Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Databricks ondersteunt het gebruik van verschillende programmeertalen voor ontwikkeling en data engineering. In dit artikel vindt u een overzicht van de beschikbare opties, waar deze talen kunnen worden gebruikt en wat de beperkingen zijn.
Aanbevelingen
Databricks raadt Python en SQL aan voor nieuwe projecten:
- Python- is een zeer populaire programmeertaal voor algemeen gebruik. Met PySpark DataFrames kunt u eenvoudig testbare, modulaire transformaties maken. Het Python-ecosysteem ondersteunt ook een breed scala aan bibliotheken die een breed scala aan bibliotheken ondersteunen voor het uitbreiden van uw oplossing.
-
SQL- is een zeer populaire taal voor het beheren en bewerken van relationele gegevenssets door bewerkingen uit te voeren zoals het uitvoeren van query's, bijwerken, invoegen en verwijderen van gegevens. SQL is een goede keuze als uw achtergrond zich voornamelijk in databases of datawarehousing bevindt. SQL kan ook worden ingesloten in Python met behulp van
spark.sql.
De volgende talen bieden beperkte ondersteuning, zodat Databricks ze niet aanbeveelt voor nieuwe data engineering-projecten:
- Scala- is de taal die wordt gebruikt voor de ontwikkeling van Apache Spark™.
- R- wordt alleen volledig ondersteund in Databricks-notebooks.
Taalondersteuning varieert ook, afhankelijk van de functiemogelijkheden die worden gebruikt voor het bouwen van gegevenspijplijnen en andere oplossingen. Lakeflow-pijplijnen ondersteunen bijvoorbeeld Python en SQL, terwijl u met werkstromen gegevenspijplijnen kunt maken met behulp van Python, SQL, Scala en Java.
Notitie
Andere talen kunnen worden gebruikt om te communiceren met Databricks om gegevens op te vragen of gegevenstransformaties uit te voeren. Deze interacties bevinden zich echter voornamelijk in de context van integraties met externe systemen. In deze gevallen kan een ontwikkelaar vrijwel elke programmeertaal gebruiken om met Databricks te communiceren via de Databricks REST API, ODBC-/JDBC-stuurprogramma's, specifieke talen met Databricks SQL-connector ondersteuning (Go, Python, Javascript/Node.js) of talen die Spark Connect-implementaties hebben, zoals Go en Rust.
Werkruimteontwikkeling versus lokale ontwikkeling
U kunt gegevensprojecten en pijplijnen ontwikkelen met behulp van de Databricks-werkruimte of een IDE (geïntegreerde ontwikkelomgeving) op uw lokale computer, maar het starten van nieuwe projecten in de Databricks-werkruimte wordt aanbevolen. De werkruimte is toegankelijk via een webbrowser, biedt eenvoudige toegang tot gegevens in Unity Catalog en biedt ondersteuning voor krachtige foutopsporingsmogelijkheden en -functies zoals de Genie Code.
Ontwikkel code in de Databricks-werkruimte met behulp van Databricks-notebooks of de SQL-editor. Databricks-notebooks ondersteunen meerdere programmeertalen, zelfs binnen hetzelfde notebook, zodat u kunt ontwikkelen met behulp van Python, SQL en Scala.
Er zijn verschillende voordelen van het rechtstreeks ontwikkelen van code in de Databricks-werkruimte:
- De feedbacklus is sneller. U kunt geschreven code direct testen op echte gegevens.
- De ingebouwde, contextbewuste Genie Code kan de ontwikkeling versnellen en helpen bij het oplossen van problemen.
- U kunt eenvoudig notebooks en query's rechtstreeks vanuit de Databricks-werkruimte plannen.
- Voor Python-ontwikkeling kunt u uw Python-code correct structuren met behulp van bestanden als Python-pakketten in een werkruimte.
Lokale ontwikkeling binnen een IDE biedt echter de volgende voordelen:
- IDE's hebben betere hulpprogramma's voor het werken met softwareprojecten, zoals navigatie, codeherstructurering en statische codeanalyse.
- U kunt kiezen hoe u uw bron bepaalt en als u Git gebruikt, is er lokaal meer geavanceerde functionaliteit beschikbaar dan in de werkruimte met Git-mappen.
- Er is een breder scala aan ondersteunde talen. U kunt bijvoorbeeld code ontwikkelen met behulp van Java en deze implementeren als EEN JAR-taak.
- Er is betere ondersteuning voor codeopsporing.
- Er is betere ondersteuning voor het werken met eenheidstests.
Voorbeeld van taalselectie
Taalselectie voor data engineering wordt gevisualiseerd met behulp van de volgende beslissingsstructuur:
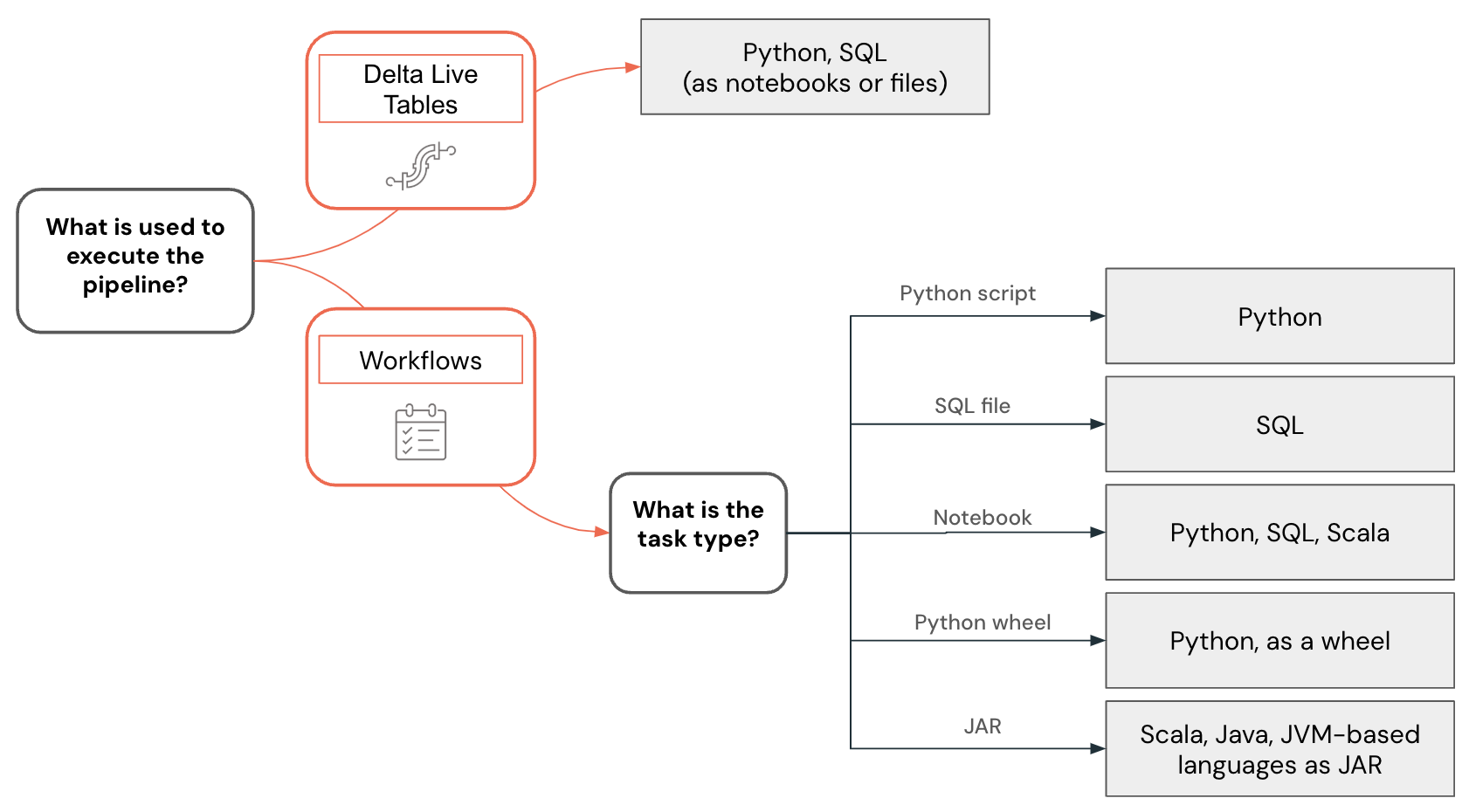
Python-code ontwikkelen
De Python-taal biedt eersteklas ondersteuning voor Databricks. U kunt deze gebruiken in Databricks-notebooks, Lakeflow-pijplijnen en -werkstromen, om UDF's te ontwikkelen en te implementeren als een Python script en als wielen.
Bij het ontwikkelen van Python-projecten in de Databricks-werkruimte, hetzij als notebooks of in bestanden, biedt Databricks hulpprogramma's zoals het voltooien van code, navigatie, syntaxisvalidatie, het genereren van code met behulp van Genie Code, interactieve foutopsporing en meer. Ontwikkelde code kan interactief worden uitgevoerd, geïmplementeerd als een Databricks-werkstroom of Lakeflow-pijplijnen, of zelfs als een functie in Unity Catalog. U kunt uw code structureren door deze te splitsen in afzonderlijke Python-pakketten die vervolgens kunnen worden gebruikt in meerdere pijplijnen of taken.
Databricks biedt een -extensie voor Visual Studio Code en JetBrains biedt een -invoegtoepassing voor PyCharm- waarmee u Python-code kunt ontwikkelen in een IDE, code kunt synchroniseren naar een Databricks-werkruimte, deze in de werkruimte kunt uitvoeren en stapsgewijze foutopsporing kunt uitvoeren met behulp van Databricks Connect. De ontwikkelde code kan vervolgens worden geïmplementeerd met behulp van Declarative Automation Bundles als een Databricks-job of -pipeline.
SQL-code ontwikkelen
De SQL-taal kan worden gebruikt in Databricks-notebooks of als Databricks-query's met behulp van de SQL-editor. In beide gevallen krijgt een ontwikkelaar toegang tot hulpprogramma's zoals het voltooien van code en de contextbewuste Genie Code die kan worden gebruikt voor het genereren van code en het oplossen van problemen. De ontwikkelde code kan worden geïmplementeerd als een taak of pijplijn.
Met Databricks-werkstromen kunt u ook SQL-code uitvoeren die is opgeslagen in een bestand. U kunt een IDE gebruiken om deze bestanden te maken en deze te uploaden naar de werkruimte. Een ander populair gebruik van SQL is in data engineering-pijplijnen die zijn ontwikkeld met behulp van dbt (data build tool). Databricks-werkstromen ondersteunen het organiseren van dbt-projecten.
Scala-code ontwikkelen
Scala is de oorspronkelijke taal van Apache Spark™. Het is een krachtige taal, maar het heeft een steile leercurve. Hoewel Scala een ondersteunde taal is in Databricks-notebooks, zijn er enkele beperkingen met betrekking tot de wijze waarop Scala-klassen en -objecten worden gemaakt en onderhouden die de ontwikkeling van complexe pijplijnen moeilijker maken. IDE's bieden doorgaans betere ondersteuning voor de ontwikkeling van Scala-code, die vervolgens kan worden geïmplementeerd met behulp van JAR-taken in Databricks-werkstromen.
Aanvullende informatiebronnen
- Ontwikkelen op Databricks is een toegangspunt voor documentatie over verschillende ontwikkelopties voor Databricks.
- Op de pagina ontwikkelhulpprogramma's worden verschillende ontwikkelhulpprogramma's beschreven die kunnen worden gebruikt om lokaal te ontwikkelen voor Databricks, waaronder declaratieve Automation-bundels en invoegtoepassingen voor IDE's.
- Code ontwikkelen in Databricks-notebooks beschrijft hoe u ontwikkelt in de Databricks-werkruimte met behulp van Databricks-notebooks.
- Query's schrijven en gegevens verkennen in de SQL-editor. In dit artikel wordt beschreven hoe u de Databricks SQL-editor gebruikt om te werken met SQL-code.
- Ontwikkel Lakeflow-pijplijnen beschrijft het ontwikkelingsproces voor Lakeflow-pijplijnen.
- Databricks Connect kunt u verbinding maken met Databricks-clusters en code uitvoeren vanuit uw lokale omgeving.
- Meer informatie over het gebruik van Genie Code voor snellere ontwikkeling en het oplossen van codeproblemen.