Azure HDInsight-architecturen voor bedrijfscontinuïteit
In dit artikel vindt u enkele voorbeelden van architecturen voor bedrijfscontinuïteit die u kunt overwegen voor Azure HDInsight. Tolerantie voor verminderde functionaliteit tijdens een noodgeval is een zakelijke beslissing die varieert van de ene toepassing tot de volgende. Het kan acceptabel zijn dat sommige toepassingen gedurende een bepaalde periode niet beschikbaar zijn of gedeeltelijk beschikbaar zijn met verminderde functionaliteit of vertraagde verwerking. Voor andere toepassingen kan elke verminderde functionaliteit onaanvaardbaar zijn.
Notitie
De architecturen die in dit artikel worden gepresenteerd, zijn op geen enkele manier volledig. U moet uw eigen unieke architecturen ontwerpen zodra u objectieve beslissingen hebt genomen over de verwachte bedrijfscontinuïteit, operationele complexiteit en eigendomskosten.
Apache Hive en Interactive Query
Hive Replication V2 wordt aanbevolen voor bedrijfscontinuïteit in HDInsight Hive- en Interactieve queryclusters. De permanente secties van een zelfstandig Hive-cluster die moeten worden gerepliceerd, zijn de opslaglaag en de Hive-metastore. Hive-clusters in een scenario voor meerdere gebruikers met Enterprise Security Package hebben Microsoft Entra Domain Services en Ranger Metastore nodig.
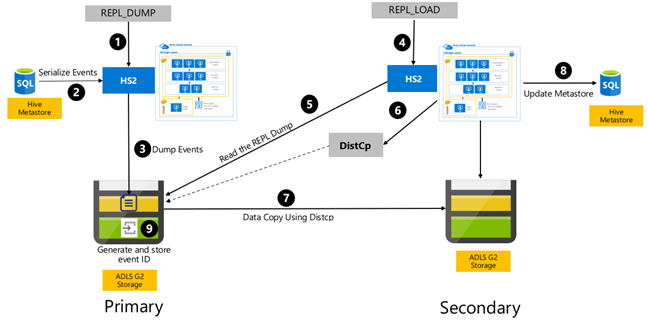
Hive-replicatie op basis van gebeurtenissen wordt geconfigureerd tussen de primaire en secundaire clusters. Dit bestaat uit twee afzonderlijke fasen, bootstrapping en incrementele uitvoeringen:
Met Bootstrapping wordt het hele Hive-magazijn gerepliceerd, inclusief de Hive-metastore-informatie van primair naar secundair.
Incrementele uitvoeringen worden geautomatiseerd op het primaire cluster en de gebeurtenissen die tijdens de incrementele uitvoeringen worden gegenereerd, worden afgespeeld op het secundaire cluster. Het secundaire cluster haalt de gebeurtenissen op die zijn gegenereerd op basis van het primaire cluster, zodat het secundaire cluster consistent is met de gebeurtenissen van het primaire cluster nadat de replicatie is uitgevoerd.
Het secundaire cluster is alleen nodig op het moment van replicatie om gedistribueerde kopie uit te voeren, DistCpmaar de opslag- en metastores moeten persistent zijn. U kunt ervoor kiezen om een gescripte secundaire cluster op aanvraag in te stellen voordat replicatie wordt uitgevoerd, het replicatiescript erop uit te voeren en het vervolgens te verwijderen na een geslaagde replicatie.
Het secundaire cluster heeft meestal het kenmerk Alleen-lezen. U kunt het secundaire cluster lezen/schrijven, maar dit voegt extra complexiteit toe waarbij de wijzigingen van het secundaire cluster naar het primaire cluster worden gerepliceerd.
RPO en RTO voor hive-replicatie op basis van gebeurtenissen
RPO: gegevensverlies is beperkt tot de laatste geslaagde incrementele replicatie-gebeurtenis van primair naar secundair.
RTO: De tijd tussen de fout en de hervatting van upstream- en downstreamtransacties met de secundaire.
Apache Hive- en Interactive Query-architecturen
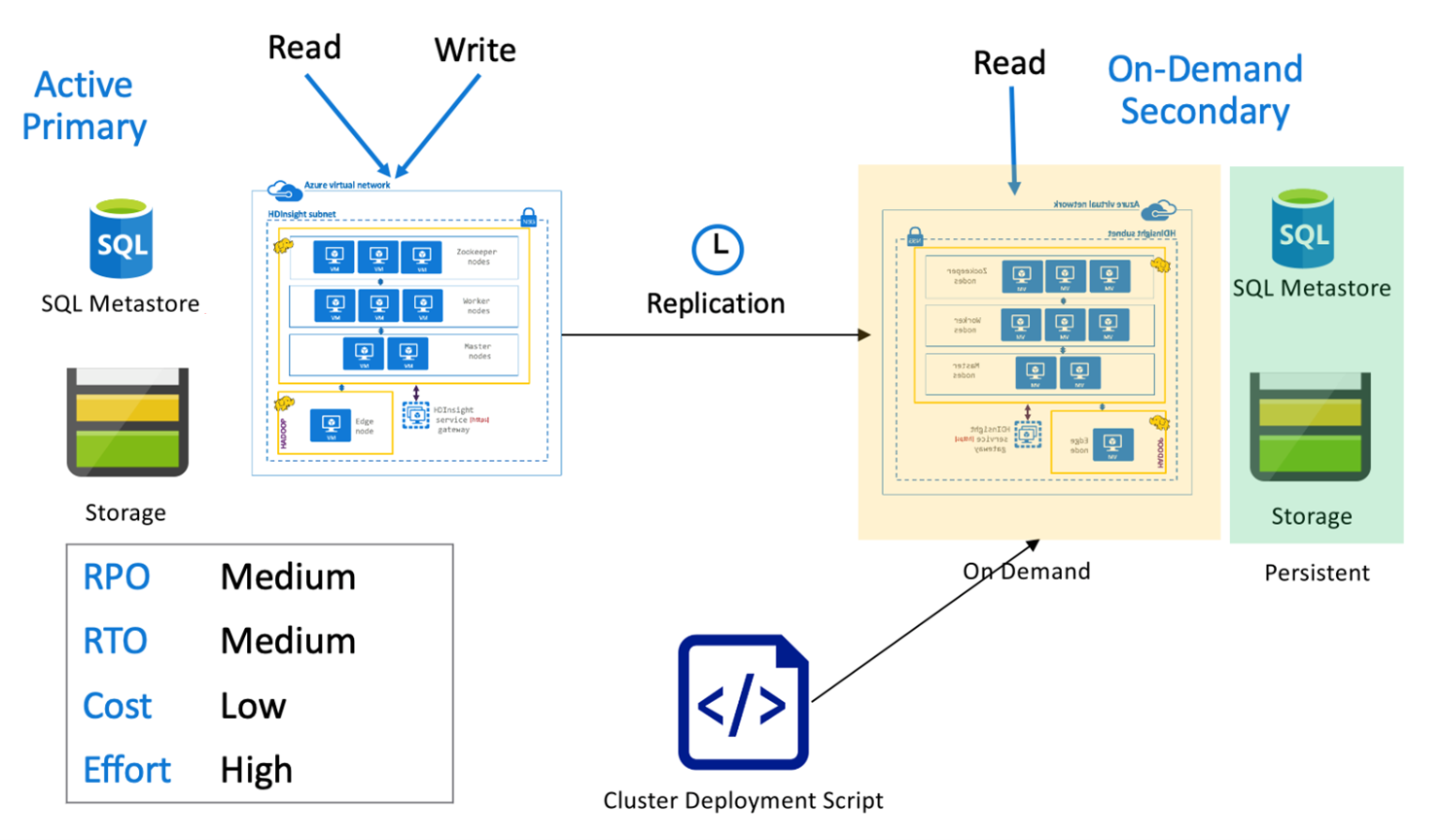
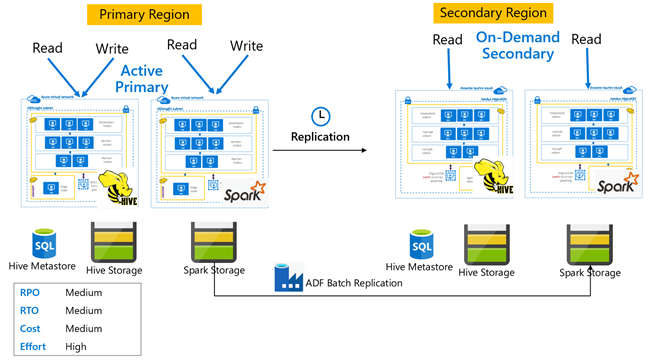
Hive-actieve primaire met secundaire on-demand
In een actieve primaire met secundaire architectuur op aanvraag schrijven toepassingen naar de actieve primaire regio terwijl er tijdens normale bewerkingen geen cluster is ingericht in de secundaire regio. SQL Metastore en Storage in de secundaire regio zijn permanent, terwijl het HDInsight-cluster alleen op aanvraag wordt gescript en geïmplementeerd voordat de geplande Hive-replicatie wordt uitgevoerd.
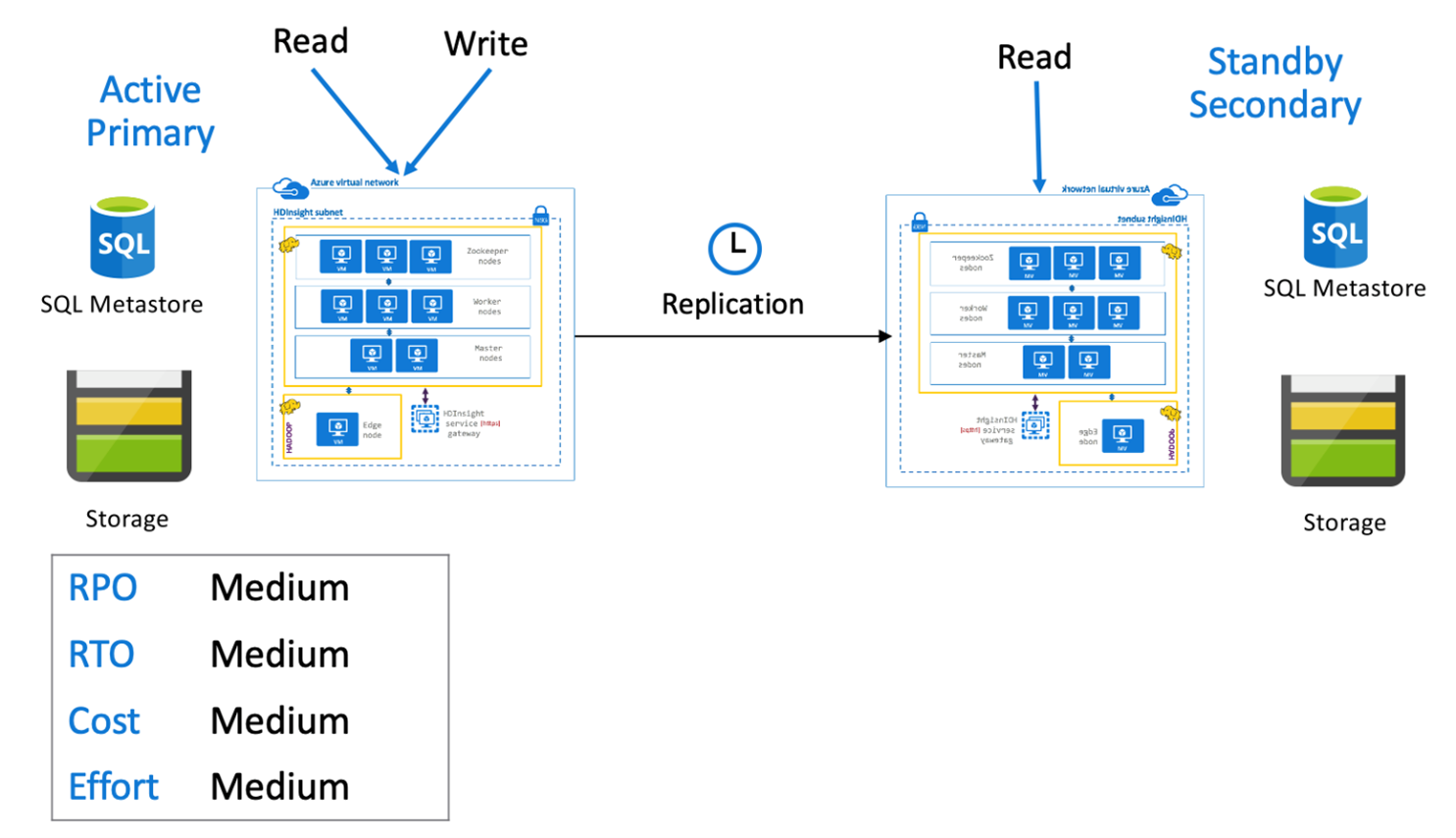
Hive actief primair met stand-by secundair
In een actieve primaire met secundaire stand-by schrijven toepassingen naar de actieve primaire regio terwijl een stand-by secundair cluster in de modus Alleen-lezen wordt uitgevoerd tijdens normale bewerkingen. Tijdens normale bewerkingen kunt u ervoor kiezen om regiospecifieke leesbewerkingen naar secundaire regio's te offloaden.
Raadpleeg Apache Hive-replicatie in Azure HDInsight-clusters voor meer informatie over Hive-replicatie en codevoorbeelden
Apache Spark
Spark-workloads kunnen al dan niet betrekking hebben op een Hive-onderdeel. Als u wilt dat Spark SQL-workloads gegevens uit Hive kunnen lezen en schrijven, delen HDInsight Spark-clusters aangepaste Hive-metastores uit Hive/Interactive-queryclusters in dezelfde regio. In dergelijke scenario's moet replicatie tussen regio's van Spark-workloads ook de replicatie van Hive-metastores en -opslag ondersteunen. De failoverscenario's in deze sectie zijn van toepassing op beide:
- Spark SQL in ACID-tabellen met Hive Warehouse Verbinding maken or(HWC) Setup met behulp van een HDInsight Interactive Query-cluster.
- Spark SQL-werkbelasting in niet-ACID-tabellen met behulp van een HDInsight Hadoop-cluster.
Voor scenario's waarin Spark werkt in de zelfstandige modus, moeten gecureerde gegevens en opgeslagen Spark Jars (voor Livy-taken) regelmatig worden gerepliceerd van de primaire regio naar de secundaire regio met behulp van Azure Data Factory DistCP.
U wordt aangeraden versiebeheersystemen te gebruiken om Spark-notebooks en -bibliotheken op te slaan, waar ze eenvoudig kunnen worden geïmplementeerd op primaire of secundaire clusters. Zorg ervoor dat op notebooks gebaseerde en niet-notebookoplossingen zijn voorbereid om de juiste gegevenskoppelingen in de primaire of secundaire werkruimte te laden.
Als er klantspecifieke bibliotheken zijn die verder gaan dan wat HDInsight systeemeigen biedt, moeten ze worden bijgehouden en periodiek in het secundaire stand-bycluster worden geladen.
RPO en RTO voor Apache Spark-replicatie
RPO: Het gegevensverlies is beperkt tot de laatste geslaagde incrementele replicatie (Spark en Hive) van primair naar secundair.
RTO: De tijd tussen de fout en de hervatting van upstream- en downstreamtransacties met de secundaire.
Apache Spark-architecturen
Actieve primaire spark met secundaire on-demand
Toepassingen lezen en schrijven naar Spark- en Hive-clusters in de primaire regio, terwijl er tijdens normale bewerkingen geen clusters worden ingericht in de secundaire regio. SQL Metastore, Hive Storage en Spark Storage zijn permanent in de secundaire regio. De Spark- en Hive-clusters worden gescript en geïmplementeerd op aanvraag. Hive-replicatie wordt gebruikt om Hive Storage en Hive-metastores te repliceren, terwijl Azure Data Factory's DistCP kunnen worden gebruikt om zelfstandige Spark-opslag te kopiëren. Hive-clusters moeten worden geïmplementeerd voordat elke Hive-replicatie wordt uitgevoerd vanwege de rekenkracht van afhankelijkheden DistCp .
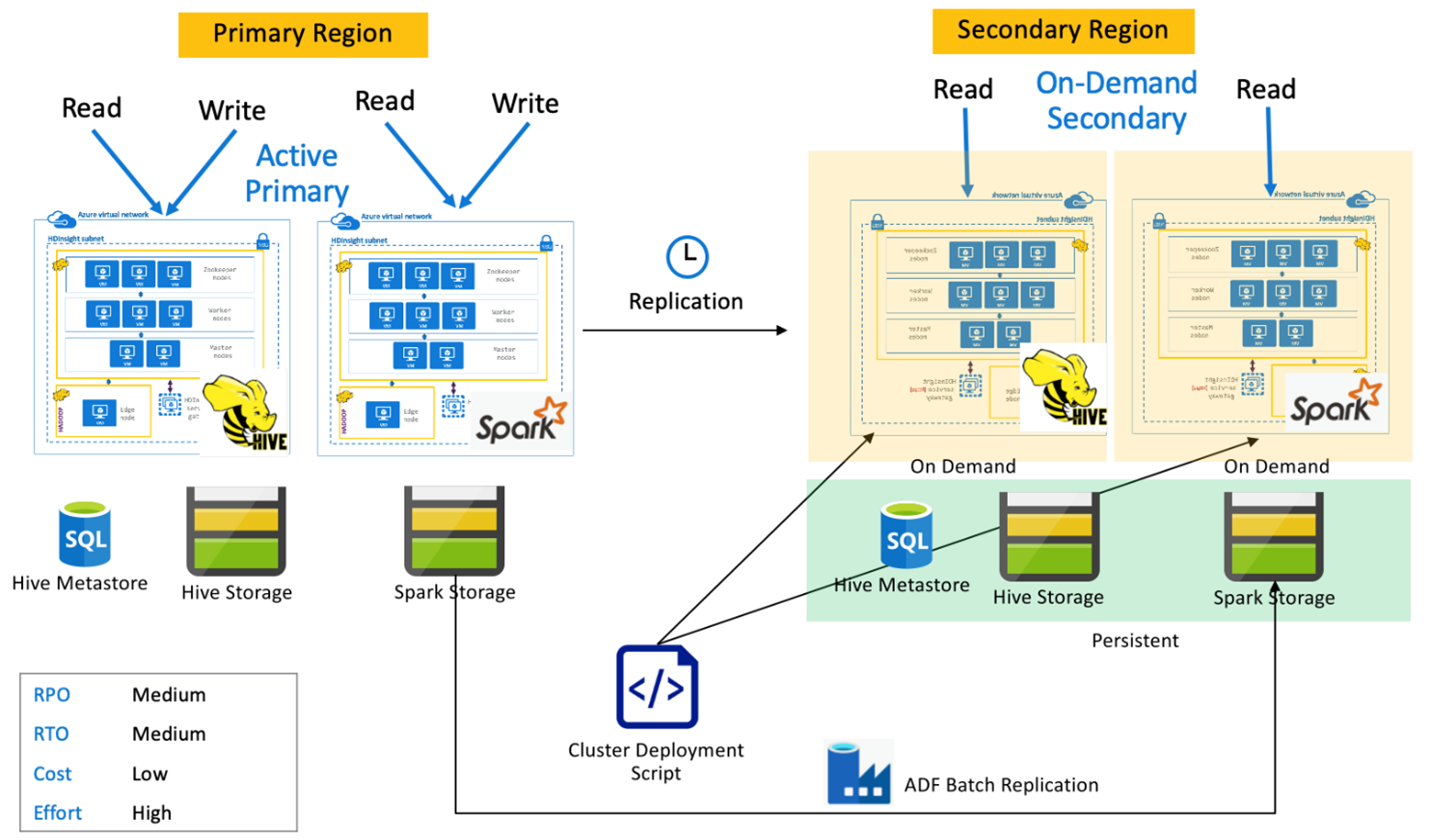
Actieve primaire spark met stand-by secundair
Toepassingen lezen en schrijven naar Spark- en Hive-clusters in de primaire regio, terwijl hive- en Spark-clusters in de modus Alleen-lezen worden uitgevoerd in de secundaire regio tijdens normale bewerkingen. Tijdens normale bewerkingen kunt u ervoor kiezen om regiospecifieke Hive- en Spark-leesbewerkingen naar secundaire regio's te offloaden.
Apache HBase
HBase-export en HBase-replicatie zijn veelvoorkomende manieren om bedrijfscontinuïteit tussen HDInsight HBase-clusters mogelijk te maken.
HBase Export is een batchreplicatieproces dat gebruikmaakt van het HBase Export Utility om tabellen van het primaire HBase-cluster te exporteren naar de onderliggende Azure Data Lake Storage Gen 2-opslag. De geëxporteerde gegevens kunnen vervolgens worden geopend vanuit het secundaire HBase-cluster en geïmporteerd in tabellen die vooraf moeten bestaan in de secundaire. Hoewel HBase Export wel granulariteit op tabelniveau biedt, bepaalt de exportautomatiseringsengine in incrementele updatesituaties het bereik van incrementele rijen die in elke uitvoering moeten worden opgenomen. Zie HDInsight HBase Backup and Replication voor meer informatie.
HBase Replication maakt gebruik van bijna realtime replicatie tussen HBase-clusters op een volledig geautomatiseerde manier. Replicatie wordt uitgevoerd op tabelniveau. Alle tabellen of specifieke tabellen kunnen worden gericht op replicatie. HBase-replicatie is uiteindelijk consistent, wat betekent dat recente bewerkingen in een tabel in de primaire regio mogelijk niet direct beschikbaar zijn voor alle secundaire databases. Secundaire databases worden uiteindelijk gegarandeerd consistent met de primaire. HBase-replicatie kan worden ingesteld tussen twee of meer HDInsight HBase-clusters als:
- Primaire en secundaire bevinden zich in hetzelfde virtuele netwerk.
- Primaire en secundaire netwerken bevinden zich in verschillende gekoppelde VNets in dezelfde regio.
- Primaire en secundaire netwerken bevinden zich in verschillende gekoppelde VNets in verschillende regio's.
Zie Apache HBase-clusterreplicatie instellen in virtuele Azure-netwerken voor meer informatie.
Er zijn een paar andere manieren om back-ups van HBase-clusters uit te voeren, zoals het kopiëren van de hbase-map, het kopiëren van tabellen en momentopnamen.
HBase RPO & RTO
HBase Exporteren
- RPO: Gegevensverlies is beperkt tot de laatste geslaagde batch incrementele import door de secundaire van de primaire.
- RTO: De tijd tussen het mislukken van de primaire en hervatting van I/O-bewerkingen op de secundaire.
HBase-replicatie
- RPO: Gegevensverlies is beperkt tot de laatste WalEdit-zending die is ontvangen op de secundaire.
- RTO: De tijd tussen het mislukken van de primaire en hervatting van I/O-bewerkingen op de secundaire.
HBase-architecturen
HBase-replicatie kan worden ingesteld in drie modi: Leader-Follower, Leader-Leader en Cyclic.
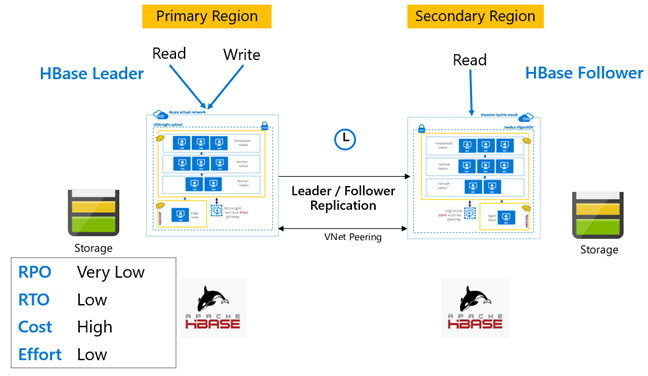
HBase-replicatie: Leider – Volgmodel
In deze cross-region set-up is replicatie unidirectioneel van de primaire regio naar de secundaire regio. Alle tabellen of specifieke tabellen op de primaire tabel kunnen worden geïdentificeerd voor unidirectionele replicatie. Tijdens normale bewerkingen kan het secundaire cluster worden gebruikt om leesaanvragen in een eigen regio te verwerken.
Het secundaire cluster werkt als een normaal HBase-cluster dat eigen tabellen kan hosten en lees- en schrijfbewerkingen kan verwerken vanuit regionale toepassingen. Schrijfbewerkingen op de gerepliceerde tabellen of tabellen die systeemeigen naar secundair zijn, worden echter niet terug gerepliceerd naar de primaire tabel.
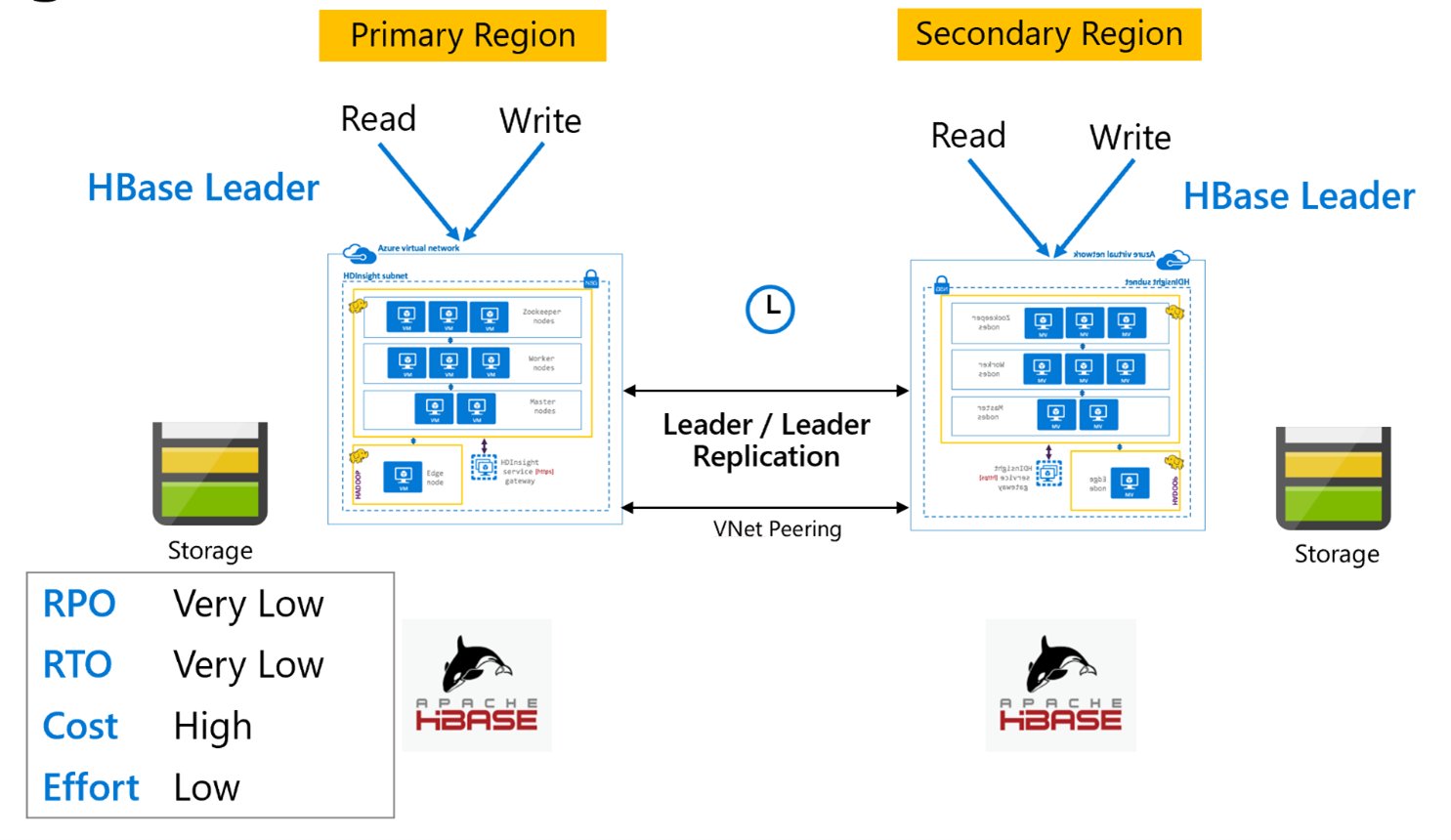
HBase-replicatie: Leader - Leader-model
Deze set-in meerdere regio's is vergelijkbaar met de unidirectionele set, behalve dat replicatie in twee richtingen plaatsvindt tussen de primaire regio en de secundaire regio. Toepassingen kunnen beide clusters gebruiken in lees-schrijfmodi en updates worden asynchroon uitgewisseld.
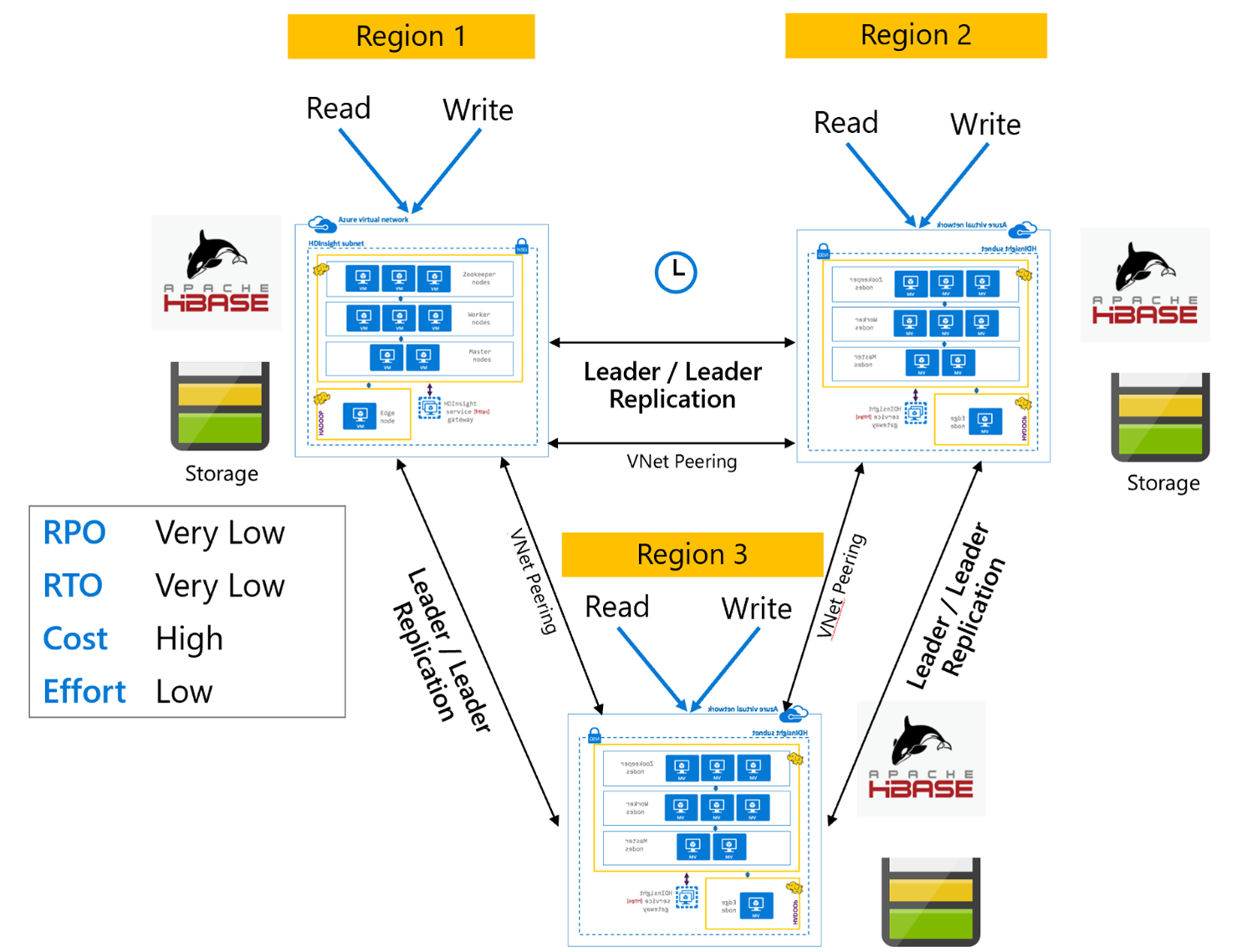
HBase-replicatie: meerdere regio's of cyclische
Het replicatiemodel voor meerdere regio's/cyclisch is een uitbreiding van HBase-replicatie en kan worden gebruikt om een wereldwijd redundante HBase-architectuur te maken met meerdere toepassingen die HBase-clusters lezen en schrijven naar regiospecifieke HBase-clusters. De clusters kunnen worden ingesteld in verschillende combinaties van Leader/Leader of Leader/Follower, afhankelijk van de bedrijfsvereisten.
Apache Kafka
HdInsight 4.0 ondersteunt Kafka MirrorMaker om beschikbaarheid tussen regio's mogelijk te maken. Deze kan worden gebruikt voor het onderhouden van een secundaire replica van het primaire Kafka-cluster in een andere regio. MirrorMaker fungeert als een consumenten-producentpaar op hoog niveau, verbruikt van een specifiek onderwerp in het primaire cluster en produceert naar een onderwerp met dezelfde naam in de secundaire. Replicatie tussen clusters voor herstel na noodgevallen met hoge beschikbaarheid met Behulp van MirrorMaker wordt ervan uitgegaan dat producenten en consumenten een failover naar het replicacluster moeten uitvoeren. Zie MirrorMaker gebruiken om Apache Kafka-onderwerpen te repliceren met Kafka in HDInsight voor meer informatie
Afhankelijk van de levensduur van het onderwerp wanneer de replicatie is gestart, kan mirrorMaker-onderwerpreplicatie leiden tot verschillende verschuivingen tussen bron- en replicaonderwerpen. HDInsight Kafka-clusters ondersteunen ook replicatie van onderwerppartities. Dit is een functie voor hoge beschikbaarheid op het niveau van het afzonderlijke cluster.
Apache Kafka-architecturen
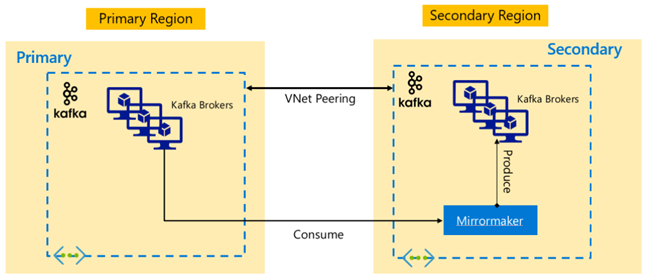
Kafka-replicatie: actief – passief
Active-Passive setup maakt asynchrone unidirectionele spiegeling van Actief naar Passief mogelijk. Producenten en consumenten moeten op de hoogte zijn van het bestaan van een actief en passief cluster en moeten gereed zijn om een failover naar het passieve cluster uit te kunnen geven voor het geval de actieve fout optreedt. Hieronder ziet u enkele voor- en nadelen van actief-passieve installatie.
Voordelen:
- Netwerklatentie tussen clusters heeft geen invloed op de prestaties van het actieve cluster.
- Eenvoud van unidirectionele replicatie.
Nadelen:
- Het passieve cluster kan onderbenut blijven.
- Ontwerpcomplexiteit bij het opnemen van failoverbewustzijn in toepassingsproducenten en consumenten.
- Mogelijk gegevensverlies tijdens het mislukken van het actieve cluster.
- Uiteindelijke consistentie tussen onderwerpen tussen actieve en passieve clusters.
- Failbacks naar Primair kunnen leiden tot inconsistentie van berichten in onderwerpen.
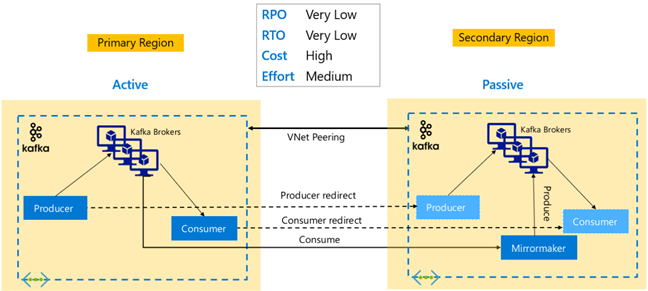
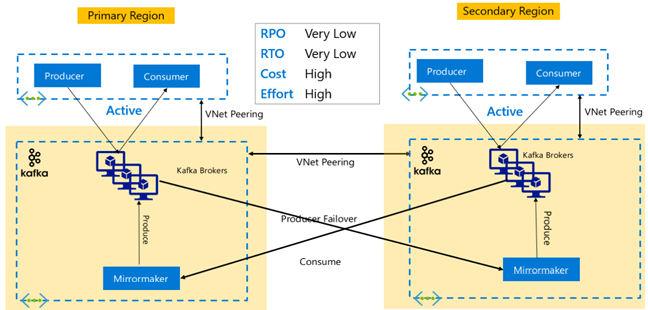
Kafka-replicatie: Actief – Actief
Active-Active-set-up omvat twee regionaal gescheiden VNet-gekoppelde HDInsight Kafka-clusters met bidirectionele asynchrone replicatie met MirrorMaker. In dit ontwerp worden berichten die door de consumenten in het primaire model worden gebruikt, ook beschikbaar gesteld aan consumenten in secundaire en omgekeerde. Hieronder ziet u enkele voor- en nadelen van Active-Active Setup.
Voordelen:
- Vanwege hun gedupliceerde status zijn failovers en failbacks eenvoudiger uit te voeren.
Nadelen:
- Instellen, beheren en bewaken is complexer dan Actief-Passief.
- Het probleem van circulaire replicatie moet worden aangepakt.
- Bidirectionele replicatie leidt tot hogere regionale kosten voor uitgaand gegevensverkeer.
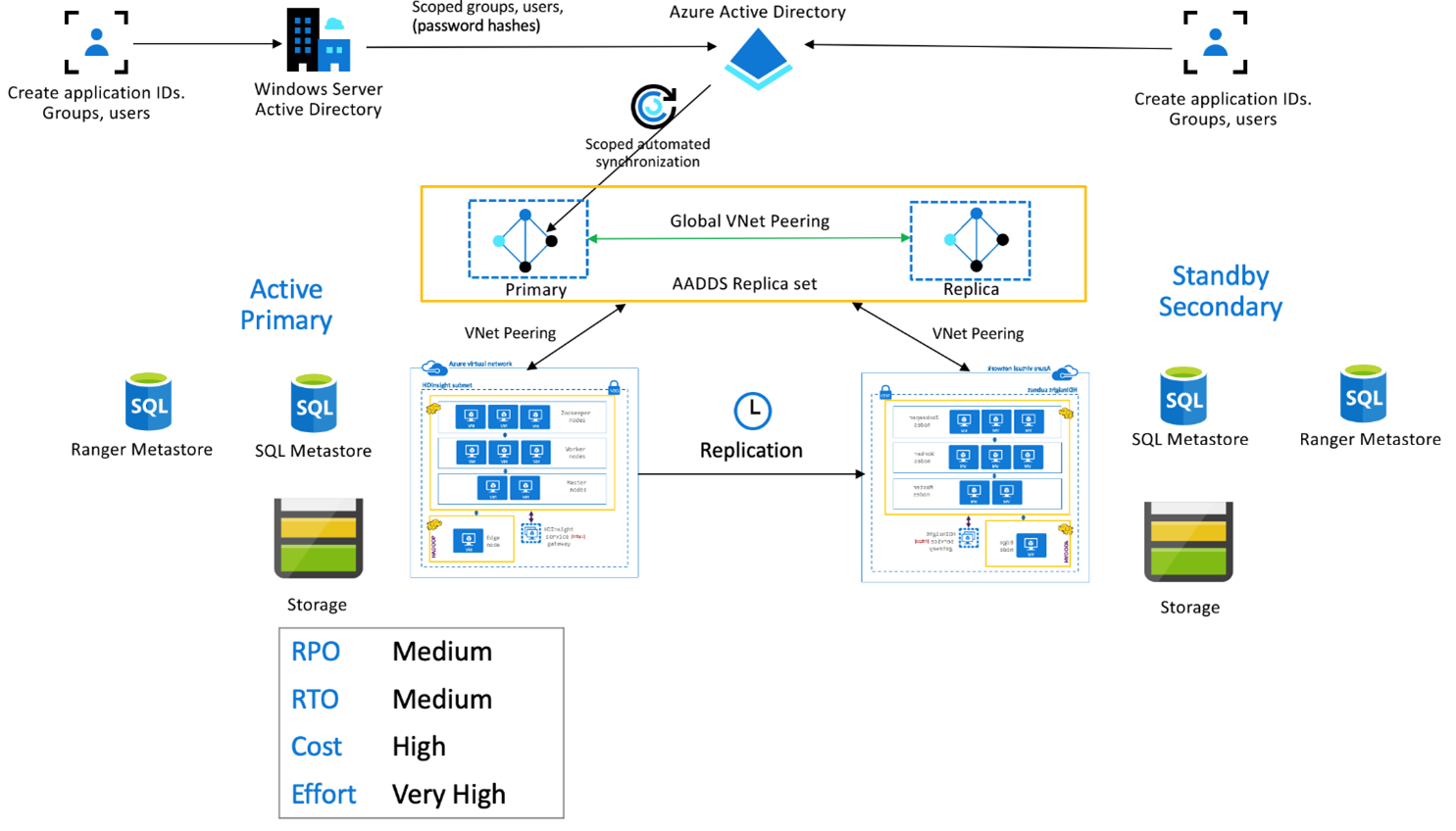
HDInsight Enterprise Security Package
Deze configuratie wordt gebruikt om functionaliteit voor meerdere gebruikers in te schakelen in zowel primaire als secundaire replicasets, evenals Replicasets van Microsoft Entra Domain Services om ervoor te zorgen dat gebruikers zich kunnen verifiëren bij beide clusters. Tijdens normale bewerkingen moet Ranger-beleid worden ingesteld in de secundaire site om ervoor te zorgen dat gebruikers worden beperkt tot leesbewerkingen. In de onderstaande architectuur wordt uitgelegd hoe een met ESP ingeschakelde Hive Active Primary - Stand-by secundaire instelling er mogelijk uitziet.
Ranger Metastore-replicatie:
Ranger Metastore wordt gebruikt voor het permanent opslaan en bedienen van Ranger-beleid voor het beheren van gegevensautor. We raden u aan onafhankelijke Ranger-beleidsregels te onderhouden in primaire en secundaire en de secundaire te onderhouden als een leesreplica.
Als u Ranger-beleid synchroon wilt houden tussen primaire en secundaire beleidsregels, gebruikt u Ranger Import/Export om periodiek een back-up te maken en Ranger-beleid te importeren van primair naar secundair.
Het repliceren van Ranger-beleid tussen primaire en secundaire beleidsregels kan ertoe leiden dat de secundaire wordt ingeschakeld voor schrijven, wat kan leiden tot onbedoelde schrijfbewerkingen op de secundaire voorloop naar inconsistenties van gegevens.
Volgende stappen
Zie voor meer informatie over de items die in dit artikel worden besproken: