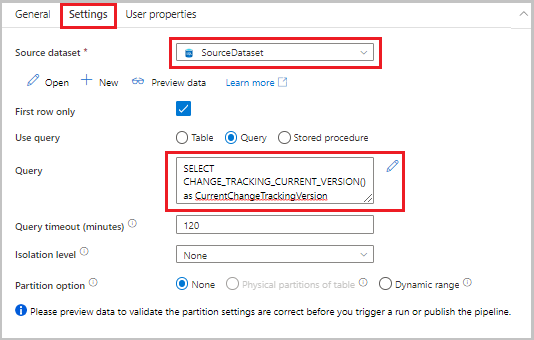
Ga naar het tabblad Instellingen in het venster Eigenschappen en voer de volgende stappen uit:
Selecteer SourceDataset voor de brongegevensset.
Selecteer Query voor Query gebruiken.
Voer voor Query de volgende SQL-query in:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
Vouw in de werkset Activiteiten Move & transform uit. Sleep de kopieergegevensactiviteit naar het ontwerpoppervlak voor pijplijnen. Stel de naam van de activiteit in op IncrementalCopyActivity. Met deze activiteit worden de gegevens tussen de laatste versie voor het bijhouden van wijzigingen en de huidige versie voor het bijhouden van wijzigingen gekopieerd naar het doelgegevensarchief.
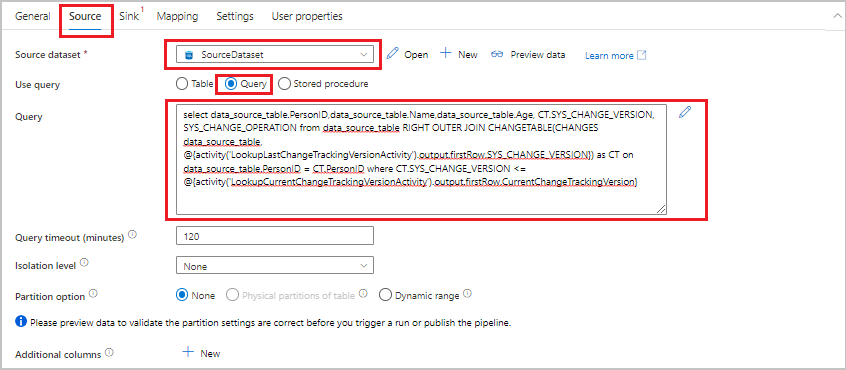
Ga naar het tabblad Bron in het venster Eigenschappen en voer de volgende stappen uit:
Selecteer SourceDataset voor de brongegevensset.
Selecteer Query voor Query gebruiken.
Voer voor Query de volgende SQL-query in:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
Ga naar het tabblad Sink . Voor Sink-gegevensset selecteert u SinkDataset.
Verbinding maken beide opzoekactiviteiten één voor één naar de kopieeractiviteit. Sleep de groene knop die is gekoppeld aan de opzoekactiviteit naar de kopieeractiviteit.
Sleep de opgeslagen procedureactiviteit van de Werkset Activities naar het ontwerpoppervlak voor pijplijnen. Stel de naam van de activiteit in op StoredProceduretoUpdateChangeTrackingActivity. Met deze activiteit wordt de versie voor het bijhouden van wijzigingen in de
table_store_ChangeTracking_versiontabel bijgewerkt.Ga naar het tabblad Instellingen en voer de volgende stappen uit:
- Selecteer AzureSqlDatabaseLinkedService voor de gekoppelde service.
- Selecteer Update_ChangeTracking_Version bij Opgeslagen procedurenaam.
- Selecteer Importeren.
- Geef in de sectie Parameters van de opgeslagen procedure de volgende waarden op voor de parameters:
Name Type Weergegeven als CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}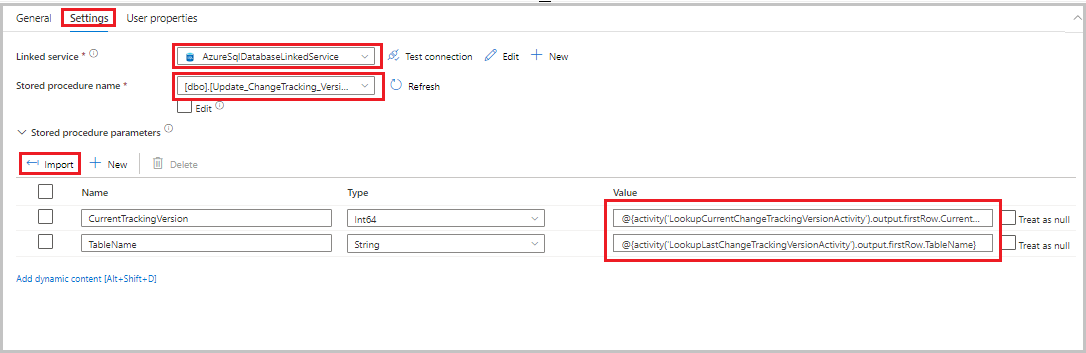
Verbinding maken de kopieeractiviteit naar de opgeslagen procedureactiviteit. Sleep de groene knop die is gekoppeld aan de kopieeractiviteit naar de opgeslagen procedureactiviteit.
Selecteer Valideren op de werkbalk. Controleer of er geen validatiefouten zijn. Sluit het venster Pijplijnvalidatierapport .
Publiceer entiteiten (gekoppelde services, gegevenssets en pijplijnen) naar de Data Factory-service door de knop Alles publiceren te selecteren. Wacht totdat het bericht Publiceren is voltooid wordt weergegeven.
De pijplijn incrementele kopie uitvoeren
Selecteer Trigger toevoegen op de werkbalk voor de pijplijn en selecteer Nu activeren.
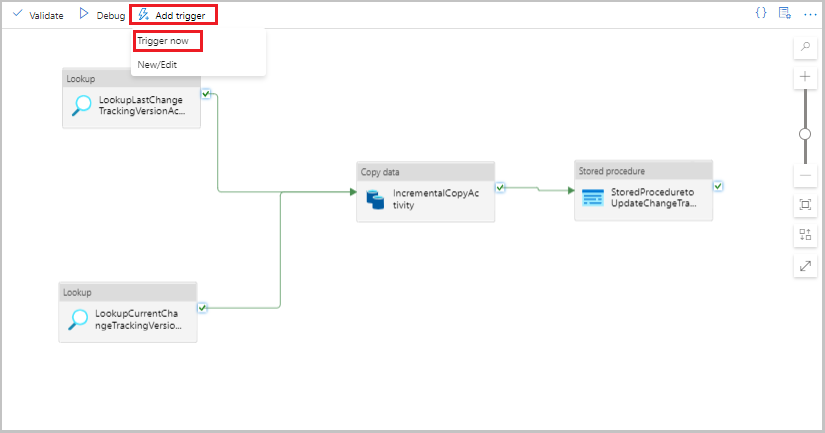
Selecteer OK in het venster Pijplijnuitvoering.
De pijplijn incrementele kopie bewaken
Selecteer het tabblad Monitor . De pijplijnuitvoering en de status ervan worden weergegeven in de lijst. Als u de lijst wilt vernieuwen, selecteert u Vernieuwen.
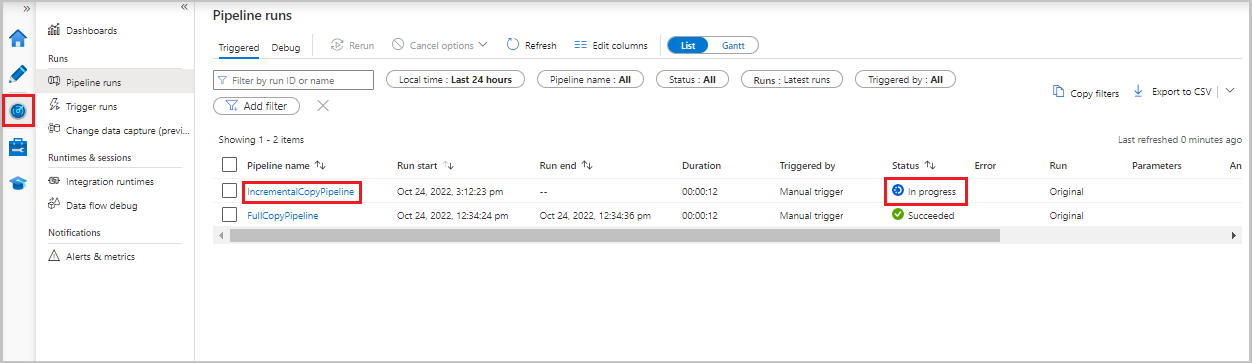
Als u activiteitsuitvoeringen wilt weergeven die zijn gekoppeld aan de pijplijnuitvoering, selecteert u de koppeling IncrementalCopyPipeline in de kolom Pijplijnnaam . De uitvoeringen van de activiteit worden weergegeven in een lijst.
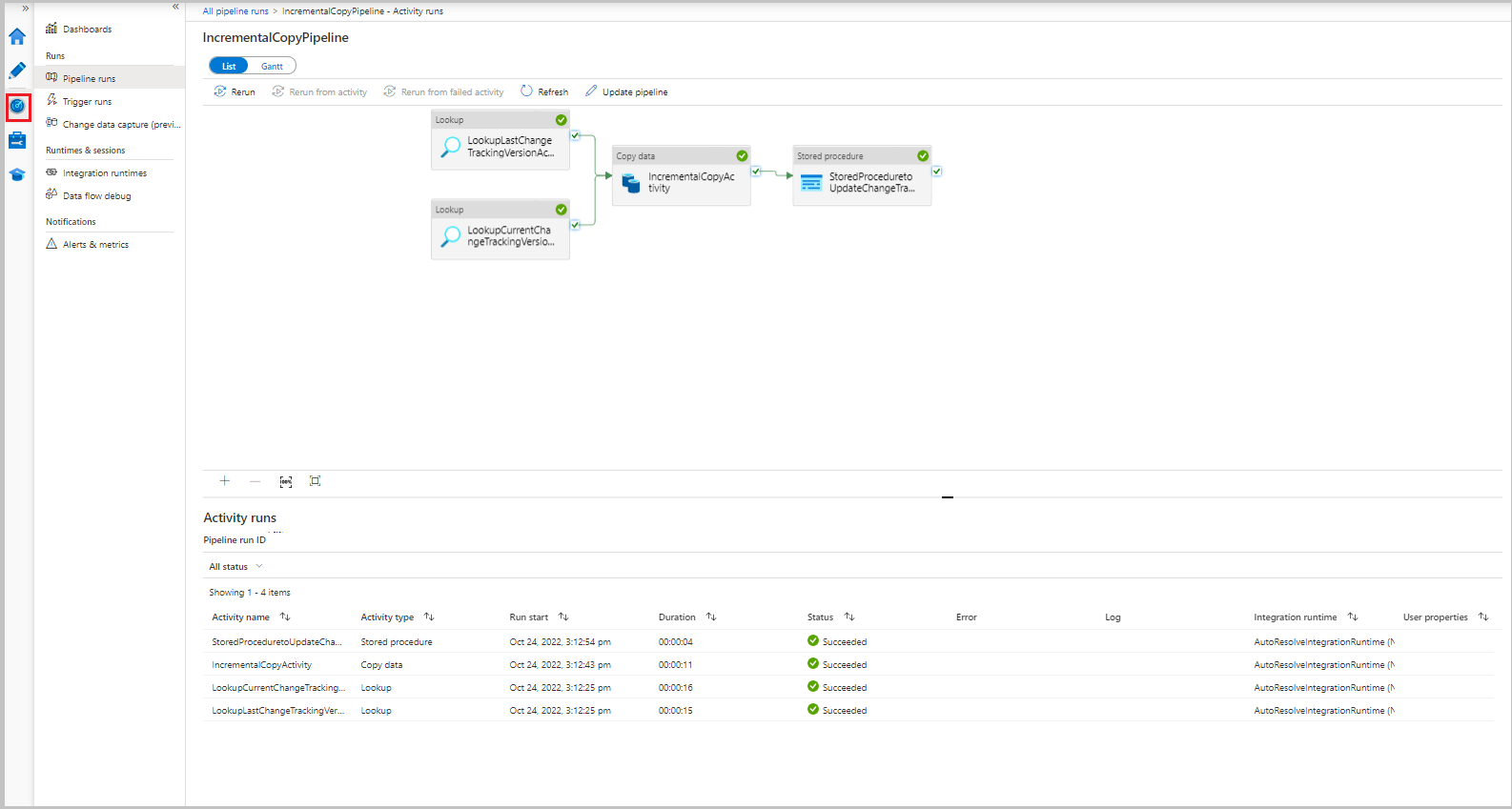
De resultaten bekijken
Het tweede bestand wordt weergegeven in de map incchgtracking van de adftutorial-container .

Het bestand mag alleen de deltagegevens van uw database bevatten. De record met U is de bijgewerkte rij in de database en I is de rij die is toegevoegd.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
De eerste drie kolommen zijn gewijzigde gegevens van data_source_table. De laatste twee kolommen zijn de metagegevens uit de tabel voor het systeem voor het bijhouden van wijzigingen. De vierde kolom is de SYS_CHANGE_VERSION waarde voor elke gewijzigde rij. De vijfde kolom is de bewerking: U = update, I = insert. Zie voor meer informatie over de traceringsgegevens CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Gerelateerde inhoud
Ga naar de volgende zelfstudie voor meer informatie over het kopiëren van alleen nieuwe en gewijzigde bestanden, op LastModifiedDatebasis van:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor