Apache Hive-replicatie gebruiken in Azure HDInsight-clusters
In de context van databases en magazijnen is replicatie het proces van het dupliceren van entiteiten van het ene naar het andere magazijn. Duplicatie kan worden toegepast op een hele database of op een kleiner niveau, zoals een tabel of partitie. Het doel is om een replica te hebben die wordt gewijzigd wanneer de basisentiteit wordt gewijzigd. Replicatie op Apache Hive is gericht op herstel na noodgevallen en biedt unidirectionele replicatie van primaire kopieerbewerkingen. In HDInsight-clusters kan Hive-replicatie worden gebruikt om de Hive-metastore en de bijbehorende onderliggende data lake in Azure Data Lake Storage Gen2 unidirectioneel te repliceren.
Hive Replication is in de loop der jaren ontwikkeld met nieuwere versies die betere functionaliteit bieden en sneller en minder resource-intensief zijn. In dit artikel bespreken we Hive-replicatie (Replv2) die wordt ondersteund in zowel HDInsight 3.6- als HDInsight 4.0-clustertypen.
Hive ReplicationV2 (ook wel genoemd Replv2) heeft de volgende voordelen ten opzichte van de eerste versie van Hive-replicatie die Hive IMPORT-EXPORT heeft gebruikt:
- Incrementele replicatie op basis van gebeurtenissen
- Point-in-time-replicatie
- Beperkte bandbreedtevereisten
- Vermindering van het aantal tussenliggende exemplaren
- De replicatiestatus wordt gehandhaafd
- Beperkte replicatie
- Ondersteuning voor een hub- en spoke-model
- Ondersteuning voor ACID-tabellen (in HDInsight 4.0)
Hive-replicatie op basis van gebeurtenissen wordt geconfigureerd tussen de primaire en secundaire clusters. Deze replicatie bestaat uit twee afzonderlijke fasen: bootstrapping en incrementele uitvoeringen.
Bootstrapping is bedoeld om eenmaal uit te voeren om de basisstatus van de databases van primair naar secundair te repliceren. U kunt bootstrapping zo nodig configureren om een subset van de tabellen in de doeldatabase op te nemen waarvoor replicatie moet worden ingeschakeld.
Na het opstarten worden incrementele uitvoeringen geautomatiseerd op het primaire cluster en worden gebeurtenissen die tijdens deze incrementele uitvoeringen worden gegenereerd, afgespeeld op het secundaire cluster. Wanneer het secundaire cluster bij het primaire cluster komt, wordt de secundaire consistent met de gebeurtenissen van de primaire cluster.
Hive biedt een set REPL-opdrachten , DUMPLOADen STATUS - voor het organiseren van de stroom van gebeurtenissen. Met de DUMP opdracht wordt een lokaal logboek gegenereerd van alle DDL/DML-gebeurtenissen op het primaire cluster. De LOAD opdracht is een methode voor het lui kopiëren van metagegevens en gegevens die zijn vastgelegd in de geëxtraheerde uitvoer van de replicatiedump en wordt uitgevoerd op het doelcluster. De STATUS opdracht wordt uitgevoerd vanuit het doelcluster om de meest recente gebeurtenis-id op te geven die de meest recente replicatiebelasting is gerepliceerd.
Voordat u begint met replicatie, moet u ervoor zorgen dat de database die moet worden gerepliceerd, is ingesteld als de replicatiebron. U kunt de DESC DATABASE EXTENDED <db_name> opdracht gebruiken om te bepalen of de parameter repl.source.for is ingesteld met de beleidsnaam.
Als het beleid is gepland en de repl.source.for parameter niet is ingesteld, moet u deze parameter eerst instellen met behulp van ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
De REPL DUMP [database name]. => location / event_id opdracht wordt gebruikt in de bootstrapfase om relevante metagegevens naar Azure Data Lake Storage Gen2 te dumpen. Hiermee event_id geeft u de minimale gebeurtenis op waarnaar relevante metagegevens zijn geplaatst in Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Voorbeelduitvoer:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
De REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } opdracht wordt gebruikt om gegevens in het doelcluster te laden voor zowel de bootstrap als de incrementele fasen van replicatie. Dit [database name] kan hetzelfde zijn als de bron of een andere naam op het doelcluster. De [location] vertegenwoordigt de locatie uit de uitvoer van een eerdere REPL DUMP opdracht. Dit betekent dat het doelcluster moet kunnen communiceren met het broncluster. De WITH component is voornamelijk toegevoegd om te voorkomen dat het doelcluster opnieuw wordt opgestart, waardoor replicatie mogelijk is.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
De REPL STATUS [database name] opdracht wordt uitgevoerd op doelclusters en voert de laatst gerepliceerde uitvoer uit event_id. Met de opdracht kunnen gebruikers ook weten naar welke status hun doelcluster is gerepliceerd. U kunt de uitvoer van deze opdracht gebruiken om de volgende REPL DUMP opdracht te maken voor incrementele replicatie.
repl status tpcds_orc;
Voorbeelduitvoer:
| last_repl_id |
|---|
| 2925 |
De REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } opdracht wordt gebruikt om relevante metagegevens en gegevens te dumpen naar Azure Data Lake Storage. Deze opdracht wordt gebruikt in de incrementele fase en wordt uitgevoerd op het bronwarehouse. Dit FROM [event-id] is vereist voor de incrementele fase en de waarde ervan event-id kan worden afgeleid door de REPL STATUS [database name] opdracht uit te voeren op het doelwarehouse.
repl dump tpcds_orc from 2925;
Voorbeelduitvoer:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46646agad0 | 2960 |
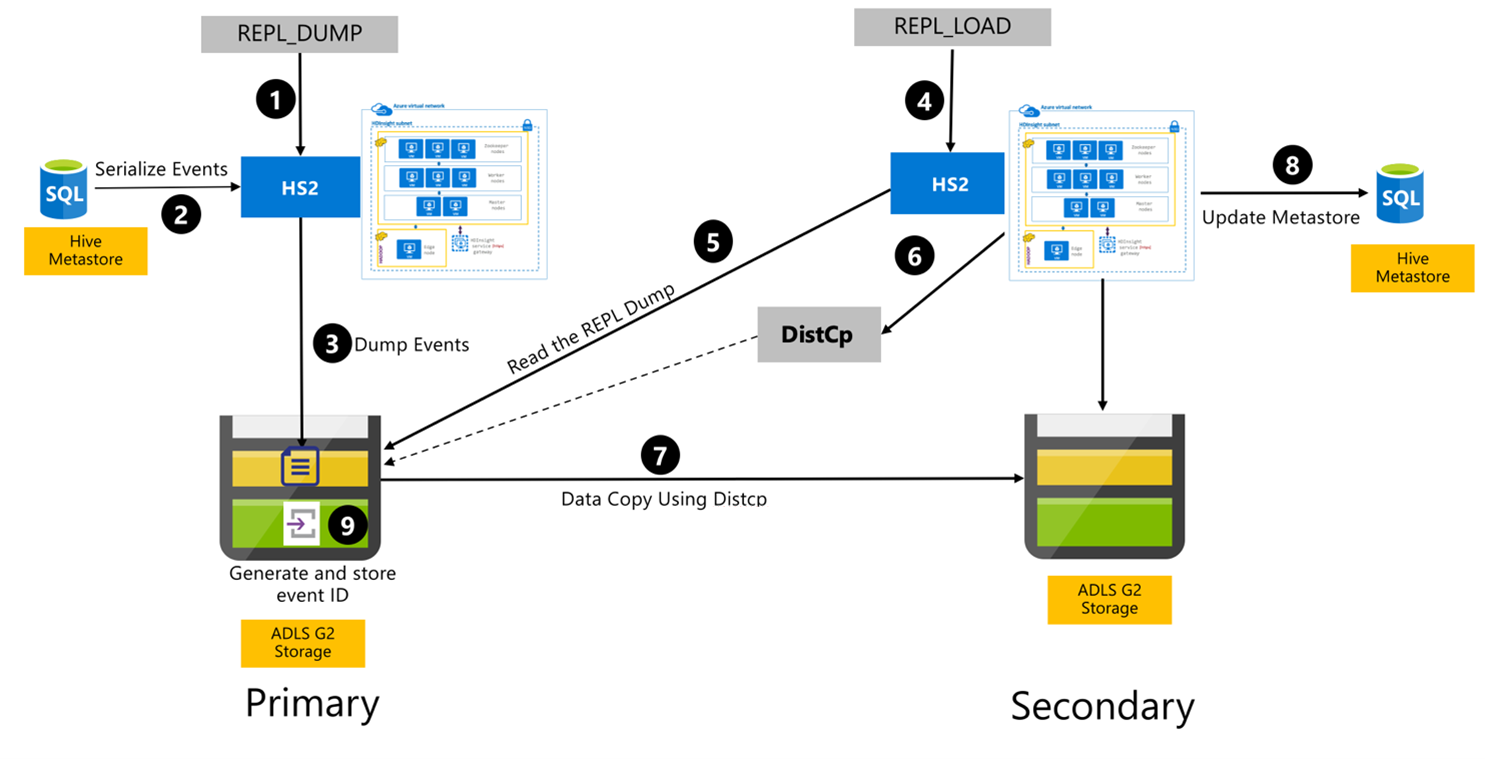
De volgende stappen zijn de opeenvolgende gebeurtenissen die plaatsvinden tijdens het Hive-replicatieproces.
Zorg ervoor dat de tabellen die moeten worden gerepliceerd, zijn ingesteld als de replicatiebron voor een bepaald beleid.
De
REPL_DUMPopdracht wordt uitgegeven aan het primaire cluster met gekoppelde beperkingen, zoals databasenaam, gebeurtenis-id-bereik en Azure Data Lake Storage Gen2-opslag-URL.Het systeem serialiseert een dump van alle bijgehouden gebeurtenissen van de metastore naar de nieuwste. Deze dump wordt opgeslagen in het Azure Data Lake Storage Gen2-opslagaccount op het primaire cluster op de URL die is opgegeven door de
REPL_DUMP.Het primaire cluster bewaart de replicatiemetagegevens naar de Azure Data Lake Storage Gen2-opslag van het primaire cluster. Het pad kan worden geconfigureerd in de Hive-configuratiegebruikersinterface in Ambari. Het proces biedt het pad waar de metagegevens worden opgeslagen en de id van de meest recente bijgehouden DML/DDL-gebeurtenis.
De
REPL_LOADopdracht wordt uitgegeven vanuit het secundaire cluster. De opdracht verwijst naar het pad dat is geconfigureerd in stap 3.Het secundaire cluster leest het metagegevensbestand met bijgehouden gebeurtenissen die zijn gemaakt in stap 3. Zorg ervoor dat het secundaire cluster netwerkconnectiviteit heeft met de Azure Data Lake Storage Gen2-opslag van het primaire cluster waar de bijgehouden gebeurtenissen vandaan
REPL_DUMPworden opgeslagen.Het secundaire cluster spawns gedistribueerde kopie (
DistCPrekenkracht).Het secundaire cluster kopieert gegevens uit de opslag van het primaire cluster.
De metastore op het secundaire cluster wordt bijgewerkt.
De laatst bijgehouden gebeurtenis-id wordt opgeslagen in de primaire metastore.
Incrementele replicatie volgt hetzelfde proces en vereist de laatste gerepliceerde gebeurtenis-id als invoer. Dit leidt tot een incrementele kopie sinds de laatste replicatie-gebeurtenis. Incrementele replicaties worden normaal gesproken geautomatiseerd met een vooraf bepaalde frequentie om de vereiste beoogde beoogde herstelpunten (RPO) te bereiken.
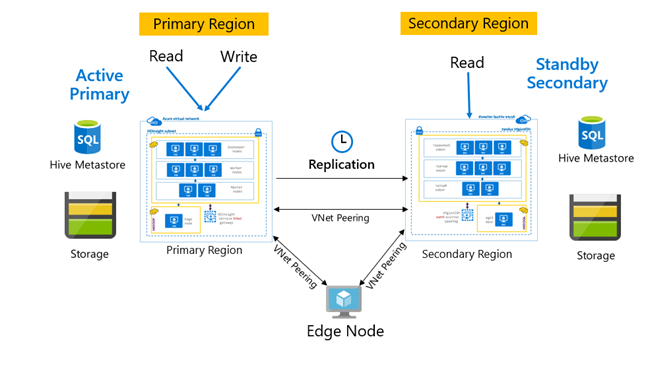
Replicatie wordt normaal gesproken op een unidirectionele manier geconfigureerd tussen de primaire en secundaire, waar de primaire geschikt is voor lees- en schrijfaanvragen. Het secundaire cluster is alleen geschikt voor leesaanvragen. Schrijfbewerkingen zijn toegestaan op de secundaire als er een noodgeval is, maar omgekeerde replicatie moet worden geconfigureerd naar de primaire.
Er zijn veel patronen die geschikt zijn voor Hive-replicatie, waaronder primair, secundair, hub en spoke en relay.
In HDInsight Active Primary – Standby Secondary is een gemeenschappelijk BCDR-patroon (bedrijfscontinuïteit en herstel na noodgevallen) en HiveReplicationV2 kan dit patroon worden gebruikt met regionaal gescheiden HDInsight Hadoop-clusters met VNet-peering. Een algemene virtuele machine die is gekoppeld aan beide clusters, kan worden gebruikt om de scripts voor replicatieautomatisering te hosten. Raadpleeg de documentatie over bedrijfscontinuïteit van HDInsight voor meer informatie over mogelijke HDInsight BCDR-patronen.
In gevallen waarin Hive-replicatie is gepland op HDInsight Hadoop-clusters met Enterprise Security Package, moet u rekening houden met replicatiemechanismen voor Ranger-metastore en Microsoft Entra Domain Services.
Gebruik de functie Microsoft Entra Domain Services-replicasets om meer dan één Microsoft Entra Domain Services-replicaset te maken per Microsoft Entra-tenant in meerdere regio's. Elke afzonderlijke replicaset moet worden gekoppeld aan HDInsight-VNets in hun respectieve regio's. In deze configuratie worden wijzigingen in Microsoft Entra Domain Services, waaronder configuratie, gebruikersidentiteit en referenties, groepen, groepsbeleidsobjecten, computerobjecten en andere wijzigingen toegepast op alle replicasets in het beheerde domein met behulp van Microsoft Entra Domain Services-replicatie.
Er kan periodiek een back-up van Ranger-beleid worden gemaakt en gerepliceerd van de primaire naar de secundaire met behulp van de functionaliteit Ranger Import-Export. U kunt ervoor kiezen om alle of een subset van Ranger-beleidsregels te repliceren, afhankelijk van het autorisatieniveau dat u wilt implementeren op het secundaire cluster.
De volgende codereeks bevat een voorbeeld van hoe bootstrapping en incrementele replicatie kunnen worden geïmplementeerd in een voorbeeldtabel met de naam tpcds_orc.
Stel de tabel in als de bron voor een replicatiebeleid.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Bootstrapdump op het primaire cluster.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Voorbeelduitvoer:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Bootstrapbelasting op het secundaire cluster.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Controleer de
REPLstatus op het secundaire cluster.repl status tpcds_orc;last_repl_id 2925 Incrementele dump op het primaire cluster.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Voorbeelduitvoer:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Incrementele belasting bij secundair cluster.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Controleer
REPLde status bij het secundaire cluster.repl status tpcds_orc;last_repl_id 2960
Zie voor meer informatie over de items die in dit artikel worden besproken: