Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u een Apache Hadoop-cluster op aanvraag in Azure HDInsight kunt maken met behulp van Azure Data Factory. Vervolgens gebruikt u gegevenspijplijnen in Azure Data Factory om Hive-taken uit te voeren en het cluster te verwijderen. In deze zelfstudie leert u hoe u een big data-taakuitvoering kunt operationalize, waarbij het maken van een cluster, het uitvoeren van een taak en het verwijderen van een cluster worden uitgevoerd volgens een schema.
Deze zelfstudie bestaat uit de volgende taken:
- Een Azure-opslagaccount maken
- Inzicht in Azure Data Factory-activiteit
- Een data factory maken met behulp van de Azure-portal
- Gekoppelde services maken
- Een pipeline maken
- Een pijplijn activeren
- Een pijplijn bewaken
- De uitvoer controleren
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
De Az-module van PowerShell geïnstalleerd.
Een Microsoft Entra-service-principal. Wanneer u de service-principal hebt gemaakt, moet u de toepassings-id en verificatiesleutel ophalen met behulp van de instructies in het gekoppelde artikel. U hebt deze waarden later in deze zelfstudie nodig. Deze service-principal moet bovendien lid zijn van de rol Inzender van het abonnement of de resourcegroep waarin het cluster is gemaakt. Zie Een Microsoft Entra-service-principal maken voor instructies voor het ophalen van de vereiste waarden en het toewijzen van de juiste rollen.
Voorlopige Azure-objecten maken
In deze sectie maakt u verschillende objecten die worden gebruikt voor het HDInsight-cluster dat u op aanvraag maakt. Het gemaakte opslagaccount bevat het HiveQL-voorbeeldscript, partitionweblogs.hql, dat u gebruikt voor het simuleren van een Apache Hive-voorbeeldtaak die wordt uitgevoerd op het cluster.
In deze sectie wordt gebruikgemaakt van een Azure PowerShell-script voor het maken van het opslagaccount en het kopiëren van de vereiste bestanden in het opslagaccount. Het Azure PowerShell-voorbeeldscript in deze sectie voert de volgende taken uit:
- Aanmelden bij Azure.
- Hiermee maakt u een Azure-resourcegroep.
- Hiermee wordt een Azure Storage-account gemaakt.
- Een blobcontainer in het opslagaccount maken
- Het HiveQL-voorbeeldscript (partitionweblogs.hql) kopiëren naar de blobcontainer. Het voorbeeldscript is al beschikbaar in een andere openbare blobcontainer. Het onderstaande PowerShell-script maakt een kopie van deze bestanden in het Azure Storage-account dat wordt gemaakt.
Opslagaccount maken en bestanden kopiëren
Belangrijk
Geef namen op voor de Azure-resourcegroep en het Azure Storage-account dat door het script wordt gemaakt. Noteer de naam van de resourcegroep, de naam van het opslagaccount en de sleutel van het opslagaccount die door het script worden uitgevoerd. U hebt deze in de volgende sectie nodig.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Opslagaccount verifiëren
- Meld u aan bij Azure Portal.
- Ga aan de linkerkant naar Alle services>Algemeen>Resourcegroepen.
- Selecteer de resourcegroepsnaam die u met het PowerShell-script hebt gemaakt. Gebruik het filter als er te veel resourcegroepen worden weergegeven.
- In de overzichtsweergave wordt één resource weergegeven, tenzij u de resourcegroep deelt met andere projecten. Deze resource is het opslagaccount met de naam die u eerder hebt opgegeven. Selecteer de naam van het opslagaccount.
- Selecteer de tegel Containers.
- Selecteer de container adfgetstarted. U ziet een map met de naam
hivescripts. - Open de map en zorg ervoor dat deze het voorbeeldscriptbestand partitionweblogs.hql bevat.
Inzicht in de Azure Data Factory-activiteit
Met Azure Data Factory wordt de verplaatsing en transformatie van gegevens beheerd en geautomatiseerd. Azure Data Factory kan een HDInsight Hadoop-cluster just-in-time maken om een invoergegevenssegment te verwerken en het cluster te verwijderen wanneer de verwerking is voltooid.
In Azure Data Factory kan een data factory een of meer gegevenspijplijnen hebben. Een gegevenspijplijn kan een of meer activiteiten bevatten. Er zijn twee soorten activiteiten:
- Activiteiten voor gegevensverplaatsing. Activiteiten voor gegevensverplaatsing worden gebruikt om gegevens van een brongegevensarchief te verplaatsen naar een doelgegevensarchief.
- Activiteiten voor gegevenstransformatie. Activiteiten voor gegevenstransformatie worden gebruikt om gegevens te transformeren/verwerken. HDInsight Hive-activiteit is een van de transformatieactiviteiten die door Data Factory worden ondersteund. U gebruikt de Hive-transformatieactiviteit in deze zelfstudie.
In dit artikel configureert u de Hive-activiteit voor het maken van een Hadoop-cluster op aanvraag in HDInsight. Wanneer de activiteit wordt uitgevoerd om gegevens te verwerken, gebeurt het volgende:
Er wordt automatisch just-in-time een HDInsight Hadoop-cluster voor u gemaakt om het segment te verwerken.
De invoergegevens worden verwerkt door een HiveQL-script op het cluster uit te voeren. In deze zelfstudie worden met het HiveQL-script dat aan de Hive-activiteit is gekoppeld, de volgende acties uitgevoerd:
- De bestaande tabel (hivesampletable) wordt gebruikt om een andere tabel (HiveSampleOut) te maken.
- De tabel HiveSampleOut wordt alleen gevuld met specifieke kolommen van de oorspronkelijke tabel, hivesampletable.
Het HDInsight Hadoop-cluster wordt verwijderd nadat de verwerking is voltooid en het cluster is inactief gedurende de ingestelde tijd (timeToLive-instelling). Als het volgende gegevenssegment beschikbaar is voor verwerking binnen deze timeToLive-tijd, wordt hetzelfde cluster gebruikt om het segment te verwerken.
Een data factory maken
Meld u aan bij het Azure-portaal.
Ga in het menu aan de linkerkant naar
+ Create a resource>Analyse>Data Factory.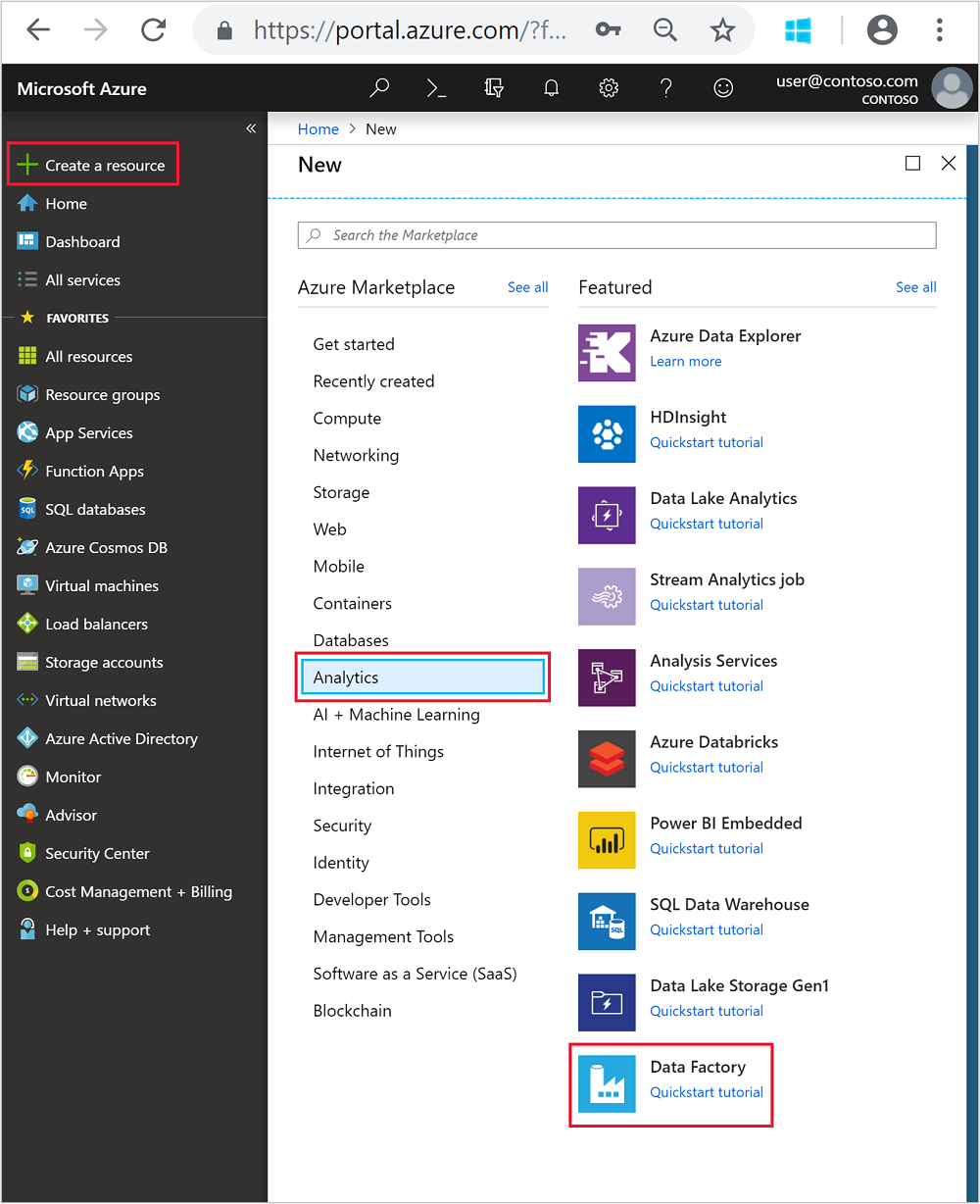
Typ of selecteer de volgende waarden voor de tegel Nieuwe data factory:
Eigenschappen Waarde Naam Voer een naam in voor de data factory. Deze naam moet wereldwijd uniek zijn. Versie Laat de versie ingesteld staan op V2. Abonnement Selecteer uw Azure-abonnement. Resourcegroep Selecteer de resourcegroep die u hebt gemaakt met behulp van het PowerShell-script. Locatie De locatie wordt automatisch ingesteld op de locatie die u eerder hebt opgegeven bij het maken van de resourcegroep. Voor deze zelfstudie is de locatie ingesteld op US - oost. GIT inschakelen Schakel dit selectievakje uit. 
Selecteer Maken. Het maken van een data factory duurt ongeveer twee tot vier minuten.
Zodra de data factory is gemaakt, ontvangt u de melding Implementatie voltooid met de knop Naar de resource gaan. Selecteer Naar de resource gaan om naar de standaardweergave van de data factory te gaan.
Selecteer Maken en controleren om de portal voor het maken en controleren van Azure Data Factory te starten.
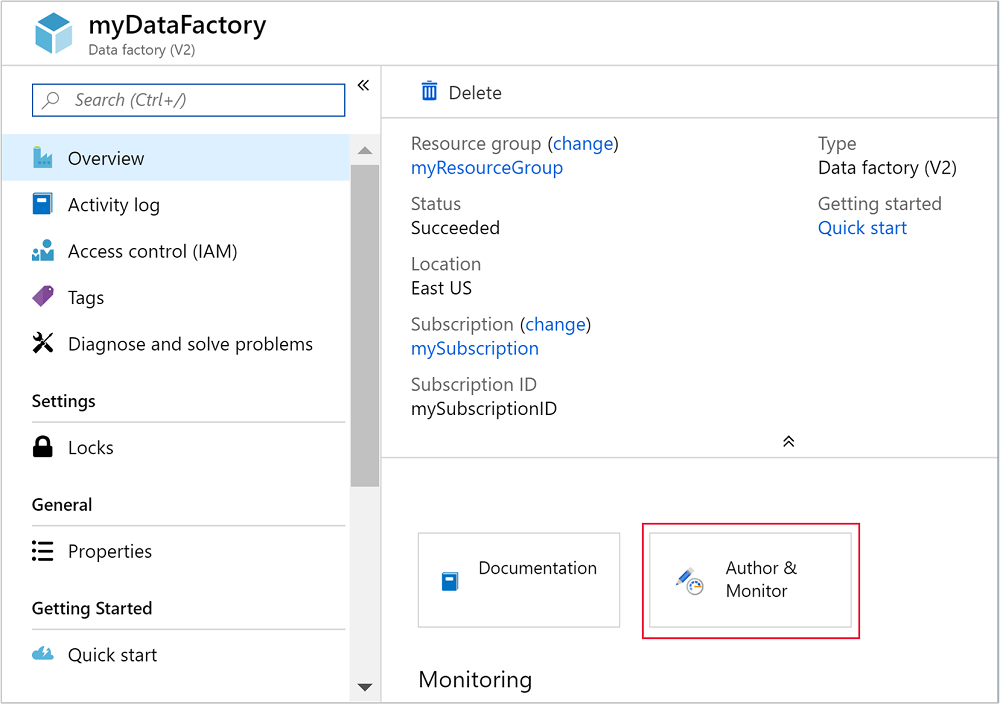
Gekoppelde services maken
In deze sectie maakt u twee gekoppelde services in uw data factory.
- Een gekoppelde Azure Storage-service waarmee een Azure-opslagaccount wordt gekoppeld aan de gegevensfactory. Deze opslag wordt gebruikt voor het HDInsight-cluster op aanvraag. Deze bevat ook het Hive-script dat wordt uitgevoerd op het cluster.
- Een gekoppelde HDInsight-service op aanvraag. Azure Data Factory maakt automatisch een HDInsight-cluster en voert het Hive-script uit. Het HDInsight-cluster wordt vervolgens verwijderd als het cluster gedurende een vooraf geconfigureerde tijd inactief is geweest.
Een gekoppelde Azure Storage-service maken
Selecteer in het linkerdeelvenster van de pagina Aan de slag het pictogram Auteur.

Selecteer Verbindingen in de hoek linksonder in het venster en selecteer + Nieuw.
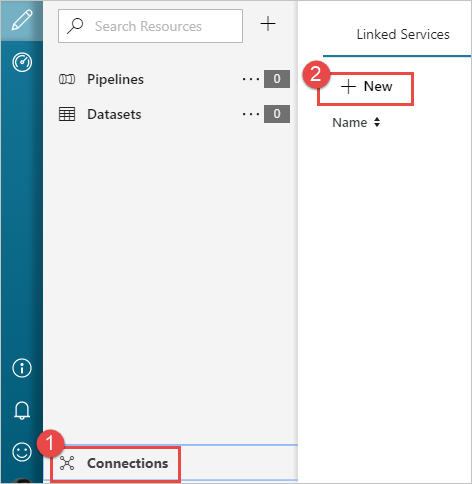
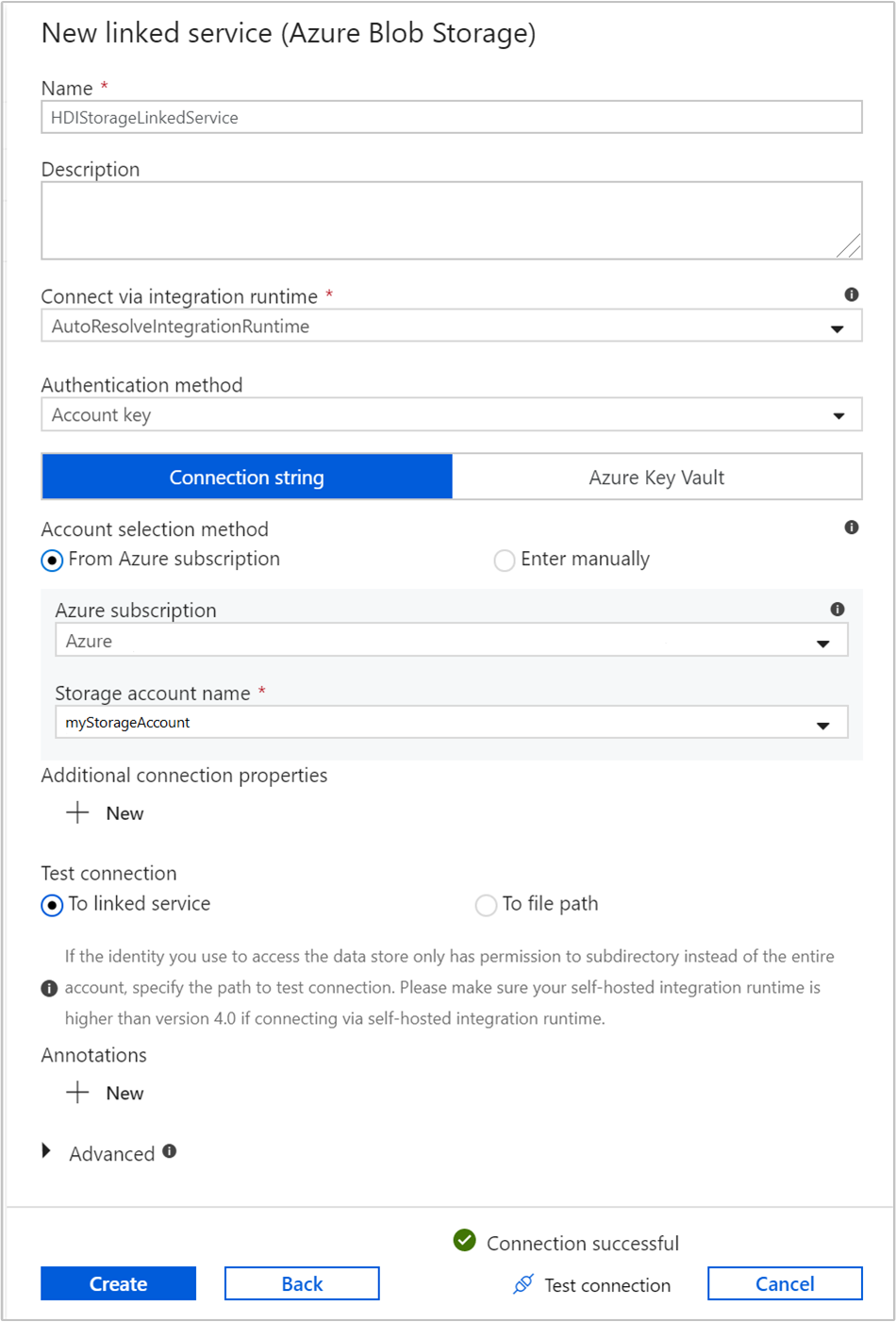
Selecteer in het dialoogvenster Nieuwe gekoppelde service de optie Azure Blob-opslag en selecteer vervolgensDoorgaan.
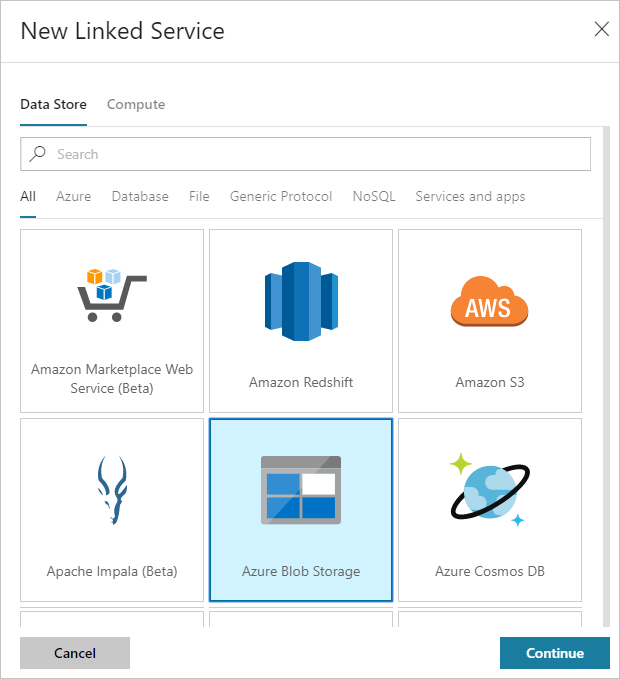
Geef de volgende waarden op voor de aan de opslag gekoppelde service:
Eigenschappen Waarde Naam Voer HDIStorageLinkedServicein.Azure-abonnement Selecteer uw abonnement in de vervolgkeuzelijst. Naam van het opslagaccount Selecteer het Azure Storage-account dat u hebt gemaakt als onderdeel van het PowerShell-script. Selecteer Verbinding testen en selecteer (na een geslaagde test) vervolgens Maken.
Een gekoppelde HDInsight-service op aanvraag maken
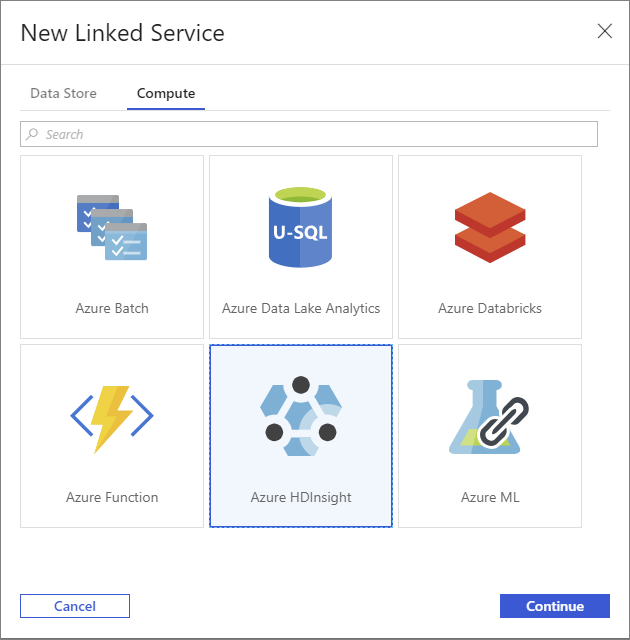
Selecteer nogmaals de knop + Nieuw om een andere gekoppelde service te maken.
Selecteer in het venster Nieuwe gekoppelde service het tabblad Berekening.
Selecteer Azure HDInsight en vervolgens Doorgaan.
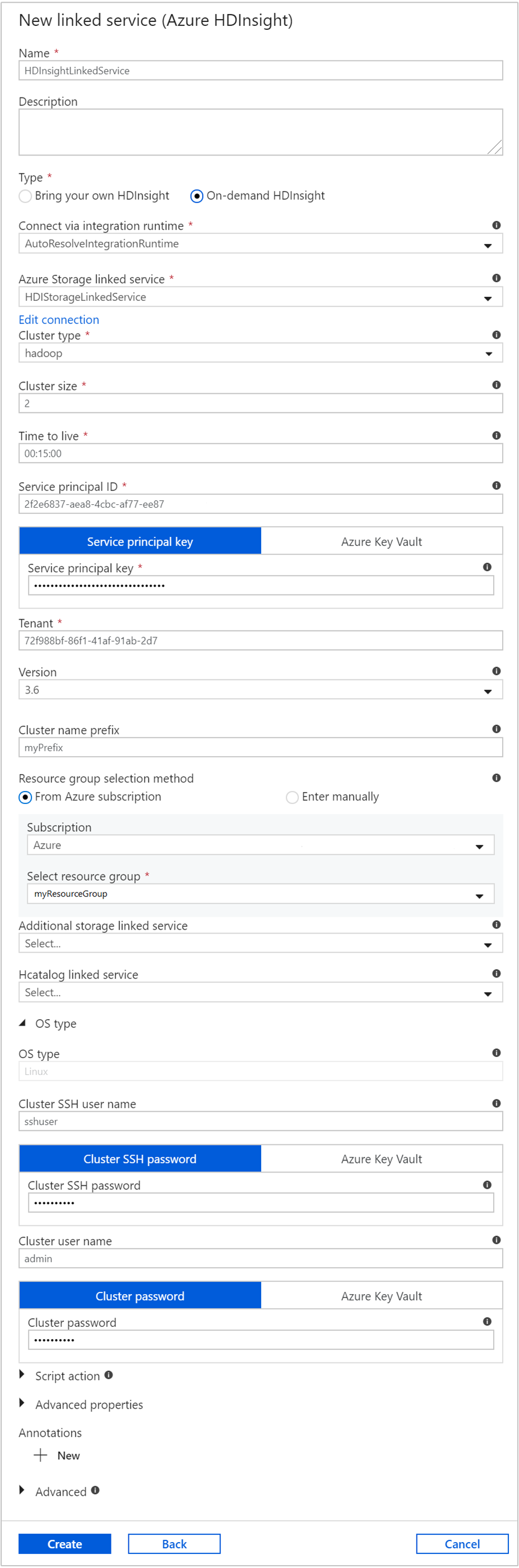
Voer in het venster Nieuwe gekoppelde service de volgende waarden in en laat de rest van de standaardwaarden ongewijzigd:
Eigenschappen Waarde Naam Voer HDInsightLinkedServicein.Type Selecteer HDInsight op aanvraag. Gekoppelde Azure Storage-service Selecteer HDIStorageLinkedService.Clustertype Selecteer hadoop Time to live Geef de tijdsduur dat het HDInsight-cluster beschikbaar moet blijven voordat het automatisch wordt verwijderd. Service-principal-id Geef de toepassings-id op van de Microsoft Entra-service-principal die u hebt gemaakt als onderdeel van de vereisten. Sleutel voor de service-principal Geef de verificatiesleutel op voor de Microsoft Entra-service-principal. Clusternaamvoorvoegsel Geef een waarde op die wordt toegevoegd aan het begin van de naam van elk clustertype dat met de data factory wordt gemaakt. Abonnement Selecteer uw abonnement in de vervolgkeuzelijst. Resourcegroep selecteren Selecteer de resourcegroep die u hebt gemaakt als onderdeel van het PowerShell-script dat u eerder hebt gebruikt. Type besturingssysteem/SSH-gebruikersnaam van het cluster Voer een SSH-gebruikersnaam in. Meestal is dit sshuser.Type besturingssysteem/SSH-wachtwoord van het cluster Geef een wachtwoord voor de SSH-gebruiker op Type besturingssysteem/gebruikersnaam van het cluster Voer een gebruikersnaam in voor het cluster. Meestal is dit admin.Type besturingssysteem/wachtwoord van het cluster Voer een wachtwoord voor de clustergebruiker in. Selecteer vervolgens Maken.
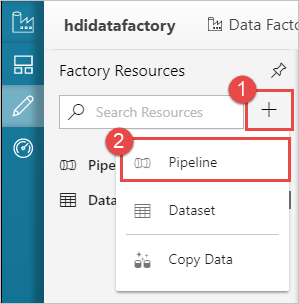
Een pipeline maken
Selecteer de knop + (plus) en selecteer vervolgens Pijplijn.
Vouw HDInsight uit in de werkset Activities en sleep de activiteit Hive naar het ontwerpoppervlak voor pijplijnen. Geef op het tabblad General een naam op voor de activiteit.
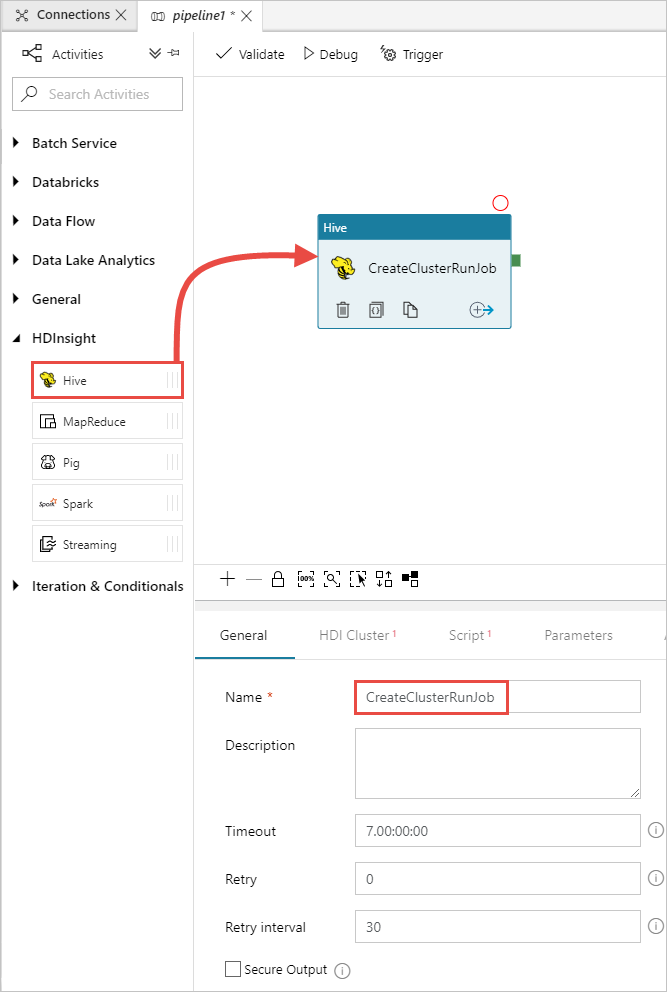
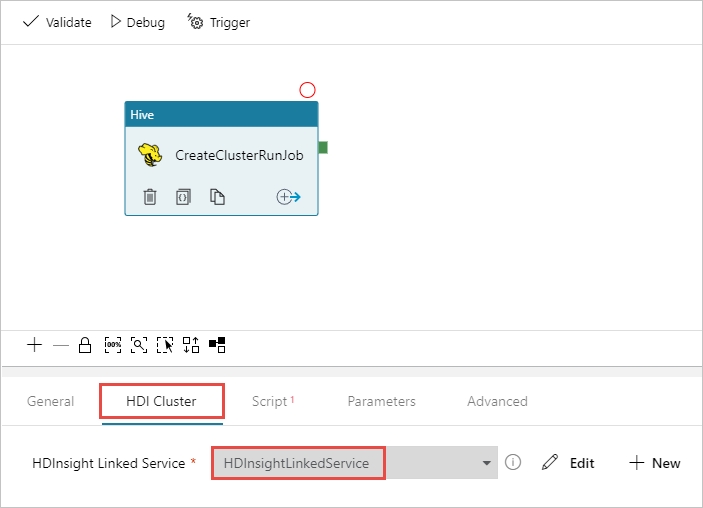
Zorg ervoor dat u de Hive-activiteit hebt geselecteerd en selecteer het tabblad HDI-cluster . Selecteer in de vervolgkeuzelijst Gekoppelde HDInsight-service de gekoppelde service die u eerder hebt gemaakt, HDInsightLinkedService voor HDInsight.
Selecteer het tabblad Script en voer de volgende stappen uit:
Selecteer HDIStorageLinkedService- in de vervolgkeuzelijst Met script gekoppelde service. Deze waarde is de gekoppelde opslagservice die u eerder hebt gemaakt.
Selecteer bij Bestandspad de optie Bladeren in opslag en navigeer naar de locatie waar het Hive-voorbeeldscript beschikbaar is. Als u het PowerShell-script eerder hebt uitgevoerd, moet de locatie
adfgetstarted/hivescripts/partitionweblogs.hqlzijn.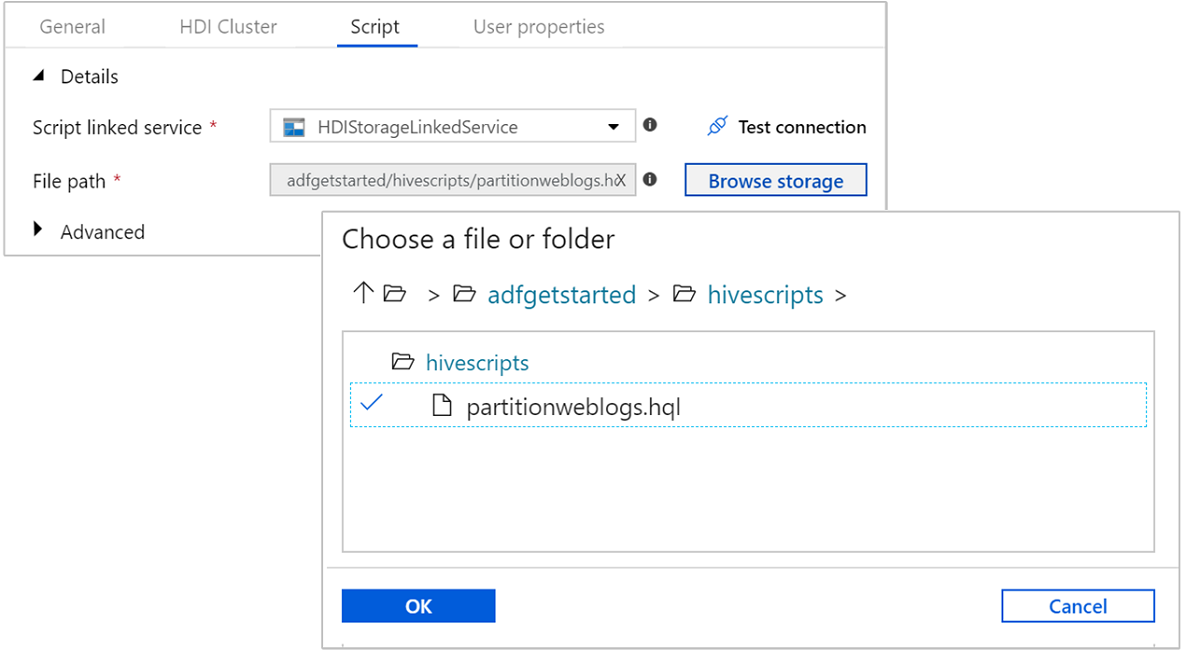
Selecteer
Auto-fill from scriptonder Geavanceerd>Parameters. Met deze optie zoekt u naar parameters in het Hive-script waarvoor waarden moeten worden opgegeven tijdens runtime.Voeg in het tekstvak waarde de bestaande map toe in de indeling
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. Het pad is hoofdlettergevoelig. Dit pad is de locatie waar de uitvoer van het script wordt opgeslagen. Hetwasbs-schema is noodzakelijk omdat beveiligde overdracht nu standaard vereist is voor opslagaccounts.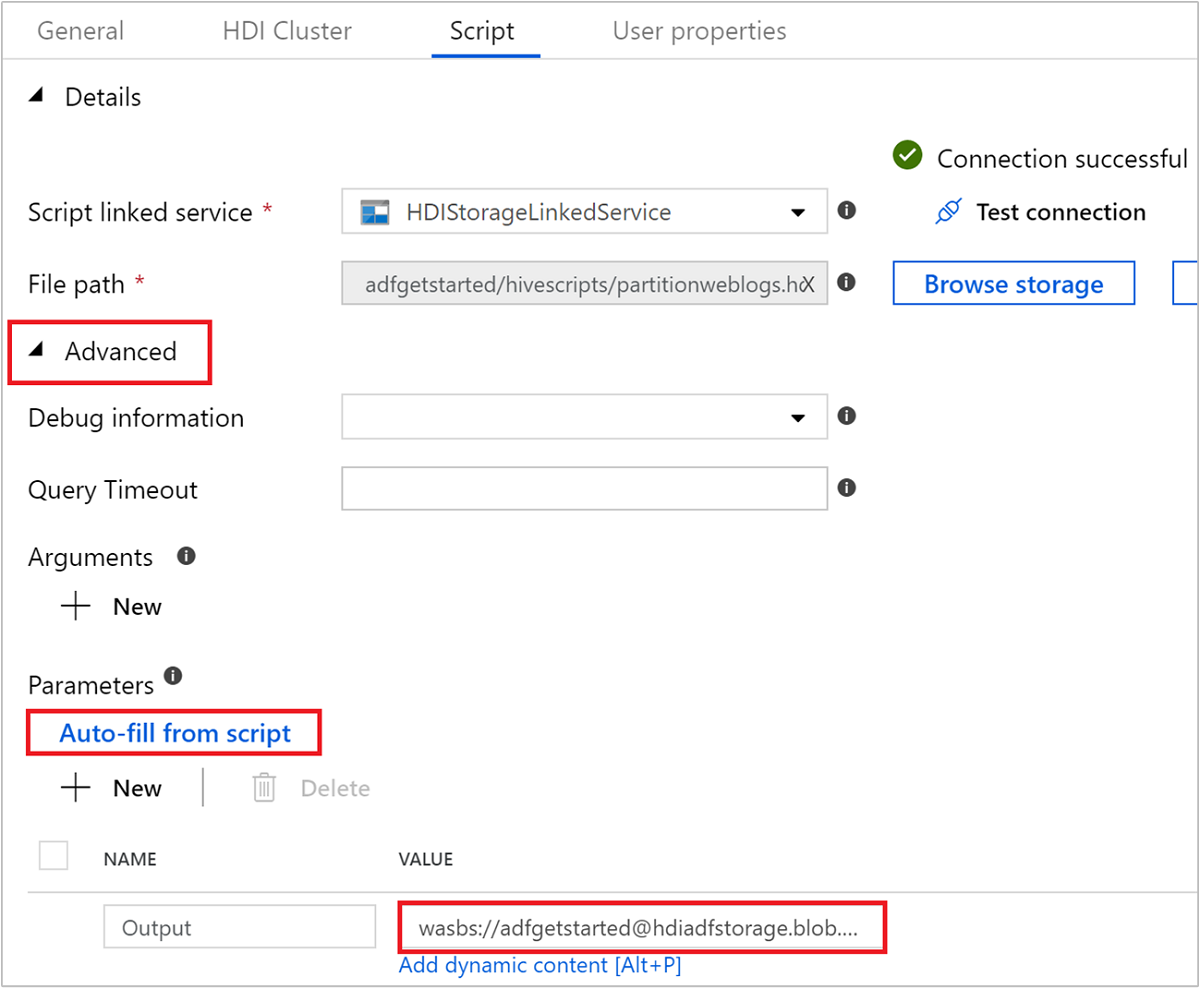
Selecteer Valideren om de pijplijn te valideren. Selecteer de >> (pijl-rechts) om het validatievenster te sluiten.
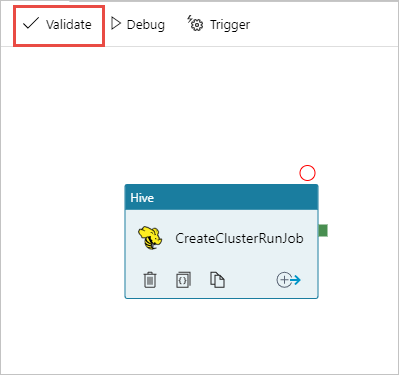
Selecteer ten slotte Alles publiceren om de artefacten naar Azure Data Factory te publiceren.
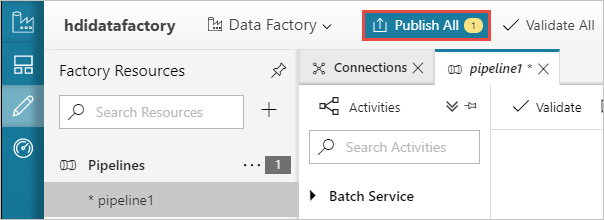
Een pijplijn activeren
Selecteer in de werkbalk op het ontwerpoppervlak Trigger toevoegen>Nu activeren.
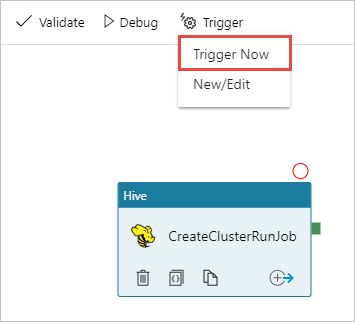
Selecteer OK in de pop-upzijbalk.
Een pijplijn bewaken
Ga naar het tabblad Controleren aan de linkerkant. U ziet een pijplijn die worden uitgevoerd in de lijst Pipeline Runs. U ziet de status van de uitvoering in de kolom Status.
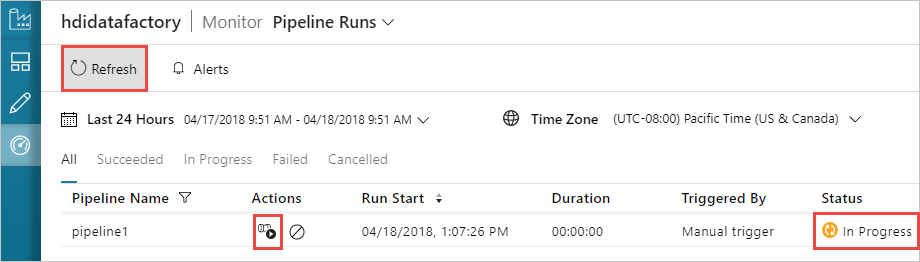
Selecteer Vernieuwen om de status te vernieuwen.
U kunt ook het pictogram Uitvoeringen van activiteit weergeven selecteren om de uitvoering van activiteit te zien die is gekoppeld aan de pijplijn. In de onderstaande schermopname ziet u dat er slechts één uitvoering van activiteit actief is omdat er slechts één activiteit is in de pijplijn die u hebt gemaakt. Als u wilt terugschakelen naar de vorige weergave, selecteert u Pijplijnen boven aan de pagina.
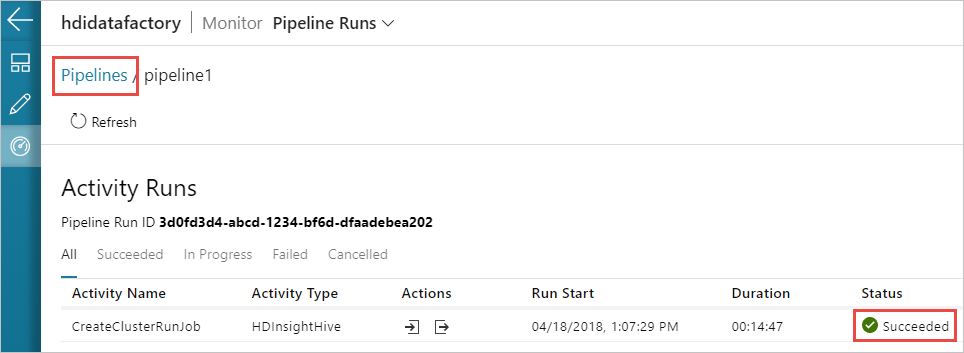
De uitvoer controleren
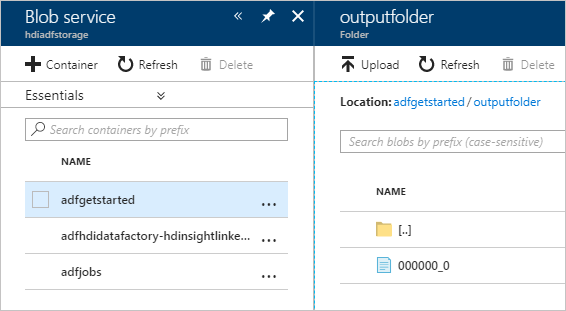
Als u de uitvoer wilt controleren, gaat u in de Azure-portal naar het opslagaccount dat u voor deze zelfstudie hebt gebruikt. Als het goed is, ziet u de volgende mappen of containers:
De map adfgerstarted/outputfolder met de uitvoer van het Hive-script dat is uitgevoerd als onderdeel van de pijplijn.
U ziet een adfhdidatafactory-linked-service-name-timestampcontainer<<>>. Deze container is de standaardopslaglocatie van het HDInsight-cluster dat is gemaakt als onderdeel van de pijplijnuitvoering.
De container adfjobs met de taaklogboeken van Azure Data Factory.
Resources opschonen
Wanneer u het HDInsight-cluster op aanvraag hebt gemaakt, hoeft u het HDInsight-cluster niet expliciet te verwijderen. Het cluster wordt verwijderd op basis van de configuratie die u hebt opgegeven bij het maken van de pijplijn. Ook nadat het cluster is verwijderd, blijven de opslagaccounts die zijn gekoppeld aan het cluster bestaan. Dit gedrag is inherent aan het ontwerp, zodat u uw gegevens intact kunt houden. Als u de gegevens niet wilt behouden, kunt u het gemaakte opslagaccount verwijderen.
U kunt ook de hele resourcegroep verwijderen die u voor deze quickstart hebt gemaakt. Met dit proces verwijdert u zowel het opslagaccount als de Azure Data Factory die u hebt gemaakt.
De resourcegroep verwijderen
Meld u aan bij Azure Portal.
Selecteer Resourcegroepen in het linkerdeelvenster.
Selecteer de resourcegroepsnaam die u met het PowerShell-script hebt gemaakt. Gebruik het filter als er te veel resourcegroepen worden weergegeven. De resourcegroep wordt geopend.
Op de tegel Resources worden het standaard opslagaccount en de data factory weergegeven, tenzij u de resourcegroep met andere projecten deelt.
Selecteer Resourcegroep verwijderen. Hiermee verwijdert u het opslagaccount en de gegevens die zijn opgeslagen in het opslagaccount.
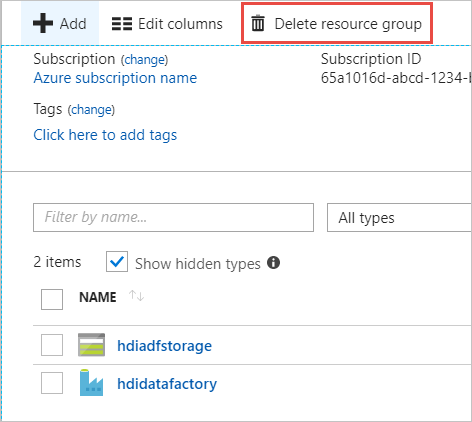
Voer de naam van de resourcegroep in ter bevestiging, en selecteer Verwijderen.
Volgende stappen
In dit artikel hebt u geleerd hoe u Azure Data Factory kunt gebruiken om een HDInsight-cluster op aanvraag te maken en Apache Hive-taken uit te voeren. Ga naar het volgende artikel voor meer informatie over het maken van HDInsight-clusters met een aangepaste configuratie.