Casestudy voor azure HDInsight-oplossingsarchitectuur met hoge beschikbaarheid
De replicatiemechanismen van Azure HDInsight kunnen worden geïntegreerd in een oplossingsarchitectuur met hoge beschikbaarheid. In dit artikel wordt een fictieve casestudy voor Contoso Retail gebruikt om mogelijke benaderingen voor herstel na noodgevallen met hoge beschikbaarheid, kostenoverwegingen en hun bijbehorende ontwerpen uit te leggen.
Aanbevelingen voor herstel na noodgevallen met hoge beschikbaarheid kunnen veel permutaties en combinaties hebben. Deze oplossingen moeten worden aangekomen na het in deibereren van de voor- en nadelen van elke optie. In dit artikel wordt slechts één mogelijke oplossing besproken.
In de volgende afbeelding ziet u de primaire architectuur van Contoso Retail. De architectuur bestaat uit een streamingworkload, batchworkload, serverlaag, verbruikslaag, opslaglaag en versiebeheer.
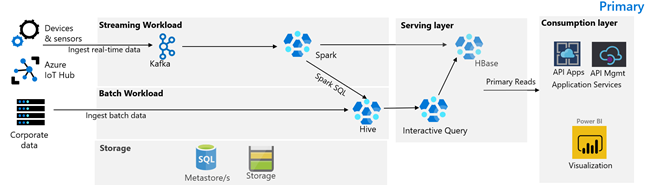
Apparaten en sensoren produceren gegevens naar HDInsight Kafka, dat het berichtenframework vormt. Een HDInsight Spark-consument leest uit de Kafka-onderwerpen. Spark transformeert de binnenkomende berichten en schrijft deze naar een HDInsight HBase-cluster op de ondersteunende laag.
Een HDInsight Hadoop-cluster met Hive en MapReduce neemt gegevens op van on-premises transactionele systemen. Onbewerkte gegevens die worden getransformeerd door Hive en MapReduce, worden opgeslagen in Hive-tabellen op een logische partitie van de data lake die wordt ondersteund door Azure Data Lake Storage Gen2. Gegevens die zijn opgeslagen in Hive-tabellen, worden ook beschikbaar gesteld voor Spark SQL. Hiermee worden batchtransformaties uitgevoerd voordat de gecureerde gegevens in HBase worden opgeslagen voor de service.
Een HDInsight HBase-cluster met Apache Phoenix wordt gebruikt om gegevens te leveren aan webtoepassingen en visualisatiedashboards. Een HDInsight LLAP-cluster wordt gebruikt om te voldoen aan interne rapportagevereisten.
Een Azure API Apps- en API Management-laag terug een openbare webpagina. Aan de vereisten voor interne rapportage wordt voldaan door Power BI.
Logisch gepartitioneerd Azure Data Lake Storage Gen2 wordt gebruikt als een data lake voor ondernemingen. De HDInsight-metastores worden ondersteund door Azure SQL DB.
Een versiebeheersysteem dat is geïntegreerd in een Azure Pipelines en wordt gehost buiten Azure.
Het is belangrijk om de minimale bedrijfsfunctionaliteit te bepalen die u nodig hebt als er een noodgeval is.
- We moeten worden beschermd tegen een regionale storing of regionale servicestatusprobleem.
- Mijn klanten mogen nooit een 404-fout zien. Openbare inhoud moet altijd worden geleverd. (RTO = 0)
- Gedurende het grootste deel van het jaar kunnen we openbare inhoud weergeven die vijf uur verouderd is. (RPO = 5 uur)
- Tijdens het feestdagenseizoen moet onze openbare inhoud altijd up-to-date zijn. (RPO = 0)
- Mijn interne rapportagevereisten worden niet beschouwd als essentieel voor bedrijfscontinuïteit.
- Kosten voor bedrijfscontinuïteit optimaliseren.
In de volgende afbeelding ziet u de architectuur voor herstel na noodgevallen met hoge beschikbaarheid van Contoso Retail.
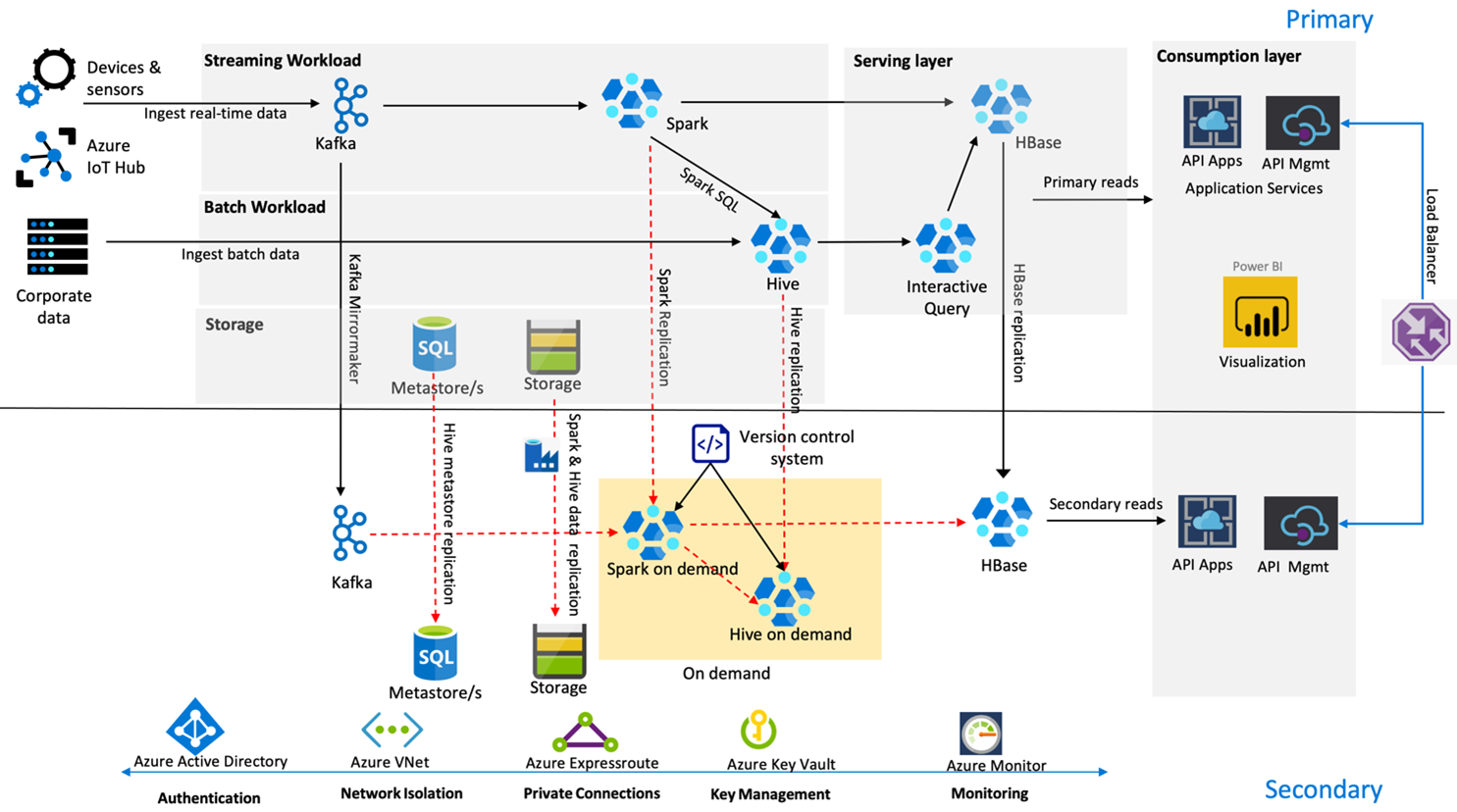
Kafka maakt gebruik van actieve– passieve replicatie om Kafka-onderwerpen van de primaire regio naar de secundaire regio te spiegelen. Een alternatief voor Kafka-replicatie kan zijn om te produceren naar Kafka in beide regio's.
Hive en Spark gebruiken actieve primaire - secundaire replicatiemodellen op aanvraag tijdens normale tijden. Het Hive-replicatieproces wordt periodiek uitgevoerd en begeleidt de replicatie van de Hive Azure SQL-metastore en het Hive-opslagaccount. Het Spark-opslagaccount wordt periodiek gerepliceerd met behulp van ADF DistCP. De tijdelijke aard van deze clusters helpt de kosten te optimaliseren. Replicaties worden elke 4 uur gepland om bij een RPO te komen die ruim binnen de vereiste van vijf uur valt.
HBase-replicatie maakt gebruik van het Leader – Follower-model tijdens normale tijden om ervoor te zorgen dat gegevens altijd worden geleverd, ongeacht de regio en dat de RPO zeer laag is.
Als er sprake is van een regionale fout in de primaire regio, worden de webpagina- en back-endinhoud gedurende 5 uur geleverd vanuit de secundaire regio met enige mate van veroudering. Als het dashboard voor de status van de Azure-service geen herstel-ETA aangeeft in het venster van vijf uur, maakt Contoso Retail de Hive- en Spark-transformatielaag in de secundaire regio en wijst alle upstream-gegevensbronnen vervolgens naar de secundaire regio. Als u de secundaire regio beschrijfbaar maakt, wordt er een failbackproces uitgevoerd waarbij replicatie wordt teruggezet naar de primaire regio.
Tijdens een hoogseizoen is de volledige secundaire pijplijn altijd actief en actief. Kafka-producenten produceren in beide regio's en de HBase-replicatie wordt gewijzigd van Leader-Follower in Leader-Leader om ervoor te zorgen dat openbare inhoud altijd up-to-date is.
Er hoeft geen failoveroplossing te worden ontworpen voor interne rapportage, omdat deze niet essentieel is voor bedrijfscontinuïteit.
Zie voor meer informatie over de items die in dit artikel worden besproken: